哈希
- unordered系列关联式容器
- unordered_set与unordered_map
- set VS unordered_set
- 底层结构
- 哈希概念与哈希冲突
- 哈希冲突的解决
- 闭散列——开放定址法
- 开散列——哈希桶
- 模拟实现unordered_set与unordered_map
- 其他哈希函数
- 哈希的应用
- 哈希切割(面试题)
- 位图
- 位图应用(面试题)
- 布隆过滤器
- 布隆过滤器的优缺点
- 布隆过滤器应用(面试题)
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到
l
o
g
2
N
log_2N
log2N,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。
最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是
其底层结构不同。
unordered_set与unordered_map
unordered_set文档
template < class Key, // unordered_set::key_type/value_type
class Hash = hash, // unordered_set::hasher
class Pred = equal_to, // unordered_set::key_equal
class Alloc = allocator // unordered_set::allocator_type
class unordered_set;

#include<iostream>
#include<unordered_set>
using namespace std;
int main()
{
unordered_set<int>us;
us.insert(3);
us.insert(4);
us.insert(2);
us.insert(3);
us.insert(0);
for (auto e : us)
{
cout << e << " ";
}
cout << endl;
return 0;
}
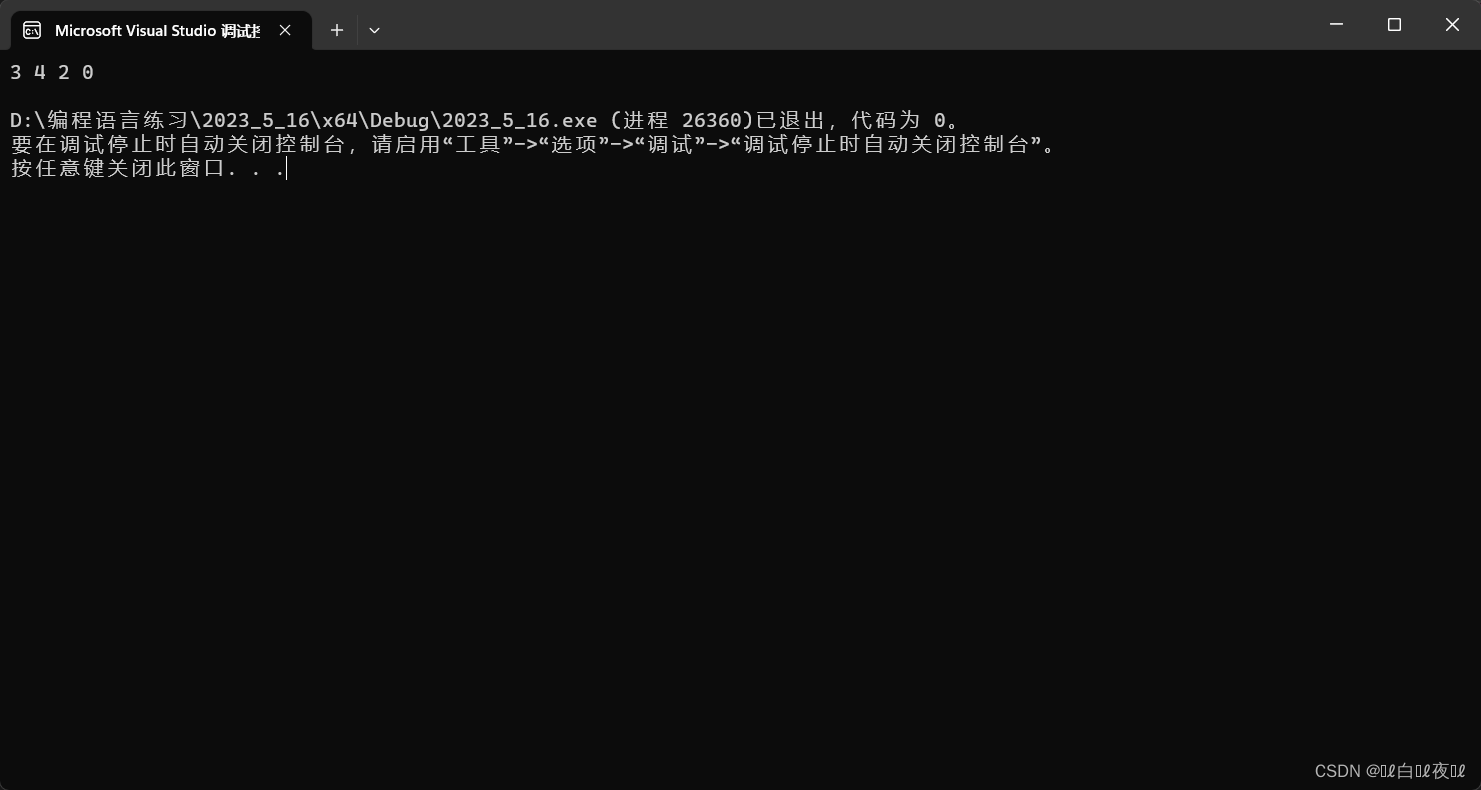
这里是无序的。
unordered_map文档
template < class Key, // unordered_map::key_type
class T, // unordered_map::mapped_type
class Hash = hash, // unordered_map::hasher
class Pred = equal_to, // unordered_map::key_equal
class Alloc = allocator< pair<const Key,T> > // unordered_map::allocator_type
class unordered_map;

set VS unordered_set
这里用几组测试用例来看看它们的各大接口效率。
插入效率
#include<iostream>
#include<unordered_set>
#include<set>
#include<vector>
#include<ctime>
using namespace std;
int main()
{
const size_t N = 100000;
unordered_set<int>arr1;
set<int>arr2;
vector<int>arr;
arr.reserve(N);
srand(time(0));
for (int i = 0; i < N; i++)
{
arr.push_back(rand());
}
size_t begin1 = clock();
for (auto e : arr)
{
arr1.insert(e);
}
size_t end1 = clock();
size_t begin2 = clock();
for (auto e : arr)
{
arr2.insert(e);
}
size_t end2 = clock();
cout << "unordered_set:" << end1 - begin1 << endl;
cout << "set:" << end2 - begin2 << endl;
}
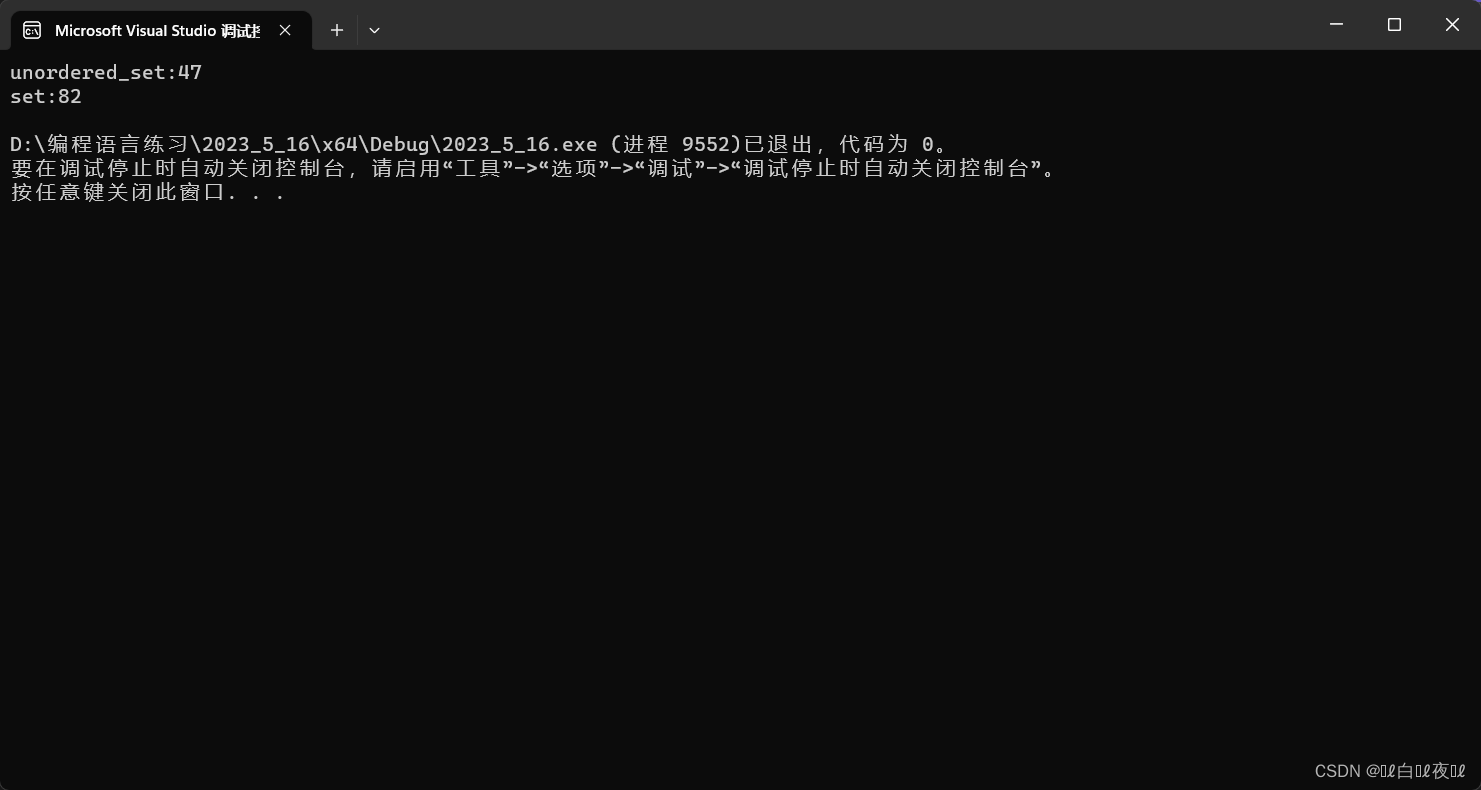
这里set更慢一些,因为插入的是随机值,如果是有序的,set速度会比unordered_set更快一些。
查找效率
#include<iostream>
#include<unordered_set>
#include<set>
#include<vector>
#include<ctime>
using namespace std;
int main()
{
const size_t N = 100000;
unordered_set<int>arr1;
set<int>arr2;
vector<int>arr;
arr.reserve(N);
srand(time(0));
for (int i = 0; i < N; i++)
{
arr.push_back(rand());
}
size_t begin1 = clock();
for (auto e : arr)
{
arr1.insert(e);
}
size_t end1 = clock();
size_t begin2 = clock();
for (auto e : arr)
{
arr2.insert(e);
}
size_t end2 = clock();
cout << "unordered_set:" << end1 - begin1 << endl;
cout << "set:" << end2 - begin2 << endl;
size_t begin3 = clock();
for (auto e : arr)
{
arr1.find(e);
}
size_t end3 = clock();
size_t begin4 = clock();
for (auto e : arr)
{
arr2.find(e);
}
size_t end4 = clock();
cout << "unordered_set:" << end3 - begin3 << endl;
cout << "set:" << end4 - begin4 << endl;
}

把数组里面的数再多加一点,变成一百万。
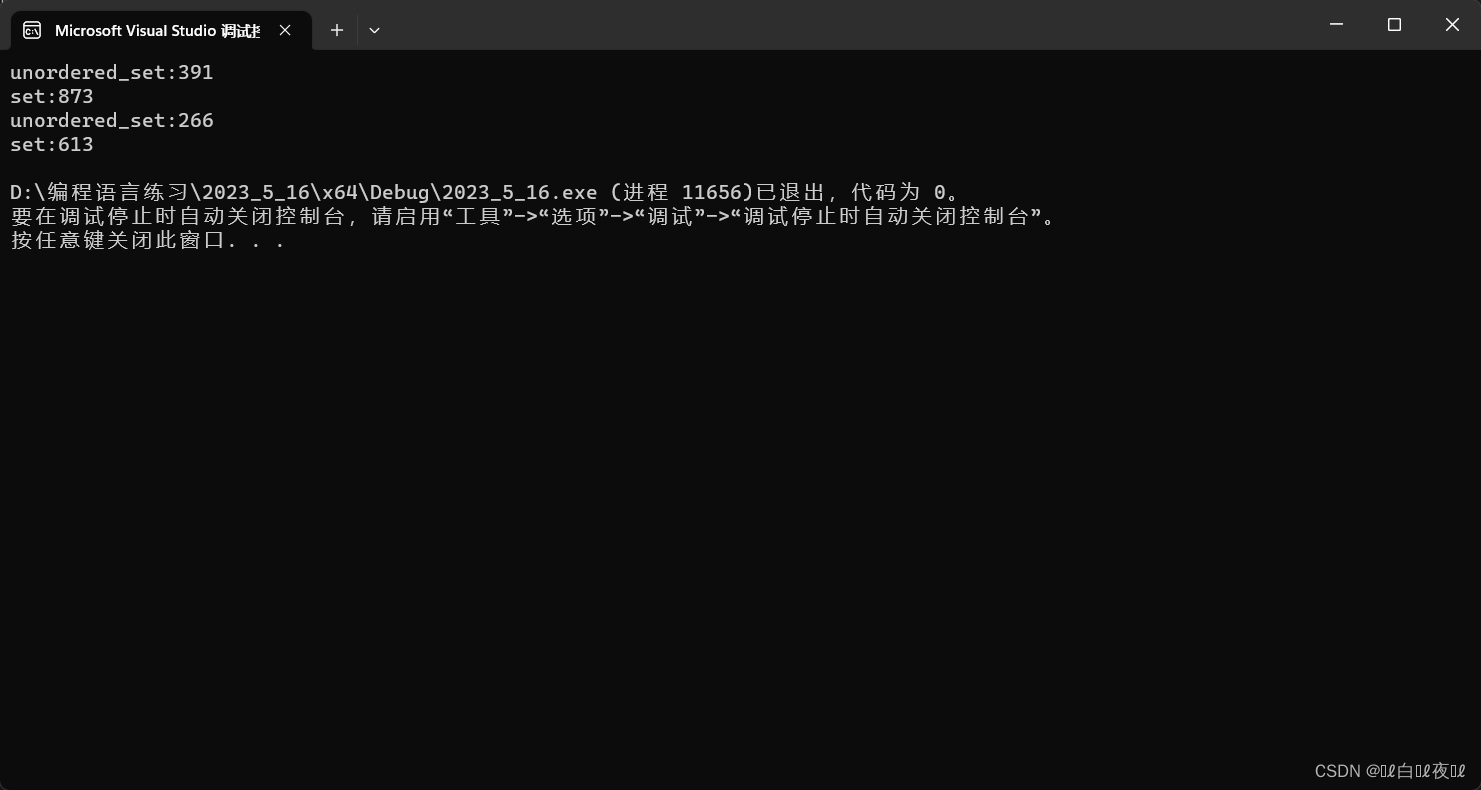
这里就算set里面是最平衡的数据(插入的时候都是有序数组),查找的效率也是不如unordered_set。
删除效率
#include<iostream>
#include<unordered_set>
#include<set>
#include<vector>
#include<ctime>
using namespace std;
int main()
{
const size_t N = 1000000;
unordered_set<int>arr1;
set<int>arr2;
vector<int>arr;
arr.reserve(N);
srand(time(0));
for (int i = 0; i < N; i++)
{
arr.push_back(rand());
}
size_t begin1 = clock();
for (auto e : arr)
{
arr1.insert(e);
}
size_t end1 = clock();
size_t begin2 = clock();
for (auto e : arr)
{
arr2.insert(e);
}
size_t end2 = clock();
cout << "unordered_set:" << end1 - begin1 << endl;
cout << "set:" << end2 - begin2 << endl;
size_t begin3 = clock();
for (auto e : arr)
{
arr1.find(e);
}
size_t end3 = clock();
size_t begin4 = clock();
for (auto e : arr)
{
arr2.find(e);
}
size_t end4 = clock();
cout << "unordered_set:" << end3 - begin3 << endl;
cout << "set:" << end4 - begin4 << endl;
size_t begin5 = clock();
for (auto e : arr)
{
arr1.erase(e);
}
size_t end5 = clock();
size_t begin6 = clock();
for (auto e : arr)
{
arr2.erase(e);
}
size_t end6 = clock();
cout << "unordered_set:" << end5 - begin5 << endl;
cout << "set:" << end6 - begin6 << endl;
}
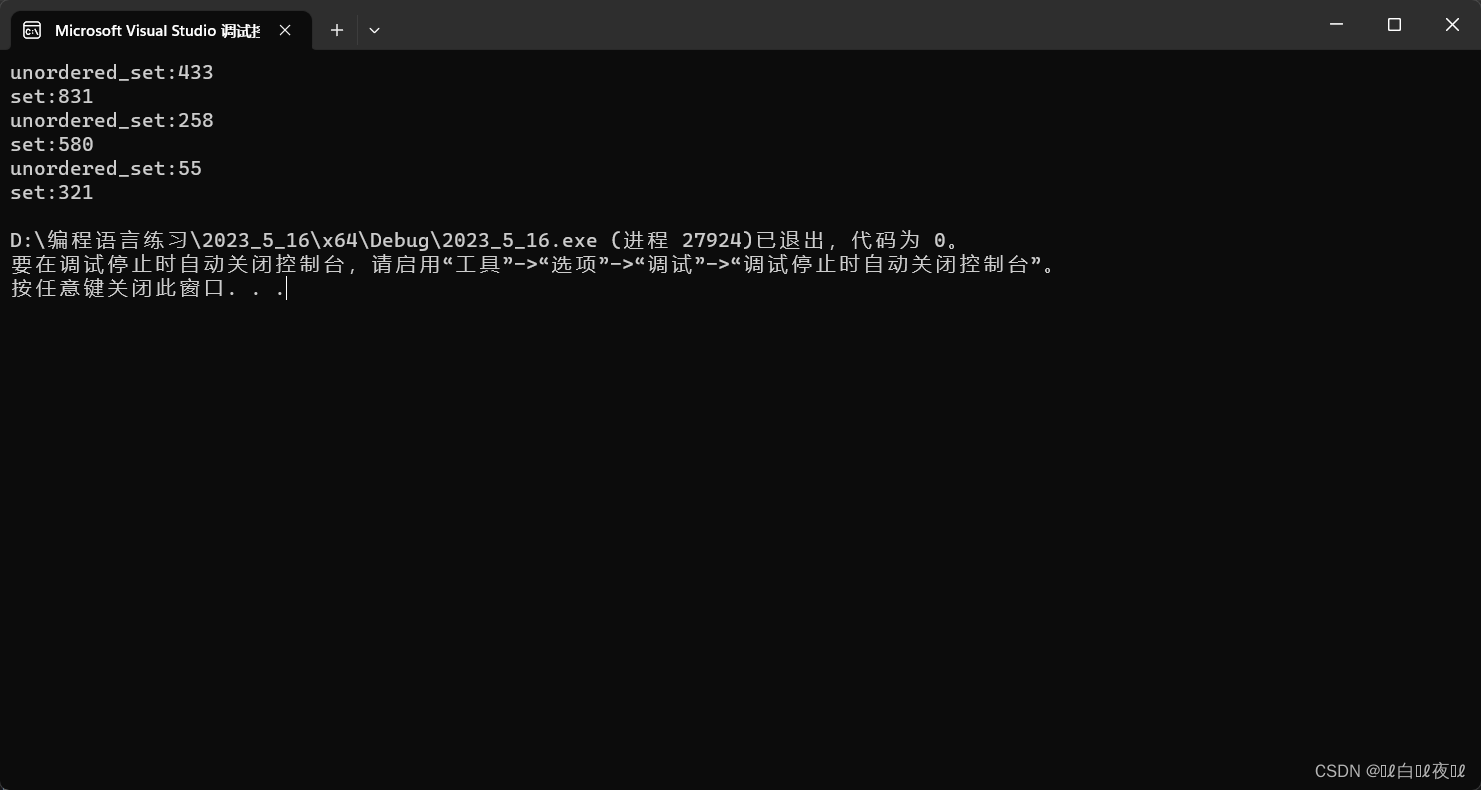
如果是有序的话,set会更快。
总结:对于查找来说,unordered系列的查找是最快的。
底层结构
unordered系列的关联式容器之所以效率比较高,是因为其底层使用了哈希结构。
哈希概念与哈希冲突
哈希映射:key值跟储存位置建立关联关系。(类似于计数排序一样)
但是这种方式有一个很大的问题,如果最小值和最大值差距非常大,那么值就会非常分散,并且会消耗很大的空间。
这个方法叫做:直接定址法。(一般适用于范围集中的一组值)
如果遇到那种一组值大小分散的很大,就用除留余数法:
1 10 55 3 6 88 123 1234
这里给了8个值,我们开辟10个空间就够了,然后让这组数%10就能找到值的相对位置。
但是这里就会有新问题,123%10=3,与数组里面的3相同,那么3的位置应该放哪一个?
这里就叫做哈希冲突,不同的值映射到相同的位置。
哈希冲突的解决
闭散列——开放定址法
如果映射的位置已经有值了,那么就按照某种规律找其他位置。
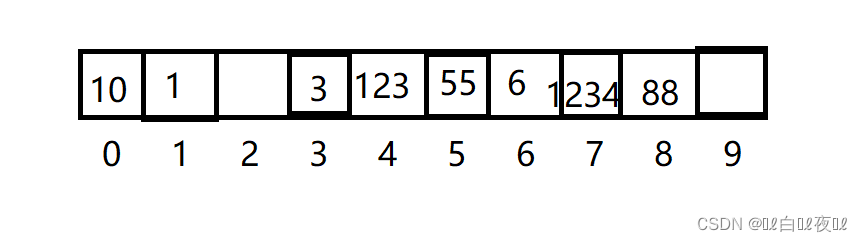
这里123%10等于3,但是下标为3的位置已经被占用了,所以只能向后找位置,发现下标为4的位置没有被占用,后续的1234插入的时候发现下标为4的位置被占用了,就向后找没被占用位置的位置。
但是如果冲突很多,查找的效率就会降低。
线性探测:
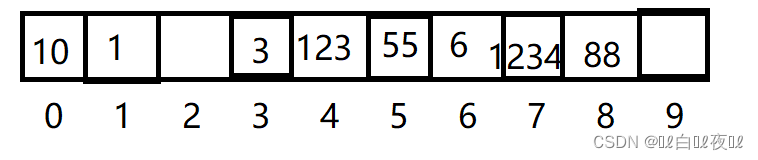
如果我们要找1234这个值是否存在,先让1234%10,然后到4下标找,发现不是1234这个值,那么就向后继续找,最后在下标为7的位置找到1234。
如果要找66这个值,先从下标为6的地方找,然后继续往后找,但是走到下标为9的时候,发现为空,那么这里久没必要在进行查找了,说明没有此值。
如何删除一个值
如果想删除哈希表中的一个值,搜狐先不能牵动哈希表中的任何值,如果移动了其他值就会导致原本在正确位置上的值变得不正确,查找就可能会出问题:不移动只是删除然后变成空也不行,因为查找的时候遇到空停下,那么这个时候删除的这个位置后面的值就有可能无法被查找到了。
这个时候的解决办法就是:
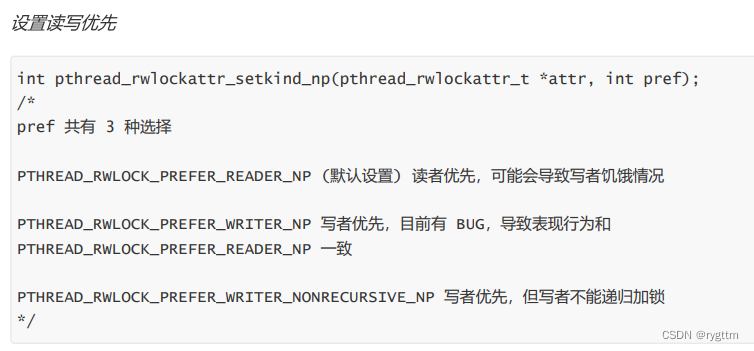
给每个数组中元素都设置三个状态——空,删除,存在
闭散列的实现
首先考虑要给问题,扩容。
什么时候扩容最合适?肯定不是满了在扩容,有一个叫做负载因子(载荷因子)= 表中有效数据的个数/表的大小。
负载因子越小,冲突概率越小,消耗空间越多。
负载因子越大,冲突概率越大,消耗空间利用率越高。
一般负载因子控制在0.7就可以了。
那么扩容的时候就需要将原来表中的数据重新放入新表中,这样就会让一些数据回到本该属于他们的位置,线性探测消耗的时间就不会太多了。
还有一个问题,那么如果插入的不是整形数据,是一个字符串呢?
一个字符串没办法去取%,所以我们要用仿函数对于字符串等类型进行特殊处理。(转成整形在进行映射)
#include<iostream>
#include<cassert>
#include<vector>
#include<string>
using namespace std;
template<class K>
struct HashFunc//能直接转成整型类型的仿函数
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<class K>
struct Hashstring//让string类型转成整形,这里也可以用HashFunc的特化支持string类型
{
size_t operator()(const K& key)
{
size_t sum = 0;
size_t count = 0;
for (auto e : key)
{
++count;
sum += e;
}
return sum;
}
};
//闭散列的状态
enum State
{
EMPTY,//空
EXIST,//存在
DELETE//删除
};
//闭散列的每个元素
template<class K, class V>
struct Closed
{
pair<K, V> _kv;
State _state = EMPTY;
};
template<class K, class V, class HashF = HashFunc<K>>
class Closed_hash
{
public:
typedef Closed<K, V> data;
Closed_hash()
:_n(0)
{
_hash.resize(10);
}
bool Insert(const pair<K, V>& kv)
{
if (find(kv.first))
return false;
if (_n * 10 / _hash.size() > 7)//如果等于0.7就扩容
{
Closed_hash<K, V, HashF> node;
node._hash.resize(_hash.size() * 2);
for (auto& e : _hash)
{
if (e._state == EXIST)//如果存在就插入新开辟的node里面
{
node.Insert(e._kv);
}
}
node._hash.swap(_hash);//交换两个表中的数组
}
HashF datum;
size_t hashi = datum(kv.first) % _hash.size();//找到原本插入的位置
while (_hash[hashi]._state == EXIST)//线性探测
{
++hashi;
hashi = hashi % _hash.size();//防止越界
}//如果找到删除或者是空的位置就插入数据
_hash[hashi]._kv = kv;
_hash[hashi]._state = EXIST;//改变状态
++_n;
return true;
}
data* find(const K& key)
{
HashF datum;
size_t hashi = datum(key) % _hash.size();
size_t start = hashi;
while (_hash[hashi]._state != EMPTY)
{
if (_hash[hashi]._state == EXIST && _hash[hashi]._kv.first == key)
{
return &_hash[hashi];
}
++hashi;
hashi %= _hash.size();
if(start == hashi)//极端场景下,表中的数据不是存在就是删除,没有空
break;
}
return nullptr;
}
bool Erase(const K& key)
{
data* ret = find(key);
if (ret != nullptr)
{
ret->_state = DELETE;
return true;
}
return false;
}
private:
vector<data> _hash;//哈希表
size_t _n = 0;//哈希表中有效数据的个数
};
二次探测
二次探测是按照二次方的顺序探测。
这个是为了解决连续冲突数据。
开散列——哈希桶
这里就是数组是要给指针数组,数组里面存放单链表的地址,将冲突的值放在单链表里面就可以了。
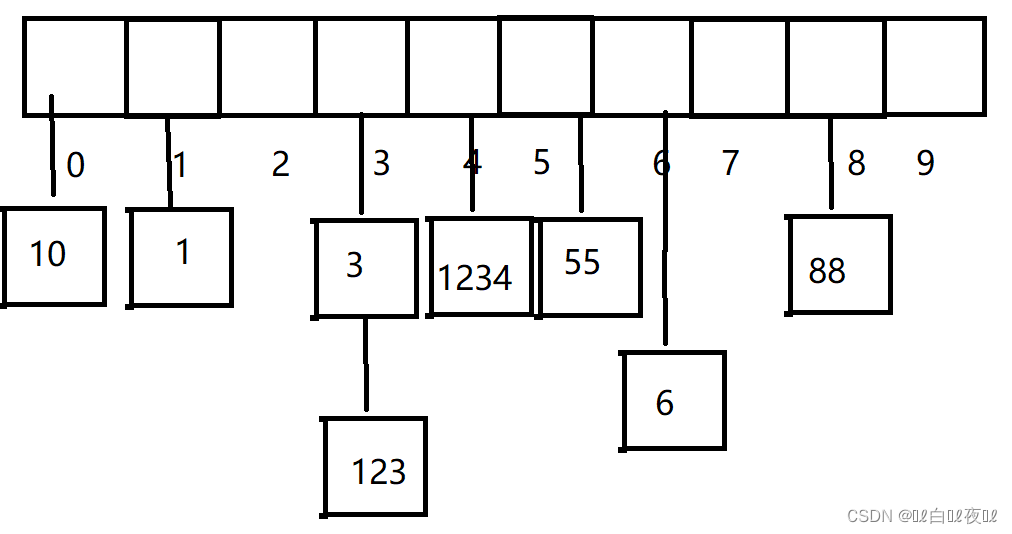
但是如果某一个位置冲突很多,挂了很长,那么效率也会下降。
不过这里下面不一定能非要挂单链表,也可以挂红黑树等等。
哈希桶的实现
首先表中类型需要更改,并且负载因子等于1才会进行扩容。
如果当前位置没有任何值就是空,如果有就挂链表。
每一次链表插入的时候需要进行头插,这样更方便,不需要进行排序,因为不知道要先找谁。
#include<iostream>
#include<cassert>
#include<vector>
#include<string>
using namespace std;
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>//HashFunc特化,如果是string类型的就走这里
{
size_t operator()(const string& key)
{
size_t sum = 0;
size_t count = 0;
for (auto e : key)
{
++count;
sum += e;
}
return sum;
}
};
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K ,V>* next;
HashNode(const pair<K, V>& kv)
:_kv(kv)
,next(nullptr)
{ }
};
template<class K, class V, class Hashc = HashFunc<K>>
class Hashbucket
{
typedef HashNode<K, V> data;
public:
Hashbucket()
{
_hash.resize(10, nullptr);
}
~Hashbucket()
{
for (int i = 0; i < _hash.size(); i++)
{
data* old = _hash[i];
while (old)
{
data* p = old -> next;
delete old;
old = p;
}
_hash[i] = nullptr;
}
}
bool Insert(const pair<K, V>& kv)
{
if (find(kv.first))
return false;
Hashc hs;
if (_hash.size() == _n)//扩容
{
vector<data*> new_hash;//这里必须创建Hashbucket中的vector<data*>,如果直接用Hashbucket类型会导致析构出问题
new_hash.resize(2 * _hash.size(), nullptr);
for (size_t i = 0; i < _hash.size(); i++)
{
data* cur = _hash[i];
while (cur)
{
data* old = cur->next;
size_t hashi = hs(cur->_kv.first) % new_hash.size();//计算重新插入的位置
cur->next = new_hash[hashi];//头插
new_hash[hashi] = cur;
cur = old;
}
_hash[i] = nullptr;
}
_hash.swap(new_hash);
}
size_t hashi = hs(kv.first) % _hash.size();
data* newnode = new data(kv);
newnode->next = _hash[hashi];
_hash[hashi] = newnode;
++_n;
return true;
}
data* find(const K& key)
{
Hashc hs;
size_t hashi = hs(key) % _hash.size();
data* p = _hash[hashi];
while (p)
{
if (p->_kv.first == key)
{
return p;
}
else
{
p = p -> next;
}
}
return nullptr;
}
bool Erase(const K& key)
{
Hashc hs;
size_t hashi = hs(key) % _hash.size();
data* cur = _hash[hashi];
data* old = nullptr;//指向cur的前一个结点
while (cur)
{
if (cur->_kv.first == key)
{
if (cur == _hash[hashi])//这里说明删除的是第一个结点
{
_hash[hashi] = cur->next;
}
else
{
old->next = cur->next;
}
_n--;
delete cur;
return true;
}
else
{
old = cur;
cur = cur->next;
}
}
return false;
}
private:
vector<data*> _hash;
size_t _n = 0;
};
模拟实现unordered_set与unordered_map
这里有一种说法,说哈希表的大小保持一个素数的大小更好。
那么看源码是怎么处理的:
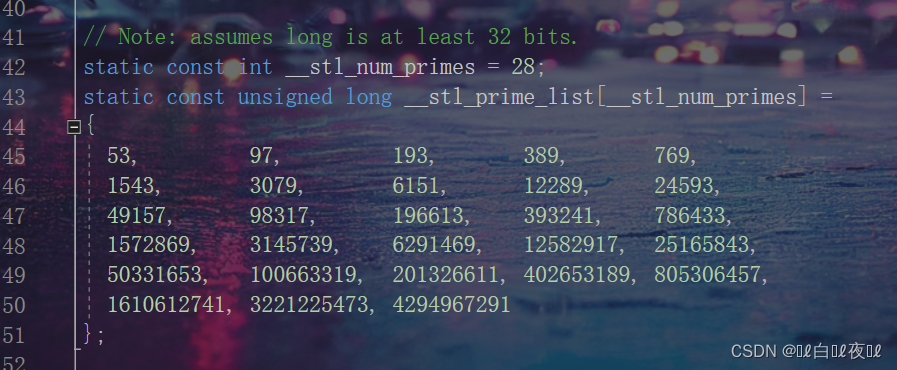
这里给了一个素数表。
将素数表放进上面实现哈希桶用的代码里面,我们只需要封装成一个函数就可以了。
参数选择传当前哈希表的大小。
然后通过这个参数来比较是否需要扩容即可。
返回值也是返回容量大小,如果是表中最后一个值还要继续扩容,那么这里就返回最后一个值,不进行扩容,因为内存已经很大了。
unsigned long Prime_list(unsigned long n)//素数表
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (int i = 0; i < __stl_num_primes; i++)
{
if (n < __stl_prime_list[i])
{
return __stl_prime_list[i];
}
}
return __stl_prime_list[__stl_num_primes - 1];
}
然后接下来进行对哈希桶改造与迭代器的封装:
首先考虑以下迭代器如何遍历整个哈希桶。
从第一个有结点的地方开始遍历,走到空之后去找表中的下一个有结点的地方再从头开始走,以此类推,遍历完整个表就可以了。
#include<iostream>
#include<cassert>
#include<vector>
#include<string>
using namespace std;
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>//HashFunc特化,如果是string类型的就走这里
{
size_t operator()(const string& key)
{
size_t hash = 0;
for (auto ch : key)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
//前置声明,不然迭代器不知道有哈希桶这个类
template<class K, class T, class KeyOFT, class Hashc>
class Hashbucket;
template<class T>
struct HashNode
{
T _data;
HashNode<T>* next;
HashNode(const T& data)
:_data(data)
, next(nullptr)
{ }
};
template<class K, class T, class KeyOFT, class Hashc>
struct HIterator
{
typedef HashNode<T> Node;
typedef HIterator<K, T, KeyOFT, Hashc> Self;
typedef Hashbucket<K, T, KeyOFT, Hashc> Hashbucket;
Node* _node;
Hashbucket* _hs;
HIterator(Node* node, Hashbucket* hs)
:_node(node)
,_hs(hs)
{}
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
bool operator!=(const Self& s)const
{
return _node != s._node;
}
Self operator++()
{
if (_node->next)
{
_node = _node->next;
}
else
{
KeyOFT kot;
Hashc ht;
size_t hashi = ht(kot(_node->_data)) % _hs->_hash.size();
hashi++;
while (hashi < _hs->_hash.size())//找表中下一个不为空的结点
{
if (_hs->_hash[hashi])
{
_node = _hs->_hash[hashi];
break;
}
else
{
hashi++;
}
}
if (hashi == _hs->_hash.size())//如果走到末尾了就说明结束了
_node = nullptr;
}
return *this;
}
};
template<class K, class T, class KeyOFT, class Hashc>//这里的取整数仿函数不在这里放缺省值
class Hashbucket
{
template<class K, class T, class KeyOFT, class Hashc>
friend struct HIterator;//这里将迭代器设置友元,因为迭代器内部需要调用该类的私有成员
typedef HashNode<T> Data;
public:
typedef HIterator<K, T, KeyOFT, Hashc> Iterator;
Iterator begin()
{
for (size_t i = 0; i < _hash.size(); i++)
{
if (_hash[i])
{
return Iterator(_hash[i], this);
}
}
return Iterator(nullptr, this);
}
Iterator end()
{
return Iterator(nullptr, this);
}
Hashbucket()
{
_hash.resize(10, nullptr);
}
~Hashbucket()
{
for (int i = 0; i < _hash.size(); i++)
{
Data* old = _hash[i];
while (old)
{
Data* p = old->next;
delete old;
old = p;
}
_hash[i] = nullptr;
}
}
pair<Iterator, bool> Insert(const T& data)
{
KeyOFT kot;
Iterator it = find(kot(data));
if (it != end())
return make_pair(it, false);
Hashc hs;
if (_hash.size() == _n)//扩容
{
vector<Data*> new_hash;//这里必须创建Hashbucket中的vector<data*>,如果直接用Hashbucket类型会导致析构出问题
new_hash.resize(2 * _hash.size(), nullptr);
for (size_t i = 0; i < _hash.size(); i++)
{
Data* cur = _hash[i];
while (cur)
{
Data* old = cur->next;
size_t hashi = hs(kot(cur->_data)) % new_hash.size();//计算重新插入的位置
cur->next = new_hash[hashi];//头插
new_hash[hashi] = cur;
cur = old;
}
_hash[i] = nullptr;
}
_hash.swap(new_hash);
}
size_t hashi = hs(kot(data)) % _hash.size();
Data* newnode = new Data(data);
newnode->next = _hash[hashi];
_hash[hashi] = newnode;
++_n;
return make_pair(Iterator(newnode, this), true);
}
Iterator find(const K& key)
{
KeyOFT kot;
Hashc hs;
size_t hashi = hs(key) % _hash.size();
Data* p = _hash[hashi];
while (p)
{
if (kot(p->_data) == key)
{
return Iterator(p, this);
}
else
{
p = p->next;
}
}
return Iterator(nullptr, this);
}
bool Erase(const K& key)
{
Hashc hs;
KeyOFT kot;
size_t hashi = hs(key) % _hash.size();
Data* cur = _hash[hashi];
Data* old = nullptr;//指向cur的前一个结点
while (cur)
{
if (kot(cur->_data) == key)
{
if (cur == _hash[hashi])//这里说明删除的是第一个结点
{
_hash[hashi] = cur->next;
}
else
{
old->next = cur->next;
}
_n--;
delete cur;
return true;
}
else
{
old = cur;
cur = cur->next;
}
}
return false;
}
unsigned long Prime_list(unsigned long n)//素数表
{
static const int __stl_num_primes = 28;
static const unsigned long __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (int i = 0; i < __stl_num_primes; i++)
{
if (n < __stl_prime_list[i])
{
return __stl_prime_list[i];
}
}
return __stl_prime_list[__stl_num_primes - 1];
}
private:
vector<Data*> _hash;
size_t _n = 0;
};
#include "uset与umap.h"
template<class K, class Hash = HashFunc<K>>
class uset
{
struct Setkot
{
const K& operator()(const K& key)
{
return key;
}
};
public:
typedef typename Hashbucket<K, K, Setkot, Hash>::Iterator Iterator;
Iterator begin()
{
return _set.begin();
}
Iterator end()
{
return _set.end();
}
pair<Iterator, bool> Insert(const K& key)
{
return _set.Insert(key);
}
Iterator Find(const K& key)
{
return _set.find(key);
}
bool Erase(const K& key)
{
return _set.Erase(key);
}
private:
Hashbucket<K, K, Setkot, Hash> _set;
};
#include "uset与umap.h"
template<class K, class V, class Hash = HashFunc<K>>
class umap
{
struct Mapkot
{
const K& operator()(const pair<const K, V>& kv)
{
return kv.first;
}
};
public:
typedef typename Hashbucket<K, pair<K, V>, Mapkot, Hash>::Iterator Iterator;
Iterator begin()
{
return _map.begin();
}
Iterator end()
{
return _map.end();
}
pair<Iterator, bool> Insert(const pair<K, V>& kv)
{
return _map.Insert(kv);
}
V& operator[](const K& key)
{
pair<Iterator, bool> it = Insert(make_pair(key, V()));
return it.first->second;
}
Iterator Find(const K& key)
{
return _map.find(key);
}
bool Erase(const K& key)
{
return _map.Erase(key);
}
private:
Hashbucket<K, pair<K, V>, Mapkot, Hash> _map;
};
但是const版本的迭代器和非const迭代器是不能像以前一样套两个模板就能分别返回不同的const与非const类型,因为我们调用const迭代器的时候this指针也是const,那么成员:
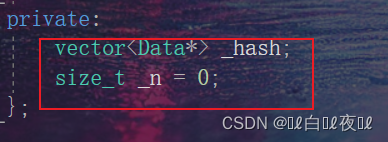
这两个也是const类型,按照以前写begin()const,end()const:
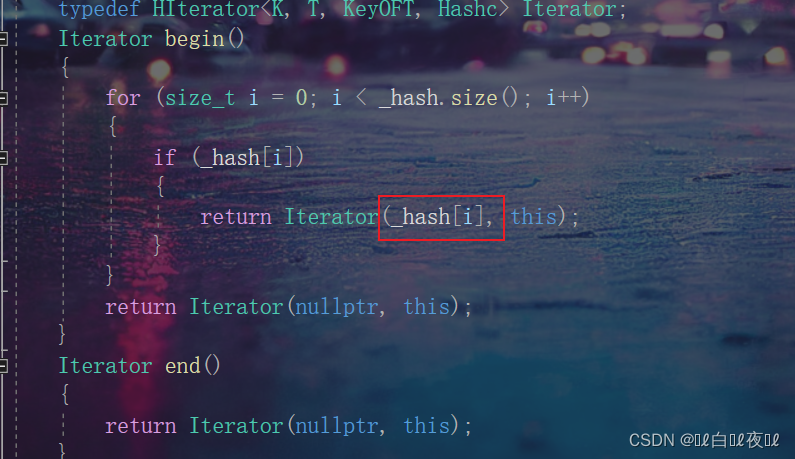
然后取用const类型去构造,这里的迭代器构造函数是非const类型,没办法进行构造,这里属于权限放大。

所以我们这里就绪就要重新写一个const版本的迭代器(这里跟const迭代器什么区别)。
其他哈希函数
- 平方取中法
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;
再比如关键字为4321,对它平方就是18671041,抽取中间的3位671(或710)作为哈希地址。
平方取中法比较适合:不知道关键字的分布,而位数又不是很大的情况。 - 折叠法
折叠法是将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址。
折叠法适合事先不需要知道关键字的分布,适合关键字位数比较多的情况。 - 随机数法
选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key) = random(key),其中random为随机数函数。
通常应用于关键字长度不等时采用此法。 - 数学分析法
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定
相同,可能在某些位上分布比较均匀,每种符号出现的机会均等,在某些位上分布不均匀只
有某几种符号经常出现。可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散
列地址。
例如:
假设要存储某家公司员工登记表,如果用手机号作为关键字,那么极有可能前7位都是 相同
的,那么我们可以选择后面的四位作为散列地址,如果这样的抽取工作还容易出现 冲突,还
可以对抽取出来的数字进行反转(如1234改成4321)、右环位移(如1234改成4123)、左环移
位、前两数与后两数叠加(如1234改成12+34=46)等方法。
数字分析法通常适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的
若干位分布较均匀的情况。
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突。
哈希的应用
哈希切割(面试题)
给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
IP可以视为一个字符串,无法直接转成整形。
这道题可以将这100G的文件切割成1G的文件(100份)。
将100G文件中的IP通过哈希切割(哈希表与桶上面将string转成int类型的仿函数)转成整形,遍历一遍然后挨个%100放进这100份的文件中。
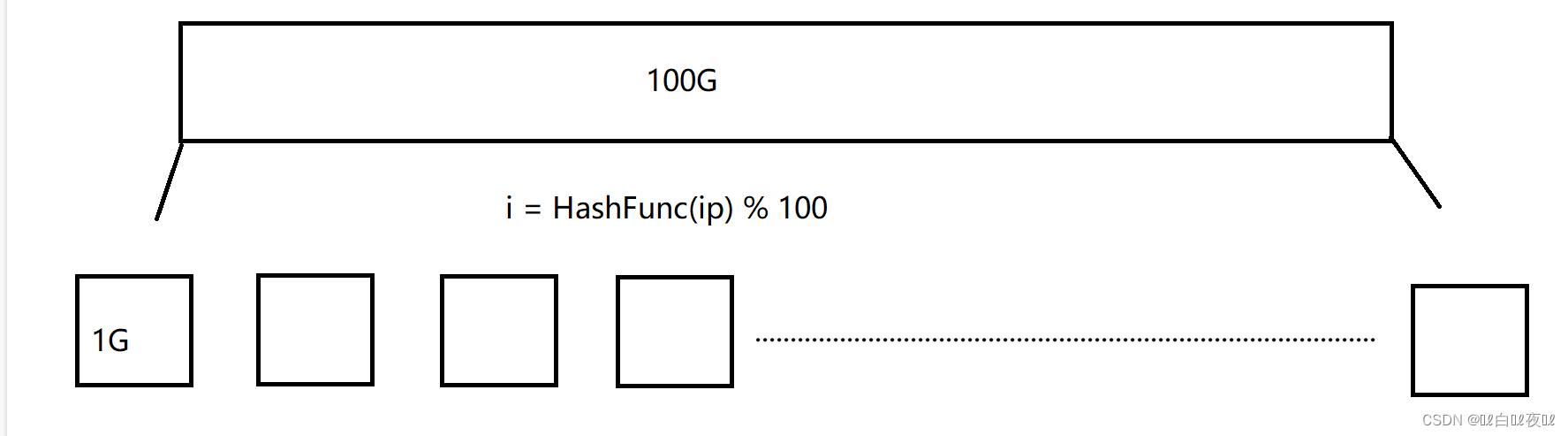
然后用map统计次数,统计完一个小文件释放掉这个map,在新创建一个map用来统计下一个,最后找到IP最多的。
那么如果一个小文件大小超过1G呢?这会有两种情况:
1.这个小文件不同IP很多,大多数都是不重复的,map统计不下。
2.这个小文件相同IP很多,大多数都是重读的,map可以统计下。
此时只要解决了第一种情况即可:
换个哈希切割的函数(方法),一定要换方法,不然切割出来的内容还是相同的,然后在从头开始进行上面的方法,分成100份,再用map统计即可。
区分这两种方式是,直接用map统计,如果是第一种情况map就会插入结点失败,抛异常。
第二种不会有任何的错误,会统计完,不会报错。
位图
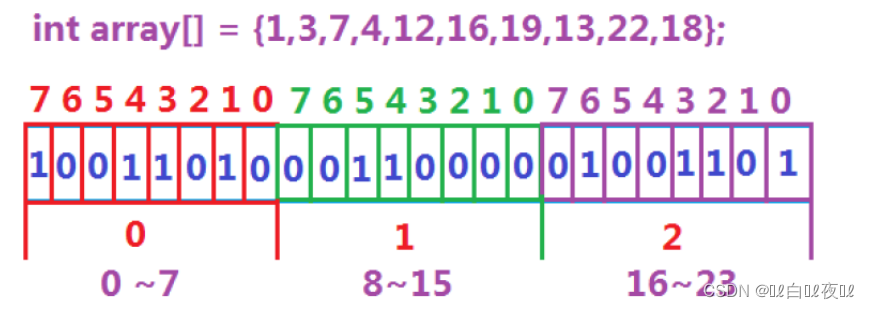
所谓位图,就是用每一位来存放某种状态,适用于海量数据,数据无重复的场景。通常是用
来判断某个数据存不存在的。(也是一种哈希的思想)
例如:用23个比特位就能判断这组数据是否存在。
位图应用(面试题)
1. 给40亿个不重复的无符号整数,没排序过,给一个无符号整数,如何快速判断一个数是否在这40亿个数。【腾讯】
40亿个整数大概是16G的大小,我们电脑台式机一般都是32G,笔记本一般是16G,这些数据要是放进内存肯定是不行的。
所以这里就适合用位图去搞。
一个无符号整形数据的范围是:

这里就放2^23-1个比特位的位图,大小算起来就是512MB的大小。
然后,因为一个字节是8个比特位,那么在开辟空间的时候就是按照字节开辟,存储比特位也通过字节位移的方式存储。

那么对应值如何映射到位图中呢?首先确定是在哪一个字节,也就是要/8,然后确定是该字节中的哪个比特位当中%8。
#include<iostream>
#include<vector>
using namespace std;
namespace baiye
{
template<size_t N>
class bit_set
{
public:
bit_set()
{
_arr.resize(N / 8 + 1, 0);//这里是开辟多少个字节,+1是为了多余的比特位能有容身之所
}
void set(size_t x)//标记比特位
{
size_t i = x / 8;
size_t j = x % 8;
_arr[i] |= (1 << j);
}
void reset(size_t x)//清除比特位
{
size_t i = x / 8;
size_t j = x % 8;
_arr[i] &= (~(1 << j));
}
bool test(size_t x)//查找这个数是否存在
{
size_t i = x / 8;
size_t j = x % 8;
return _arr[i] &= (1 << j);//0就是不存在,非0就是存在
}
private:
vector<char> _arr;
};
}
void test()
{
baiye::bit_set<100> arr;
arr.set(10);
arr.set(20);
arr.set(30);
cout << arr.test(30) << endl;
cout << arr.test(20) << endl;
cout << arr.test(10) << endl;
arr.reset(30);
cout << arr.test(30) << endl;
}
int main()
{
test();
return 0;
}
库里一个写好的位图:https://legacy.cplusplus.com/reference/bitset/bitset/?kw=bitset

2. 给定100亿个整数,设计算法找到只出现一次的整数?
这道题使用位图表示数据的状态,其实可以用两个比特位就能表示:
0次 00
1次 01
1次以上 11
我们可以开辟两个大小相同的位图结构:
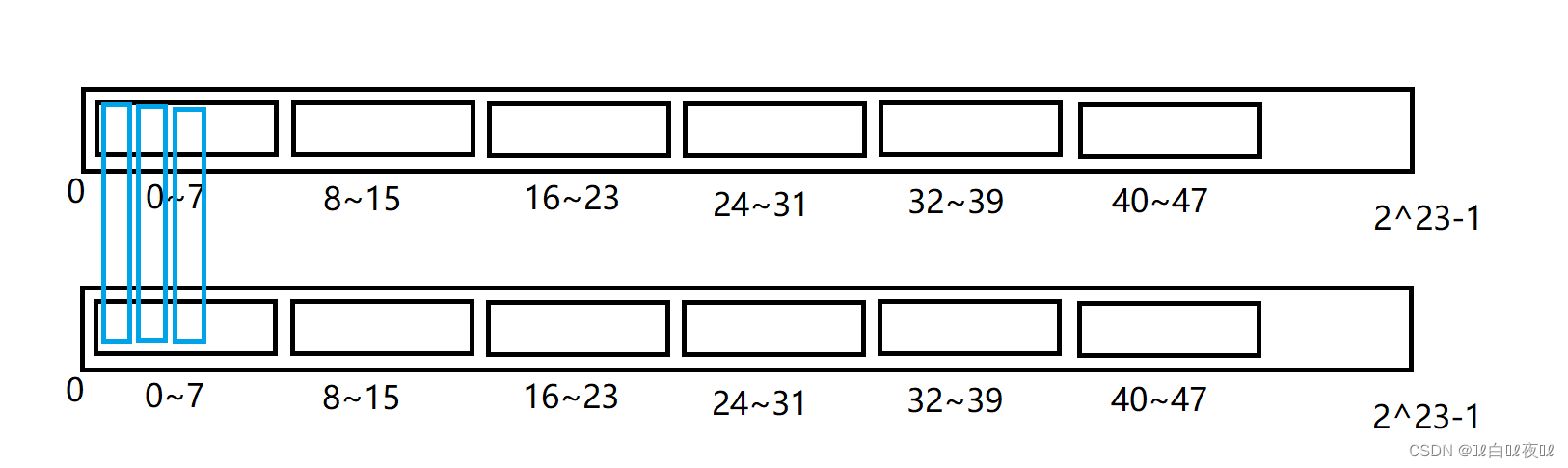
一个位图对应另一个位图的相同位置成为一组。
#include<iostream>
#include<vector>
#include<bitset>
using namespace std;
namespace baiye
{
template<size_t N>
class bit_set
{
public:
void set(size_t x)
{
if (arr1.test(x) == 0)
arr1.set(x);
else
arr2.set(x);
}
void Printf()
{
for (size_t i = 0; i < arr1.size(); i++)
{
if (arr1[i] && !arr2[i])
{
cout << i << ' ';
}
}
cout << endl;
}
private:
bitset<N> arr1;
bitset<N> arr2;
};
}
void test()
{
baiye::bit_set<100> arr;
int a[] = { 10,25,25,66,66,66,78,49,32, };
for (auto& e : a)
{
arr.set(e);
}
arr.Printf();
}
3. 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集?
这道题和上一道题区别不大,开两个位图,遍历两个位图,如果都为1就是交集。
4. 位图应用变形:1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整
数。
可以在第二题的基础上改动,:
0次 00
1次 01
2次 10
2次以上 11
布隆过滤器
给一组英文单词,想看这几个单词是否存在,我们可以用位图,但是冲突是不可避免的,完全不相同的单词通过HashFunc函数可能就转成了同一个整形,映射到了同一个位置,如果某个单词其实不存在,但是他映射的位置是1,那么这里就有了误判。
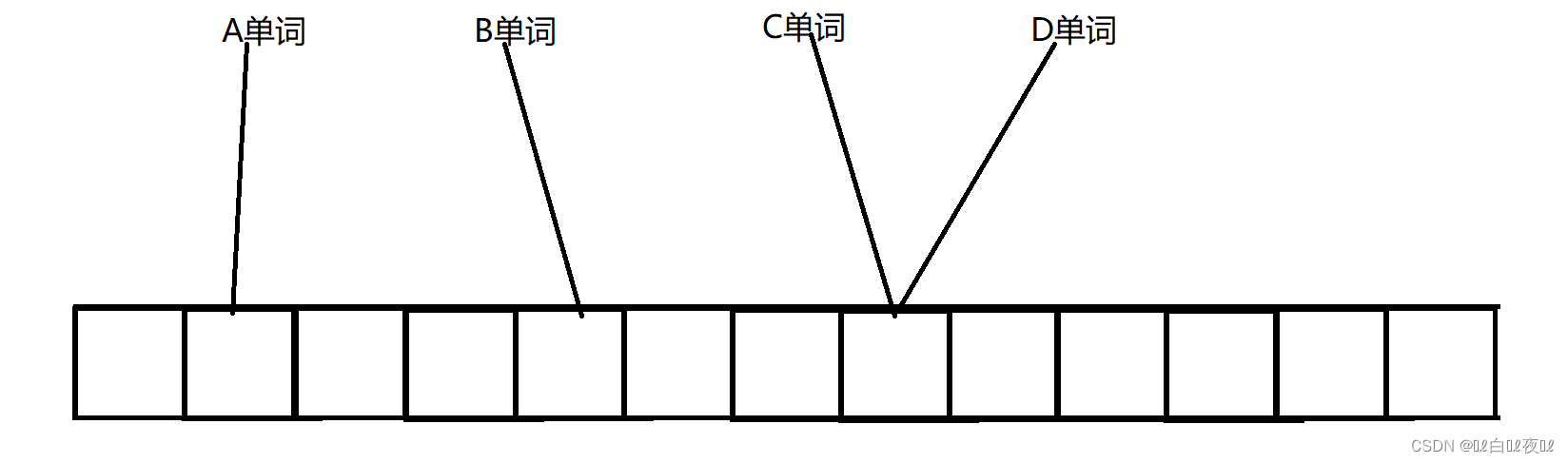
那么有什么办法能降低误判率呢?我们可以让每个单词同时映射2个位置。
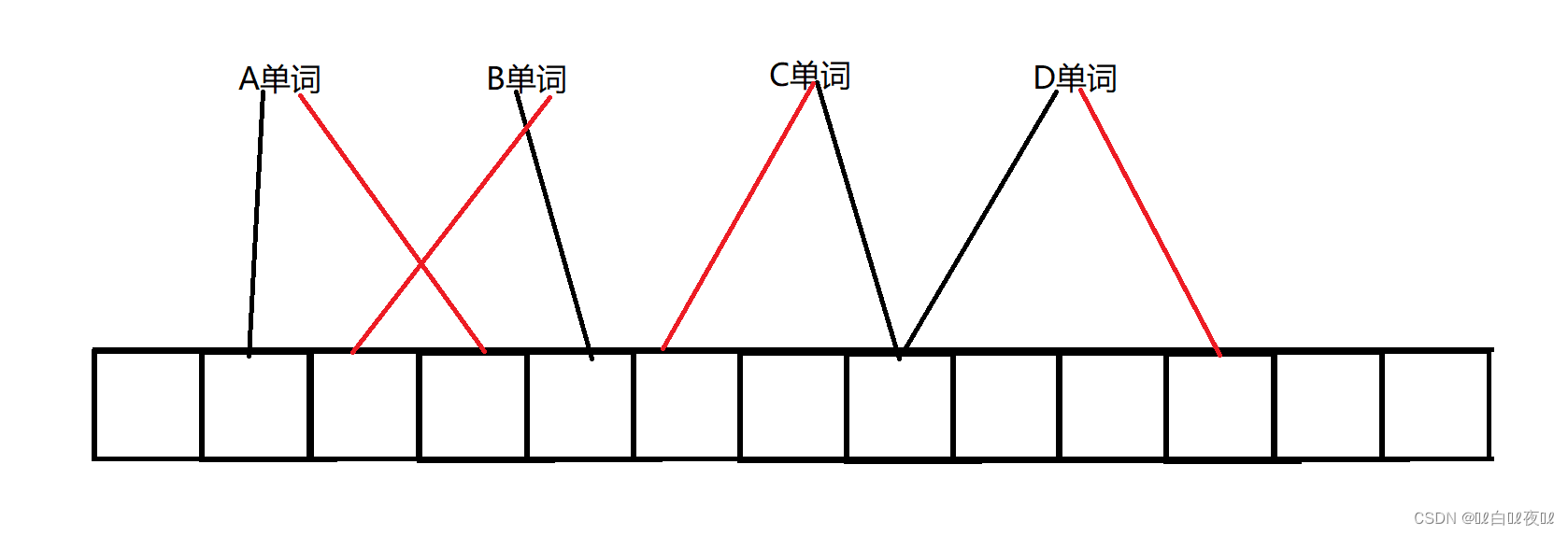
C单词看两个位置如果都为1,就是存在,D单词也是,如果D单词不存在,C单词存在,D单词红线映射的部分就是0,黑线还是1,这样两个单词就不冲突了。(降低了误判率)
布隆过滤器的改进:映射多个位置,降低误判率。
多少个哈希函数(映射关系)与误判率的概率:
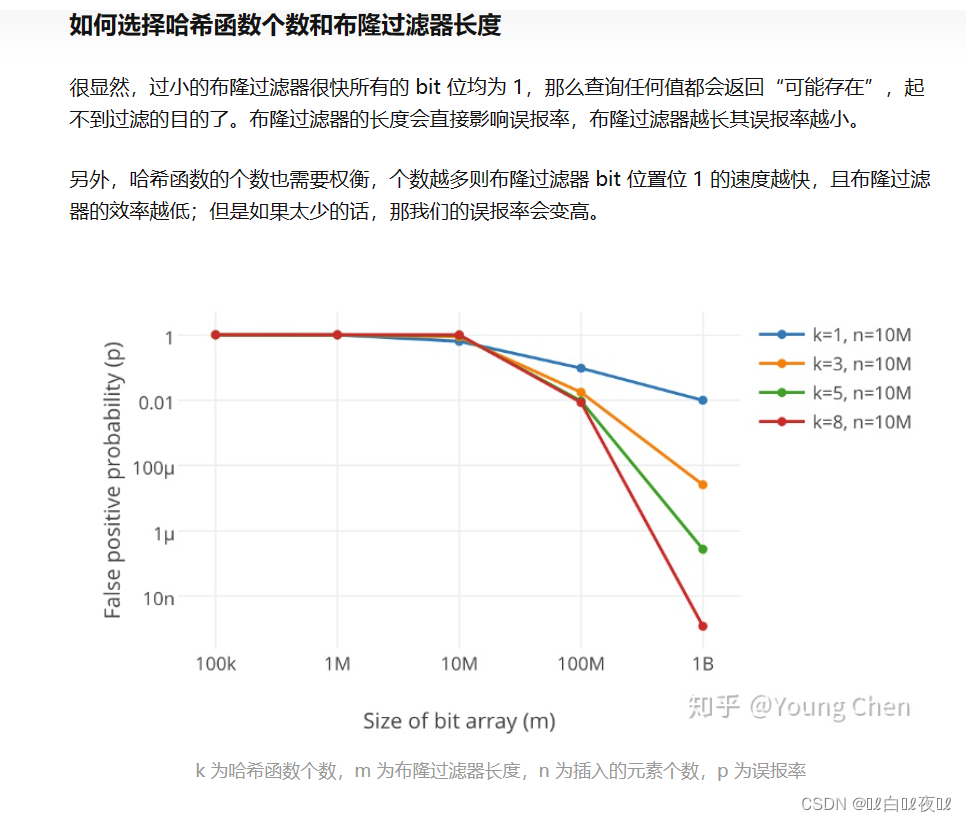

原文章地址:https://zhuanlan.zhihu.com/p/43263751/
m = k*n/0.7
假设k = 3 ,m = 4.2n,也就是说存一个值要开4个位出来。
代码实现
#include<iostream>
#include<string>
#include<bitset>
using namespace std;
struct Func1
{
size_t operator()(const string str)
{
size_t hash = 0;
for (auto& ch : str)
{
hash = hash * 131 + ch;
}
return hash;
}
};
struct Func2
{
size_t operator()(const string str)
{
unsigned int hash = 0;
int i = 0;
for (auto& ch : str)
{
if ((i & 1) == 0)
{
hash ^= ((hash << 7) ^ ch ^ (hash >> 3));
}
else
{
hash ^= (~((hash << 11) ^ ch ^ (hash >> 5)));
}
i++;
}
return hash;
}
};
struct Func3
{
size_t operator()(const string str)
{
size_t hash = 5381;
for (auto& ch : str)
{
hash += (hash << 5) + ch;
}
return hash;
}
};
template<size_t N,//假设N是最多储存数据的个数
class HashFunc1 = Func1,//映射几个位置就给几个哈希函数
class HashFunc2 = Func2,
class HashFunc3 = Func3,
class K = string>//因为大部分都是string类型,给个缺省值
class BloomFilter
{
public:
void set(const K& key)//存数据
{
arr.set(HashFunc1()(key) % (5 * N));//将key分别映射到三个位置
arr.set(HashFunc2()(key) % (5 * N));
arr.set(HashFunc3()(key) % (5 * N));
}
bool test(const K& key)
{
size_t hashi1 = HashFunc1()(key) % (5 * N);
size_t hashi2 = HashFunc2()(key) % (5 * N);
size_t hashi3 = HashFunc3()(key) % (5 * N);
if (!arr.test(hashi1))
return false;
if (!arr.test(hashi2))
return false;
if (!arr.test(hashi3))
return false;
return true;
}
private:
bitset<N * 5> arr;//原本是4.2,这里多扩大一点
};
int main()
{
BloomFilter<10> arr;
string str[] = { "666", "ckx","小黑子","鸡哥","树枝","蒸虾头","蒸乌鱼","香翅捞饭" };
for (auto& e : str)
{
arr.set(e);
}
for (auto& e : str)
{
cout << arr.test(e) << " ";
}
cout << endl;
string str1[] = { "1白龙马", "白1龙马","白龙1马","白龙马1","1白1龙1马1","白1龙1马","1白龙1马","白1龙马1" };
for (auto& e : str1)
{
arr.set(e);
}
for (auto& e : str1)
{
cout << arr.test(e) << " ";
}
return 0;
}
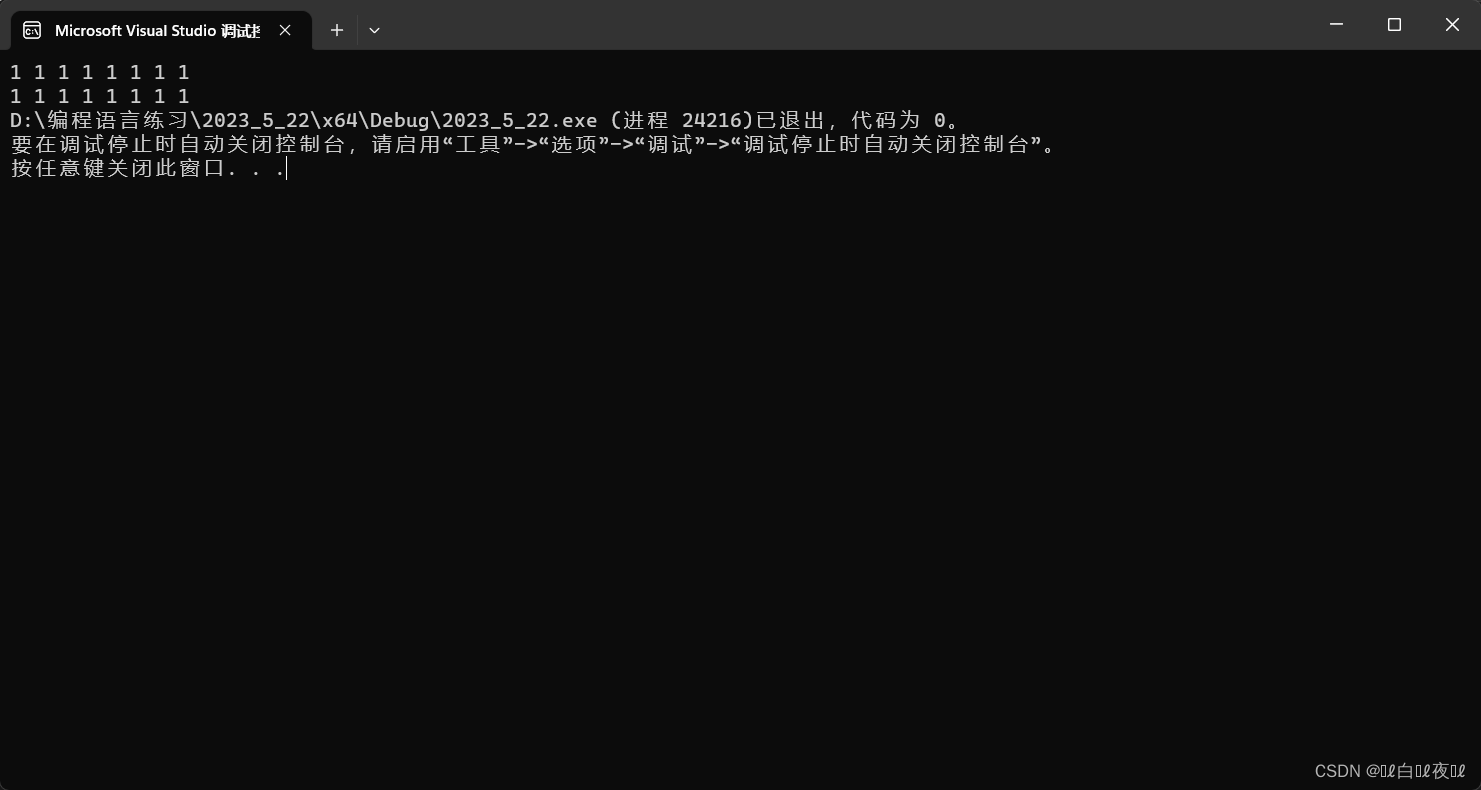
第二组测试用例是近似的,但是也区分开来了,说明冲突的概率确实不大。(但是无法避免,只能缩小概率)
布隆过滤器不能直接支持删除工作,因为在删除一个元素时,可能会影响其他元素。
布隆过滤器的优缺点
优点
- 增加和查询元素的时间复杂度为:O(K), (K为哈希函数的个数,一般比较小),与数据量大小无
关。 - 哈希函数相互之间没有关系,方便硬件并行运算。
- 布隆过滤器不需要存储元素本身,在某些对保密要求比较严格的场合有很大优势。
- 在能够承受一定的误判时,布隆过滤器比其他数据结构有这很大的空间优势。
- 数据量很大时,布隆过滤器可以表示全集,其他数据结构不能。
- 使用同一组散列函数的布隆过滤器可以进行交、并、差运算。
缺陷
- 有误判率,即存在假阳性(False Position),即不能准确判断元素是否在集合中。(补救方法:再
建立一个白名单,存储可能会误判的数据) - 不能获取元素本身。
- 一般情况下不能从布隆过滤器中删除元素。
- 如果采用计数方式删除,可能会存在计数回绕问题。
布隆过滤器应用(面试题)
1. 给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法。
精准算法:
query一般是查询指令,比如是一个网络请求,一个数据库sql语句等等。
假设每个query每个是50字节,那么100亿个就是500G。
想要精准计算,就要用到上面讲100G的文件分成100个文件的方法。
这里两个大文件各分成1000份小文件:HashFunc(query)%1000
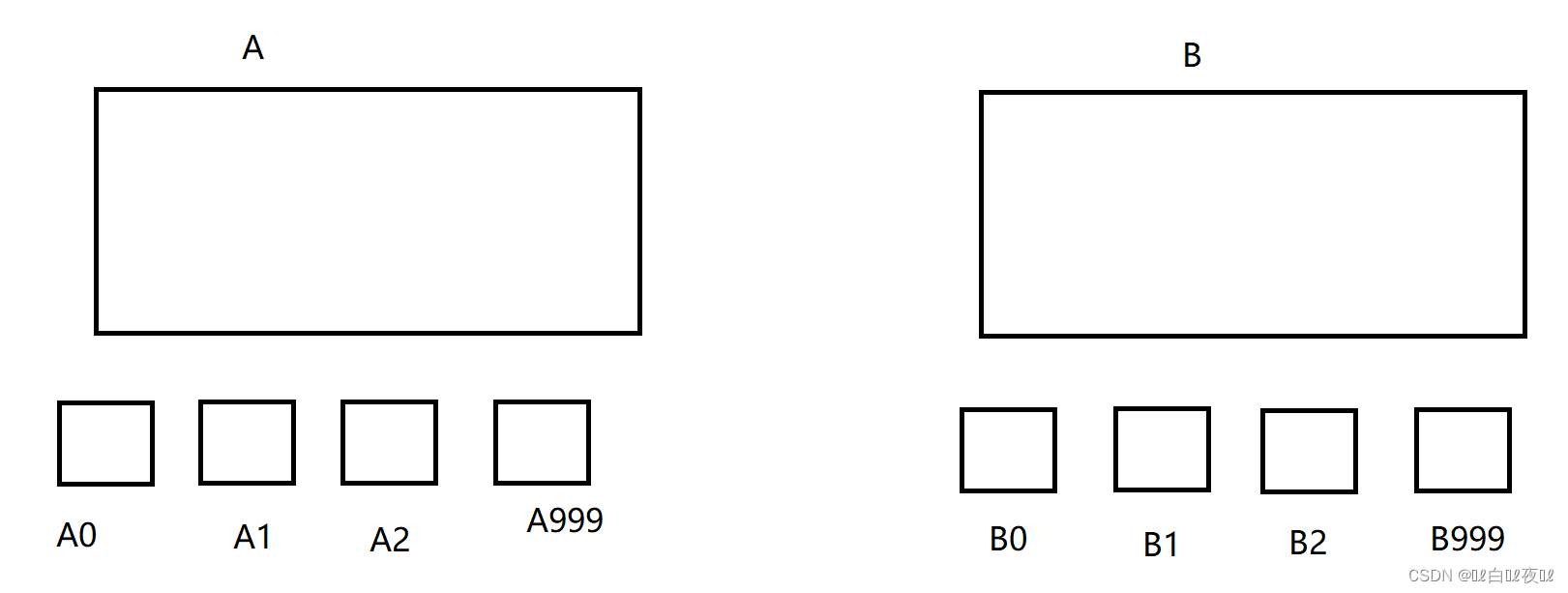
然后通过一个两个小文件组成一对,找出他们的交集即可。

这里如果某个小文件超过规定的大小,那么就从头开始继续分,像之前的哈希切割一样。
近似算法:
用一个布隆过滤器,两个数据中是交集的一定会映射到一起去,但是也会有不是的映射到一起去。
2. 如何扩展BloomFilter使得它支持删除元素的操作。
可以在每个位图上面加一个计数的,每有一个映射在这个位置上就++,少一个映射就- - 。







![[架构之路-200]- 性能需求与性能分析:影响性能的主要因素](https://img-blog.csdnimg.cn/20210928172207220.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAZHhtZHhtMTIz,size_20,color_FFFFFF,t_70,g_se,x_16)