一、vector源码解析
没有任何一个东西可以在原地扩充,因为要了一块内存后,后面这块内存有可能被使用了,或者能不能用也不知道。链表可以保留原有节点,再将指针指向别处开辟的新内存,但这个也不算原地扩充。
对于vector这种需要连续空间存储数据的容器也是,因为容量满了之后,数组后面的那段空间可能已经被其它地方用了,如下图为某段内存,其蓝色部分是用于vector存放数据:
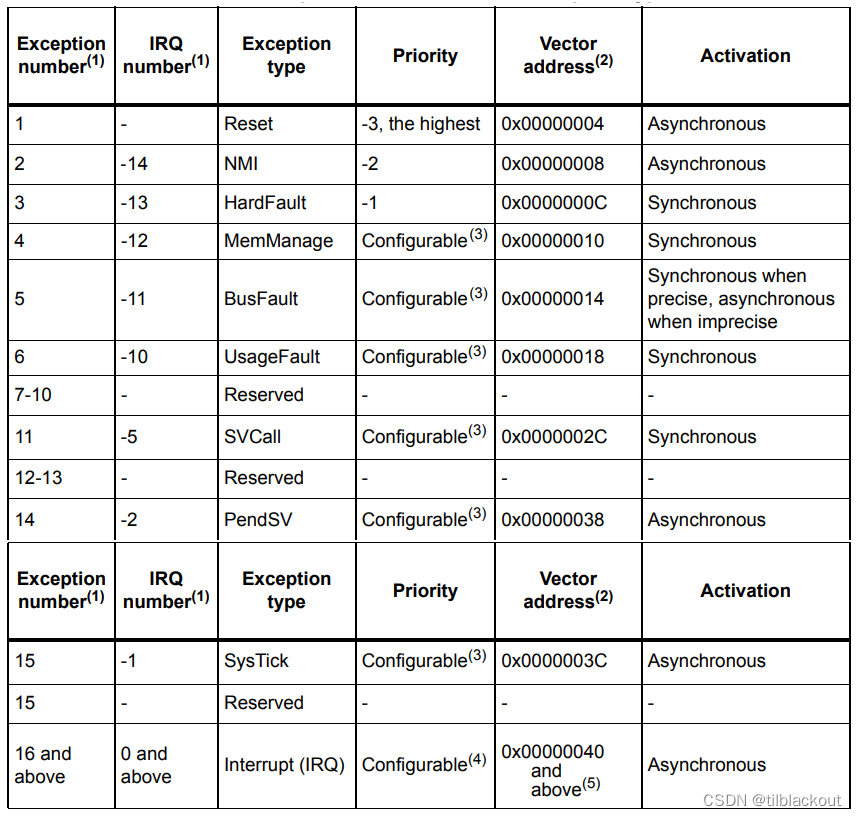
我们都知道,vector有3个指针来维护size和capacity的,而且扩容的机制是新开辟的内存为扩容前的两倍,如下图:
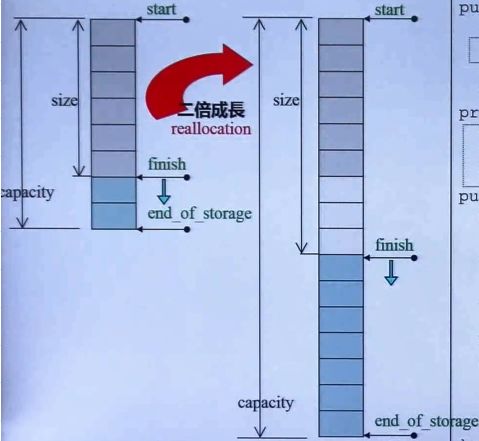
start —— finish之间就是vector中实际存放的数据,start —— end_of_storage之间就是该vector占有的总堆内存,finish —— end_of_storage之间就没有存数据,属于可用空间。
当capacity不够用时,新找到一块两倍大的内存后,要拷贝原先的数据,再放到新的内存里,这个扩充容量的次数多了之后,开销就很大,所以这也是为什么vector要预留出一块内存,即capacity大于size,就是为了避免频繁扩容:当有新数据要存放时,不是直接扩容,而是将数据存放在finish —— end_of_storage之间。
vector的重要源码如下:
注意,这是侯捷老师讲的G2.9的版本,STL有G4.9新版本的实现。
// 侯捷vector源码解析课
template<class T, class Alloc = alloc>
class vector{
public:
typedef T value_type;
typedef value_type* iterator;
typedef value_type& reference;
typedef size_t size_type;
protected:
iterator start;
iterator finish;
iterator end_of_storage;
public:
iterator begin() {return start;}
iterator end() {return finish;}
size_type size() const
{
return size_type(end() - begin());
}
size_type capacity() const
{
return size_type(end_of_storage - begin());
}
bool empty() const
{
return begin() == end();
}
reference operator[](size_type n)
{
return *(begin() + n);
}
reference front()
{
return *begin();
}
reference back()
{
return *(end() - 1);
}
// push_back代码如下
void push_back(const T& x)
{
if(finish != end_of_storage){ // 尚有可用空间
construct(finish, x); // 全局函数
++finish; // 调整水位
}
else // 无可用空间则调用insert_aux()
insert_aux(end(), x);
}
};
push_back()里调用了insert_aux(),这个函数也会被insert()里面调用。这里体现了函数封装的好处,所以在push_back()方法源码里,要追溯到insert_aux()。
可以看到拷贝原vector内容的时候,后面还会拷贝安插点(如果是push_back那就是尾元素,后面没元素,如果是insert情况那后面就有)之后的内容。
// insert_aux()源码如下,扩容实现在里面
template<class T, class Alloc>
void vector(T, Alloc)::insert_aux(iterator position, const T& x){
if(finish != end_of_storage){ // 尚有可用空间,因为该函数还会被insert(pos, value)调用,所以这里还会判断
// 在可用空间起始处构建一个元素,并以vector最后一个元素为其初始值
construct(finish, *(finish - 1));
++finish; // 调整水位
T x_copy = x;
copy_backword(position, finish - 2, finish - 1); // 因为新插入了数据,后面的数据都得拷贝到新位置
*position = x_copy; // 目标插入处赋值为x
}
else{ // 无可用空间
const size_type old_size = size();
// 扩容原则:原大小为0则分配1,否则两倍扩容
const size_type len = old_size != 0 ? 2 * old_size : 1;
// 扩容后,前半段用于放置旧数据,后面的放新数据
iterator new_start = data_allocator::allocate(len);
iterator new_finish = new_start;
try{
// 将原vector的内容拷贝到新vector
new_finish = uninitialized_copy(start, position, new_start);
construct(new_finish, x); //为新元素设初值x
++new_finish; // 调整水位
// 拷贝插入点之后的内容,用于被insert()调用时
new_finish = uninitailized_copy(position, finish, new_finish);
}
catch(...){
destory(new_start, new_finish);
data_allocator::deallocate(new_start, len);
throw;
}
}
}
try…catch…部分就是将原vector的数据拷贝到新的vector里。
还有全局函数construct()
template<class T, class... Args>
void construct(T* p, Args&&... args);
如:
int* p = new int;
construct(p, 42);
construct()是对placement new的封装,不申请内存,也就是只调用类T的构造函数。STL里是把申请内存和构造对象、析构对象和回收内存四件事分开做的。这样做的好处从vector的源码就可以看出,当vector尚有可用空间时,调用construct()全局函数来构造对象,不需要new申请空间,因为vector还有可用的堆空间,见if(finish != end_of_storage)部分。
调用构造函数的时候其实就需要进行仲裁,因为vector里存的是一些自定义类型时,里面有多种构造函数,那么就需要判断调用哪个构造函数。— —这里就已经可以引出vector在扩容时的优化了。
二、vector的扩容优化
元素的拷贝会引发copy_construct,即拷贝构造函数,而原来的元素要删除又会引发destructor,即析构函数。
如果元素很多,那就每次扩容都会调用大量的拷贝构造和析构函数。
那么我们需要对vector的扩容过程进行优化:
1,在定义vector时可以指定容器的大小尽量大一些,int N = 10000;vector<int>nums(N);像STL中的hashtable用的vector就是为了减少扩容次数而设置了默认的初始大小,所以定义unordered_map时即使没有指定大小,他也不是空的,而是有个初始值。
2,当后续需要新增元素的时候,不再是傻乎乎的一个个接着push_back,然后超出容量就按默认的机制2倍2倍的扩,而是先预估后续还需要多大容量,就指定大小,用nums.reserve(N),这样一步到位,不需要多次扩容,当然实际中也往往只能减少扩容次数。
3,给vector存储的元素类型实现移动构造。
有些帖子说用emplace_back,实际上这是直接原地构造函数,当类A有移动构造函数的时候,push_back和emplace_back都是调用移动构造,而emplace_back(20)这种传入构造对象所需参数才是优化,使得vector直接原地构造对象,不需要再调用拷贝构造或者移动构造(emplace的优化是不需要你先构造好对象再复制/移动进vector),但vector这里已经有多余空间。
这种地方优化的是在vector空间够用,往里面新增元素的时候,和扩容没啥关系,所以讨论扩容优化的时候,不应该往emplace_back上去扯。
在vector的扩容过程中,可以用移动语义优化这个拷贝过程(对容器里存的数据类的设计提出要求):
因为拷贝的时候,是挨个调用元素的拷贝构造函数,而且拷贝构造完还要把原vector里的各个元素挨个调用析构函数。
那如果是直接将对象从旧的内存移动到新的内存上呢?这样不就不需要再析构了,只是匹配构造函数的时候,把拷贝构造替换成移动构造,具体移动构造做了啥,那得看vector里面存的元素它的移动构造怎么实现的。
比如下图中的类A,每个对象就一个属性,即int* ptr且指针指向堆区内存:
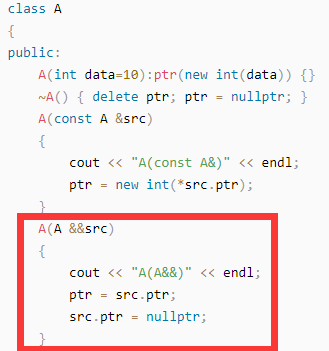
如果是调用拷贝构造函数,那新vector里除了要构造这些对象,给对象属性赋值,还要把对象掌管的堆区资源再new出一块。
要是每个对象里面掌管了很多堆区资源呢,那就要新new出很多堆区内存(注意不要和vector的内存混淆,它只保存对象!不保存对象自己里面指针指向的内存,我们用sizeof(对象名)计算对象大小时也是这样,不计算对象的指针成员所指向的内存大小,只计算指针自己占用多少)。而且还要把原先的vector上每个元素,指向的堆区内存都释放干净!
如果是移动构造,那我只要在新vector处构造出对象a1等,然后把对象a1等指针指向的内存接管起来,我不用再new了,当然这里的移动构造函数,实现了ptr指向的内存的移动,使得新vector处的对象只要构造出ptr这个指针即可,这个指针指向原先那个内存。
因为vector的里面每个元素都存在堆区,所以ptr也是在堆区,但是这个ptr没法移动吧,再说一个int* ptr构造多容易,所以这里类A的移动构造只实现了ptr指向资源的移动,当然具体取决于类A的实现。
一般的移动构造函数都只会实现一个类里含有的堆资源的移动而不包括成员属性本身;
因为一般情况用移动构造是局部对象a快出作用域了(即将消亡的对象),那栈上资源不需要析构函数也能被回收,只有堆区的需要接管所有权,减少拷贝构造和析构的开销。
这个优化后的扩容过程如下所示,扩容前是vec1,扩容后是vec2,里面每个元素都有些指针指向其它堆区内存处(vector里存放的元素本身也存在堆区,所以是堆区指针指向堆区)
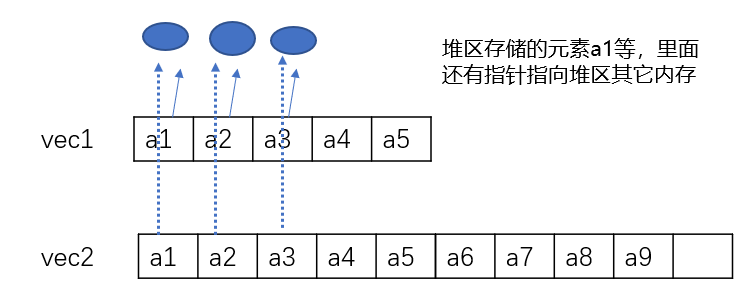
要是用的拷贝构造,那就是对每个元素a1,a2,a3…重新new出堆内存,还要把原有的堆内存(蓝色)free掉。时间和空间上,都很低效。
注意这种优化并不是针对vector的源码,因为这个过程只需要类A自己实现,不需要vector做什么,vector里面的construct()函数根据传入的a的类型来仲裁是调用移动构造还是拷贝构造。
注意上面类A的移动构造函数有缺漏!!!
当我们使用vector,对里面存储的元素的类写移动构造函数时需要注意,一定要加noexcept关键字,否则编译器自动会执行拷贝构造函数,因为vector有强异常安全保证
下图来自博客,节选自《C++性能优化指南》



![[架构之路-200]- 性能需求与性能分析:影响性能的主要因素](https://img-blog.csdnimg.cn/20210928172207220.png?x-oss-process=image/watermark,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAZHhtZHhtMTIz,size_20,color_FFFFFF,t_70,g_se,x_16)