目录
【goroutine的调度器】
【Go语言的sync包】
【sync.Mutex】
sync.Mutex 底层原理
sync.Mutex 其它用法
【sync.RWMutex】
sync.RWMutex 实现原理
【sync.WaitGroup】
Go 并发编程中存在的难题:并发编程不像是传统的串行编程,程序的运行存在着很大的不确定性。怎么才能让相应的任务按照设想的流程运行?有时候按照正常理解的并发方式去实现的程序却莫名其妙就 panic 或者死锁了,排查起来非常困难。
【goroutine的调度器】
这里说的调度器是用于调度 goroutine、对接系统级线程,它主要负责统筹调配 Go 并发编程模型中的三个主要元素:G(goroutine 的缩写)、P(processor 的缩写)和 M(machine 的缩写),其中的 M 指代的就是系统级线程,而 P 指的是一种可以承载若干个 G 且能够使这些 G 适时地与 M 进行对接并得到真正运行的中介。参考资料:Golang深入理解GPM模型_golang gpm_TerryZjl的博客-CSDN博客。
看一个例子:
package main
import (
"fmt"
"time"
)
func test1() {
for i := 0; i < 10; i++ {
go func() {
fmt.Println(i)
}()
}
// 大概率没有任何输出
}
func main() {
test1()
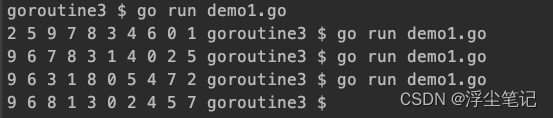
}在尝试运行上面的程序之后,只有极少概率会输出数据:

分析一下为什么会出现这样的情况?
- 每一个独立的 Go 程序在运行时总会有一个主 goroutine 被自动地启用,主 goroutine 的go函数就是程序入口的main函数。
- 当程序执行到一条go语句的时候,Go 语言的运行时系统会尝试从某个存放空闲的goroutine队列中获取一个goroutine,如果找不到空闲goroutine的情况下才会去创建一个新的goroutine,如果有已存在的 goroutine 则会被优先复用。
- 在拿到了一个空闲的goroutine之后,Go 语言运行时系统会把这个goroutine追加到某个存放可运行的goroutine队列中,并且按照先进先出的顺序由调度器安排运行,这里面会存在耗时。go函数的执行时间总是会滞后于它所属的go语句的执行时间。
- 只要go语句本身执行完毕,Go 程序就不会再等待go函数的执行,而是会立刻去执行后边的语句(也就是例子中for语句中的下一个迭代),也就是异步并发地执行。
- 上面的for语句会以很快的速度执行完毕,然而那 10 个包装了go函数的 goroutine 可能还没有获得运行的机会。一旦主 goroutine 中的代码(也就是main函数中的那些代码)执行完毕,当前的 Go 程序就会结束运行,如果这个还有 goroutine 未得到运行机会,那么它们就真的被“抛弃”了。
- Go 语言并不会去保证这些 goroutine 以怎样的顺序运行,由于主 goroutine 与我们手动启用的其他 goroutine 一起接受调度,所以哪个 goroutine 先执行完、哪个 goroutine 后执行完往往是不可预知的,除非使用某种方式人为干预。
怎么人工干预?也就是怎样让主 goroutine 等待其他 goroutine?简单的办法就是让主 goroutine 睡一会儿。比如改成下面这样:
package main
import (
"fmt"
"time"
)
func test2() {
for i := 0; i < 10; i++ {
go func() {
fmt.Print(i, " ")
}()
}
time.Sleep(time.Millisecond * 500) //小睡500毫秒
}
func main() {
test2()
}改过之后会发现每次运行都会有数据输出了:
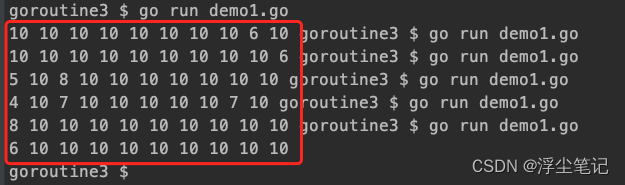
但是输出的内容没有规律,不太符合预期的结果(0到9)。原因是上面的变量 i 在其它额goroutine里面被共享了,共享变量就存在竞争条件,这个时候就需要用锁的机制来完成。先不用说怎么用锁,可以简单的改成下面的方式就能正常输出了:
package main
import (
"fmt"
"time"
)
func test3() {
for i := 0; i < 10; i++ {
go func(i int) {
fmt.Print(i, " ")
}(i)
}
time.Sleep(time.Millisecond * 500)
// 输出: 9 3 4 5 6 7 8 0 2 1 (顺序不确定)
}
func main() {
test3()
} 
像上面这样把变量 i 传递给协程内部的函数就可以了,这是因为go的方法调用使用的是值传递,因此变量 i 被复制了一份,此时每个协程里面所拥有的变量地址是不一样的,它没有了竞争关系,所以是可以正确执行的。
但是每次输出的结果的顺序都是不确定的,这和goroutine的调度有关。如果想要顺序的输出0到9,可以改成下面这样:
package main
import (
"fmt"
"time"
)
func test5() {
var count uint32
trigger := func(i uint32, fn func()) {
for {
if n := atomic.LoadUint32(&count); n == i {
fn()
atomic.AddUint32(&count, 1)
break
}
time.Sleep(time.Nanosecond)
}
}
for i := uint32(0); i < 10; i++ {
go func(i uint32) {
fn := func() {
fmt.Print(i, " ")
}
trigger(i, fn)
}(i)
}
trigger(10, func() {})
//输出: 0 1 2 3 4 5 6 7 8 9
}
func main() {
test5()
}实现步骤分析:
- 在go函数中先声明了一个匿名的函数并赋给了变量fn,用来打印go函数的参数i的值。
- 定义一个 trigger函数,接受两个参数,一个是uint32类型的参数i, 另一个是func()类型的参数fn,trigger函数会不断地获取名叫count的变量的值,并判断该值是否与参数i的值相同,如果相同就立即调用fn代表的函数,然后把count变量的值加1并退出当前循环;如果不相同就先让当前的goroutine“睡眠”一个纳秒再进入下一个迭代。
- 由于trigger函数会被多个 goroutine 并发地调用,所以它用到的非本地变量count 被多个用户级线程共用,因此操作变量count的时候需要使用原子操作。此时的count变量的值总是下一个迭代的序号,因此go函数实际的执行顺序才会与go语句的执行顺序完全一致。
让主 goroutine 睡一会儿就是为了给其它goroutine争取运行的机会,使用time.Sleep之后输出了数据,说明这个办法可行。但是具体应该睡多久呢?时间太短可能还来不及让其它goroutine执行完毕,时间太长可能导致资源浪费。因此可以先创建一个channel,它的长度应该与手动启用的 goroutine 的数量一致,在每个手动启用的 goroutine 即将运行完毕的时候向这个channel发送一个值。看下面的代码:
package main
import (
"fmt"
"time"
)
func test4() {
num := 10
sign := make(chan struct{}, num)
for i := 0; i < num; i++ {
go func(i int) {
fmt.Print(i, " ")
sign <- struct{}{}
}(i)
}
for j := 0; j < num; j++ {
<-sign
}
}
func main() {
test4()
}
注意上面声明channel的元素变量的时候用的是 chan struct{}类型,这里的 struct{} 代表了既不包含任何字段也不拥有任何方法的空结构体类型,它的表示方法只有一个:struct{}{},它占用的内存空间是0字节,这个值在整个 Go 程序中永远都只会存在一份。虽然可以无数次地使用这个值的字面量,但是用到的却都是同一个值。
以上代码是在main函数的最后从channel接收元素值,接收的次数应该与手动启用的 goroutine 的数量保持一致。有没有比使用channel更好的方法?当然有,可以使用 sync.WaitGroup 类型。
package main
import (
"fmt"
"time"
)
func test6() {
var wg sync.WaitGroup
for i := 0; i < 10; i++ {
wg.Add(1)
go func(i int) {
fmt.Print(i, " ")
wg.Done()
}(i)
}
wg.Wait()
// 输出: 9 6 4 1 2 7 0 8 5 3 (顺序不确定)
}
func main() {
test6()
}【Go语言的sync包】
Go 语言之父 Rob Pike 说过:“不要通过共享内存来通信,应该通过通信来共享内存(Don’t communicate by sharing memory, share memory by communicating)”,Go 中不仅可以使用基于CSP模型的 channel 进行不同 Goroutine 间的通信,还提供了sync 包(意思是“同步”)的相关操作,包括:sync.WaitGroup(并发编排)、sync.Mutex(互斥锁)、sync.RWMutex(读写互斥锁)、sync.Once(只执行一次)、sync.Cond(条件变量)等。
一旦数据被多个线程共享,那么就有可能产生竞争和冲突的情况。因此需要避免多个线程或者多个协程在同一时刻操作同一个数据块,常规的办法就是使用“互斥锁”。也就是一个线程在想要访问某一个共享资源的时候需要先申请访问权限(拿到锁),只有申请成功之后才能真正开始访问,当线程对共享资源的访问结束时应该归还对该资源的访问权限(归还锁)。这里的共享资源可以被称为是“临界区”。
比如多个 goroutine 并发更新同一个资源,比如 计数器、同时更新用户的账户信息、秒杀系统、往同一个 buffer 中并发写入数据等等。如果没有互斥控制就会出现一些异常情况,比如 计数器的计数不准确、用户的账户可能出现透支、秒杀系统出现超卖、buffer 中的数据混乱,等等。使用互斥锁之后,限定临界区只能同时由一个线程持有。
这里的互斥锁跟MySQL中的“排他锁”有点类似,可以参考:深入理解MySQL中的事务和锁_浮尘笔记的博客-CSDN博客
【sync.Mutex】
当一个 goroutine 通过调用 Lock 方法获得了这个锁的拥有权后, 其它请求锁的 goroutine 就会阻塞在 Lock 方法的调用上,直到锁被释放并且自己获取到了这个锁的拥有权。sync.Mutex的用法如下:
var mu sync.Mutex
mu.Lock() // 加锁
doSomething()
mu.Unlock() // 解锁先来看一个goroutine中不加锁的例子,在5000次循环中 创建goroutine并累加:
package main
import (
"fmt"
"time"
)
func test1() {
counter := 0
for i := 0; i < 5000; i++ {
go func() {
counter++
}()
}
time.Sleep(1 * time.Second)
fmt.Println(counter)
}
func main() {
test1()
}

可以看到,每次运行的结果都不一样,而且没有达到预期的结果5000,这是因为 counter++ 不是原子操作,它至少包含如下几个步骤:读取变量 counter 的当前值、对这个值加 1、把结果再保存到 counter 中。因为不是原子操作,就可能有并发的问题。
锁定操作可以通过调用互斥锁 sync.Mutex 的Lock方法实现,解锁操作可以调用Unlock方法,看下面的代码:
package main
import (
"fmt"
"time"
)
func test2() {
var mu sync.Mutex
counter := 0
for i := 0; i < 5000; i++ {
go func() {
defer func() {
mu.Unlock() //释放互斥锁
}()
mu.Lock() //添加互斥锁
counter++
}()
}
time.Sleep(1 * time.Second)
fmt.Println(counter)
}
func main() {
test2()
}
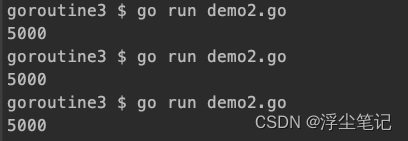
添加互斥锁之后,每次计算得到的结果都是复合预期的5000。
使用互斥锁时有哪些注意事项?
- 尽量减少在锁中的操作,这可以减少因 Goroutine 阻塞而带来的损耗与延迟;
- 不要重复锁定互斥锁;
- 不要忘记使用Unlock解锁互斥锁,避免重复锁定,必要时使用defer语句;
- 不要对尚未锁定或者已解锁的互斥锁解锁;
- 不要在多个函数之间直接传递互斥锁。
对于每一个锁定操作都应该只有一个对应的解锁操作。Go 语言运行时只要发现所有的用户级 goroutine 都处于等待状态,就会自行抛出一个带有如下信息的 panic:fatal error: all goroutines are asleep - deadlock! 属于致命错误,无法被恢复,即使调用recover函数也不会起任何作用。一旦产生死锁,程序必然崩溃。
sync.Mutex 底层原理
互斥锁 sync.Mutex 是一个结构体类型,属于值传递,因此使用的时候会产生副本,如果把一个互斥锁作为参数值传给了一个函数,那么在这个函数中对传入的锁的所有操作都不会影响该函数之外的那个原锁。以下是 sync.Mutex 的定义:
// $GOROOT/src/sync/mutex.go
// Values containing the types defined in this package should not be copied.
// “不应复制那些包含了此包中类型的值”
package sync
type Mutex struct {
state int32 //表示当前互斥锁的状态
sema uint32 //用于控制锁状态的信号量
}
type Locker interface {
Lock() //加锁方法
Unlock() //解锁方法
}
func (m *Mutex) Lock() {}
func (m *Mutex) Unlock() {}
// A Mutex must not be copied after first use.
// “禁止复制首次使用后的Mutex”初始情况下 Mutex 的实例处于 Unlocked 状态(state 和 sema 均为 0),如果对 Mutex 实例的复制(也就是两个整型字段的复制),原变量与副本就是两个单独的内存块,各自发挥同步作用,互相就没有了关联。而且如果在一个 mutex 处于 locked 的状态时对它进行了拷贝,就会对副本进行加锁操作,将导致加锁的 Goroutine 永远阻塞下去。
sync.Mutex 其它用法
很多情况下,Mutex 会嵌入到其它 struct 中使用,比如下面的方式:
package main
import (
"fmt"
"sync"
)
type Counter struct {
mu sync.Mutex
Count uint64
}
func main() {
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
for j := 0; j < 100000; j++ {
counter.mu.Lock()
counter.Count++
counter.mu.Unlock()
}
}()
}
wg.Wait()
fmt.Println(counter.Count)
}还可以把获取锁、释放锁、计数加一的逻辑封装成一个方法,对外不需要暴露锁等逻辑:
package main
import (
"fmt"
"sync"
)
// 线程安全的计数器类型
type Counter struct {
CounterType int
Name string
mu sync.Mutex
count uint64
}
// 加1的方法,内部使用互斥锁保护
func (c *Counter) Incr() {
c.mu.Lock()
c.count++
c.mu.Unlock()
}
// 得到计数器的值,也需要锁保护
func (c *Counter) Count() uint64 {
c.mu.Lock()
defer c.mu.Unlock()
return c.count
}
func main() {
// 封装好的计数器
var counter Counter
var wg sync.WaitGroup
wg.Add(10)
// 启动10个goroutine
for i := 0; i < 10; i++ {
go func() {
defer wg.Done()
// 执行10万次累加
for j := 0; j < 100000; j++ {
counter.Incr() // 受到锁保护的方法
}
}()
}
wg.Wait()
fmt.Println(counter.Count())
}
【sync.RWMutex】
有些时候,比如在写少读多的情况下,即使一段时间内没有写操作,大量并发的读访问也不得不在 sync.Mutex 的保护下变成了串行访问,这个时候对性能的影响就比较大。因此Go语言中还有一个 sync.RWMutex 用来表示读写互斥锁,可以理解为sync.Mutex的子集,相当于对共享资源的“读操作”和“写操作”区别对待,相比于互斥锁,读写锁可以实现更加精细的访问控制。
使用读写锁的时候,如果某个读操作的 goroutine 持有了锁,其它读操作的 goroutine 就不必一直等待了,而是可以并发地访问共享变量,这样就可以将串行的读变成并行读,提高读操作的性能。当写操作的 goroutine 持有锁的时候,它就是一个排他锁,其它的写操作和读操作的 goroutine 需要阻塞等待持有这个锁的 goroutine 释放锁。
一个读写锁中包含了两个锁:读锁和写锁:
- sync.RWMutex 类型中的 Lock 方法和Unlock方法分别用于对 写锁 进行锁定和解锁,
- sync.RWMutex 类型中的 RLock 方法和RUnlock方法分别用于对 读锁 进行锁定和解锁。
var rwmu sync.RWMutex
rwmu.RLock() //加读锁
readSomething()
rwmu.RUnlock() //解读锁
rwmu.Lock() //加写锁
writeSomething()
rwmu.Unlock() //解写锁对于某个受到读写锁保护的共享资源,多个写操作不能同时进行,写操作和读操作也不能同时进行,但多个读操作却可以同时进行。
- 在写锁已被锁定的情况下再试图锁定写锁,会阻塞当前的 goroutine。
- 在写锁已被锁定的情况下试图锁定读锁,也会阻塞当前的 goroutine。
- 在读锁已被锁定的情况下试图锁定写锁,同样会阻塞当前的 goroutine。
- 在读锁已被锁定的情况下再试图锁定读锁,并不会阻塞当前的 goroutine。
读写锁适合应用在具有一定并发量且读多写少的场合,在大量并发读的情况下,多个 Goroutine 可以同时持有读锁,从而减少在锁竞争中等待的时间。
sync.RWMutex 实现原理
sync.RWMutex 是基于 Mutex 实现的:
// $GOROOT/src/sync/rwmutex.go
type RWMutex struct {
w Mutex // 互斥锁解决多个writer的竞争
writerSem uint32 // writer信号量
readerSem uint32 // reader信号量
readerCount int32 // 记录当前 reader 的数量,以及是否有 writer 竞争锁
readerWait int32 // 记录 writer 请求锁时需要等待 read 完成的 reader 的数量
}
const rwmutexMaxReaders = 1 << 30 //最大的 reader 数量【sync.WaitGroup】
sync.WaitGroup 上面例子中已经用过了,它是用来做任务编排的,要解决的就是并发等待的问题。Go 标准库中的 WaitGroup 提供了三个方法:
// $GOROOT/src/sync/waitgroup.go
type WaitGroup struct {
noCopy noCopy
state atomic.Uint64
sema uint32
}
func (wg *WaitGroup) Add(delta int) {} //用来设置 WaitGroup 的计数值
func (wg *WaitGroup) Done() {} //用来将 WaitGroup 的计数值减 1,其实就是调用了 Add(-1)
func (wg *WaitGroup) Wait() {} //调用这个方法的 goroutine 会一直阻塞,直到 WaitGroup 的计数值变为 0一般使用 WaitGroup 来记录需要等待的 goroutine 的数量,这个类型的Done方法用于对计数器的值减一,可以在需要等待的 goroutine 中通过defer语句调用;Wait方法用来阻塞当前的 goroutine,直到计数器归零。
现在,直接来看 sync.WaitGroup 是怎么实现阻塞的,它可以替换掉上面例子中一直在使用的 time.Sleep,使用 sync.WaitGroup 之后就可以实现goroutine的阻塞等待了,输出结果也是预期的5000
package main
import (
"fmt"
"time"
)
func test3() {
var mu sync.Mutex
var wg sync.WaitGroup
counter := 0
for i := 0; i < 5000; i++ {
wg.Add(1)
go func() {
defer func() {
mu.Unlock()
}()
mu.Lock()
counter++
wg.Done() //结束阻塞
}()
}
wg.Wait() //开始阻塞
fmt.Println(counter)
}
func main() {
test3()
}
- sync.WaitGroup 中 Add方法的值不可以小于或者等于0,否则会引发 panic: sync: negative WaitGroup counter
- sync.WaitGroup 中 Add方法和Wait方法应该放在同一个 goroutine 中执行。
源代码:https://gitee.com/rxbook/go-demo-2023/tree/master/basic/go03/sync1







![[FMC152]AD9208的2 路2GSPS/2.6GSPS/3GSPS 14bit AD 采集FMC 子卡模块中文版本设计资料及调试经验](https://img-blog.csdnimg.cn/95b43869656246468f0ec948339550d0.png)