异常检测定义
Anomaly detection。异常检测是对与标准行为或模式显著不同的罕见事件、项目或可疑观察的识别。异常也被称为异常值、噪声、偏差等。
对于异常的理解:
- 异常不一定是无用的,部分异常对数据挖掘领域有较大的价值
- 不同的场景下,异常的界定结果也并非均是异常
检测难点
- 相对于正常点,异常点数量可能非常少
- 异常和数据本身的噪声波动很难区分
- 无法预知异常点所属类型
异常分类
点异常、条件异常、聚集异常
异常结果
呈现方式:
- 异常标签 labels:直接标记正常数据和异常数据
- 异常得分 score:表示异常程度的数值
传统异常检测方法
传统的异常检测技术方法,主要是基于类标号和研究方法进行分类。
1、基于类标号。可细分为监督、半监督、无监督
2、基于研究方法。根据其训练步所使用方法不同,分为基于模型、邻近度、基于聚类和分类的异常检测。
2.1 基于模型的异常检测。可细分为基于模型、深度、误差的方法。
1)基于模型/统计。古早的异常检测是基于统计来判断的。由训练步和测试步组成,检测效率随着数据维度和数据量的增加而降低,适用于单变量数据集。
2)基于深度。其异常检测方法包括:
- 凸壳剥离法:从最外层开始构建凸壳,类似onion
- 半空间深度法:根据深度值判断异常点,
- FDC法:基于半空间深度法,设定阈值筛选异常点,效率较高
- 最小椭球体积估计:通过数据分布划分椭圆边界,其外则异常
3)基于误差。理论充足,应用较少,需事先了解数据特征。
2.2 基于邻近度。具体细分为基于距离、密度。经典方法LOF。存在的不足:难以确定最小近邻域。
2.3 基于聚类。会将联系紧密的数据归分至同簇,异常数据则不属于任一簇或者原理簇中心。为无监督方法,其主要任务是对数据聚类,且异常检测的效果不咋理想。
2.4 基于分类。根据训练集建立分类器(分类模型),确定对象所属目标类,适用于预测二元分类数据集。
- 基于神经网络。将信息的存储和处理结合,对数据建模的同时区分异常类,有较好的智能性和容错能力,应用较广。
- 基于贝叶斯网络、基于支持向量机、基于规则。即学习正常标签数据中的规则来寻找异常。
深度异常检测方法
深度异常检测即深度学习支持的异常检测。
为何会选择采取深度检测的方法?实践中,深度方法具有更强的处理这类大规模数据的能力
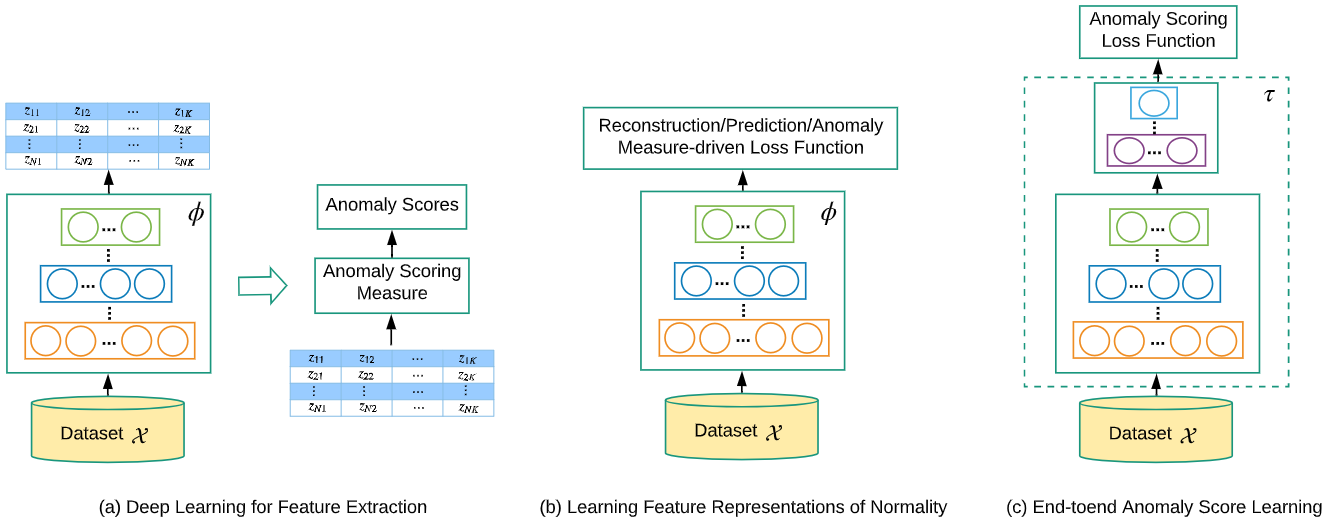
深度异常检测方法分类:只作为特征提取器、用于表示学习配合其他loss使用、端到端得到异常分值
参考
- 深度异常检测入门:一个统—框架与一个分类
- 异常检测综述:Deep Learning for Anomaly Detection: A Review
参考文献
[1]卓琳,赵厚宇,詹思延.异常检测方法及其应用综述[J].计算机应用研究,2020(S01):9-15