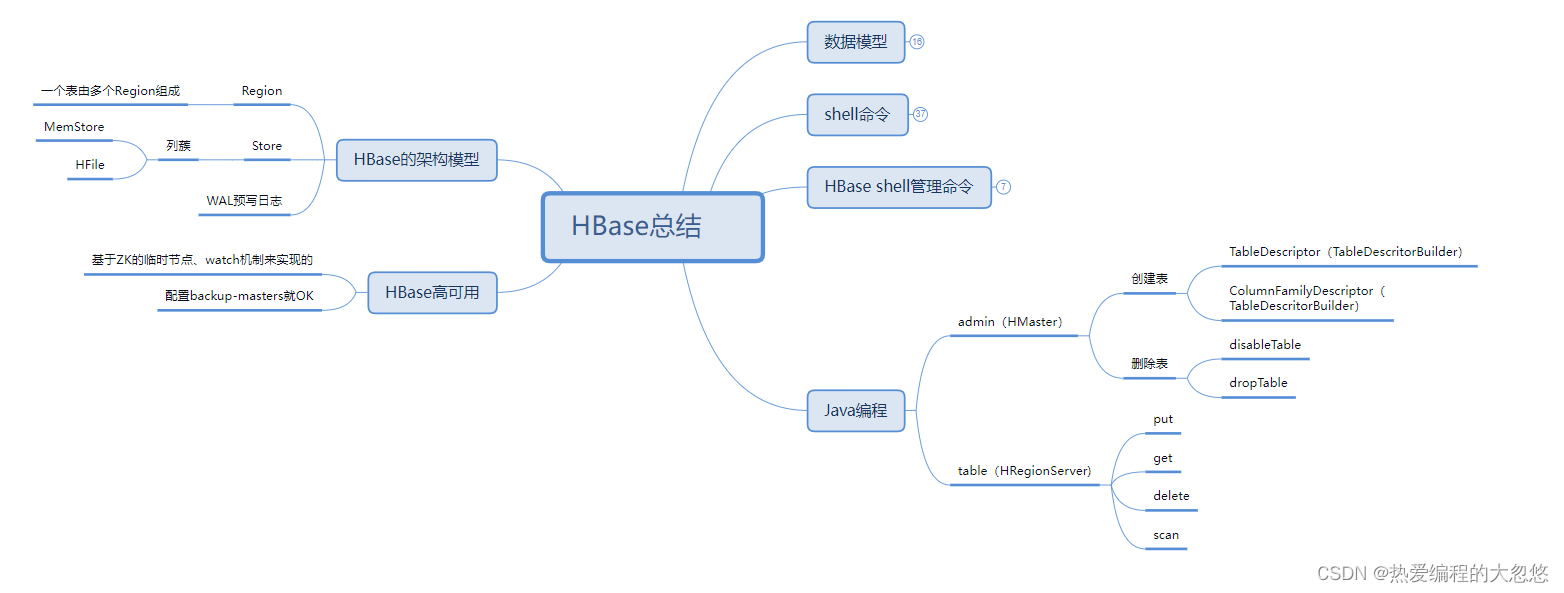
0、前言:
- numpy是生成和处理array类型矩阵数据的工具,而pandas中的series(一维矩阵)和dataframe(二维矩阵)数据类型可以来自numpy生成的数据,pandas的重要之处在于他可以导入和处理多种格式类型的数据,其中还有很多方法可以使用。
1、round函数:
- round函数在series中有,在pandas中也有
- 保留两位小数:df.round(2)
- 对于多列数据采取不同的保留位数:df.round({‘A’: 1, ‘B’: 2}) # A列保留1位,B列保留2位
2、apply函数:
- Series和DataFrame对象均有此方法
- apply函数不支持对多列数据进行操作
- 指定列保留0位小数的百分比:df[‘A’].apply(lambda x: ‘{:.0%}’.format(x))
- 指定列保留2位小数的百分比:df[‘A’].apply(lambda x: ‘{:.2%}’.format(x))
- 指定列设置千位分隔符:df[‘A’].apply(lambda x: ‘{:,}’.format(x) # 设置千分位之后数据就不再是数值了而是字符串
3、applymap函数:
- DataFrame对象的方法,不支持单列的操作
- 指定多列保留小数操作:df[[‘A’, ‘B’, ‘C’]].applymap(lambda x: ‘{:.2%}’.format(x))
- 指定多列设置千分位分隔符:df[[‘A’, ‘B’, ‘C’]].applymap(lambda x: ‘{:,}’.format(x)) # 设置千分位之后数据就不再是数值了而是字符串
4、map方法
- Series对象的方法,不支持多列的操作
- 指定列保留2位小数的百分比:df[‘A’].map(lambda x: ‘{:.2%}’.format(x))
- map主要用于数据映射:比如在数据库中男女用数字1和2表示,如果要进行报表汇报,就要通过map来把1和2映射为男和女:df[‘性别’].map(l{‘男’:1, ‘女’:2})
- 概念1
5、数据分组聚合
-
原始数据表

-
让数据根据一级分类列索引分组,然后统计每个分组中数量列索引的和:df.groupby(‘一级分类’, as_index=False)[‘数量’].sum()

-
多列分组,多列聚合:df.groupby([‘一级分类’, ‘二级分类’])[[‘数量’, ‘金额’]].sum().reset_index()

-
注意分组之后的数据仍然是DataFrame数据类型
6、groupby+agg函数
- agg函数是聚合函数,通过agg函数就能对分组之后的数据有针对性的使用其他函数了。
# 例如:我想要获取一级分类之后,数量的均值,数量的求和值~
df.groupby('一级分类').agg(
数量_均值=('数量', 'mean'),
数量_求和=('数量', 'sum'),
金额_求和=('金额', 'sum'),
金额_均值=('金额', 'mean'))

- 自定义函数分组统计
# 统计频数最高(行计数最多)的二级分类
# 以及总数量和总金额
# df['二级分类'].value_counts():该函数可以获取二级分类中所有数据出现次数由高到低的排序,基于此通过index[0]就能获取最高频次的二级分类数据
df.agg({
'数量': 'sum',
'金额': 'sum',
'二级分类': lambda x: x.value_counts().index[0]
})
# 以一级分类为分组,统计销售数量最多的二级分类
'''
普通方法:
df[df['一级分类'] == '办公'].groupby('二级分类')['数量'].sum().idxmax()
df[df['一级分类'] == '技术'].groupby('二级分类')['数量'].sum().idxmax()
df[df['一级分类'] == '家具'].groupby('二级分类')['数量'].sum().idxmax()
整合语句:
grouped = df.groupby('一级分类') # grouped 数据类型是DataFrameGroupBy,没法直接再次用groupby
grouped.apply(lambda x: x.groupby('二级分类')['数量'].sum().idxmax())
'''
7、groupby+transform函数
- 前言:在 Pandas 中,transform 函数是对 DataFrame 或 Series 的分组数据进行变换的一种方法。它可以返回一个与原始输入数据形状相同的 pandas 数据结构
- transform 函数可以传递一个函数或 lambda 表达式作为参数,在分组操作时对每个小组执行该函数,得到按小组索引对应的输出值(如平均值或标准差等),然后将这些输出值“广播”回原始数据中对应的位置。
# 统计各省的金额以及占所属大区的比例
# 先以大区和省份分组对金额求和
tb = df.groupby(['大区', '省份'])['金额'].sum().reset_index()
# df.groupby(['大区', '省份']).agg({'金额': 'sum'}).reset_index()
# 再以大区分组求和金额,并应用transform得到大区金额
tb['大区金额'] = tb.groupby('大区')['金额'].transform('sum')
tb['金额占比'] = tb['金额'] / tb['大区金额']
tb['金额占比'] = tb['金额占比'].apply(lambda x: '{:.1%}'.format(x))

- 多列合并计算

8、pivot_table透视表
- 前言:这部分知识不太了解,先把一些关键参数记录下来,后面用到了可以参考
# data:DataFrame对象
# values:Excel透视表的值
# index:Excel透视表的行
# columns:Excel透视表的列
# aggfunc:Excel透视表的计算类型
# fill_value:填充空值
# margins:是否显示合计
# dropna:是否删除缺失行(如整行缺失)
# margins_name:合计的别名
# df.pivot_table()
pd.pivot_table(
data=df,
index=['大区', '省份'],
columns='一级分类',
values=['数量', '金额'],
aggfunc={'数量': 'sum', '金额': 'mean'},
margins=True,
margins_name='总计',
fill_value=0,
)
9、crosstab交叉表
- 前言:这部分知识不太了解,先把一些关键参数记录下来,后面用到了可以参考
# index: 行索引,Series对象
# columns: 列索引,Series对象
# values: 聚合字段,Series对象
# rownames: 行索引的别名
# colnames: 列索引的别名
# aggfunc: 聚合函数
# margins: 是否显示合计
# margins_name: 合计的别名
# dropna: 是否删除缺失行(如整行缺失)
# normalize: Excel透视表“值显示方式”
# normalize=True,总计百分比
# normalize='all',总计百分比
# normalize='index',行汇总百分比
# normalize='columns',列汇总百分比
pd.crosstab(
index=df['大区'],
columns=df['一级分类'],
values=df['数量'],
aggfunc='sum',
margins_name='总计',
normalize='columns'
)

![[FMC152]AD9208的2 路2GSPS/2.6GSPS/3GSPS 14bit AD 采集FMC 子卡模块中文版本设计资料及调试经验](https://img-blog.csdnimg.cn/95b43869656246468f0ec948339550d0.png)