文章目录
- 文本三剑客&正则表达式1
- 1 sort
- 1.1 sort -f
- 1.2 sort -b
- 1.3 sort -n
- 1.4 sort -r
- 1.5 sort -u
- 1.6 sort -t
- 1.7 sort -k
- 1.8 sort -o
- 2 uniq
- 2.1 uniq -c
- 2.2 uniq -u
- 2.3 uniq -d
- 3 tr
- 3.1tr -c
- 3.2 tr -d
- 3.3 tr -s :
- 3.4 tr -t
- 4 cut
- 4.1 cut -d
- 4.2 cut -f
- 4.3 cut -b
- 4.4 cut -c
- 4.5 cut –complement
- 4.6 cut -output-delimiter
- 5 split
- 5.1 split -l
- 5.2 split -b
- 6 paste
- 6.1 paste -d
- 6.2 paste -s
- 7 通配符
- 8 基本正则表示式
- 8.1 表示次数
- 8.2 位置锚定
- 8.3 分组
- 8.4 扩展正则表示式
- 8.5 举例
文本三剑客&正则表达式1
1 sort
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序
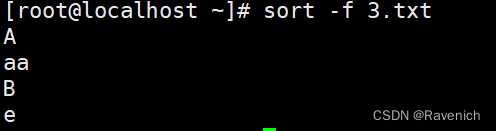
1.1 sort -f
忽略大小写,默认会大写字母排在前面
1.2 sort -b
忽略每行前面的空格
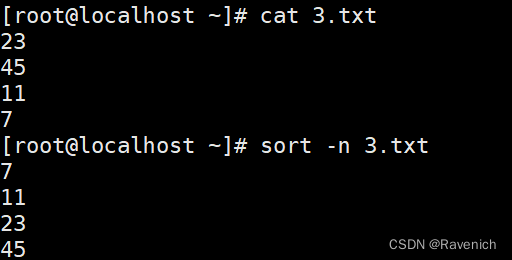
1.3 sort -n
按照数字进行排序
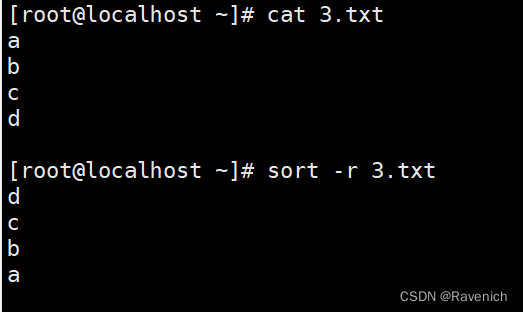
1.4 sort -r
反向排序
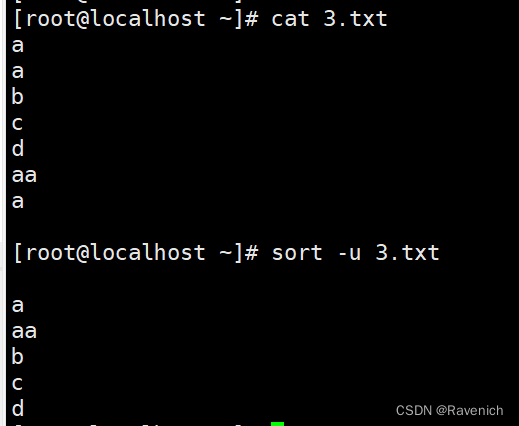
1.5 sort -u
去除重复的部分
1.6 sort -t
指定字段分隔符,默认使用tab键分隔
1.7 sort -k
指定排序字段
1.8 sort -o
将排序的结果转存至指定文件
2 uniq
用户报告或者忽略文件中连续的重复行,常与sort命令结合使用
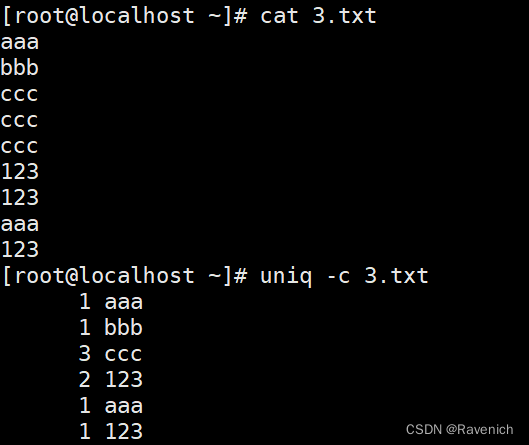
2.1 uniq -c
统计连续重复的行的次数,并且合并重复的行
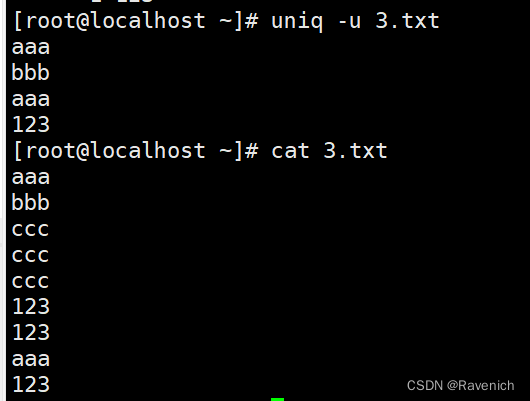
2.2 uniq -u
显示仅出现一次的行(包括不连续的重复行)
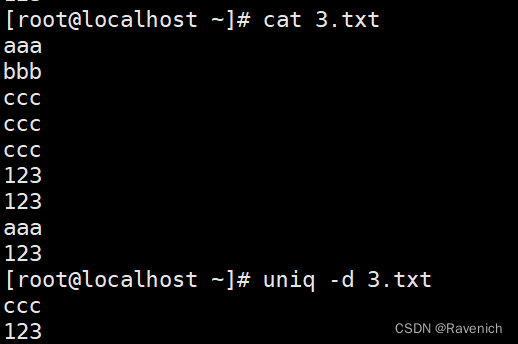
2.3 uniq -d
仅显示重复出现的行(的重复行)
3 tr
3.1tr -c
保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换

3.2 tr -d
删除所有属于字符集1的字符

3.3 tr -s :
将重复出现的字符串压缩为一个字符串,用字符集2 替换 字符集1

3.4 tr -t
字符集2 替换 字符集1,不加也行
4 cut
对字段进行截取和剪裁
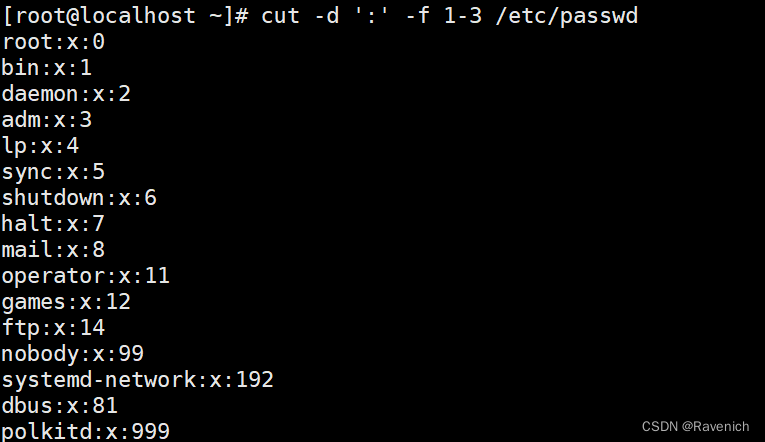
4.1 cut -d
指定分隔符(默认分隔符为Tab)
4.2 cut -f
按字段进行截取
以":"作为分隔符,指定第一个到第三个字段进行输出
4.3 cut -b
以字节为单位进行截取
4.4 cut -c
以字符为单位进行截取
4.5 cut –complement
排除所指定的字段
以:为分隔符,打印除了第二个字段
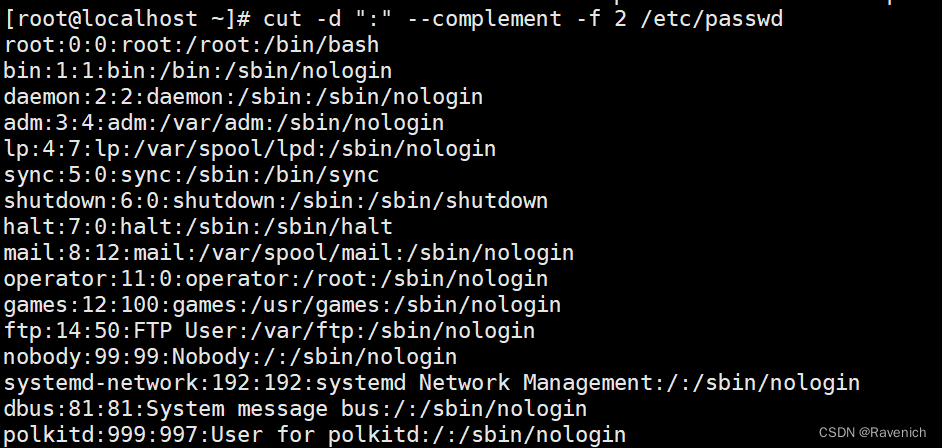
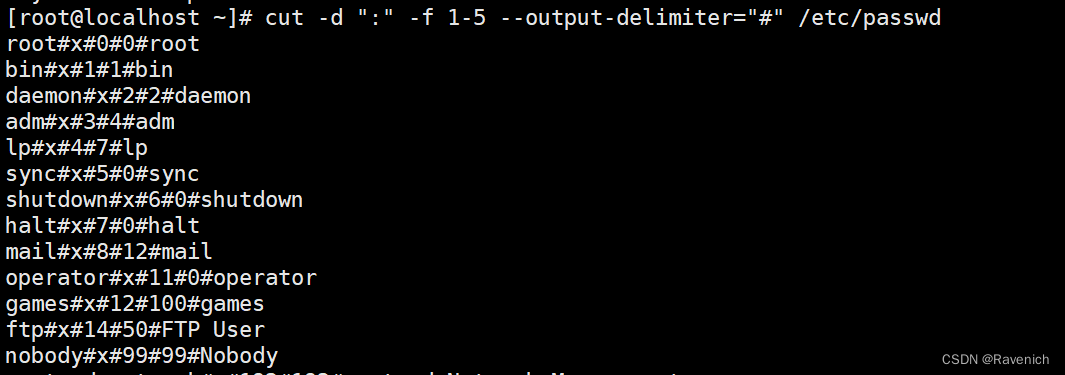
4.6 cut -output-delimiter
更改输出内容的分隔符
以:为分隔符,将1-5列的分隔符替换成#,并打印出来
5 split
用于在Linux下将大文件拆分为若干小文件。
格式:split 选项 参数 原始文件 拆分后文件名前缀
5.1 split -l
指定行数拆分

5.2 split -b
指定文件大小

6 paste
按照字段来进行文件的合并
paste是左右合并
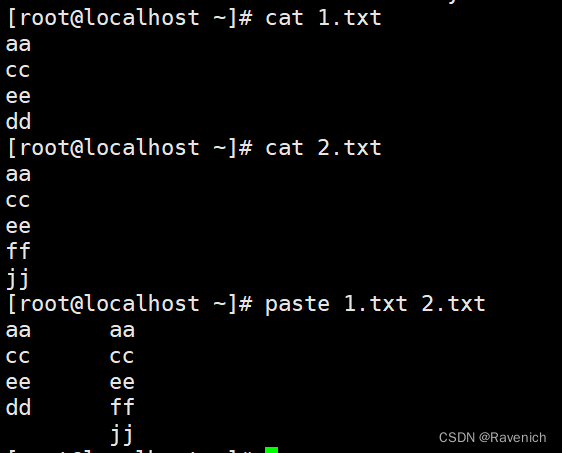
cat是上下合并
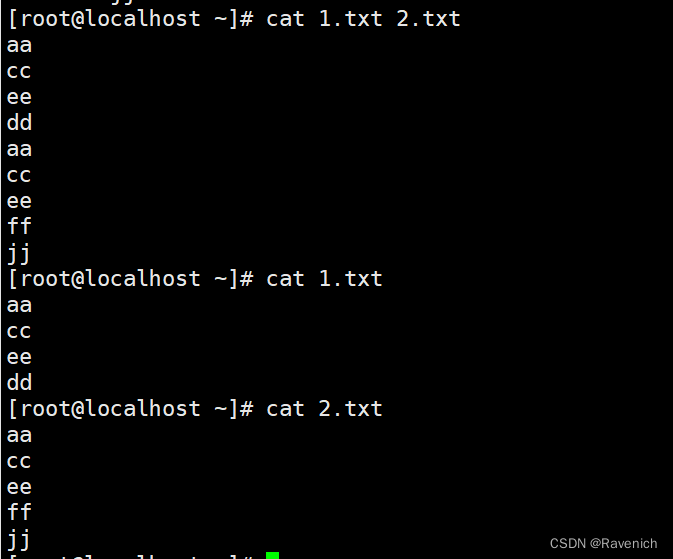
6.1 paste -d
用于指定文件的分隔符(默认情况下为制表符"\n")
6.2 paste -s
将列和行的内容进行互相交换

7 通配符
*:通配符匹配任意一个或多个字符

?:匹配一个任意字符(只能匹配一个)
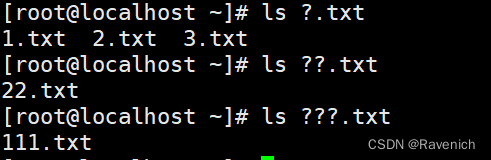
[ ] 匹配列表中的任意单个字符

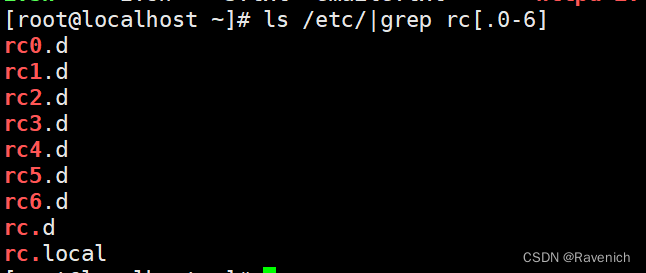
8 基本正则表示式
[a-zA-Z] #同时匹配大小写
-
匹配任意单个字符,可以是一个汉字
-
. 转义字符+. 表示单个一个点

-
匹配空格 [[:space:]]
8.1 表示次数
*匹配前面的字符任意次,包括0次
o不管有多少个,都能匹配出来,没有也可以匹配


. 任意长度的任意字符,不包括0次,也就是匹配所有*
o出现>=1次

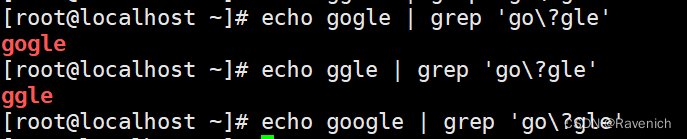
? 匹配其前面的字符出现0次或1次,即:可有可无
o只能有1个或者没有
\+ 匹配其前面的字符出现最少1次,即:肯定有且 >=1 次
o至少出现一次

\ {n \ } 匹配前面的字符n次
o只能出现2次

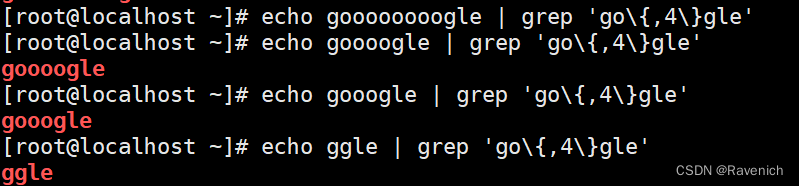
\ {m,n \ } 匹配前面的字符至少m次,至多n次
o出现至少2次,最多5次

\ {,n \ } 匹配前面的字符至多n次,<=n
g出现的次数必须小于4次,包含0次
\ {n, \ } 匹配前面的字符至少n次
o出现2次以上

8.2 位置锚定
^ 行首锚定, 用于模式的最左侧
grep “^root$” 过滤出只有root的这一行
过滤出不是以“#”开头的
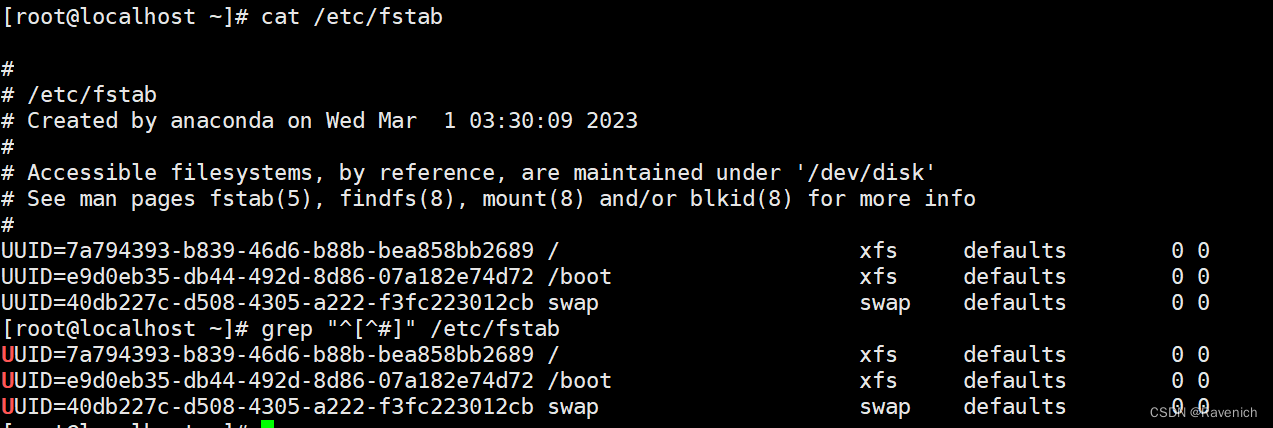
^$ 只取空行 grep “^*$”
$ 行尾锚定,用于模式的最右侧
< 或 \b 词首锚定,用于单词模式的左侧(连续的数字,字母,下划线都算单词内部)
\ > 或 \b 词尾锚定,用于单词模式的右侧
只能用于单词的匹配

8.3 分组
() 将多个字符捆绑在一起,当作一个整体处理
后面的数,是前面所要分组的字符串的倍数


\| :或者
-
匹配1或者2bc,有一个即可

-
匹配1abc或者2abc,有一个即可

8.4 扩展正则表示式
没有\,用grep -E ,用法与基本正则表示式类似
8.5 举例
- 匹配座机号
025-83346023
0510-8776655
0527-9888899

- 匹配手机号
15251391719
18851996919
15264307896

- 匹配邮箱
y@126.com
544564317@qq.com
CICIfireway@126.com
aabb556644@163.com
192AAAbc44@189.com