一、Redis的简介
1.开源免费的缓存中间件,性能高,读可达110000次/s,写可达81000次/s。
2.redis的单线程讨论:
V4.0之前:是单线程的,所有任务处理都在一个线程内完成.
V4.0:引入多线程,异步线程用于处理一些耗时较长的任务,如异步删除命令unlink,对BigKey的删除.
V6.0:在核心网络模型中引入多线程,进一步提高多核CPU利用率,但核心业务部分(命令处理)依旧是单线程.
Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小、网络宽带。
多线程会导致上下文切换,线程安全问题要引入锁机制,复杂度高,造成性能折扣。
Redis用非阻塞IO,IO多路复用的执行方式,单线程轮询描述符,将数据库的开、关、读、写都转成事件,减少线程切换和竞争。
Redis用hash结构,读取速度快。对数据存储进行了优化,压缩表(对数据压缩)、跳表(有序的数据结构加快读写速度)等。
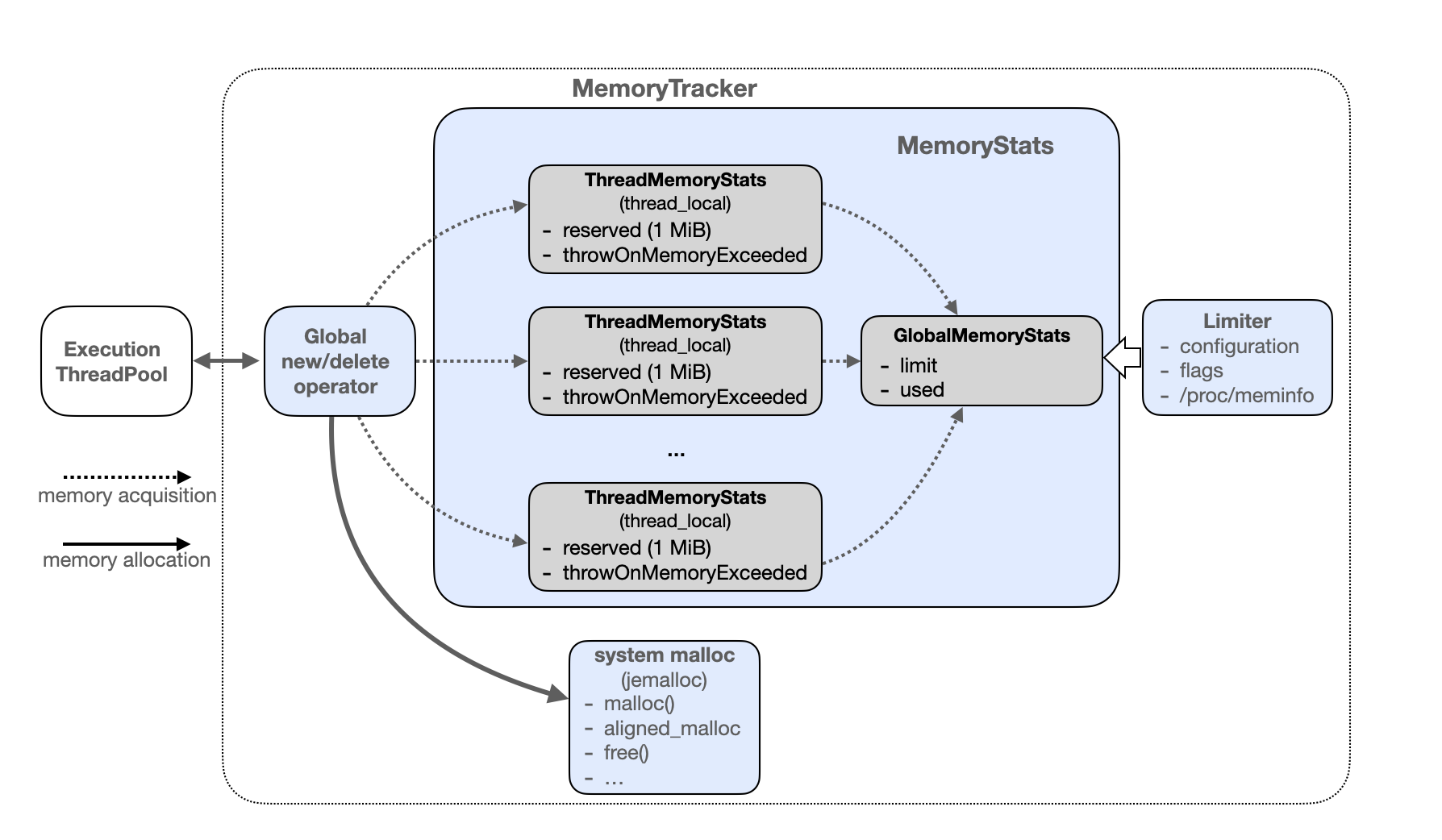
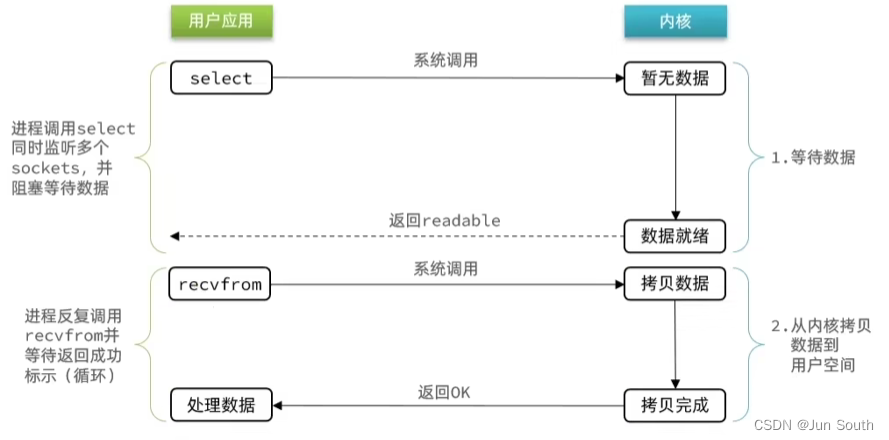
IO多路复用:利用单个线程来同时监听多个FD,并在某个FD可读、可写时得到通知,从而避免无效的等待,充分利用CPU资源。
文件描述符(File Descriptor):
简称FD,是一个从0 开始的无符号整数,用来关联Linux中的一个文件。在Linux中,一切皆文件,如常规文件、视频、硬件设备等,当然也包括网络套接字(Socket)。
二、Redis的使用经验
1.慢查询
统计比较慢的时间段指的是命令执行这个步骤。可能存的value过大、命令较多、网络延时等。 预设阀值(默认10000微秒(10毫秒)): slowlog-log-slower-than 最多保存多少条慢查询日志(默认128): slowlog-max-len
#slowlog-log-slower-than=0 #会记录所有的命令
#slowlog-log-slower-than<0 #对于任何命令都不会进行记录。
// 使用config set
config set slowlog-log-slower-than 20000
config set slowlog-max-len 1000 #指定服务器最多保存多少条慢查询日志
config rewrite #对启动 Redis 服务器时所指定的 redis.conf 文件进行改写
// 常用命令
SLOWLOG len #查看当前慢查询记录有多少条
SLOWLOG get #列出当前所有慢查询
SLOWLOG get 10 #列出慢查询的前10条
slowlog reset #清理慢查询日志2.服务器CPU100%的原因和解决方案
1.redis连接数过高 redis的默认链接数是10000,如果没有更改这个值一般可以忽略,毕竟访问不大的话不会到这么多 2.数据持久化导致的阻塞 redis是可以持久化的,而redis持久化会采取LZF算法进行压缩,这种方式会减少磁盘的存储大小,而通过这种方式是需要消耗cpu的。 rdbcompression yes 表示压缩算法是打开的 还有3个关键的参数,这里解释一下: save 900 1 //表示每15分钟且至少有1个key改变,就触发一次持久化 save 300 10 //表示每5分钟且至少有10个key改变,就触发一次持久化 save 60 10000 //表示每60秒至少有10000个key改变,就触发一次持久化 因为redis持久化的动作会记录日志,我们首先找出出问题的时间段里的持久化内容大小 3.主从存在频繁全量同步 查看主从之间网络是否有延迟,如果在一台机器上无需考虑 4.value值过大 5.redis慢查询
3.Pipeline
一次链接,批处理工具。网络延迟越大效果越好。
import redis.clients.jedis.Jedis;
import redis.clients.jedis.Pipeline;
import java.io.IOException;
/**
* 测试 Pipeline
* @Author: JunSouth
*/
public class PipelineTest {
public static void main(String[] args) throws IOException {
Jedis client = new Jedis("127.0.0.1", 6379);
long startPipe = System.currentTimeMillis();
//获取 Pipeline
Pipeline pipe = client.pipelined();
pipe.multi();
for (int i = 0; i < 100000; i++) {
pipe.set("pipe" + i, i + "" );
}
// 执行
pipe.exec();
// 关闭
pipe.close();
long endPipe = System.currentTimeMillis();
System.out.println("pipeline set 操作时间 " + (endPipe - startPipe));
for (int i = 0; i < 100000; i++) {
client.set("normal" + i, i + "");
}
System.out.println("普通 set 操作时间 : " + (System.currentTimeMillis() - endPipe));
}
}4.BigKey问题
1.String类型的Key,它的值为5MB(数据过大);
2.List类型的Key,它的列表数量为20000个(列表数量过多);
3.ZSet类型的Key,它的成员数量为10000个(成员数量过多);
4.Hash格式的Key,它的成员数量虽然只有1000个但这些成员的value总大小为100MB(成员体积过大);
redis-cli --bigkeys #连接Redis查找BigKey
redis-cli -h 127.0.0.1 -p 6379 --bigkeys #不连Redis查找BigKey1.BigKey的危害
1.阻塞请求
2.阻塞网络
3.影响主从同步、主从切换
2.BigKey的解决
1、对大Key进行拆分(用mget批量获取)
2、对大Key进行清理(通过unlink命令安全的删除大Key甚至特大Key)
3、监控Redis的内存、网络带宽、超时等指标
4、定期清理失效数据
5、压缩value
5.缓存同步策略
1.设置有效期: 查时没有则更新,设置有效期,到期自动删除。
2.同步双写: 修改数据时直接修改缓存,通过事务保持数据一致。
3.异步通知: 修改数据库后发布通知,再修改缓存。
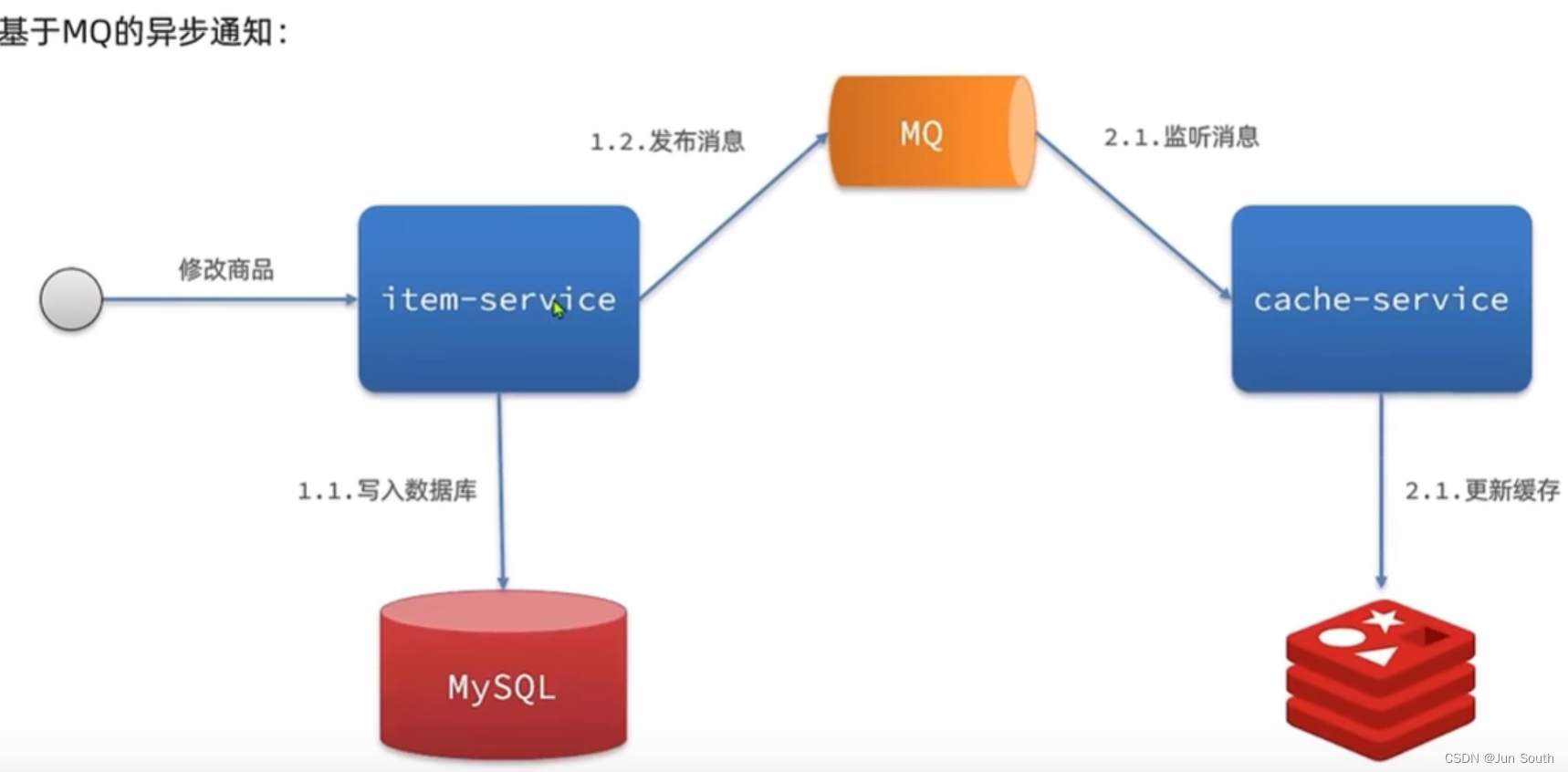
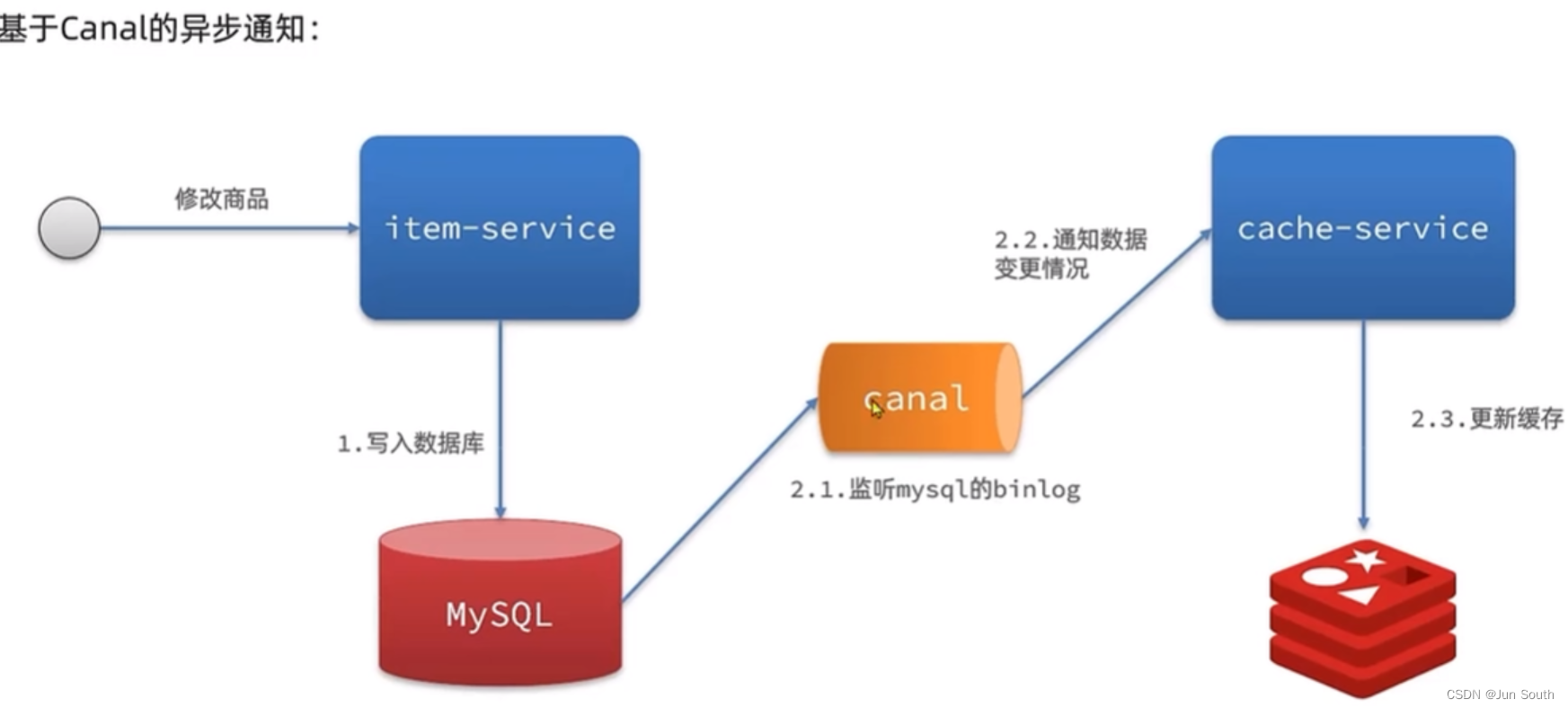

三、Redis的一些原理
1.主从的数据问题
一次从服务完整数据同步: 新的从服务器连接时,主服务器会执行一次 bgsave 命令生成一个 RDB 文件, 然后再以 Socket 的方式发送给从服务器。从服务器收到 RDB 文件之后再把所有的数据加载到自己的程序中,完成了一次全量的数据同步。 二次从服务数据同步: 主服务器会把离线之后的从服务写入命令,存储在一个特定大小队列中,队列保证先进先出的执行顺序,当从服务器重写恢复上线之后。主服务会判断离线这段时间内的命令是否还在队列中,如果在就直接把队列中的数据发送给从服务器,这样就避免了完整同步的资源浪费。 存储离线命令的队列大小默认是 1MB,可自行修改队列大小的配置项 repl-backlog-size。 主从数据一致: 当从服务器已经完成和主服务的数据同步之后,再新增的命令会以异步的方式发送至从服务器,在这个过程中主从同步会有短暂的数据不一致。 从服务器只读性 默认情况下,处于复制模式的主服务器既可以执行写操作也可以执行读操作,而从服务器则只能执行读操作。 可以在从服务器上执行 config set replica-read-only no 命令,使从服务器开启写模式,但需要注意以下几点: 在从服务器上写的数据不会同步到主服务器; 当键值相同时主服务器上的数据可以覆盖从服务器; 在进行完整数据同步时,从服务器数据会被清空;
2.哨兵的工作
监控: 持续监控 master 、slave 是否健康,是否处于预期工作状态。 主从动态切换: 当 Master 运行故障,哨兵启动自动故障恢复流程:从 slave 中选择一台作为新 master。 通知机制: 竞选出新的master之后,通知客户端与新 master 建立连接;slave 从新的 master 中 replicaof,保证主从数据的一致性。 基于 pub/sub 机制实现哨兵集群之间、客户端的通信; 通过 INFO 命令获取 slave 列表, 哨兵与 slave 建立连接;通过哨兵的 pub/sub,实现了与客户端和哨兵之间的事件通知。 1.监控: 哨兵模式启用的时候,同步启用Sentinel进程。sentinel程会向所有的master 和 slaves 以及其他sentinel进程 发送心跳包(1s一次),看看是否正常返回响应。 如果master、slave 没有在规定的时间内响应 sentinel 的 PING 命令, sentinel 会认为该节点已挂。 PING 命令的回复有两种情况: 有效: 返回 +PONG、-LOADING、-MASTERDOWN 任何一种; 无效: 有效回复之外的回复。 主观下线:某个 sentinel 节点的判断,并不是 sentinel 集群的判断。 客观下线:大部分是 sentinel 节点都对主节点的下线做了下线判断,那么就是客观的。 2.主从动态切换: sentinel 的一个很重要工作,就是从多个slave中选举出一个新的master。当然,这个选举的过程会比较严谨,需要通过 筛选 + 综合评估 方式进行选举, 1 筛选 过滤掉下线或者断线,没有回复哨兵ping响应的从节点。 评估实例过往的网络连接状况 down-after-milliseconds,如果一定周期内从库和主库经常断连,而且超出了一定的阈值(如 10 次),则该slave不予考虑。 2 综合评估 对于剩下健康的节点按顺序进行综合评估了。 3.信息通知: 等推选出最新的master之后,后续所有的写操作都会进入这个master中。要尽快通知到所有的slave,让他们重新 replacaof 到 master上,重新建立runID和slave_repl_offset。
四、Redis常见问题
缓存雪崩 同一时间内大量缓存失效,导致大量的请求打在DB上。 1.key的过期时间尽量错开。 2.主从+哨兵的集群。 缓存穿透 大量请求根本不存在的key(库中也没有),导致大量的请求打在DB上。 1.缓存空值或缺省值 2.布隆过滤器(BloomFilter),在查询时先查BloomFilter的key是否存在。 缓存击穿 热点key过期,导致大量的请求打在DB上 1.不设置过期时间 2.过期前提前更新 3.加互斥锁,某个key只让一个线程查询,阻塞其他线程. 4.缓存屏障 缓存预热 项目刚上线,提前把热key加到Redis里。 缓存降级(弃卒保帅) 保证主服务可用,将其他次要访问的数据进行缓存降级。 一般返回个温馨提示语。
LRU算法
public class LRUCache<k, v> {
//容量
private int capacity;
//当前有多少节点的统计
private int count;
//缓存节点
private Map<k, Node<k, v>> nodeMap;
private Node<k, v> head;
private Node<k, v> tail;
public LRUCache(int capacity) {
if (capacity < 1) {
throw new IllegalArgumentException(String.valueOf(capacity));
}
this.capacity = capacity;
this.nodeMap = new HashMap<>();
//初始化头节点和尾节点,用哨兵模式减少判断头结点和尾节点为空的代码
Node headNode = new Node(null, null);
Node tailNode = new Node(null, null);
headNode.next = tailNode;
tailNode.pre = headNode;
this.head = headNode;
this.tail = tailNode;
}
public void put(k key, v value) {
Node<k, v> node = nodeMap.get(key);
if (node == null) {
if (count >= capacity) {
//先移除一个节点
removeNode();
}
node = new Node<>(key, value);
//添加节点
addNode(node);
} else {
//移动节点到头节点
moveNodeToHead(node);
}
}
public Node<k, v> get(k key) {
Node<k, v> node = nodeMap.get(key);
if (node != null) {
moveNodeToHead(node);
}
return node;
}
private void removeNode() {
Node node = tail.pre;
//从链表里面移除
removeFromList(node);
nodeMap.remove(node.key);
count--;
}
private void removeFromList(Node<k, v> node) {
Node pre = node.pre;
Node next = node.next;
pre.next = next;
next.pre = pre;
node.next = null;
node.pre = null;
}
private void addNode(Node<k, v> node) {
//添加节点到头部
addToHead(node);
nodeMap.put(node.key, node);
count++;
}
private void addToHead(Node<k, v> node) {
Node next = head.next;
next.pre = node;
node.next = next;
node.pre = head;
head.next = node;
}
public void moveNodeToHead(Node<k, v> node) {
//从链表里面移除
removeFromList(node);
//添加节点到头部
addToHead(node);
}
class Node<k, v> {
k key;
v value;
Node pre;
Node next;
public Node(k key, v value) {
this.key = key;
this.value = value;
}
}
}