对于大型模型来说,重新训练所有模型参数的全微调变得不可行。比如GPT-3 175B,模型包含175B个参数吗,无论是微调训练和模型部署,都是不可能的事。所以Microsoft 提出了低秩自适应(Low-Rank Adaptation, LoRA),它冻结了预先训练好的模型权重,并将可训练的秩的分解矩阵注入到Transformer体系结构的每一层,从而大大减少了下游任务的可训练参数数量。
LoRA
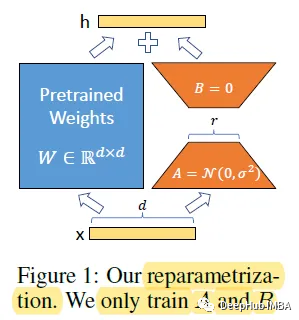
对于预训练的权重矩阵W0,可以让其更新受到用低秩分解表示后者的约束:
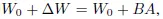
在训练过程中,W0被冻结,不接受梯度更新,而A和B包含可训练参数。当h=W0x时,修正后的正向传播变为:
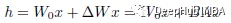
对A使用随机高斯初始化,对B使用零初始化,因此ΔW=BA在训练开始时为零(这点需要注意)。
这种方法的一个优点是,当部署到生产环境中时,只需要计算和存储W=W0+BA,并像往常一样执行推理。与其他方法相比,没有额外的延迟,因为不需要附加更多的层。
在Transformer体系结构中,自关注模块中有四个权重矩阵(Wq、Wk、Wv、Wo), MLP模块中有两个权重矩阵。LoRA只对下游任务调整关注权重,并冻结MLP模块。所以对于大型Transformer,使用LoRA可减少高达2/3的VRAM使用量。比如在GPT-3 175B上,使用LoRA可以将训练期间的VRAM消耗从1.2TB减少到350GB。
结果展示

采用HuggingFace Transformers库中的预训练RoBERTa base (125M)和RoBERTa large (355M)还有DeBERTa XXL (1.5B)进行了评估。它们通过不同的微调方法进行微调。
在大多数情况下,使用LoRA可以在GLUE上获得最佳性能。

GPT-3 175B在WikiSQL和mnli匹配的几种自适应方法的可训练参数数的比较

可以看到使用GPT-3, LoRA匹配或超过所有三个数据集的微调基线。
Stable Diffusion
Lora首先被应用在大语言模型上,但是可能被更多人知道的还是他在SD上的应用:

在Stable Diffusion微调的情况下,LoRA可以应用于将图像表示与描述它们的提示联系起来的交叉注意力层。下图的细节并不重要,只需知道黄色块是负责构建图像和文本表示之间关系的块。
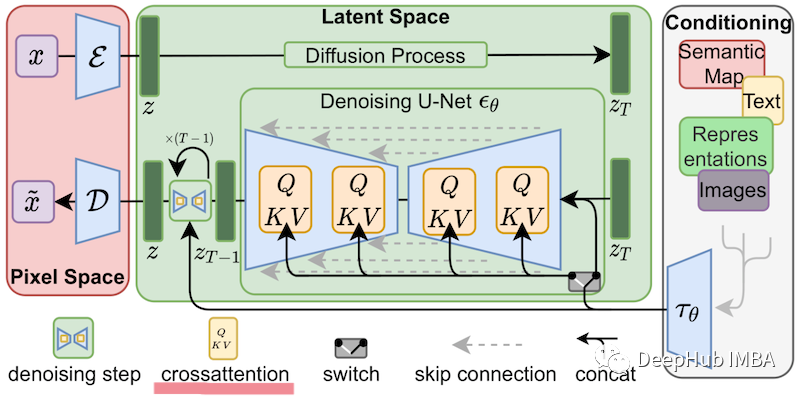
所以可以看到这样训练出来的自定义Lora模型会非常的小。
我个人实验:Stable Diffusion进行全面的微调需要最少24G的显存。但是使用Lora,批处理大小为2的单进程训练可以在单个12GB GPU上完成(不使用xformer的10GB,使用xformer的6GB)。
所以Lora在图像生成领域也是非常好的一个微调模型的方式。如果你想了解更多,这里是论文地址:
https://avoid.overfit.cn/post/407a85d672384969848f8bc5cb9bc5fe