目录
一. 什么是哈希桶
二. 哈希桶的实现
2.1 哈希表节点数据
2.2 特定Key值的查找find
2.3 哈希桶的扩容
2.4 数据插入操作insert
2.5 数据删除操作erase
2.6 哈希桶的析构函数
附录:哈希桶的实现完整版代码
一. 什么是哈希桶
之前的博客中我提到过,可以采用闭散列(二次探测、线性探测)的方法来解决哈希冲突,但是,无论是线性探测还是二次探测,其解决哈希冲突的本质方法都是去“占位”,即:发生哈希冲突的Key会去占用其他Key值原本应当占用的位置,这样一个冲突可能引发一串冲突。
为了解决闭散列方法的上述弊端,可以使用哈希桶(开散列)的方法来解决哈希冲突。在hashTable的每个位置都挂一个哈希桶,哈希桶用单链表来表示。将所有发生冲突的数据都挂在一个桶上。
此时,hashTable存储的数据类型时单链表节点,hashTable[i]是每个哈希桶的头结点,发生冲突时的数据插入相当于单链表的头插操作。

二. 哈希桶的实现
2.1 哈希表节点数据
由于哈希桶的本质是挂在哈希表上的单链表,因此,哈希表节点的数据应当为单链表节点,包括:
- 一个键值对pair<K, V> _kv,记录key值和与之配对的value值。
- 一个节点指针_next,指向单链表的下一个节点。
在Hash类模板中,将hashDate<K, V>类型重定义为Node。
代码2.1:(哈希表节点)
template<class K, class V>
struct hashDate
{
std::pair<K, V> _kv;
hashDate<K, V>* _next;
hashDate(const std::pair<K, V>& kv)
: _kv(kv)
, _next(nullptr)
{ }
};2.2 特定Key值的查找find
函数Node* find(const K& key),找到了返回key所在的节点地址,找不到返回nullptr。
- 通过哈希函数,获取key所在的哈希桶应当挂在_hashTable哪个下标位置处(记为hashi)。
- 遍历以_hashTable[hashi]为头结点的单链表,查找key,找到了返回链表节点。
- 如果遍历到nullptr还没找到,则表示key不存在于哈希桶中,函数返回false。
代码2.2:(find函数的实现)
Node* find(const K& key)
{
//哈希表中没有数据就直接返回false
//这里是为了避免模0(%0)错误
if (_hashTable.size() == 0)
{
return nullptr;
}
HashKey hashKey;
//通过哈希函数计算key所在哈希桶
size_t hashi = hashKey(key) % _hashTable.size();
//哈希桶单链表头结点
Node* cur = _hashTable[hashi];
//变量哈希桶(单链表),寻找key
while (cur)
{
if (hashKey(cur->_kv.first) == hashKey(key))
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}2.3 哈希桶的扩容
如果通过闭散列(线性探测或二次探测)的方法来解决哈希冲突,那么哈希表中存储的数据个数_size一定不能超过_table.size()。但是如果使用哈希桶,哈希表的每个位置挂的哈希桶可以有多个数据,因此负载因子是可以大于1的。
闭散列一般当负载因子大于0.7~0.8是扩容,而哈希桶则应适度提高。可以认为当插入数据后负载因子大于1就扩容。
哈希桶扩容同样需要改变原来的结构,因为不同的Key值对于的存储位置会发生改变。这里不再复用insert函数来实现数据位置的改变,而是依次遍历每个哈希桶的每个节点,创建一个新的vector作为hashTable,通过单链表头插,来使数据满足扩容后的哈希结构要求。
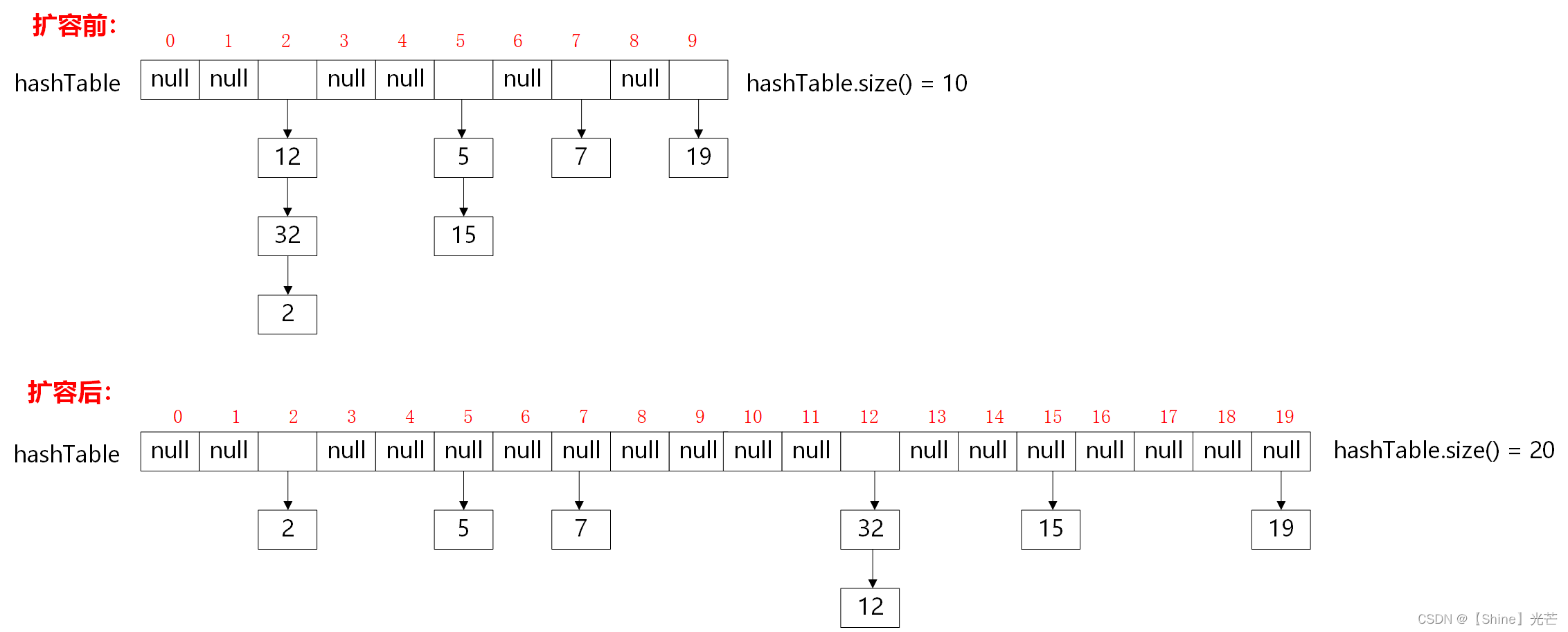
代码2.3:(哈希表扩容)
//扩容(负载因子大于1)
if (_hashTable.size() == 0 || _size == _hashTable.size())
{
size_t newSize = _hashTable.size() == 0 ? 10 : 2 * _hashTable.size();
//将原来哈希表数据的位置进行相应改变
//这里使用一个新的vector来实现
std::vector<Node*> newTable;
newTable.resize(newSize, nullptr);
//将原来table每个位置处挂的单链表,挪到新的table对应位置
for (size_t i = 0; i < _hashTable.size(); ++i)
{
Node* cur = _hashTable[i];
while (cur)
{
Node* next = cur->_next;
size_t newHashi = hashKey(cur->_kv.first) % newSize;
//执行头插操作
cur->_next = newTable[newHashi];
newTable[newHashi] = cur;
cur = next;
}
_hashTable[i] = nullptr;
}
_hashTable.swap(newTable);
}2.4 数据插入操作insert
哈希桶是挂在hashTable指定位置处的单链表。进行数据插入时,只需在检查数据是否已经存在、是否需要扩容之后,要通过哈希函数Hash(Key)找到对应的位置,然后执行单链表头插操作即可。
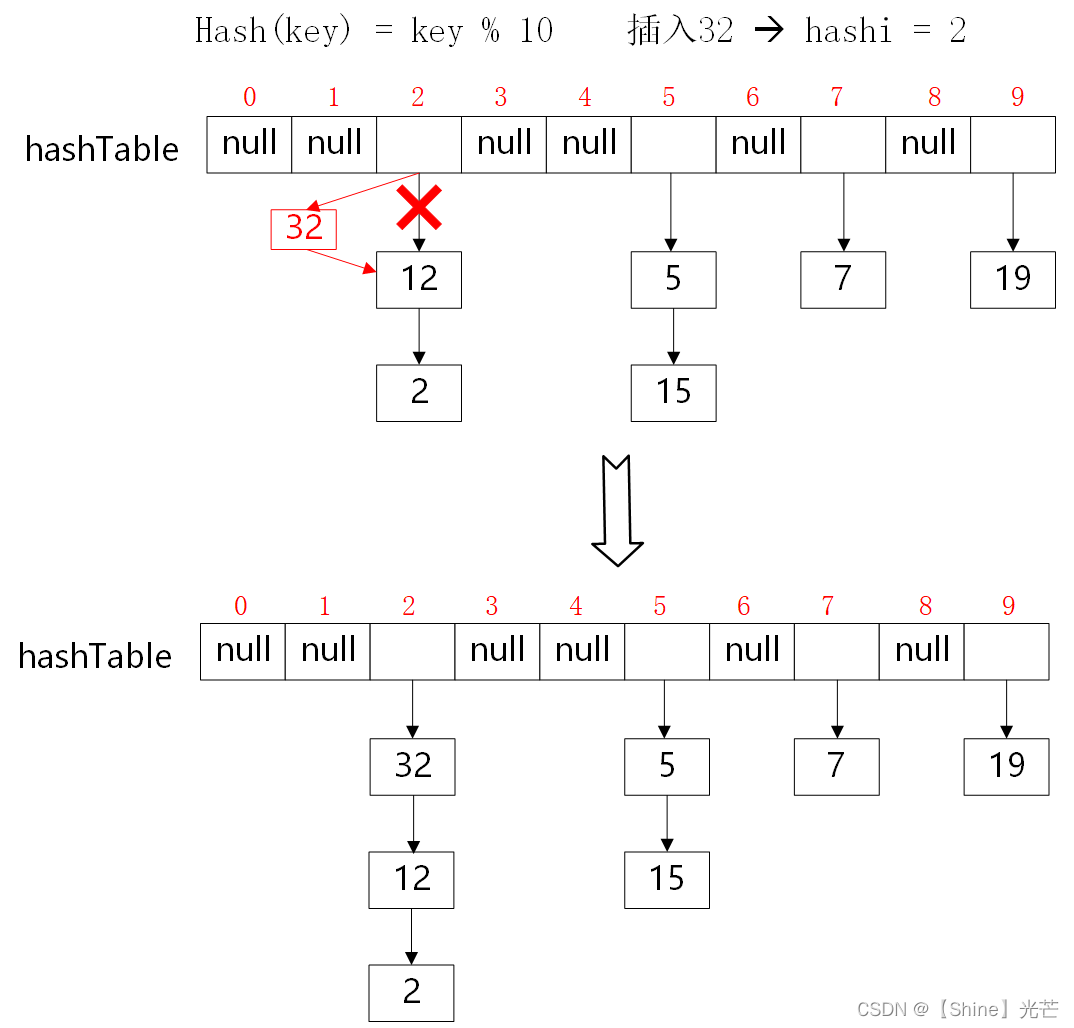
2.5 数据删除操作erase
通过哈希函数获得哈希桶的位置后,遍历单链表(哈希桶)找到key所在的位置,执行单链表节点删除操作即可。
代码2.5:(数据删除)
bool erase(const K& key)
{
if (_hashTable.size() == 0)
{
return false;
}
HashKey hashKey;
size_t hashi = hashKey(key) % _hashTable.size();
Node* prev = nullptr;
Node* cur = _hashTable[hashi];
while (cur)
{
//找到key了,删除
if (hashKey(cur->_kv.first) == key)
{
//头删
if (prev == nullptr)
{
_hashTable[hashi] = cur->_next;
free(cur);
cur = nullptr;
}
else //中间删或尾删
{
prev->_next = cur->_next;
free(cur);
cur = nullptr;
}
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}2.6 哈希桶的析构函数
自己编写代码,依次对每个哈希桶进行释放,每个哈希桶的析构等同于单链表的析构。由于vector为自定义类型数据,编译的会主动调用vector的析构函数释放hashTable的空间。
代码2.6:(析构函数)
~Hash() //析构函数
{
//释放每个节点上挂的数据
for (size_t i = 0; i < _hashTable.size(); ++i)
{
Node* cur = _hashTable[i];
//释放每个非空节点
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_hashTable[i] = nullptr;
}
}附录:哈希桶的实现完整版代码
#include<vector>
template<class K, class V>
struct hashDate
{
std::pair<K, V> _kv;
hashDate<K, V>* _next;
hashDate(const std::pair<K, V>& kv)
: _kv(kv)
, _next(nullptr)
{ }
};
template<class K>
struct HashKeyVal
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<class K, class V, class HashKey = HashKeyVal<K>>
class Hash
{
typedef hashDate<K, V> Node;
public:
~Hash() //析构函数
{
//释放每个节点上挂的数据
for (size_t i = 0; i < _hashTable.size(); ++i)
{
Node* cur = _hashTable[i];
//释放每个非空节点
while (cur)
{
Node* next = cur->_next;
delete cur;
cur = next;
}
_hashTable[i] = nullptr;
}
}
bool insert(const std::pair<K, V>& kv)
{
//查找 -- 确保不插入重复数据
if (find(kv.first))
{
return false;
}
HashKey hashKey;
//扩容(负载因子大于1)
if (_hashTable.size() == 0 || _size == _hashTable.size())
{
size_t newSize = _hashTable.size() == 0 ? 10 : 2 * _hashTable.size();
//将原来哈希表数据的位置进行相应改变
//这里使用一个新的vector来实现
std::vector<Node*> newTable;
newTable.resize(newSize, nullptr);
//将原来table每个位置处挂的单链表,挪到新的table对应位置
for (size_t i = 0; i < _hashTable.size(); ++i)
{
Node* cur = _hashTable[i];
while (cur)
{
Node* next = cur->_next;
size_t newHashi = hashKey(cur->_kv.first) % newSize;
//执行头插操作
cur->_next = newTable[newHashi];
newTable[newHashi] = cur;
cur = next;
}
_hashTable[i] = nullptr;
}
_hashTable.swap(newTable);
}
//获取插入位置
size_t hashi = hashKey(kv.first) % _hashTable.size();
Node* node = new Node(kv);
//插入数据
node->_next = _hashTable[hashi];
_hashTable[hashi] = node;
++_size;
}
bool erase(const K& key)
{
if (_hashTable.size() == 0)
{
return false;
}
HashKey hashKey;
size_t hashi = hashKey(key) % _hashTable.size();
Node* prev = nullptr;
Node* cur = _hashTable[hashi];
while (cur)
{
//找到key了,删除
if (hashKey(cur->_kv.first) == key)
{
//头删
if (prev == nullptr)
{
_hashTable[hashi] = cur->_next;
free(cur);
cur = nullptr;
}
else //中间删或尾删
{
prev->_next = cur->_next;
free(cur);
cur = nullptr;
}
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
Node* find(const K& key)
{
//哈希表中没有数据就直接返回false
//这里是为了避免模0(%0)错误
if (_hashTable.size() == 0)
{
return nullptr;
}
HashKey hashKey;
//通过哈希函数计算key所在哈希桶
size_t hashi = hashKey(key) % _hashTable.size();
//哈希桶单链表头结点
Node* cur = _hashTable[hashi];
//变量哈希桶(单链表),寻找key
while (cur)
{
if (hashKey(cur->_kv.first) == hashKey(key))
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}
private:
size_t _size = 0; //哈希表中数据个数
std::vector<Node*> _hashTable; //哈希表(存储桶节点)
};