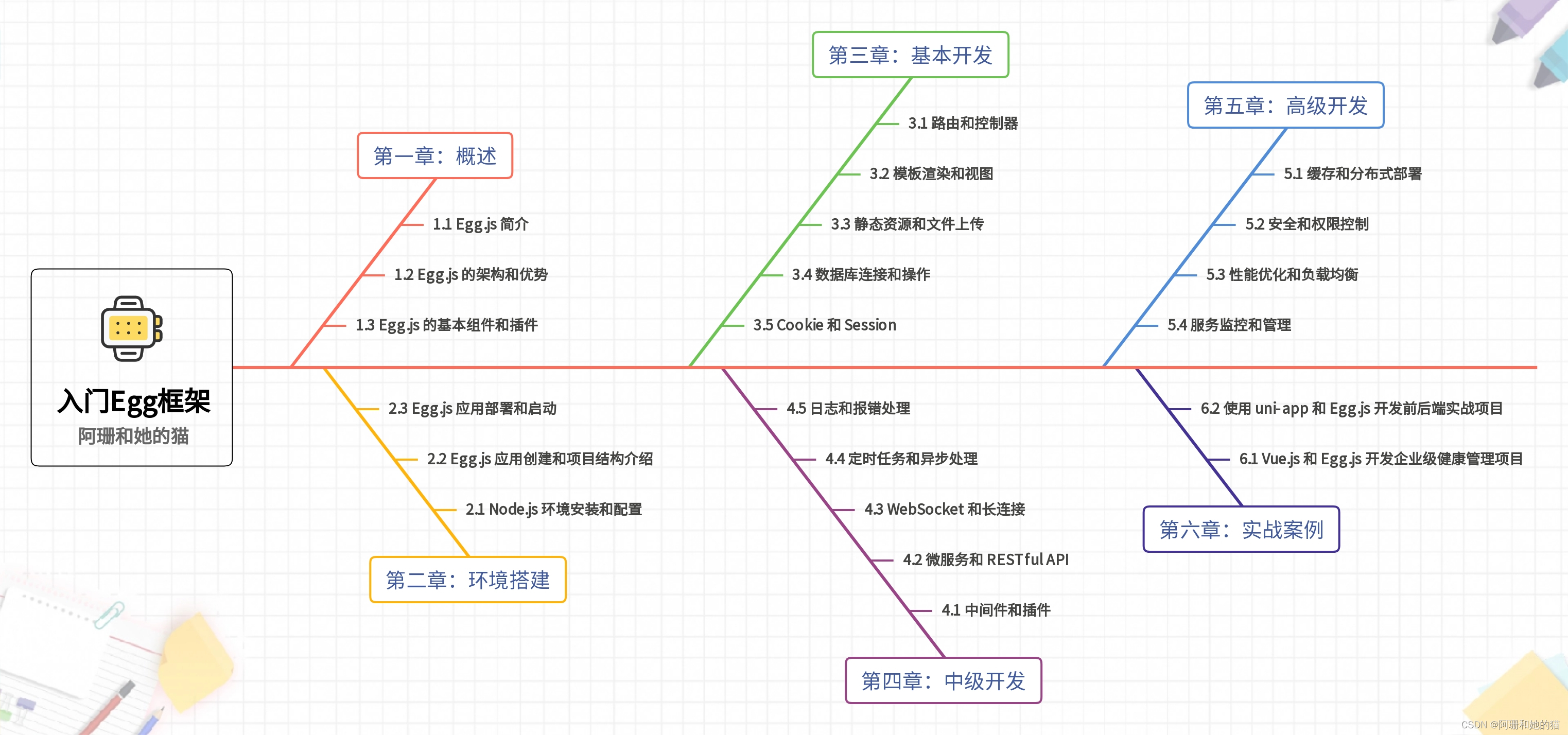
C/C++ 内存分布
在C/C++ 当中有 :
- 局部数据
- 静态数据和全局数据
- 常量数据
- 动态申请数据
上述不同的数据存储的位置也不同,:
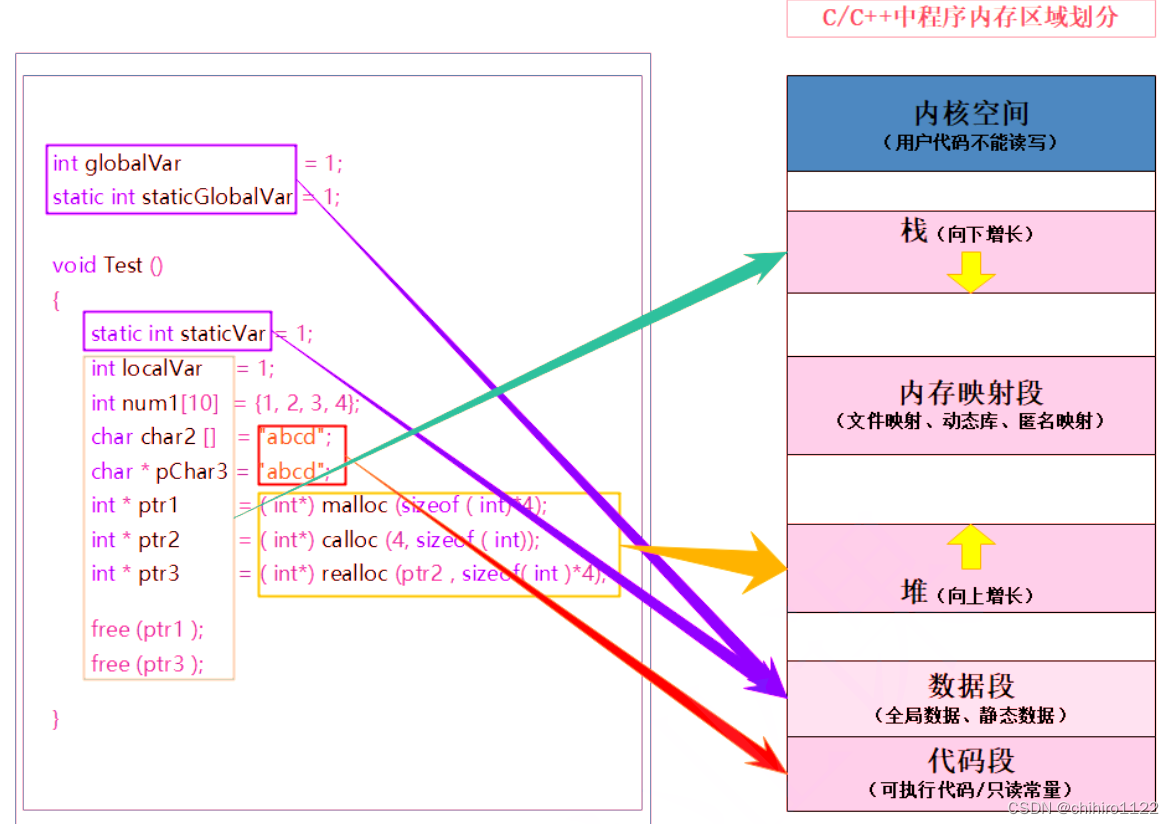
- 1. 栈又叫堆栈--非静态局部变量/函数参数/返回值等等,栈是向下增长的。
- 2. 内存映射段是高效的I/O映射方式,用于装载一个共享的动态内存库。用户可使用系统接口
- 创建共享共享内存,做进程间通信。(Linux课程如果没学到这块,现在只需要了解一下)
- 3. 堆用于程序运行时动态内存分配,堆是可以上增长的。
- 4. 数据段--存储全局数据和静态数据。
- 5. 代码段--可执行的代码/只读常量
C语言中动态内存管理方式:malloc/calloc/realloc/free
void Test()
{
int* p1 = (int*)malloc(sizeof(int));
free(p1);
// 1.malloc/calloc/realloc的区别是什么?
int* p2 = (int*)calloc(4, sizeof(int));
int* p3 = (int*)realloc(p2, sizeof(int) * 10);
// 这里需要free(p2)吗?
free(p3);
}上述的 p2 不一定需要 free,解释在下。此时只需要做的是,把 p2 这个指针给置空。
问:
malloc , realloc , calloc 的区别:
- malloc 的空间不会初始化,而 calloc 的空间会初始化。
- realloc 是对已有的空间进行阔扩容,而且realloc 函数传入的需要扩容的空间必须的是 malloc, calloc,或者是realloc的空间,假设如果是栈上的空间是,那么传入这个空间是不能使用 realloc函数进行扩容的。
- 而且 realloc 函数扩容分为两种, 一种是原地扩容,如果在原空间的后面,有足够的的空间进行扩容,那么就直接在后面进行扩容,此时返回的指针就是原空间的首地址;另一种是 异地扩容,如果原空间后面 没有足够的空间,那么realloc就会重新开辟空间,然后把 原空间当中的 数据拷贝过来,然后再把袁孔建free掉,返回的指针是新开辟空间的 首地址。
malloc 的实现原理:【CTF】GLibc堆利用入门-机制介绍_哔哩哔哩_bilibili
C++内存管理方式
C++ 当中可以使用在 C 当中使用的 内存管理的方式,但是C++当中也有自己的实现方式。
使用 new / delete 来创建和销毁空间
int main()
{
// C 当中的玩法
int* p1 = (int*)malloc(sizeof(int));
// C++ 当中的玩法
// 创建一个 int 大小的 空间
int* p2 = new int;
// 创建三个 int 大小的 空间
int* p3 = new int[3];
// 创建 一个 int 大小的 空间,并且把这个空间当中的值初始化为 10
int* p4 = new int(10);
delete p1;
delete p2;
delete[] p3;
delete p4;
return 0;
}需要注意的是 如果是多个 某类型大小的,那么在使用 delete的时候需要在后面加一个 " [] "。
- 在new当中在类型的后面使用 " () " 来给这个空间当中给初始值。
- 在new当中在类型的后面使用 " [] " 来决定创建的空间有几个类型大小。
- 在new当中初始化一个数组,不能用 " () " 而是直接使用 " { } " 来一个元素,按照下标的顺序来初始化
如果我们初始化没有初始化完,剩余没有初始化的会初始化为 0 :
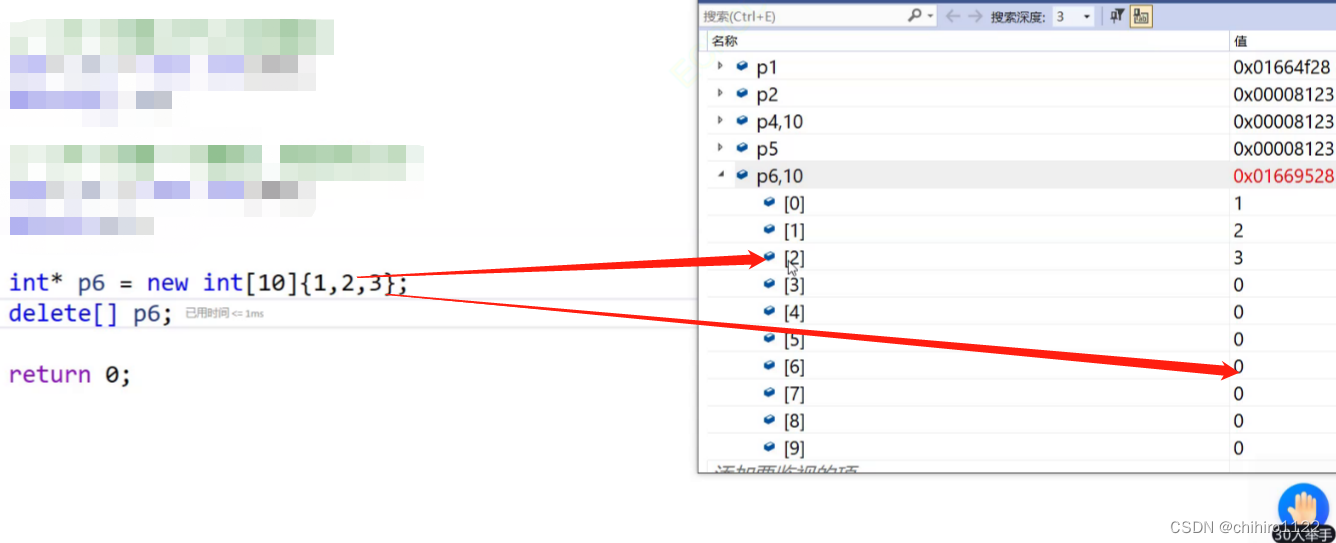
这里的new 对于内置类型,效果都差不多,C++当中的 new 主要针对的是 自定义类型,比如我们创建一个 单链表的结点,在C当中是这样的:
typedef struct ListNode
{
int _val;
struct ListNode* next;
}ListNode;
ListNode* BuynewNode(int x)
{
ListNode* tmp = (ListNode*)malloc(sizeof(ListNode));
if (tmp == NULL)
{
perror("malloc fail");
return;
}
tmp->_val = x;
tmp->next = NULL;
return tmp;
}
int main()
{
// C 实现
ListNode* p1 = BuynewNode(1);
ListNode* p1 = BuynewNode(2);
ListNode* p1 = BuynewNode(3);
return 0;
}因为malloc 是单纯的开辟空间,不能进行初始化,所以我们要自己进行初始化,而且malloc 有可能会开辟失败,我们还要判断一下。
就算使用 calloc 也不好,也 calloc 只能全部初始化为 0 ,而有的时候我们不想要都赋值为0,所以这就是 在C++当中要 新增 new的原因,当我们 new 一个自定义的类型的对象的时候,就可以 同时调用这个对象的构造函数,其中就可以进行初始化:
struct ListNode
{
int _val;
struct ListNode* _next;
ListNode(int x)
:_val(x)
,_next(NULL)
{}
};
int main()
{
ListNode* nn1 = new ListNode(1);
ListNode* nn1 = new ListNode(2);
ListNode* nn1 = new ListNode(3);
return 0;
}向上述就是 使用new (开空间 + 调用构造函数初始化),不用再像 C 当中使用 malloc 函数,需要写个函数来 初始化,而且 还需要判断 malloc 是否成功,调用 malloc 需要计算 类型的大小,还需要把malloc函数的返回值 强转 为 我们对应类型的指针,等等的这些复杂操作。
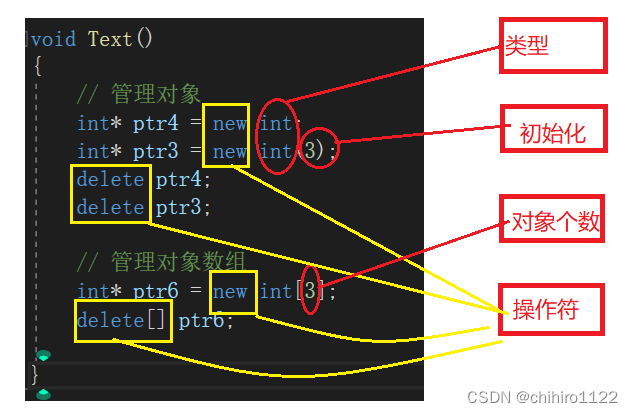
malloc 和 free 就只是开辟空间和 释放空间,不会进行初始化,而且我们在使用 new 和 delete 的时候就会调用这个自定义类型的构造函数和 析构函数: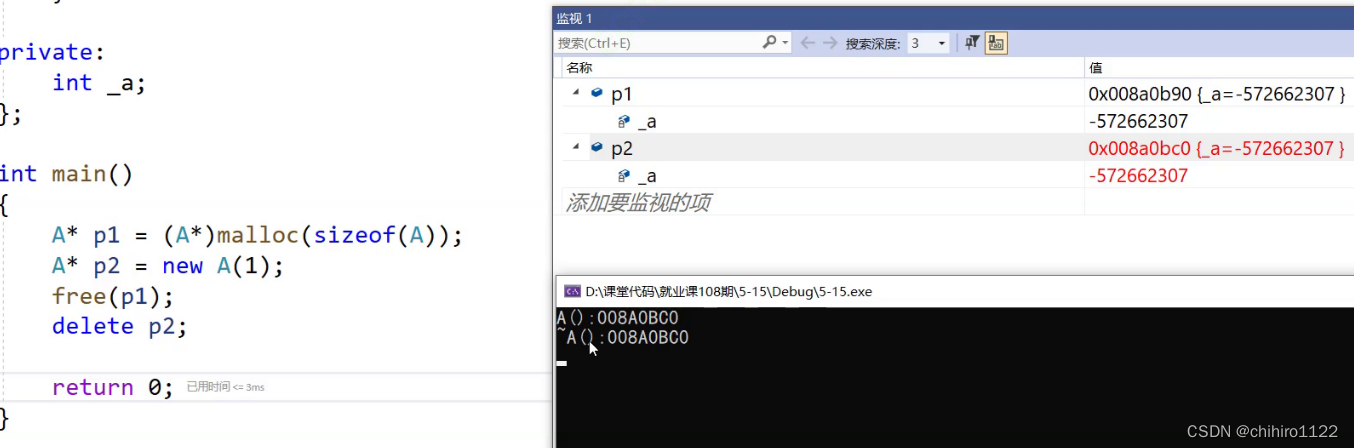
我们把调用析构函数和 构造函数时,打印一下这个函数名称,如上述所示,我调试发现, new 和 delete 都会调用 对应的 构造函数和 析构函数。
如果没有默认的构造函数,我们还可以使用 {} 来传参:
class A
{
public:
A(int a)
{
_a = a;
cout << "A(int a = 10)" << endl;
}
~A()
{
cout << "~A()" << endl;
}
protected:
int _a = 0;
};
int main()
{
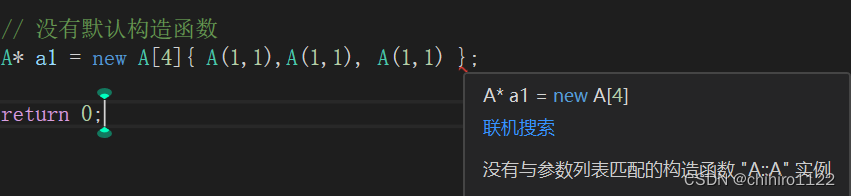
A* a1 = new A[4]{ 1,2,3,4 };
return 0;
}如上述类 A 是没有默认构造函数的,如果这个类当中构造函数只有一个参数,那么我们就可以直接传入 对应类型的 数据,这里就会发生隐式类型转换。
而如果是多个参数的,如下所示:
A(int a, int b)
{
_a = a;
_b = b;
cout << "A(int a = 10)" << endl;
}那么我们可以使用 匿名对象的方式传参,进行初始化:
A* a1 = new A[4]{ A(1,1),A(1,1), A(1,1), A(1,1) };而且此时我们不能使用 之前一个参数的时候传参的方式了:

而且像上述的 使用匿名对象来赋值的 编译器会进行优化,不会调用拷贝构造函数。
如果,没有默认构造函数,那么这个 数组中有多少个 对象,那么就必须对这个数组当中的每一个对象都要进行初始化;如果有默认构造函数,那么我们就可以选择性的选择几个对象来进行初始化。

还需要注意是的,如果使用 new 来开辟空间,就必须使用 delete 来释放空间;如果使用 malloc 等等函数来开辟空间,就是用 free 来释放空间;如果反过来用的话,可能会出现问题。为了避免出现问题,那么还是配套使用,不要随便使用。
operator new与operator delete函数
我们上述使用 new 和 delete 都是操作符,而在系统当中其实还实现了 operator new与operator delete这两个全局函数。其实我们在使用 new 和 delete 两个操作符的时候,其底层也是调用operator new与operator delete这两个全局函数。
而new 和 malloc 的最大区别就是 new 在自定义的时候会调用构造函数。但是new 也是需要开空间的,他只不过是 在开空间的基础之上,针对 自定义类型 ,它多调用了一次构造函数。其实new 开空间就是调用 C 当中的malloc 函数来在堆当中开空间的。
那么既然是使用 malloc 函数来在堆当中开辟空间,但是我们知道,如果malloc 函数开辟空间失败之后,就会返回一个空指针,C++是面对对象的语言,面对对象的语言在出错的时候不喜欢像C 一样返回一个 -1 ,它喜欢抛出异常,那抛出异常就需要捕获异常。
例如,我们写一个循环,一直 malloc 空间,直到 malloc 放回空指针为止:
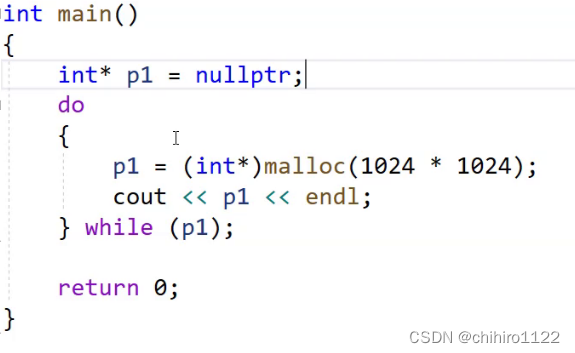
我们发现这个程序就是正常停止的,而如果我们使用new来开辟空间,同样使用这个类型的代码实现:
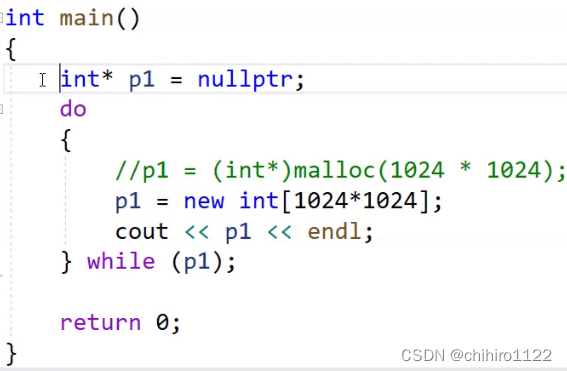
此时发现,它报了异常:
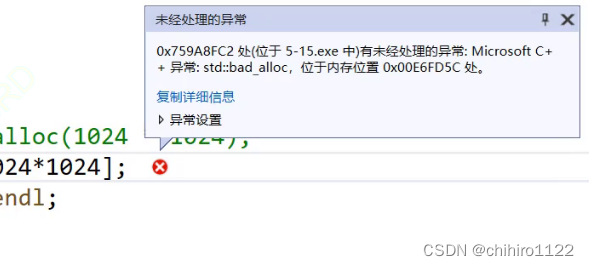
那么捕获异常,大多数语言都差不是,像java 当中就是 使用 try {} catch{} 来捕获异常,C++也是使用这个来捕获异常:
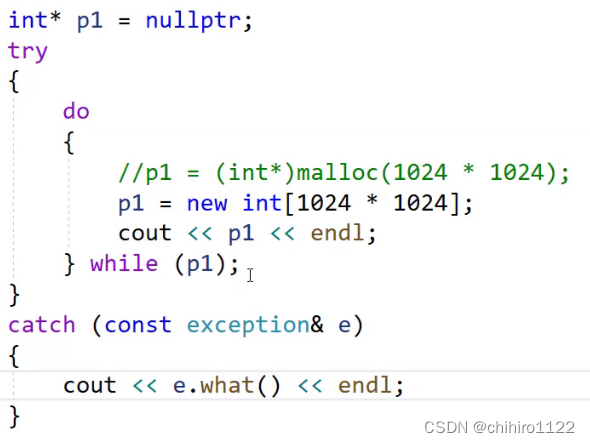
发生异常我们就 可以直接 catch 当中的处理,上述的打印值:
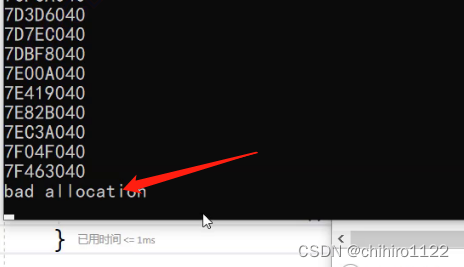
那么其实 new 操作符 调用的 operator new 函数也是实现了类型上述的功能,这个operator new函数其实就是对 C 当中的malloc函数进行的封装处理,一下是他的源代码:
/*
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间
失败,尝试执行空 间不足应对措施,如果改应对措施用户设置了,则继续申请,否
则抛异常。
*/
void* __CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{
// try to allocate size bytes
void* p;
while ((p = malloc(size)) == 0)
if (_callnewh(size) == 0)
{
// report no memory
// 如果申请内存失败了,这里会抛出bad_alloc 类型异常
static const std::bad_alloc nomem;
_RAISE(nomem);
}
return (p);
}operator delete函数源代码:
/*
operator delete: 该函数最终是通过free来释放空间的
*/
void operator delete(void* pUserData)
{
_CrtMemBlockHeader* pHead;
RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));
if (pUserData == NULL)
return;
_mlock(_HEAP_LOCK); /* block other threads */
__TRY
/* get a pointer to memory block header */
pHead = pHdr(pUserData);
/* verify block type */
_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));
_free_dbg(pUserData, pHead->nBlockUse);
__FINALLY
_munlock(_HEAP_LOCK); /* release other threads */
__END_TRY_FINALLY
return;
}
/*free 在 C当中实现:
/*
free的实现
*/
#define free(p) _free_dbg(p, _NORMAL_BLOCK)而 operator delete函数 也是一样使用的是 free()来释放空间,也是对这个free()函数就行了封装。
至此,我们就了解了 operator new与operator delete 这两个函数功能,我们也可以使用这两个函数,但是其实这两个函数不是给我们使用的,而是给 new 和 delete 来使用的,他们之间的关系如下图所示:
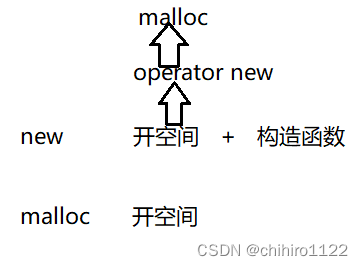
而 delete 也是差不多的:
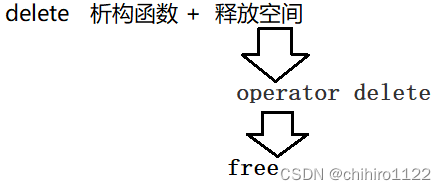
我们查看 new 的反汇编也可以看出:

new和delete的实现原理
内置类型
new和delete 在内置类型方面其实和 malloc 与 free 没有多大区别,只是 new 在开辟空间失败之后是抛出异常;而malloc 是返回一个 NULL 指针。而且 new/delete申请和释放的是单个元素的空间,new[]和delete[]申请的是连续空间。
自定义类型
对于new 和 delete 我们上述也说过了,new 是先调用 operator new 函数,来开辟空间,然后调用这里类型的构造函数;而 delete 是先调用西沟函数,然后再 调用 operator delete 释放空间。
这里主要是提, new[] 和 delete[] 这两个,顺序和上述是一样的,只是调用N次而已:
- new[] 是调用operator new函数完成N个对象空间的申请,然后在申请的空间上执行N次构造函数
- delete[] 是在释放的对象空间上执行N次析构函数,完成N个对象中资源的清理,再调用operator delete[]释放空间,实际在operator delete[]中调用operator delete来释放空间
typedef int STDataType;
class Stack
{
public:
Stack(size_t a = 3)
{
cout << "Stack(size_t a = 1)" << endl;
_array = (STDataType*)malloc(sizeof(STDataType) * _capacity);
if (_array == NULL)
{
perror("malloc fail");
return;
}
_capacity = a;
_size = 0;
}
~Stack()
{
cout << "~Stack()" << endl;
if (_array)
{
free(_array);
_array = NULL;
_capacity = 0;
_size = 0;
}
}
protected:
STDataType* _array;
int _size;
int _capacity;
};
int main()
{
Stack* ST = new Stack(3);
return 0;
}请问上述中的 Stack* ST = new Stack(3); 在内存当中是如何存储的。
ST是这个类型的指针,那么他是存储在栈上的;我们 new 出来的空间(调用operator new函数)当中存储的就是 Stack 类创建的对象当中存储的 成员:
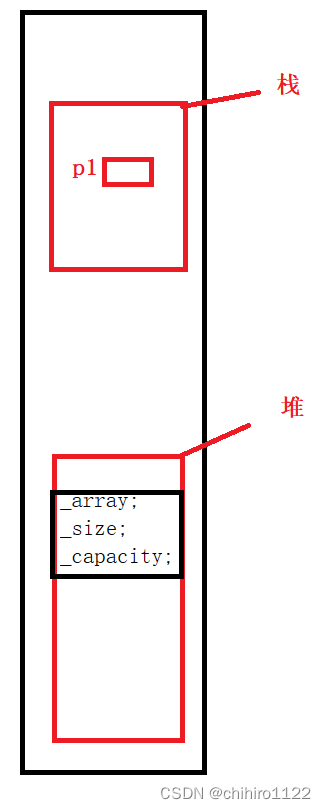
然后,再去调用构造函数,在堆上开辟空间,开辟一段数组空间,然后让 对象当中的 _array 指针指向这块空间的首地址。
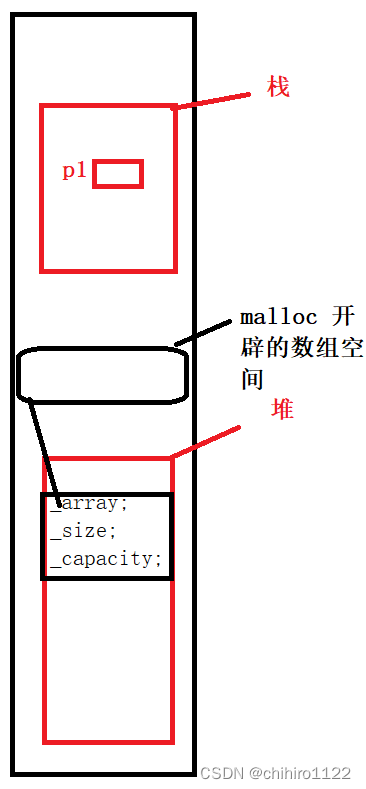
这里就是我们使用 new 创建空间的 过程,和各个变量在内存当中的分布。
我们使用delete 也是一样的,只不过他是先 调用析构函数, 再去 调用 operator delete[] 释放空间。像上述例子,就是先调用 析构函数当中的 free 掉_arrray 指针指向的 malloc 开辟的空间,然后再调用 operator delete[] 函数来释放掉 堆当中开辟的 对象的空间。
像上述的释放空间的过程是不能 反过来的,如果先free 掉 对象空间就找不到 其中 开辟的 数组空间了。
定位new表达式
new 除了可以开空间,如果是自定义类型会掉这个类型的构造函数对这个自定义类型进行初始化。
new 还可以 对已有的一块空间 ,显示调用构造函数,来对这个空间当中的成员进行初始化:
比如像上述的Stack 这个类:
Stack* ST = (Stack*)malloc(sizeof(Stack));
new(ST)Stack(3);如果在内存当中已经有这个类开辟的一个空间,那么我们就可以显示的调用构造函数,读这个空间当中的成员进行初始化。
使用语法:
new (place_address) type 或者 new (place_address) type(initializer-list)
place_address必须是一个指针,initializer-list是类型的初始化列表像上述的情况我们还可以显示的调用 析构函数来对这个对象的当中的成员空间进行 释放:
ST->~Stack();
free(ST);像上述的过程我们其实就是在模拟 new 和 detele 的过程。
问:向上述的情况,如果我们不显示调用 ST 的析构函数,它会自动调用 析构函数吗?
答:不会。因为只有自定义类型才会自动调用 构造函数和 析构函数。像上述的 ST 是 Stack* 这个类型的,是一个指针,是内置类型,所以不会自动调用。
使用场景
如果我们想要实现高效率的代码,那么有一种方法叫做 池化技术,他就是创建出很多很多的池来进行复用,从而来提升性能。如:对象池通过复用对象来减少创建对象、垃圾回收的开销。还有 连接池,内存池,线程池·······
这就好比说是,一个人住在山顶上,但是水源在山脚,那么他每一次需要水的时候,都要去山脚去取水,那么这个人做的其他的事情就会被 耽搁。那么我们就像,在山腰处 做一个蓄水池,那么这个人需要水的时候,就只需要到山脚处取水就行了,他就能更好的完成它的本职工作,从而提升工作效率。
那么,当我们从某一个池子当中,拿出一个 一块开辟好的 某一个自定义类型的空间,那么这时候我们想要去 对这个空间进行初始化,那么就要使用之前说过的 new 用法来实现了。如下例子:
Node* n1 = pool.alloc.(sizeof(Node));
new(n1)Node(2);小结
- new 和 malloc 的区别 , free 和 detele 的区别。
- malloc 和 free 是函数,而 new 和 detele 是操作符
- malloc 不能对开辟的空间进行初始化,而new可以初始化。
- malloc 在开辟空间的时候需要手动计算需要开辟空间的大小,而new 就值需要在后面跟上数据类型即可,如果需要开辟多个这个类型,那么只需要在之后 使用 [] 来指定个数即可。
- malloc 函数的返回值是 void* ,如果我们想要接收这个返回值,那么我们需要把这个指针 强转为我们需要的 指针类型。而new不需要,因为new后面跟的就是空间的类型。
- malloc 开辟空间失败之后,返回的是 NULL 指针;而 new 开辟空间失败 是抛出异常。
- 对于自定义类型 malloc 和 free 在 开辟 和 释放空间的时候,就只是开辟和释放空间;而 new 和 detele 是除了开辟和释放之外,分别会 调用 自定义类型的 构造函数 和 析构函数,以此来初始化对象和 销毁空间中的 资源。
内存泄漏
指的是,如果我们在写程序可能会疏忽或者是错误,导致程序未能释放程序已经不在使用的内存的情况。内存泄漏指的不是内存消失了,而是由于设计的失误,失去了对这块内存的 控制,因而造成了浪费。
内存泄漏的危害:长期运行的程序出现内存泄漏,影响很大,如操作系统、后台服务等等,出现
内存泄漏会导致响应越来越慢,最终卡死。
int main()
{
int* ptr1 = (int*)malloc(sizeof(int));
int* ptr2 = new int;
func();// 由于 func 函数未定义,导致抛出异常,程序异常结束,ptr2 没有来得及 释放
delete ptr2;
return 0;
}如上诉 的ptr1 和 ptr2 都每一释放空间,都属于内存泄漏。
而我们在写这些小程序的时候,多次出错,我们使用的代码环境都没有奔溃,不仅仅是我们写的程序体量太小的原因,很大原因是,我们的操作系统不会容忍一个进程 出现内存泄漏,当一个进程结束之后,他会自定把使用的内存都 回归使用权限。
内存泄漏影响的主要是 ,长期运行的程序,如果程序长期运行,那么就会有很大危害。如游戏服务,打车服务····等等。其实内存泄漏多的还好,因为可能很快就这个程序就会挂掉,那么我们检查日志相对容易发现;如果每天只是泄漏一点,比如 10MB ,那么这个程序可能在很久之后 才会奔溃,那么检查起来没有那么容易。
内存泄漏的 分类
在C/C++ 的程序当中一般都一下两种 类型泄漏:
- 堆内存泄漏(Heap leak)
堆内存指的是程序执行中依据须要分配通过malloc / calloc / realloc / new等从堆中分配的一
块内存,用完后必须通过调用相应的 free或者delete 删掉。假设程序的设计错误导致这部分
内存没有被释放,那么以后这部分空间将无法再被使用,就会产生Heap Leak。
- 系统资源泄漏
指程序使用系统分配的资源,比方套接字、文件描述符、管道等没有使用对应的函数释放
掉,导致系统资源的浪费,严重可导致系统效能减少,系统执行不稳定。
内存泄漏的检测
在vs下,可以使用 windows 操作系统提供 的函数 _CrtDumpMemoryLeaks() 函数进行简单的检测。但是这个函数只能报出有多少的字节被泄漏了,没有具体信息。
在linux下内存泄漏检测:Linux下几款C++程序中的内存泄露检查工具_testsuite kmalloc_CHENG Jian的博客-CSDN博客
在windows下使用第三方工具:
VS编程内存泄漏:VLD(Visual LeakDetector)内存泄露库_波波在学习的博客-CSDN博客
其他工具:
内存泄露检测工具比较 - 默默淡然 - 博客园 (cnblogs.com)