1.入口类 sparkSubmit 的main方法 提交application
submit=new SparkSubmit
submit.doSubmit(args) ->
super.doSubmit(args):
parseArguments(args) :参数解析
方法 中 new sparkSubmitArguments(args) 点进去该类(主要解析参数),然后找到parse(args.asJava):{ Pattern eqSeparatedOpt = Pattern.compile("(--[^=]+)=(.+)"); 正则表达式对命令行参数做分解,得到参数名称和值,里边的handle用来做处理,这个handle实际执行的是SparkSubmitArguments 类中的handle方法
}
SparkSubmitArguments 中handle 中点击MASTER( 进入到 类SparkSubmitOptionParser 中的MASTER = "--master" 对应脚本中的参数)
然后点击 sparkSubmitArguments 中找action
action = Option(action).getOrElse(SUBMIT) 默认是提交
回到 SparkSubmit
发现 case SparkSubmitAction.SUBMIT => submit(appArgs, uninitLog)的默认是提交
点进去 submit 发现
if (args.isStandaloneCluster && args.useRest)else {
doRunMain() --点进去
}
if (args.proxyUser != null) { 判断命令行参数是否有代理用户,没有 然后进入else
else {
runMain(args, uninitLog) --运行我们的主程序,点进去
}
runMain 中
**val (childArgs, childClasspath, sparkConf, childMainClass) = prepareSubmitEnvironment(args)** 准备提交的环境
val loader = getSubmitClassLoader(sparkConf) 类加载器
mainClass = Utils.classForName(childMainClass) 反射根据类的名称获得类的信息
```scala
val app: SparkApplication = if (classOf[SparkApplication].isAssignableFrom(mainClass)) {-- 该类是否继承SparkApplication(YarnClusterApplication 继承了),是的话反射创建该对象
mainClass.getConstructor().newInstance().asInstanceOf[SparkApplication]
} else {
new JavaMainApplication(mainClass)
}
app.start(childArgs.toArray, sparkConf) --启动它
```
注意:prepareSubmitEnvironment中childMainClass 赋值的地方
childMainClass = YARN_CLUSTER_SUBMIT_CLASS(org.apache.spark.deploy.yarn.YarnClusterApplication)
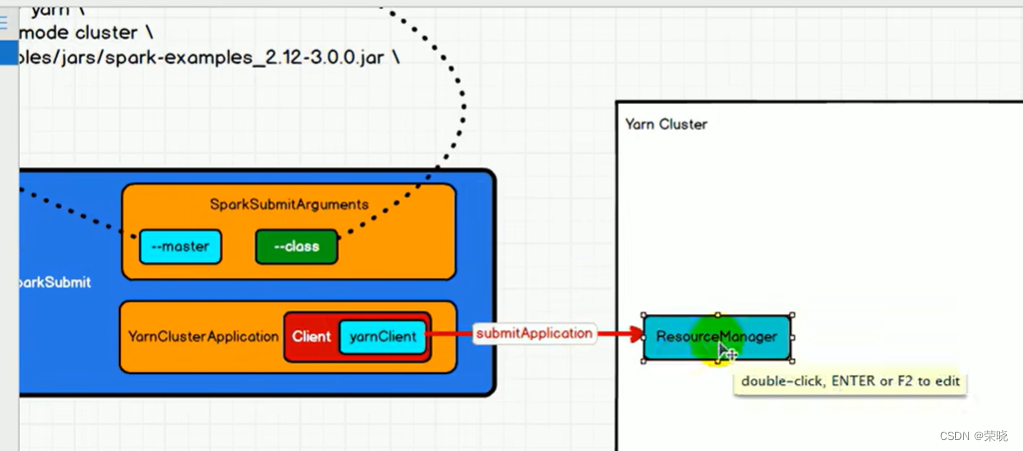
3. YarnClusterApplication 提交启动ApplicationMaster
(new Client(new ClientArguments(args), conf, (RpcEnv)null)).run()
ClientArguments 点进去parseArgs 主要是解析参数
new Client点进去-》YarnClient.createYarnClient -》new YarnClientImpl(){
该对象中的变量 rmClient(yarn当中的资源调度节点)
}
此时,客户端已经创建好了,点击run方法
submitApplication() 提交应用程序返回appid,点进去{
launcherBackend.connect()
yarnClient.init(hadoopConf)
yarnClient.start() 客户端启动
val newApp = yarnClient.createApplication()--告诉resourceManager要创建应用
appId = newAppResponse.getApplicationId() 创建会有响应,得到全局id
val containerContext = createContainerLaunchContext(newAppResponse) {--创建容器的启动环境
val amClass =
if (isClusterMode) {--如果是集群模式
Utils.classForName("org.apache.spark.deploy.yarn.ApplicationMaster").getName
} else {
Utils.classForName("org.apache.spark.deploy.yarn.ExecutorLauncher").getName
}
val amArgs =
Seq(amClass) ++ userClass ++ userJar ++ primaryPyFile ++ primaryRFile ++ userArgs ++
Seq("--properties-file",
buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, SPARK_CONF_FILE)) ++
Seq("--dist-cache-conf",
buildPath(Environment.PWD.$$(), LOCALIZED_CONF_DIR, DIST_CACHE_CONF_FILE))
val commands(包装指令) = prefixEnv ++
Seq(Environment.JAVA_HOME.$$() + "/bin/java", "-server") ++
javaOpts ++ amArgs ++
Seq(
"1>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stdout",
"2>", ApplicationConstants.LOG_DIR_EXPANSION_VAR + "/stderr")
amContainer.setCommands(printableCommands.asJava) 提交指令给RM(RM得到指令后,在NodeManger 中启动ApplicationMaster)
集群模式:amClass =org.apache.spark.deploy.yarn.ApplicationMaste
/bin/java org.apache.spark.deploy.yarn.ApplicationMaster
}
val appContext = createApplicationSubmissionContext(newApp, containerContext)--创建提交环境
yarnClient.submitApplication(appContext) --建立RM的链接,等同于提交
点appContext进去 createApplicationSubmissionContext
}
3.ApplicationMaster【进程】 根据参数启动Driver线程并初始化SparkContext
ApplicationMaster 点击进入伴生对象中的main方法 {
ApplicationMasterArguments 解析参数
master = new ApplicationMaster(amArgs, sparkConf, yarnConf){
new YarnRMClient() 点{
amClient: AMRMClient[ContainerRequest] = _ --applicationMaster连接RM之间的客户端}}
master.run() -》 runDriver {
userClassThread = startUserApplication(){-- 非常重要,启动用户的应用程序的线程
val mainMethod = userClassLoader.loadClass(args.userClass)
.getMethod("main", classOf[Array[String]]) 类加载器找到用户的main方法
mainMethod.invoke(null, userArgs.toArray) 调用main方法,初始化创建SparkContext
userThread.setName("Driver") 该线程命名为driver
userThread.start()
}
val sc = ThreadUtils.awaitResult(sparkContextPromise.future,
Duration(totalWaitTime, TimeUnit.MILLISECONDS)) --线程的主射功能,等待sparkcontext的结果,上下文的坏境对象
sc.env.rpcEnv --通信环境
registerAM --注册AM,申请资源
createAllocator --分配器{
allocator =client.createAllocator( -- 这里边的客户端就是yarnRMClient,创建一个分配器
allocator.allocateResources() {点进去-- 得到可分配的资源
val allocatedContainers = allocateResponse.getAllocatedContainers() 得到可分配的资源
handleAllocatedContainers(allocatedContainers.asScala) {--处理可用于分配的容器,将申请到的容器进行分类,分布在不同的机架上,或者同一个NodeManager 首选位置
runAllocatedContainers(containersToUse){--运行已分配的container
for (container <- containersToUse) 挨个遍历容器
if (runningExecutors.size() < targetNumExecutors) { --判断现在运行的资源是否小于我们需要的资源
numExecutorsStarting.incrementAndGet()
if (launchContainers) {
launcherPool.execute().run{线程池(ExecutorRunnable)启动Executor
nmClient.start() --
startContainer(){
val commands = prepareCommand() {
/bin/java", "-server"
*org.apache.spark.executor.YarnCoarseGrainedExecutorBackend* --进程,excutor的通讯后台
} ---准备指令,启动容器
nmClient.startContainer(container.get, ctx) 其中的nmClient 启动容器,ctx 环境信息,
} --启动container
}-
}
}
}
}
}
}
3.YarnCoarseGrainedExecutorBackend:进程(也可以理解为executor)
Backend:后台
Endpoint:终端
RpcEndpoint:通信终端( constructor -> onStart -> receive* -> onStop})生命周期
CoarseGrainedExecutorBackend.run(backendArgs, createFn){ 点进去该方法
val fetcher = --找到driver,和driver有连接
SparkEnv.createExecutorEnv
env.rpcEnv.setupEndpoint (“Executor”,-在整个通讯环境中增加一个终端 execuor
def setupEndpoint(name: String, endpoint: RpcEndpoint): RpcEndpointRef(抽象,实现的类是NettyRpcEnv){
dispatcher.registerRpcEndpoint(name, endpoint) {–注册rpc的通信终端
val addr = RpcEndpointAddress(nettyEnv.address, name) 通信地址
val endpointRef = new NettyRpcEndpointRef(nettyEnv.conf, addr, nettyEnv) --ref通信引用
var messageLoop: MessageLoop = nu --消息循环器
匹配成功创建 DedicatedMessageLoop(
private val inbox = new Inbox(name, endpoint) {
messages.add(OnStart)–当前节点有个收件箱,可以往里边发消息,发给自己
}–收件箱
threadpool --线程池
)
}
}
backendCreateFn就是当前的YarnCoarseGrainedExecutorBackend 继承的IsolatedRpcEndpoint(应该遵循生命周期)
当往inbox发送了一个Onstart之后,IsolatedRpcEndpoint 就会收到消息
}
override def onStart():{
rpcEnv.asyncSetupEndpointRefByURI(driverUrl).flatMap { ref =>. --得到了driver
driver = Some(ref)
ref.ask[Boolean](RegisterExecutor() -第七步: 向driver发起一个请求,注册executor,
self.send(RegisteredExecutor)–给自己发送注册成功的消息 第八步:注册成功
}
}
driver (指driverRpc的通信句柄) 收到请求后找SparkContext(
_schedulerBackend: SchedulerBackend = _ --通信后台 其集群模式的实现类为CoarseGrainedSchedulerBackend
)
点进去该类CoarseGrainedSchedulerBackend(
receiveAndReply(context: RpcCallContext) {–接收上边的注册executor的消息
case RegisterExecutor {
totalCoreCount.addAndGet(cores)
totalRegisteredExecutors.addAndGet(1) 资源做增加
context.reply(true) --响应注册成功
}
}
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor=>
logInfo(“Successfully registered with driver”)
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false,
resources = _resources)
driver.get.send(LaunchedExecutor(executorId)) --启动,
然后 CoarseGrainedExecutorBackend接受到消息
override def receive: PartialFunction[Any, Unit] = {
case RegisteredExecutor=>
logInfo(“Successfully registered with driver”)
executor = new Executor(executorId, hostname, env, userClassPath, isLocal = false,
resources = _resources)
driver.get.send(LaunchedExecutor(executorId)) --发送LaunchedExecutor消息,
CoarseGrainedSchedulerBackend 接收到该消息
case LaunchedExecutor(executorId) => --增加核数
executorDataMap.get(executorId).foreach { data =>
data.freeCores = data.totalCores
}
makeOffers{}
第九步:创建executor 计算对象
executor自己调度自己
)
然后回到ApplicationMaster
runDriver {–完成了注册am和createAllocator
resumeDriver() 继续运行driver,即用户的代码初始化sparkContext后,继续往下走
userClassThread.join()
}
sparkContext(
_taskScheduler.postStartHook() 实现类TaskSchedulerImpl
override def postStartHook(): Unit = {
waitBackendReady()
}
YarnClusterScheduler 继承TaskSchedulerImpl
private[spark] class YarnClusterScheduler(sc: SparkContext) extends YarnScheduler(sc) {
logInfo(“Created YarnClusterScheduler”)
override def postStartHook(): Unit = {
ApplicationMaster.sparkContextInitialized(sc) --当前的初始化环境已经完成了,让ApplicationMaster 中的val sc = ThreadUtils.awaitResult 继续往下执行
super.postStartHook() {点进去进入TaskSchedulerImpl的该方法,然后再点击waitBackendReady :死循环,backend一直在等待,我们的程序往下走
}
logInfo(“YarnClusterScheduler.postStartHook done”)
}
}
ApplicationMaster 中
resumeDriver():driver通知sparkcontext继续走下去,自己写的代码就可以继续执行
userClassThread.join()
)
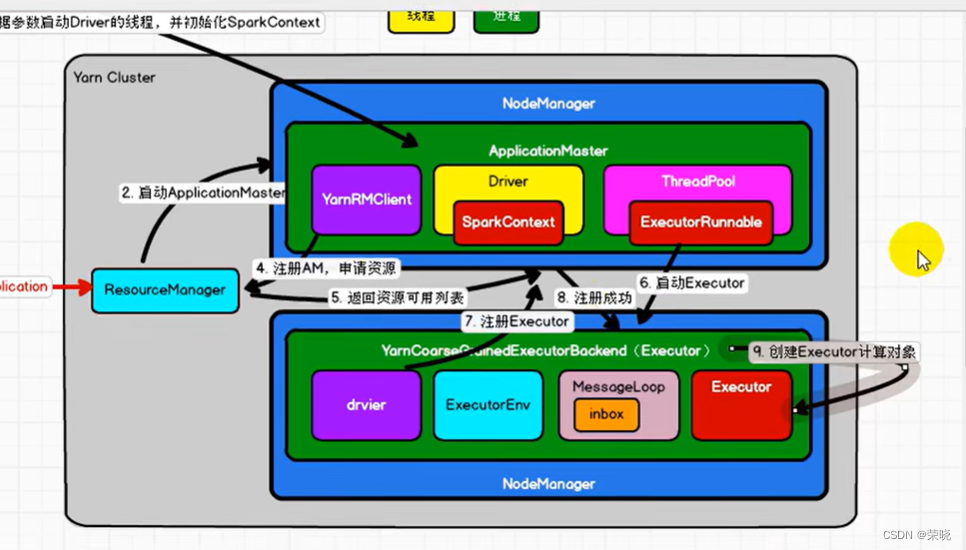
自此:整个提交流程和环境就执行好了
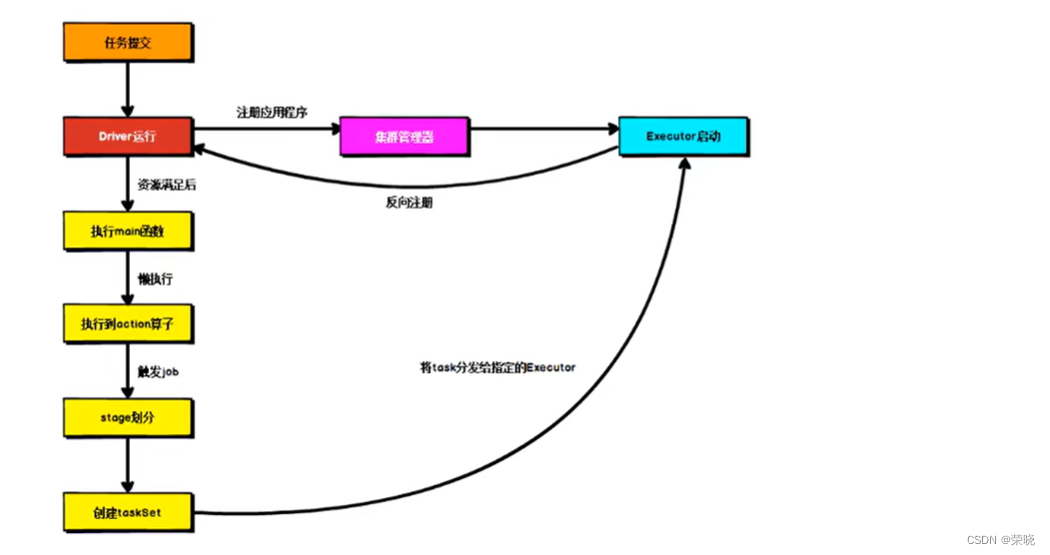
driver线程执行的过程中,注册应用程序是阻塞的,当反射执行main方法的时候,去创建SparkContext并完成初始化之后,通知注册应用程序继续执行,当executor反向注册之后,然后通知action算子继续执行
SparkEnv spark的
createSparkEnv -》{
SparkEnv.createDriverEnv->{
create ->{
RpcEnv.create ->{
NettyRpcEnvFactory().create ->{
NettyRpcEnv
nettyEnv.startServer(config.bindAddress, actualPort)->{
transportContext.createServer ->{
return new TransportServer(Epoll 模式) ->{
init(hostToBind, portToBind) ->{
IOMode—io模式
getServerChannelClass -》 case NIO:
}
}
}
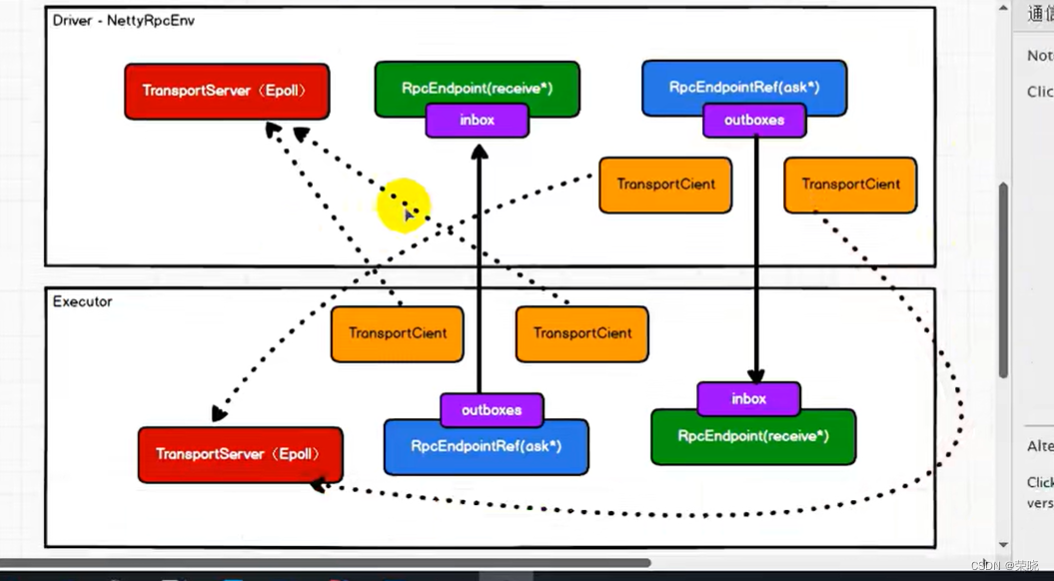
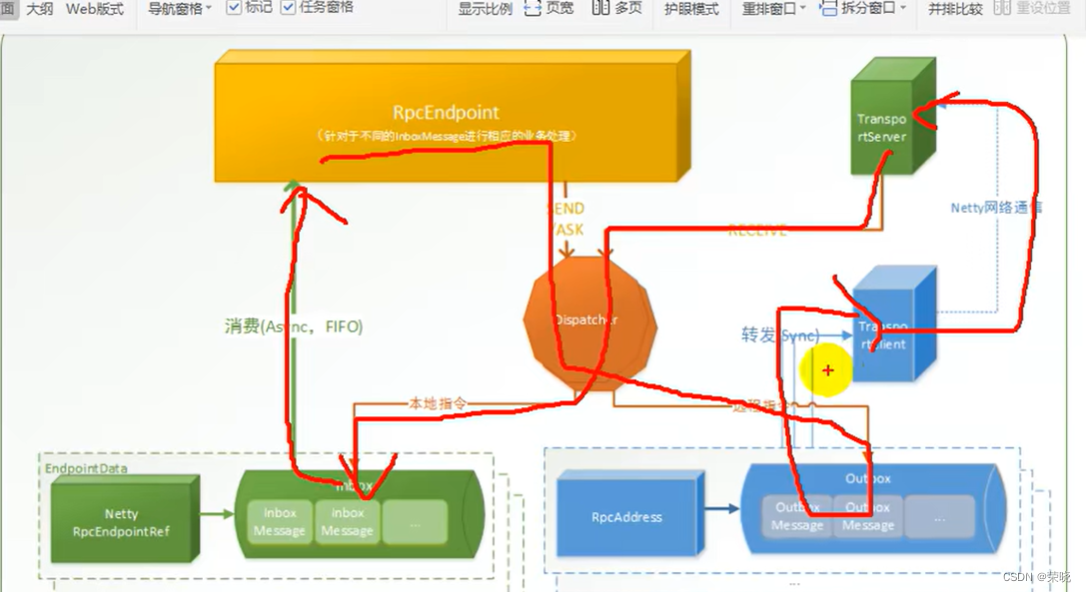
dispatcher.registerRpcEndpoint – 通讯终端(RpcEndpoint(inbox收件箱) 收数据receive,RpcEndpointRef(outboxes 发件箱) 主要是ask, Dispacher 调度的)
}
Utils.startServiceOnPort ->{
startService(tryPort)
}
}
}
}
}
}