详情链接:https://tonyzhaozh.github.io/aloha/
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
用低成本硬件学习细粒度双手操作
Tony Zhao Vikash Kumar Sergey Levine Chelsea Finn
Stanford University UC Berkeley Meta
斯坦福大学-加州大学伯克利分校Meta
ArXiv
Abstract. Fine manipulation tasks, such as threading cable ties or slotting a battery, are notoriously difficult for robots because they require precision, careful coordination of contact forces, and closed-loop visual feedback. Performing these tasks typically requires high-end robots, accurate sensors, or careful calibration, which can be expensive and difficult to set up. Can learning enable low-cost and imprecise hardware to perform these fine manipulation tasks? We present a low-cost system that performs end-to-end imitation learning directly from real demonstrations, collected with a custom teleoperation interface. Imitation learning, however, presents its own challenges, particularly in high-precision domains: the error of the policy can compound over time, drifting out of the training distribution. To address this challenge, we develop a novel algorithm Action Chunking with Transformers (ACT) which reduces the effective horizon by simply predicting actions in chunks. This allows us to learn difficult tasks such as opening a translucent condiment cup and slotting a battery with 80-90% success, with only 10 minutes worth of demonstration data.
摘要精细的操作任务,如穿线扎带或插电池,对机器人来说是出了名的困难,因为它们需要精度、接触力的仔细协调和闭环视觉反馈。执行这些任务通常需要高端机器人、精确的传感器或仔细的校准,这可能很昂贵,也很难设置。学习能否使低成本和不精确的硬件能够执行这些精细的操作任务?我们提出了一种低成本的系统,该系统直接从真实演示中执行端到端的模仿学习,并使用自定义的遥操作界面进行收集。然而,模仿学习也带来了自身的挑战,尤其是在高精度领域:随着时间的推移,策略的误差可能会加剧,偏离训练分布。为了应对这一挑战,我们开发了一种新的算法“变形金刚行动区块”(ACT),该算法通过简单地预测区块中的行动来减少有效范围。这使我们能够学习困难的任务,例如打开半透明的调味品杯和插入电池,成功率为80-90%,只需10分钟的演示数据。
Teleoperation System
远程操作系统
[Hardware Tutorial]
[硬件教程]
[ALOHA Codebase]
[ALOHA代码库]
机械臂中国区供应商:北京智能佳科技有限公司 (www.bjrobot.com)
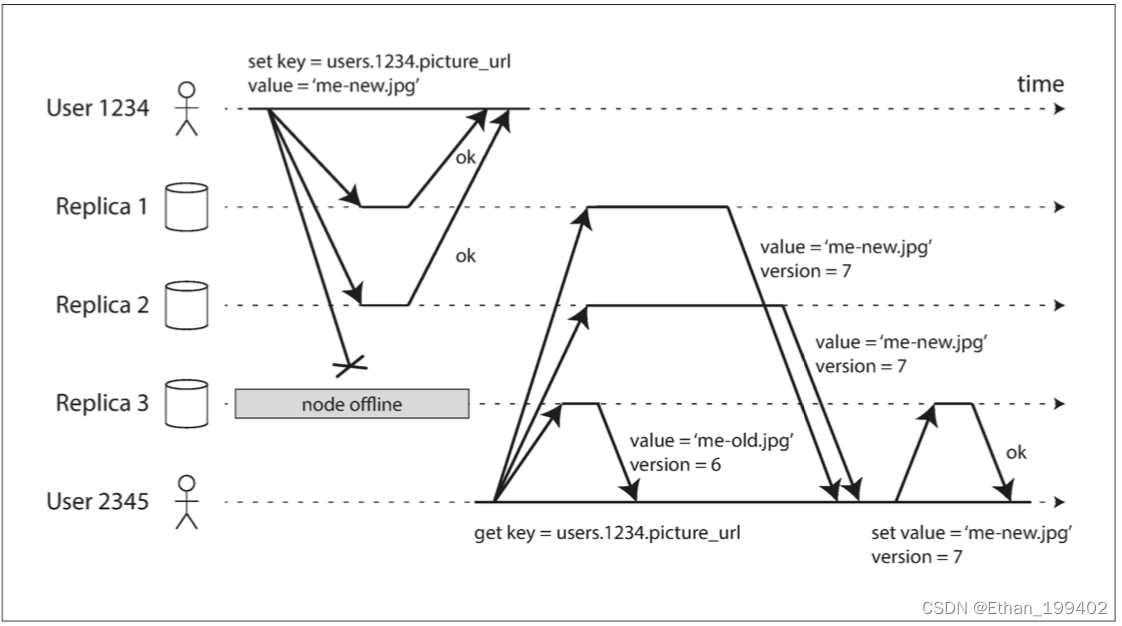
We introduce ALOHA ���️: A Low-cost Open-source Hardware System for Bimanual Teleoperation. With above $20k budget, it is capable of teleoperating precise tasks such as threading a zip tie, dynamic tasks such as juggling a ping pong ball, and contact-rich tasks such as assembling the chain in the NIST board #2.
我们介绍ALOHA���️: 一种用于双手动远程操作的低成本开源硬件系统。凭借2万多美元的预算,它能够远程操作精确的任务,如穿拉链,动态任务,如玩乒乓球,以及丰富的接触任务,如在NIST板2中组装链条。

Learning Algorithm
学习算法
[ACT+Sim Codebase]
[ACT+模拟代码库]
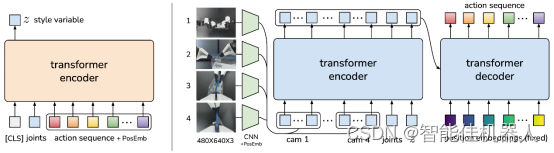
We introduce Action Chunking with Transformers (ACT). The key design choice is to predict a sequence of actions (“an action chunk”) instead of a single action like standard Behavior Cloning. The ACT policy (figure: right) is trained as the decoder of a Conditional VAE (CVAE), i.e. a generative model. It synthesizes images from multiple viewpoints, joint positions, and style variable z with a transformer encoder, and predicts a sequence of actions with a transformer decoder. The encoder of CVAE (figure: left) compresses action sequence and joint observation into z, the “style” of the action sequence. It is also implemented with a transformer. At test time, the CVAE encoder is discarded and z is simply set to the mean of the prior (i.e. zero).
我们介绍了变形金刚的动作方块(ACT)。关键的设计选择是预测一系列动作(“动作块”),而不是像标准的行为克隆那样预测单个动作。ACT策略(图:右)被训练为条件VAE(CVAE)的解码器,即生成模型。它使用变换器编码器合成来自多个视点、联合位置和风格变量的图像,并使用变换器解码器预测一系列动作。CVAE的编码器(图:左)将动作序列和联合观测压缩为动作序列的“样式”。它也通过变压器来实现。在测试时,CVAE编码器被丢弃,并简单地设置为先前的平均值(即零)。
The videos below show real-time rollouts of ACT policies, imitating from 50 demonstrations for each task. The ACT policy directly predicts joint positions at 50Hz with a fixed chunk size of 90. For perspective, the episode length is between 600 and 1000. We randomize the object position along the 15cm white referece line for both training and testing. For the following four tasks, ACT obtains 96%, 84%, 64%, 92% success respectively.
下面的视频展示了ACT政策的实时推出,模仿了每项任务的50个演示。ACT策略直接预测50Hz的联合位置,固定块大小为90。从长远来看,这一集的长度在600到1000之间。为了训练和测试,我们沿着15厘米的白色参考线随机选择物体的位置。对于以下四项任务,ACT分别获得96%、84%、64%和92%的成功率。




Reactiveness
反应性
ACT policy can react to novel environment disturbances, instead of only memorizing the training data.
ACT策略可以对新的环境扰动做出反应,而不仅仅是记忆训练数据。
Open Cup
开杯
Robustness
鲁棒性
ACT policy is also robust against certain level of distractors, shown in videos below.
ACT政策对一定程度的干扰也很有效,如下面的视频所示。
Slot Battery
槽式电池

Observations during policy execution
政策执行期间的观察
We show example image observations (i.e. the input to the ACT policy) at evaluation time. There is a total of 4 RGB cameras each streaming at 480x640. Two of the cameras are stationery and the other two are mounted on the wrist of robots.
我们展示了评估时的示例图像观察结果(即ACT策略的输入)。总共有4个RGB摄像机,每个摄像机的分辨率为480x640。其中两个摄像头是文具,另外两个安装在机器人的手腕上。



待续…
智能佳机器人