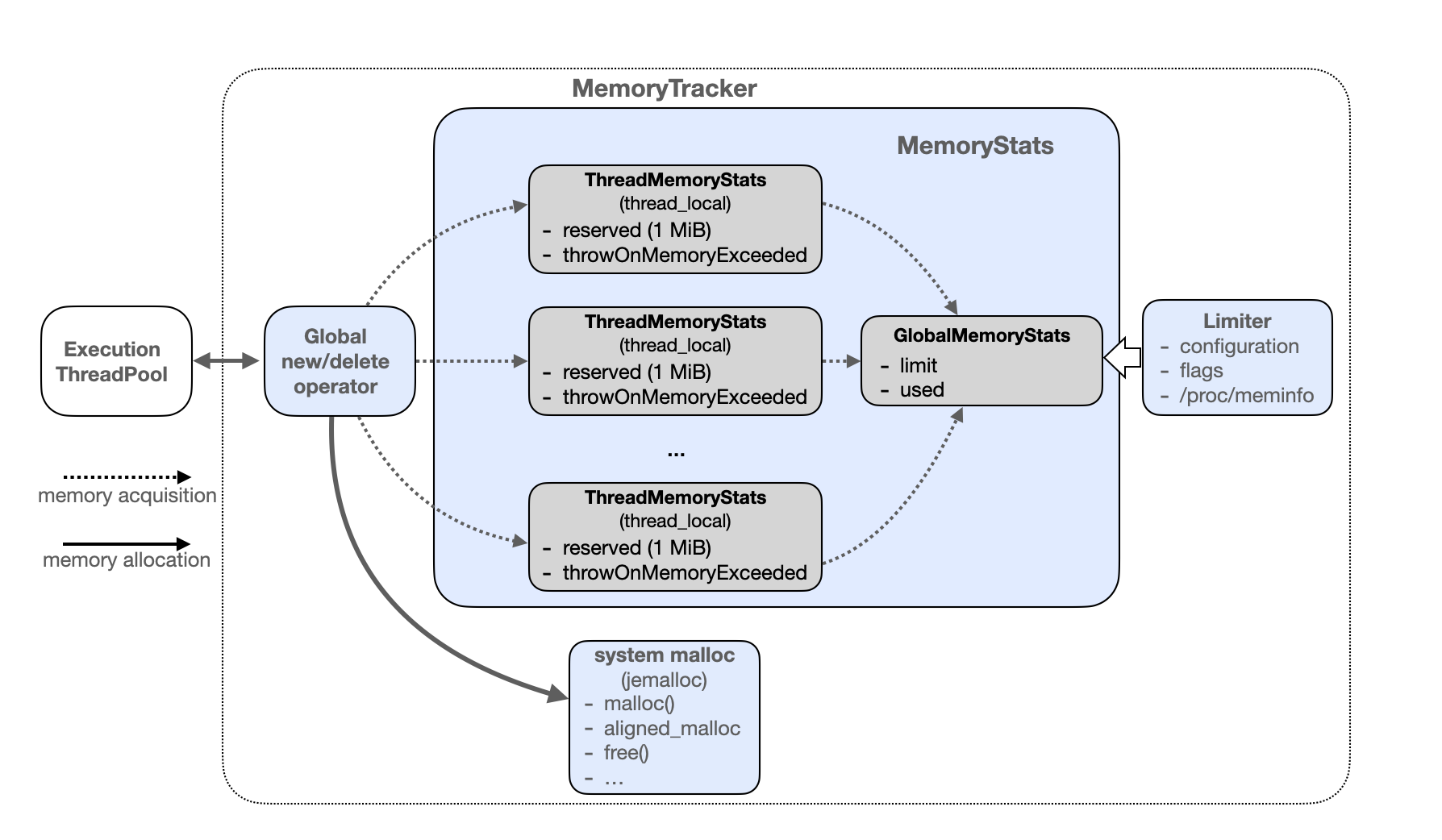
LLMs 一出,谁与争锋?
毫无疑问,大语言模型(LLM)掀起了新一轮的技术浪潮,成为全球各科技公司争相布局的领域。诚然,技术浪潮源起于 ChatGPT,不过要提及 LLMs 的技术发展的高潮,谷歌、微软等巨头在其中的作用不可忽视,它们早早地踏入 AI 的技术角斗场中,频频出招,势要在战斗中一争高下,摘取搜索之王的桂冠。
而这场大规模的 AI 之战恰好为 LLMs 技术突破奏响了序曲。LangChain 的加入则成为此番技术演进的新高潮点,它凭借其开源特性及强大的包容性,成为 LLMs 当之无愧的【奥德赛】。
LLMs 变聪明的秘密——LangChain
LLMs 优秀的对话能力已是共识,但其内存有限、容易“胡说八道”也是不争的事实。比如你要问 ChatGPT:“《荒野大镖客:救赎》游戏中设置了几种级别的难度?“,ChatGPT 会自信地回答:”没有难度设置“。但实际上,这个游戏中共设置了 3 种难度级别。LLMs 是根据权重生成答案,因此无法验证信息的可靠性或提供信息来源。
那么,如何让 LLMs 好好地回答问题并总结数据?如何让 LLMs 提供答案来源?如何让 LLMs 记住 token 限制范围外的对话?
这个时候,LangChain 就可以大展身手了。LangChain 是一个将不同计算方式、知识与 LLMs 相结合的框架,可进一步发挥 LLMs 的实际作用。可以这样理解,只要熟练使用 LangChain,你就可以搭建专业领域的聊天机器人和特定的计算 Agent 等。
不过,在 LLMs 变聪明的过程中,以 Milvus 为代表的向量数据库扮演着怎样的角色呢?或许,我们把 Milvus 看成 LLMs 的超强记忆外挂更为合适。
LLMs 一次只能处理一定数量的 token(约 4 个字符),这就意味着 LLMs 无法分析长篇文档或文档集。想要解决这个问题,我们可以将所有文档存储在数据库中,搜索时仅搜索与输入问题相关的文档,并将这些文档输入其中,向 LLMs 提问以生成最终答案。
Milvus 向量数据库可以完美地承接这一任务,它可以利用语义搜索(semantic search)更快地检索到相关性更强的文档。
首先,需要将待分析的所有文档中的文本转化为 embedding 向量。在这一步中,可以使用原始的 LLMs 生成 embedding 向量,这样不仅操作方便,还能在检索过程中保留 LLMs 的“思维过程”。将所有数据转化成 embedding 向量后,再将这些原始文本的 embedding 向量和原数据存储在 Milvus 中。在查询时,可以用同样的模型将问题转化为 embedding 向量,搜索相似性高的相关问题,然后将这个相关问题作为提问,输入 LLMs 中并生成答案。
虽然这个流程看起来简单,但完成整个流水线(pipeline)的搭建需要大量时间和精力。但好消息是,LangChain 能够帮助我们轻松完成搭建,并且还为向量数据库提供了向量存储接口 (VectorStore Wrapper)。
如何集成 Milvus 和 LangChain?
以下代码集成了 Milvus 和 LangChain:
class VectorStore(ABC):
"""Interface for vector stores.""" @abstractmethoddef add_texts(
self,
texts: Iterable[str],
metadatas: Optional[List[dict]] = None,
kwargs:Any,
) ->List[str]:
"""Run more texts through the embeddings and add to the vectorstore.""" @abstractmethoddefsimilarity_search(
self, query:str, k:int =4,kwargs: Any) -> List[Document]:
"""Return docs most similar to query."""def max_marginal_relevance_search(
self, query: str, k: int = 4, fetch_k: int = 20) -> List[Document]:
"""Return docs selected using the maximal marginal relevance."""raise NotImplementedError
@classmethod @abstractmethoddef from_texts(
cls: Type[VST],
texts: List[str],
embedding: Embeddings,
metadatas: Optional[List[dict]] = None,
**kwargs: Any,
) -> VST:
"""Return VectorStore initialized from texts and embeddings."""
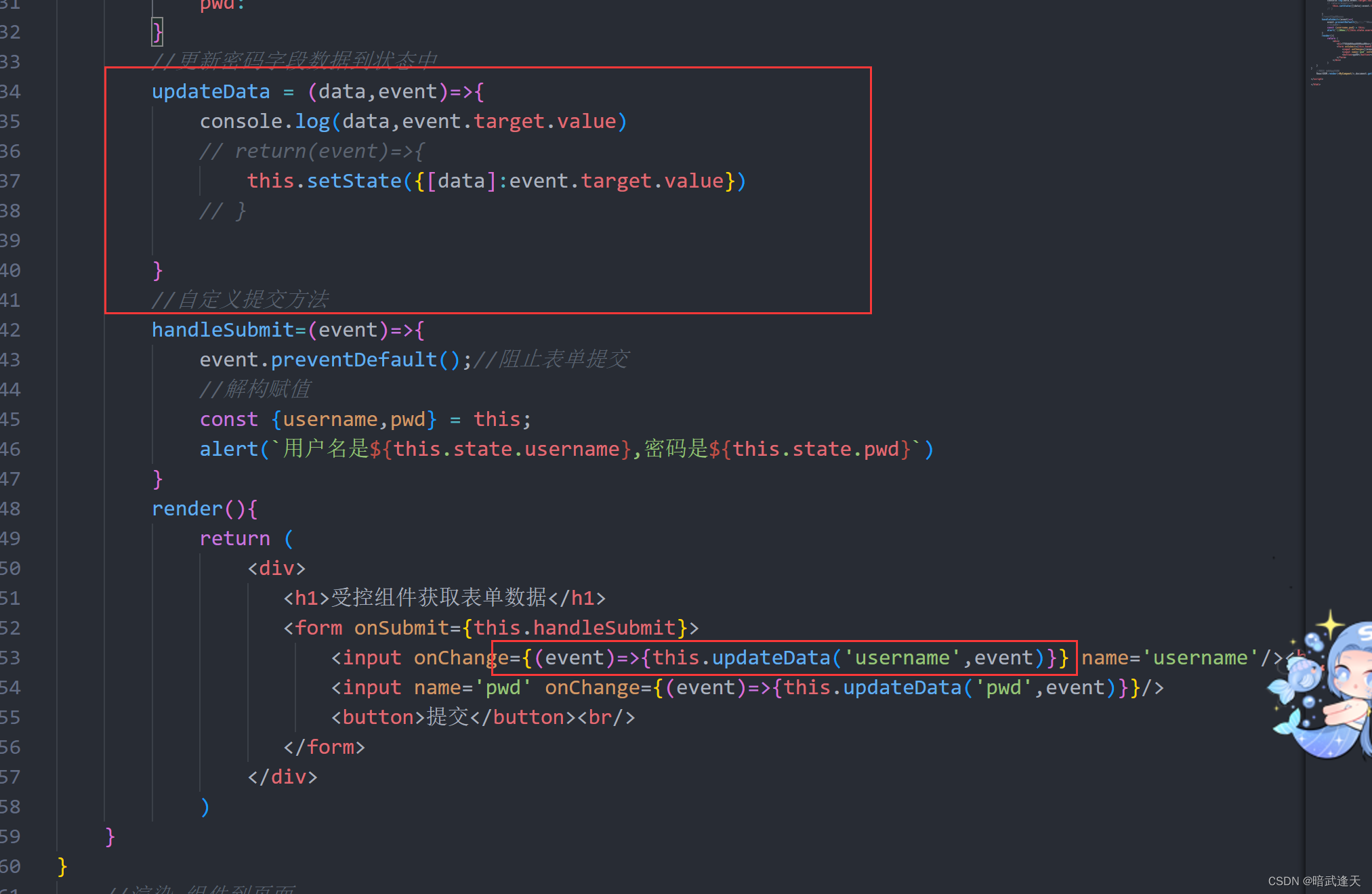
为了将 Milvus 集成到 LangChain 中,我们需要实现几个关键函数:add_texts()
、similarity_search()、max_marginal_relevance_search()和 from_text()。
总体而言 Milvus VectorStore 遵循一个简单的流程。首先它先接收一组文档。在大多数 LLMs 项目中,文档是一种数据类,包含原始文本和所有相关元数据。文档的元数据通常为 JSON 格式,方便存储在 Milvus中。VectorStore 会使用你提供的 emebdding 函数将接收到的文档转化为 embedding 向量。在大多数生产系统中,这些 embedding 函数通常是第三方的 LLMs 服务,如 OpenAI、Cohere 等。当然,如果能够提供一个函数,允许输入文本后返回向量,那也可以使用自己的模型。在 pipeline 的这个步骤中,Milvus 负责接收 embedding、原始文本和元数据,并将它们存储在一个集合(collection)中。随着集合中的文档数据越来越多,Milvus 会为所有存储的 embedding 创建索引,从而加快搜索的速度。
Pipeline 的最后一步就是检索相关数据。当用户发送一个问题时,文本和用于过滤的元数据被发送到 Milvus VectorStore。Milvus 会使用同样的 embedding 函数将问题转化为 embedding 向量并执行相似性搜索。Milvus 作为 VectorStore 提供两种类型的搜索,一种是默认的、按照未修改的顺序返回对象,另一种是使用最大边缘相关算法(MMR)排序的搜索。
不过,将 Milvus 集成到 LangChain 中的确存在一些问题,最主要的是 Milvus 无法处理 JSON 文件。目前,只有两种解决方法:
在现有的 Milvus collection 上创建一个 VectorStore。
基于上传至 Milvus 的第一个文档创建一个 VectorStore。
Collection schema 在 collection 创建时确定,因此所有后续新增的数据都需要符合 schema。不符合 schema 的数据都无法上传。
同样,如果在 collection 创建后向文档添加了任何新的元数据,这些新增的元数据都将被忽略。这些缺点不利于系统适用于多种场景。我们需要花很多额外精力来清理输入数据和创建新的 collection。不过好消息是,Milvus 2.3 版本即将支持存储 JSON 格式的文件,能够更进一步简化集成工作,感兴趣的朋友可以试用 Milvus 2.3 测试版!
写在最后
操作进行到这里,我们便可以搭建出一个 LLMs 知识库。在集成了 Milvus 后,LangChain 还新增了 Retriever,用于连接外部存储。当然,由于开发时间较短,本项目还有以下优化空间:
-
精简 Milvus VectorStore 代码。
-
加入 Retriever 功能。
此外,Milvus 目前还不支持动态 schema,因此向已创建好的 collection 中插入不符合 schema 的数据较为麻烦。在 Milvus 正式支持 JSON 格式后,我们会重新修改优化这一部分功能。
(本文首发于 The Sequence,作者 Filip Haltmayer 系 Zilliz 软件工程师。)
-
如果在使用 Milvus 或Zilliz 产品有任何问题,可添加小助手微信 “zilliz-tech” 加入交流群 -
欢迎关注微信公众号“Zilliz”,了解最新资讯。 
本文由 mdnice 多平台发布