模型介绍
Alpaca模型是斯坦福大学研发的LLM(Large Language Model,大语言)开源模型,是一个在52K指令上从LLaMA 7B(Meta公司开源的7B)模型微调而来,具有70亿的模型参数(模型参数越大,模型的推理能力越强,当然随之训练模型的成本也就越高)。
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术。如果想让一个预训练大语言模型能够执行特定领域内的任务,一般需要做fine-tuning,但是目前推理效果好的大语言模型参数维度非常非常大,有些甚至是上千亿维,如果直接在大语言模型上做fine-tuning,计算量会非常的大,成本也会非常的高。
’LoRA的做法是冻结预训练好的模型参数,然后在每个Transformer块里注入可训练的层,由于不需要对模型的参数重新计算梯度,所以,会大大的减少计算量。
具体如下图所示,核心思想是在原始预训练模型增加一个旁路,做一个降维再升维的操作。训练的时候固定预训练模型的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与预训练语言模型的参数叠加。

用随机高斯分布初始化 A,用 0 矩阵初始化 B。这样能保证训练时,新增的旁路BA=0,从而对模型结果没有影响。在推理时,将左右两部分的结果加到一起,即h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。LoRA 的最大优势是训练速度更快,使用的内存更少。
本文进行本地化部署实践的Alpaca-lora模型就是Alpaca模型的低阶适配版本。本文将对Alpaca-lora模型本地化部署、微调和推理过程进行实践并描述相关步骤。
GPU服务器环境部署
本文进行部署的GPU服务器具有4块独立的GPU,型号是P40,单个P40算力相当于60个同等主频CPU的算力。(也可以考虑使用京东云GPU的P40,
jdcloud.com/cn/calculator/calHost))
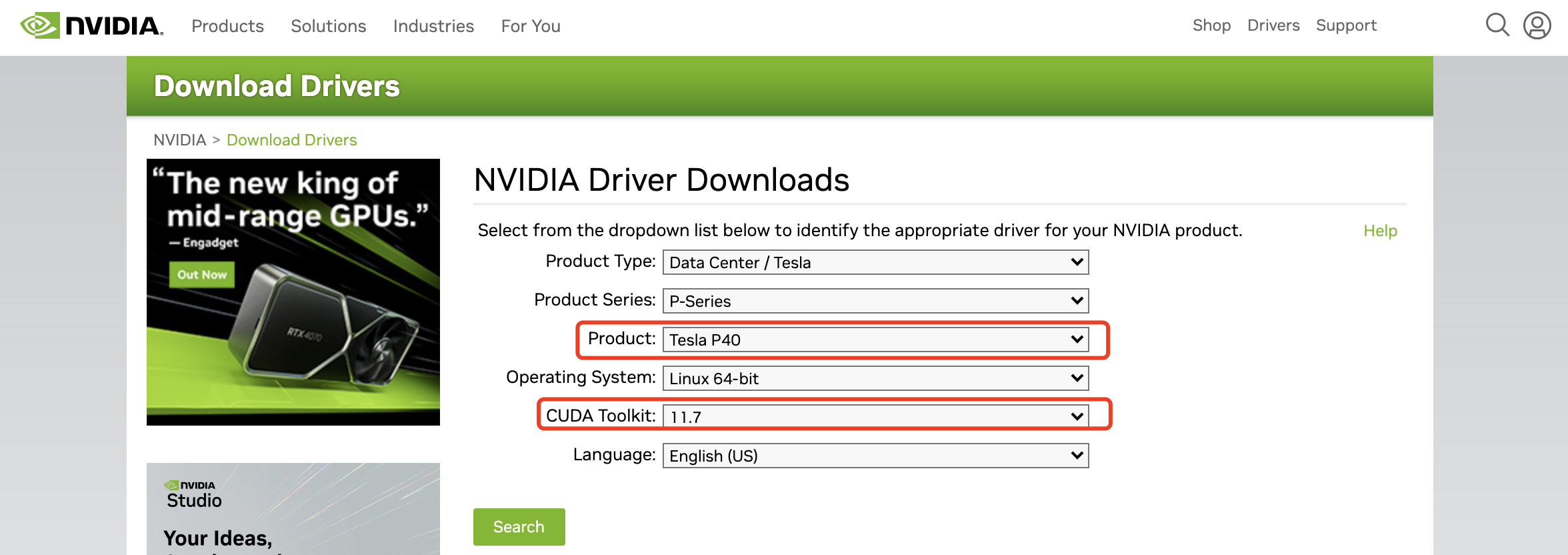
拿到GPU服务器我们首先就是安装显卡驱动和CUDA驱动(是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题)。显卡驱动需要到NVIDIA的官方网站去查找相应的显卡型号和适配的CUDA版本,下载地址:
https://www.nvidia.com/Download/index.aspx ,选择相应的显卡和CUDA版本就可以下载驱动文件啦。
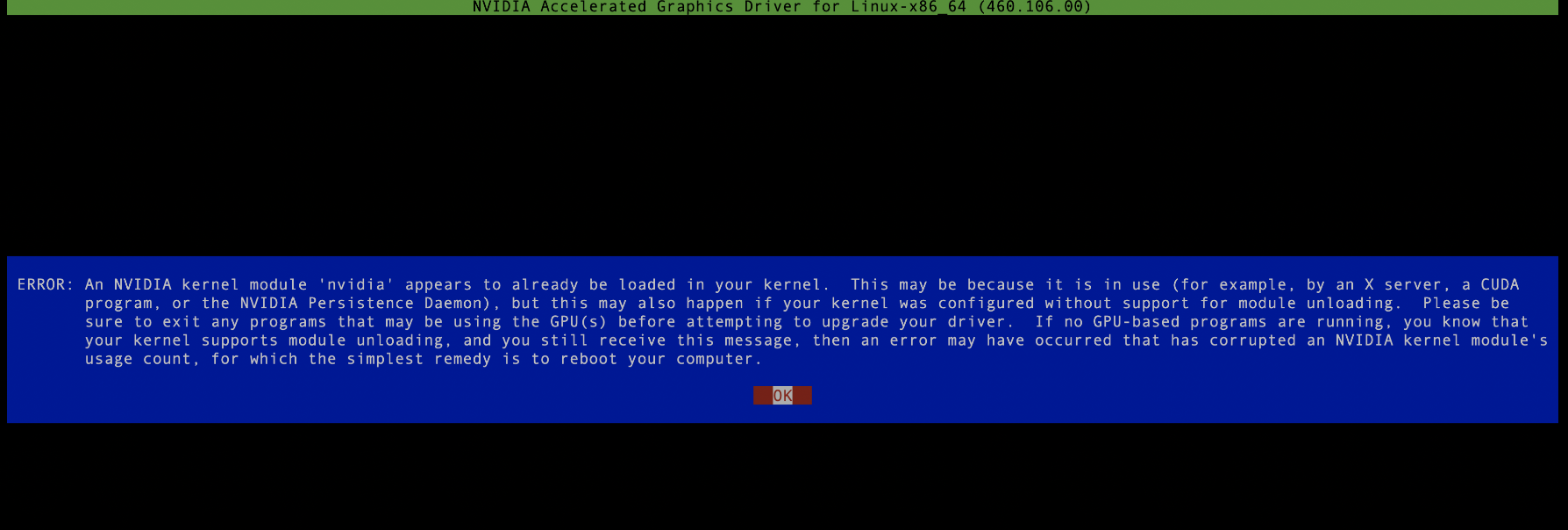
我下载的文件是NVIDIA-Linux-x86_64-515.105.01.run,这是一个可执行文件,用root权限执行即可,注意安装驱动过程中不能有运行的nvidia进程,如果有需要全部kill掉,否则会安装失败,如下图所示:
然后一路next,没有报错的话就安装成功啦。为了后续查看显卡资源情况,最好还是再安装一个显卡监控工具,比如nvitop,用pip install nvitop即可,这里注意,由于不同服务器python版本有差异,最好安装anaconda部署自己的私有python空间,防止运行时报各种奇怪的错误,具体步骤如下:
1.安装anaconda 下载方式:wget
https://repo.anaconda.com/archive/Anaconda3-5.3.0-Linux-x86_64.sh。 安装命令: shAnaconda3-5.3.0-Linux-x86_64.sh 每个安装步骤都输入“yes”,最后conda init后完成安装,这样每次进入安装用户的session,都会直接进入自己的python环境。如果安装最后一步选择no,即不进行conda init,则后续可以通过source/home/jd_ad_sfxn/anaconda3/bin/activate来进入到私有的python环境。
2.安装setuptools 接下来需要安装打包和分发工具setuptools,下载地址:wget
https://files.pythonhosted.org/packages/26/e5/9897eee1100b166a61f91b68528cb692e8887300d9cbdaa1a349f6304b79/setuptools-40.5.0.zip 安装命令: unzip setuptools-40.5.0.zip cd setuptools-40.5.0/ python setup.py install
3.安装pip 下载地址:wget
https://files.pythonhosted.org/packages/45/ae/8a0ad77defb7cc903f09e551d88b443304a9bd6e6f124e75c0fbbf6de8f7/pip-18.1.tar.gz 安装命令: tar -xzf pip-18.1.tar.gz cd pip-18.1 python setup.py install
至此,漫长的安装过程终于告一段落了,我们现在创建一个私有的python空间,执行
conda create -n alpaca python=3.9
conda activate alpaca
然后验证一下,如下图所示说明已经创建成功啦。

模型训练
上文已经把GPU服务器的基础环境安装好了,下面我们就要开始激动人心的模型训练了(激动ing),在训练之前我们首先需要下载模型文件,下载地址:
https://github.com/tloen/alpaca-lora ,整个模型都是开源的,真好!首先把模型文件下载到本地,执行git clonehttps://github.com/tloen/alpaca-lora.git .。
本地会有文件夹alpaca-lora,然后cd alpaca-lora到文件夹内部执行
pip install -r requirements.txt
这个过程可能会比较慢,需要从网上下载大量的依赖包,过程中可能也会报各种包冲突,依赖没有等问题,这块只能见招拆招,缺什么装什么(解决包依赖和版本冲突确实是个头疼的事情,不过这步做不好,模型也跑不起来,所以只能耐心的一点一点解决),这里痛苦的过程就不赘述了,因为不同机器可能遇到的问题也不太一样,参考意义不是很大。
如果安装过程执行完成,并没再有报错信息,并提示Successful compeleted,那么恭喜你啦,万里长征已经走完一半啦,你已经离成功很近了,再坚持一下下就很有可能成功啦:)。
由于我们的目标是对模型进行fine-tuning,所以我们得有一个fine-tuning的目标,由于原始模型对中文支持并不好,所以我们的目标就有了,用中文语料库让模型更好的支持中文,这个社区也给我准备好了,我们直接下载中文的语料库就好了,在本地执行 wget
https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.json?raw=true ,将后面模型训练用到的语料库下载到alpaca-lora根目录下(后面方便使用)。
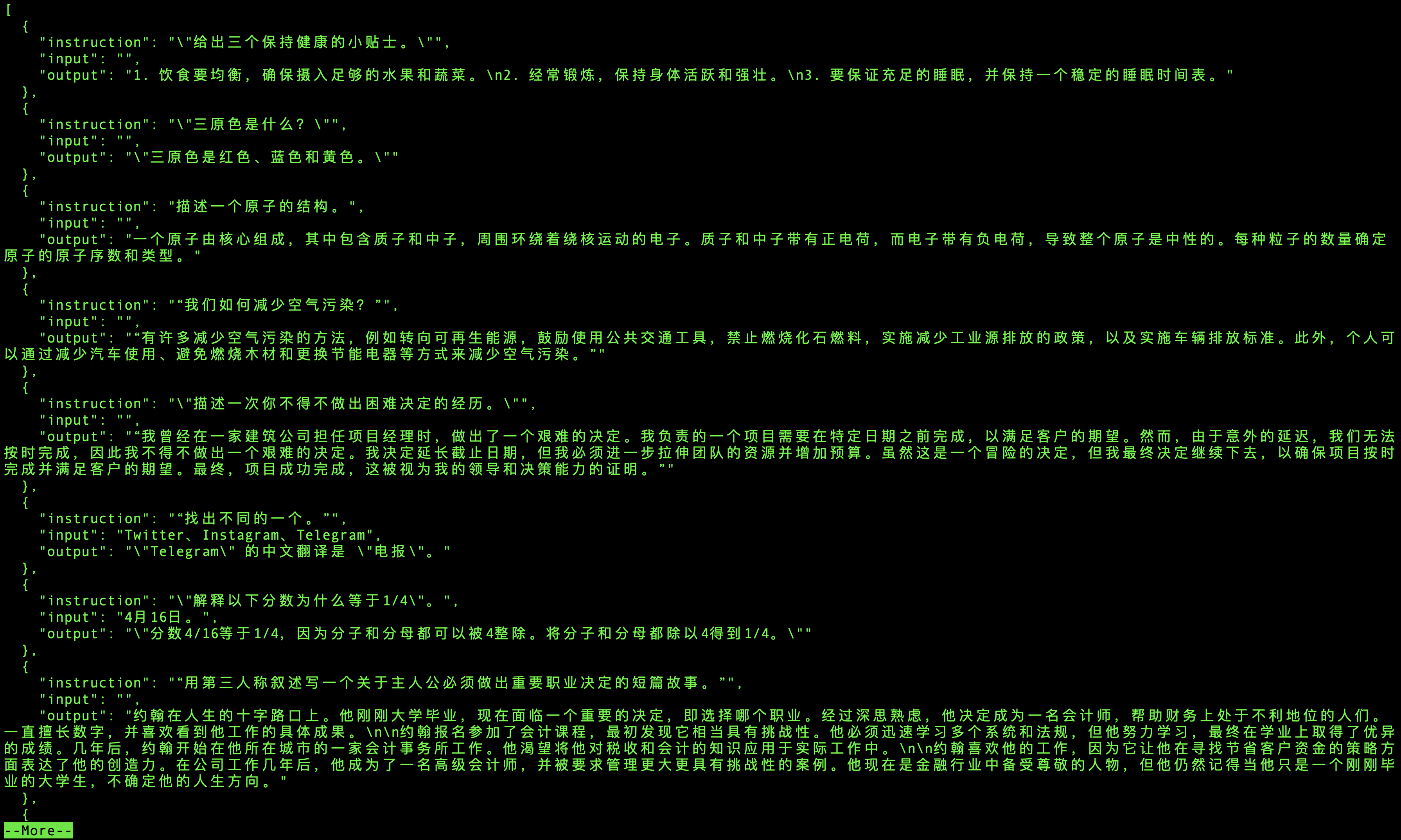
语料库的内容就是很多的三元组(instruction,input,output,如下图所示),instruction就是指令,让模型做什么事,input就是输入,output是模型的输出,根据指令和输入,训练模型应该输出什么信息,让模型能够更好的适应中文。
好的,到现在为止,万里长征已经走完2/3了,别着急训练模型,我们现在验证一下GPU环境和CUDA版本信息,还记得之前我们安装的nvitop嘛,现在就用上了,在本地直接执行nvitop,我们就可以看到GPU环境和CUDA版本信息了,如下图:

在这里我们能够看到有几块显卡,驱动版本和CUDA版本等信息,当然最重要的我们还能看到GPU资源的实时使用情况。
怎么还没到模型训练呢,别着急呀,这就来啦。
我们先到根目录下然后执行训练模型命令:
如果是单个GPU,那么执行命令即可:
python finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'trans_chinese_alpaca_data.json' \
--output_dir './lora-alpaca-zh'
如果是多个GPU,则执行:
WORLD_SIZE=2 CUDA_VISIBLE_DEVICES=0,1 torchrun \
--nproc_per_node=2 \
--master_port=1234 \
finetune.py \
--base_model 'decapoda-research/llama-7b-hf' \
--data_path 'trans_chinese_alpaca_data.json' \
--output_dir './lora-alpaca-zh'
如果可以看到进度条在走,说明模型已经启动成功啦。

在模型训练过程中,每迭代一定数量的数据就会打印相关的信息,会输出损失率,学习率和代信息,如上图所示,当loss波动较小时,模型就会收敛,最终训练完成。
我用的是2块GPU显卡进行训练,总共训练了1904分钟,也就是31.73个小时,模型就收敛了,模型训练是个漫长的过程,所以在训练的时候我们可以适当的放松一下,做点其他的事情:)。

模型推理
模型训练好后,我们就可以测试一下模型的训练效果了,由于我们是多个GPU显卡,所以想把模型参数加载到多个GPU上,这样会使模型推理的更快,需要修改
generate.py 文件,添加下面这样即可。

然后我们把服务启起来,看看效果,根目录执行:
python generate.py --base_model "decapoda-research/llama-7b-hf" \
--lora_weights './lora-alpaca-zh' \
--load_8bit
其中./lora-alpaca-zh目录下的文件,就是我们刚刚fine tuning模型训练的参数所在位置,启动服务的时候把它加载到内存(这个内存指的是GPU内存)里面。
如果成功,那么最终会输出相应的IP和Port信息,如下图所示:

我们可以用浏览器访问一下看看,如果能看到页面,就说明服务已经启动成功啦。

激动ing,费了九牛二虎之力,终于成功啦!!
因为我们目标是让模型说中文,所以我们测试一下对中文的理解,看看效果怎么样?
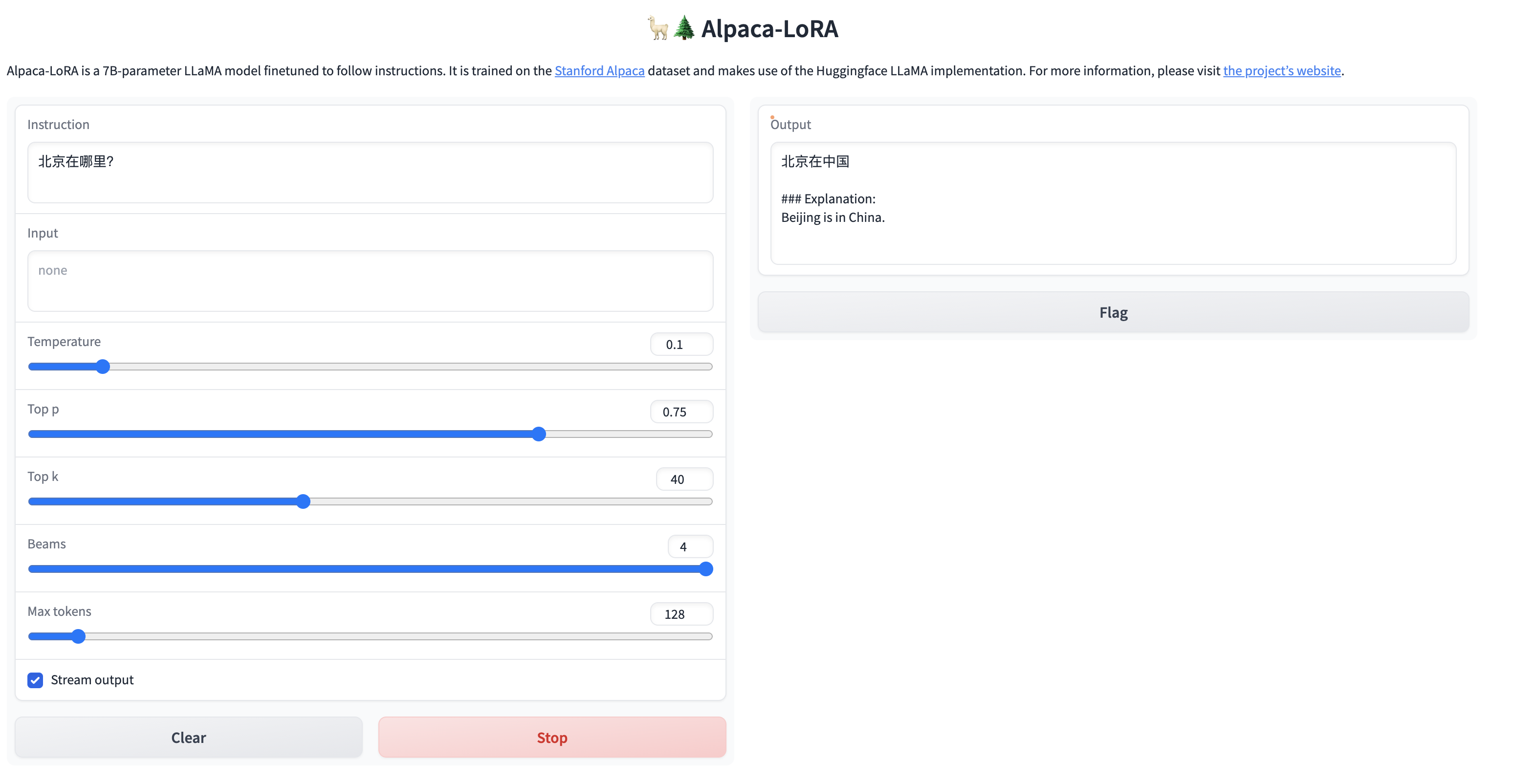

简单的问题,还是能给出答案的,但是针对稍微复杂一点的问题,虽然能够理解中文,但是并没有用中文进行回答,训练后的模型还是不太稳定啊。
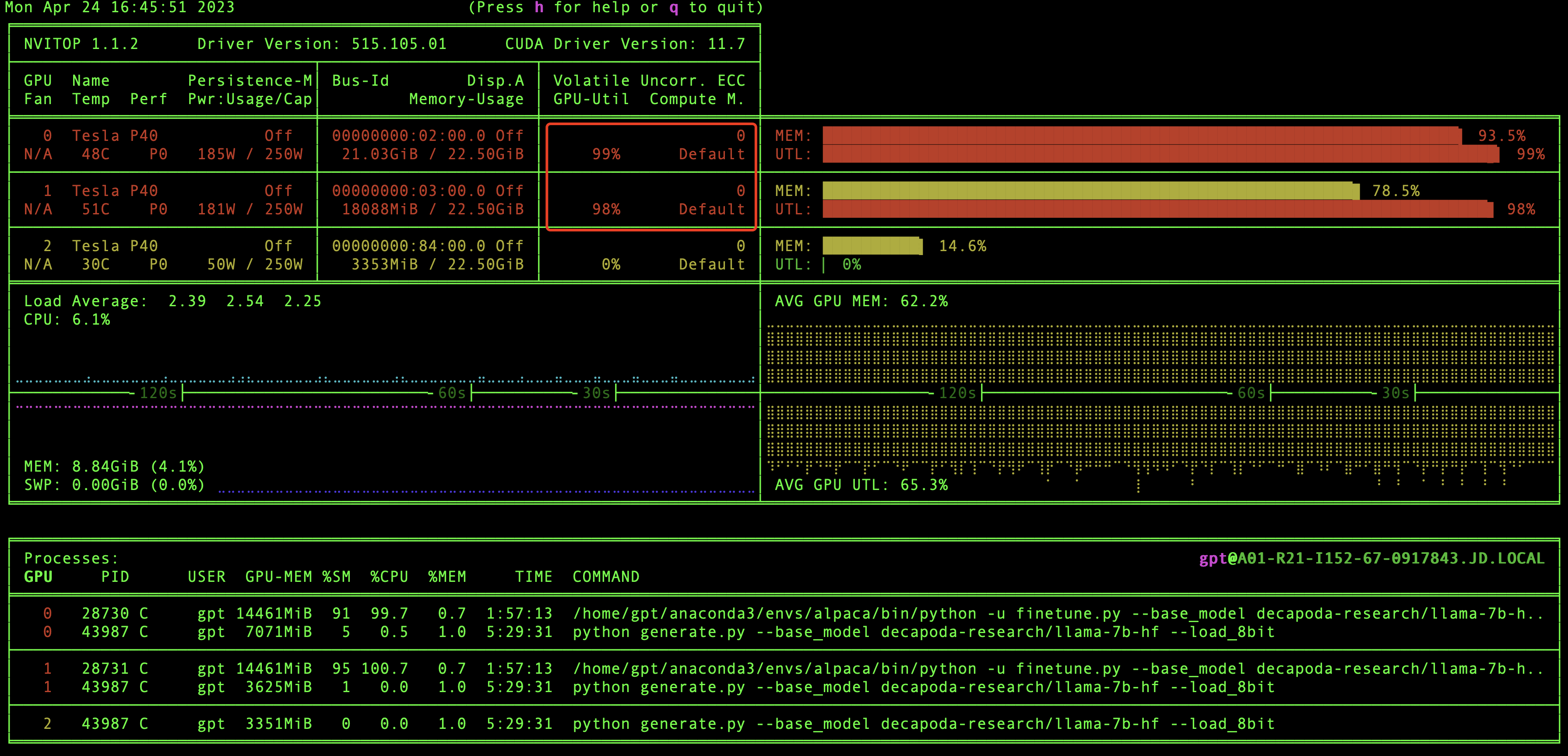
在推理的时候我们也可以监控一下GPU的变化,可以看到GPU负载是比较高的,说明GPU在进行大量的计算来完成推理。
总结
1.效果问题:由于语料库不够丰富,所以目前用社区提供的语料库训练的效果并不是很好,对中文的理解力有限,如果想训练出能够执行特定领域的任务,则需要大量的语料支持,同时训练时间也会更长;
2. 推理时间问题:由于目前部署的GPU服务器有4块GPU,能够执行的有3块,基于3块GPU,在推理的时候还是比较吃力的,执行一次交互需要大概30s-1min,如果达到chatGPT那样实时返回,则需要大量的算力进行支持,可以反推,chatGPT后台肯定是有大集群算力支持的,所以如果想做成服务,成本投入是需要考量的一个问题;
3. 中文乱码问题:在input为中文的时候,有时候返回结果会乱码,怀疑跟切词有关,由于中文的编码问题,中文不像英文以空格区分,所以可能会有一定的乱码情况产生,调用open AI 的API也会有这种情况,后面看看社区是否有相应解决办法;
4. 模型选择问题:由于目前GPT社区比较活跃,模型的产生和变化也是日新月异,由于时间仓促,目前只调研了alpaca-lora模型的本地化部署,后面针对实际落地的应用应该也会有更好的更低成本的落地方案,需要持续跟进社区的发展,选择合适的开源方案。
作者:Beyond_luo
内容来源:京东云开发者社区

![[FMC152]AD9208的2 路2GSPS/2.6GSPS/3GSPS 14bit AD 采集FMC 子卡模块中文版本设计资料及调试经验](https://img-blog.csdnimg.cn/95b43869656246468f0ec948339550d0.png)