介绍
在使用automa浏览器插件爬取数据时,可以直接通过发送请求将爬取到的网页数据持久化到数据库中
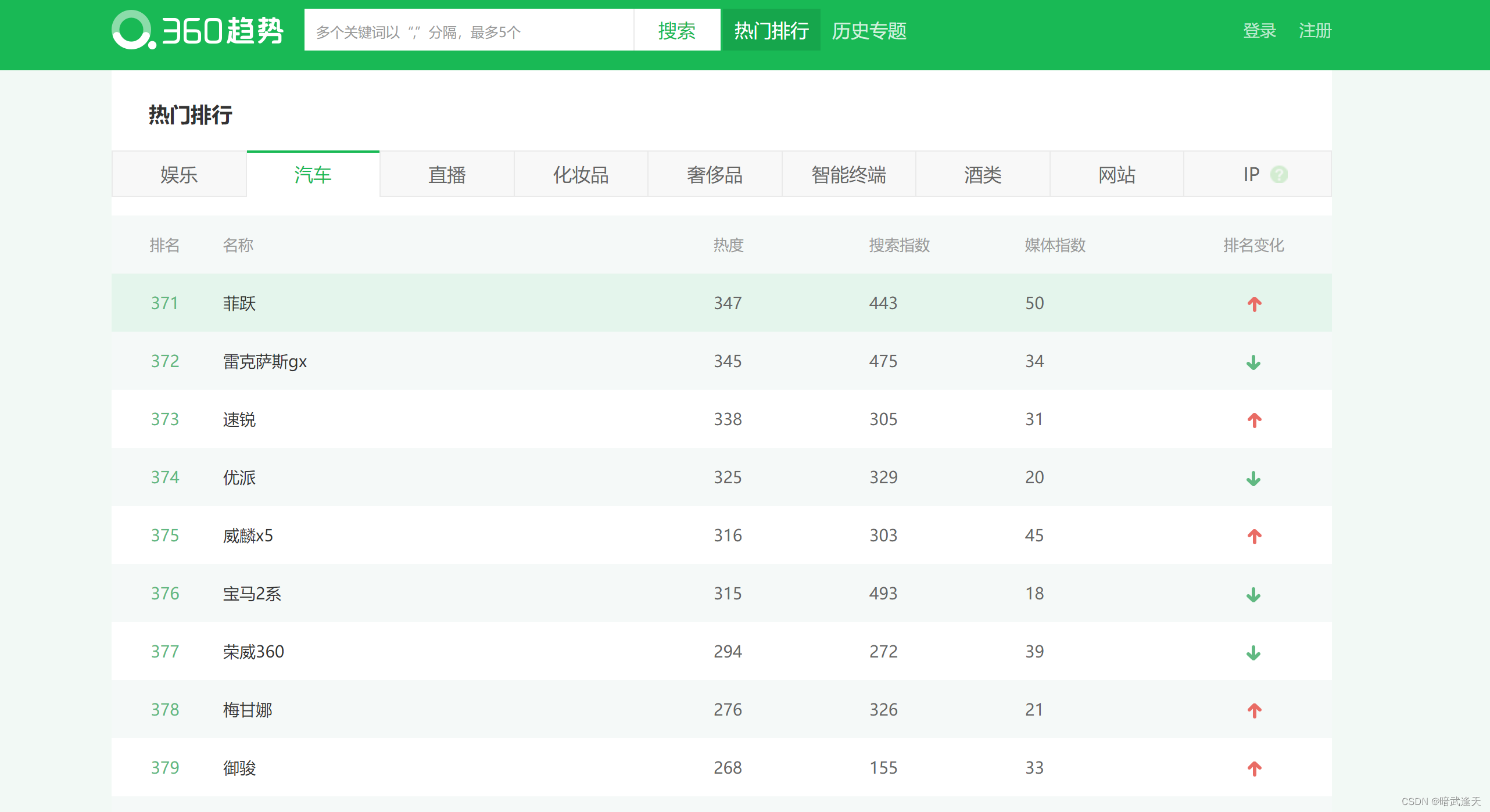
本次以360趋势图爬取后插入数据库当做测试
建立流程
首先建立打开360趋势图的流程,这个不再演示,直接从获取分析元素开始
打开要爬取的网页 点击定位元素
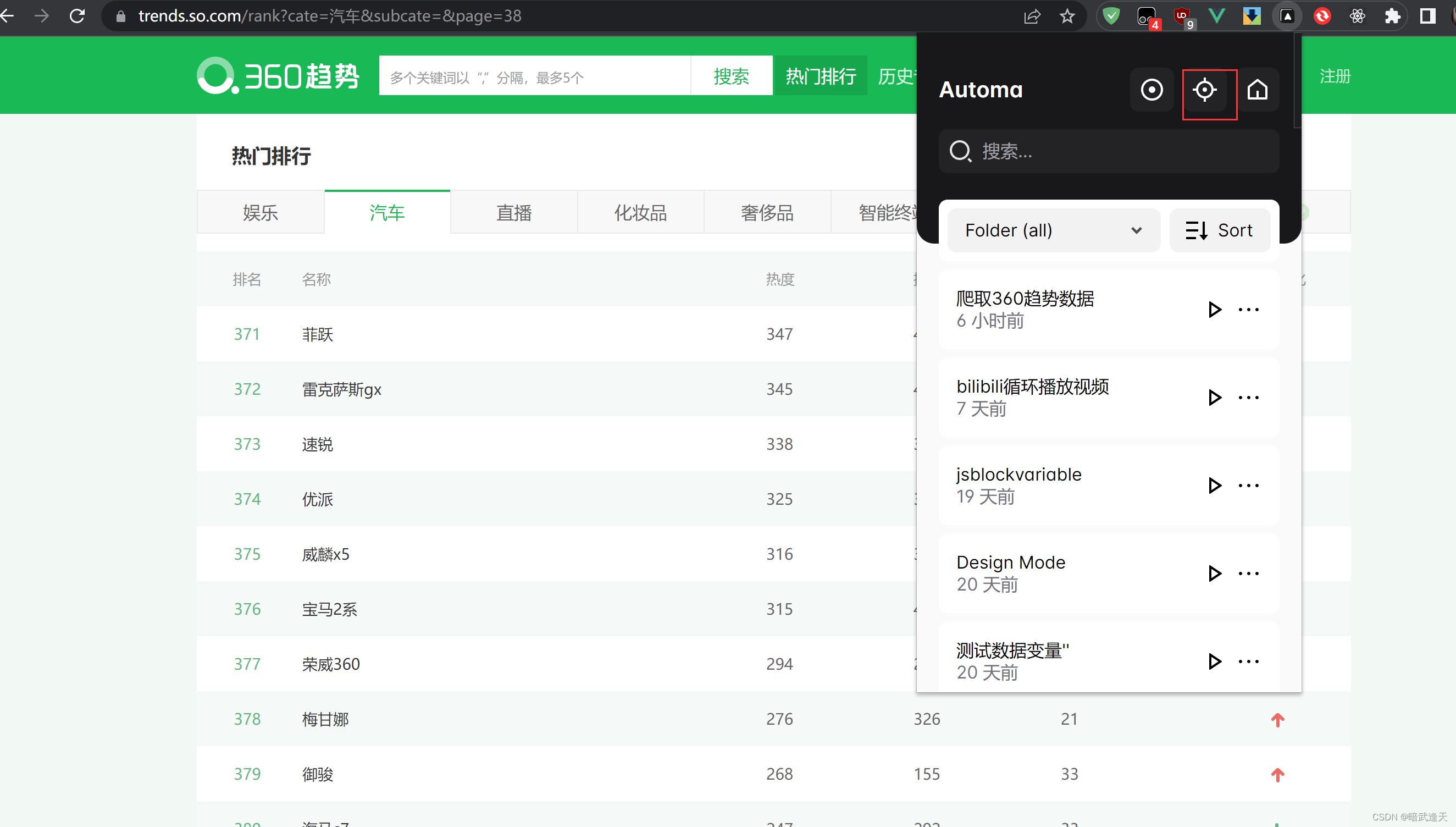
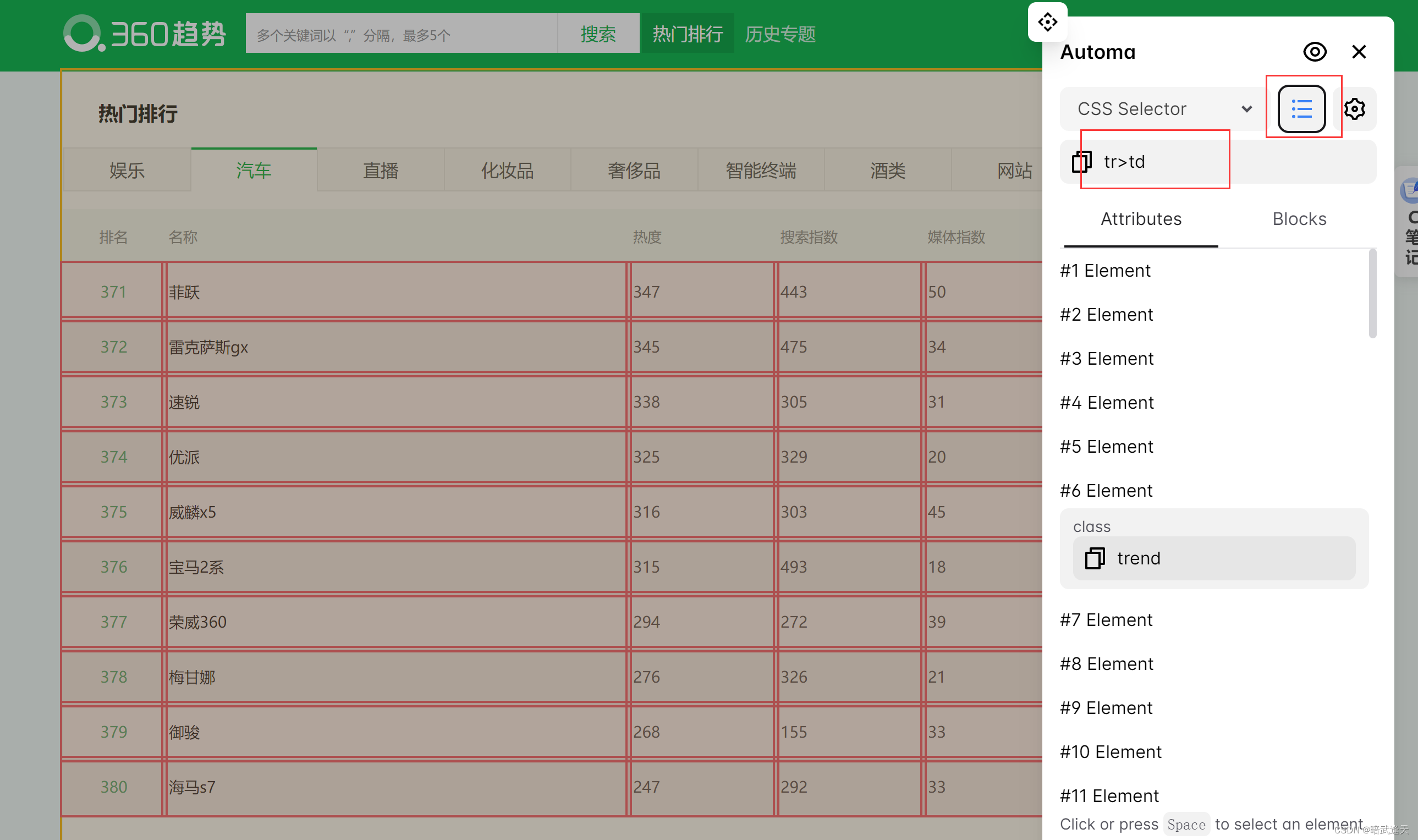
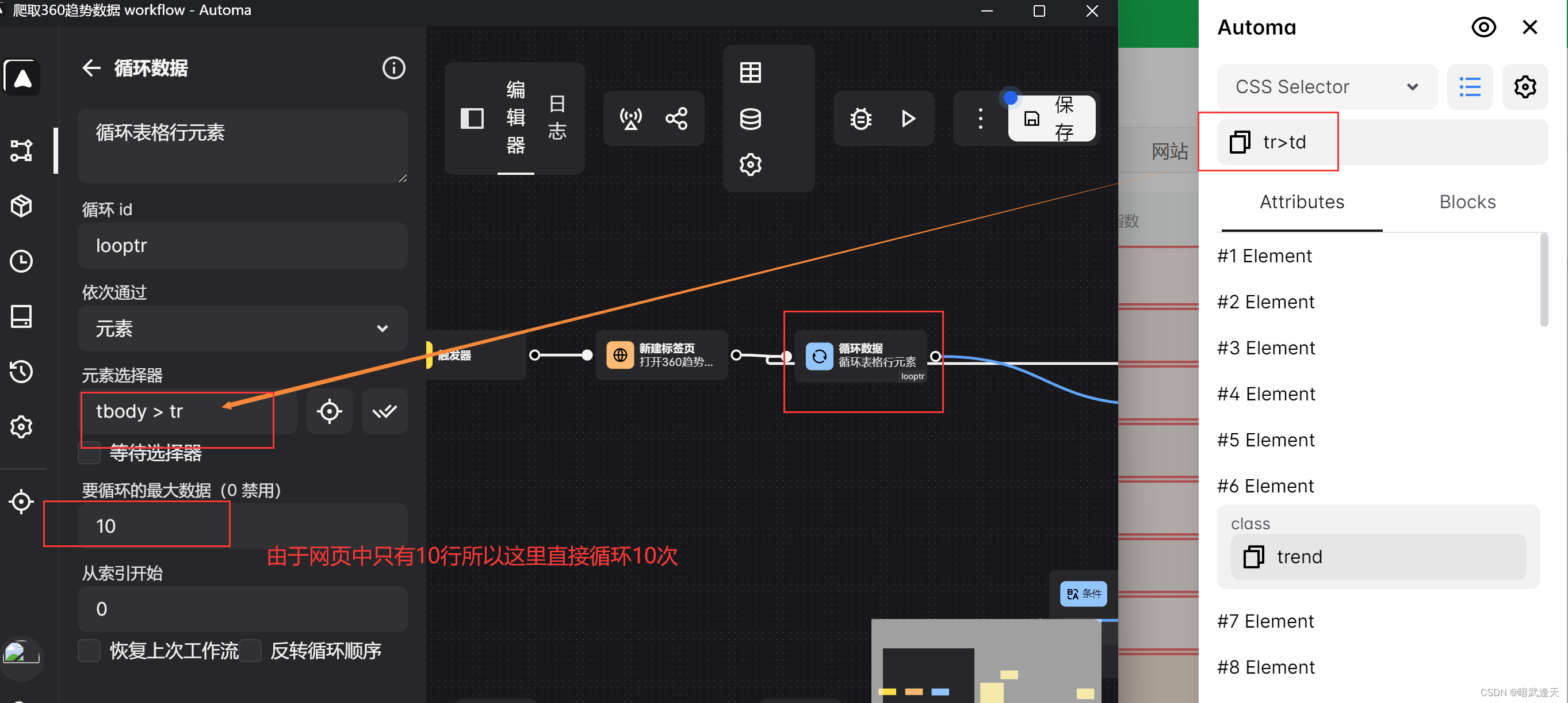
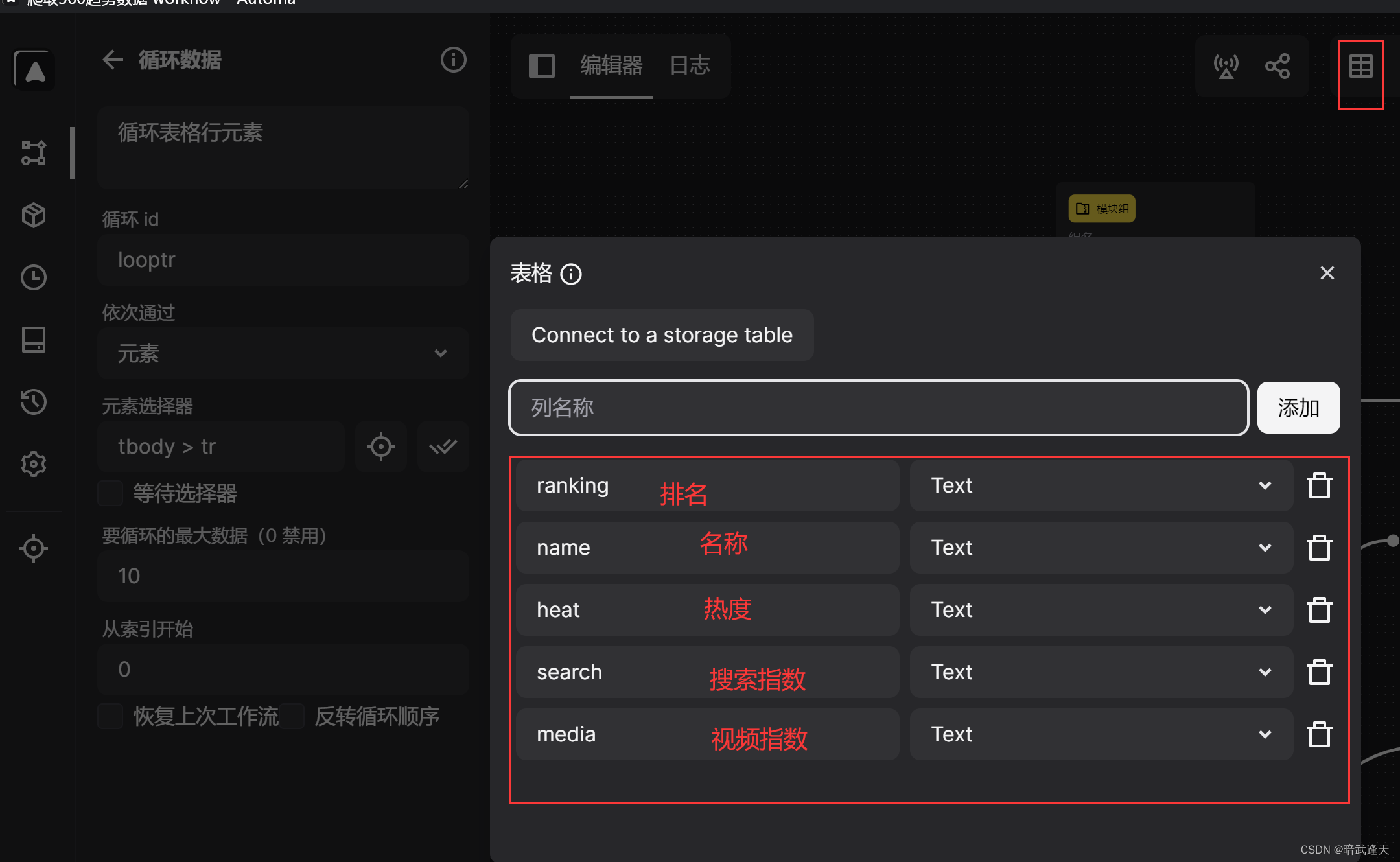
建立表格存储爬取到的数据
建立获取文本组
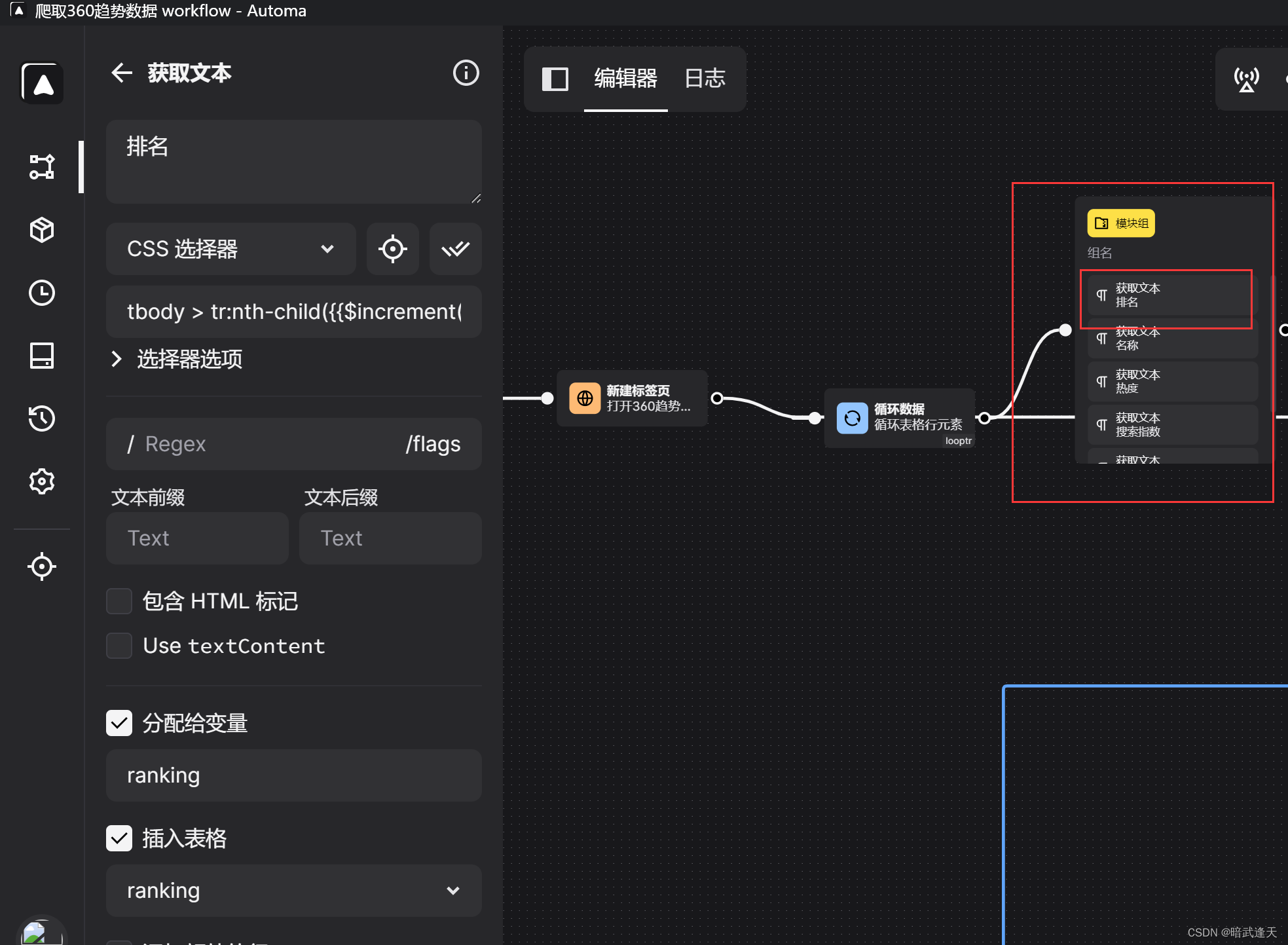
测试是否能拿到单个单元格数据
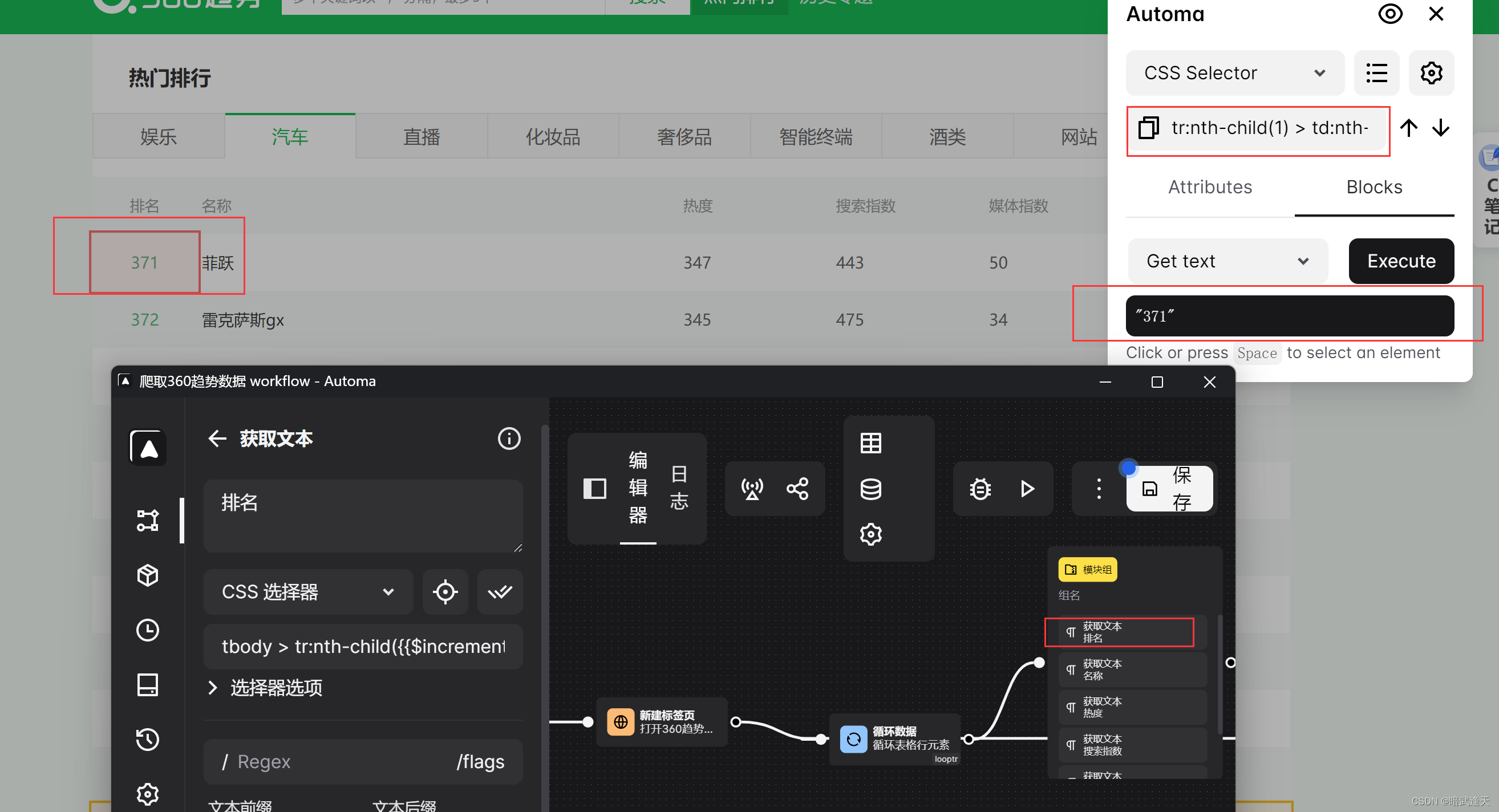
其他几个也是同理
添加循环断点 指定断点的循环id
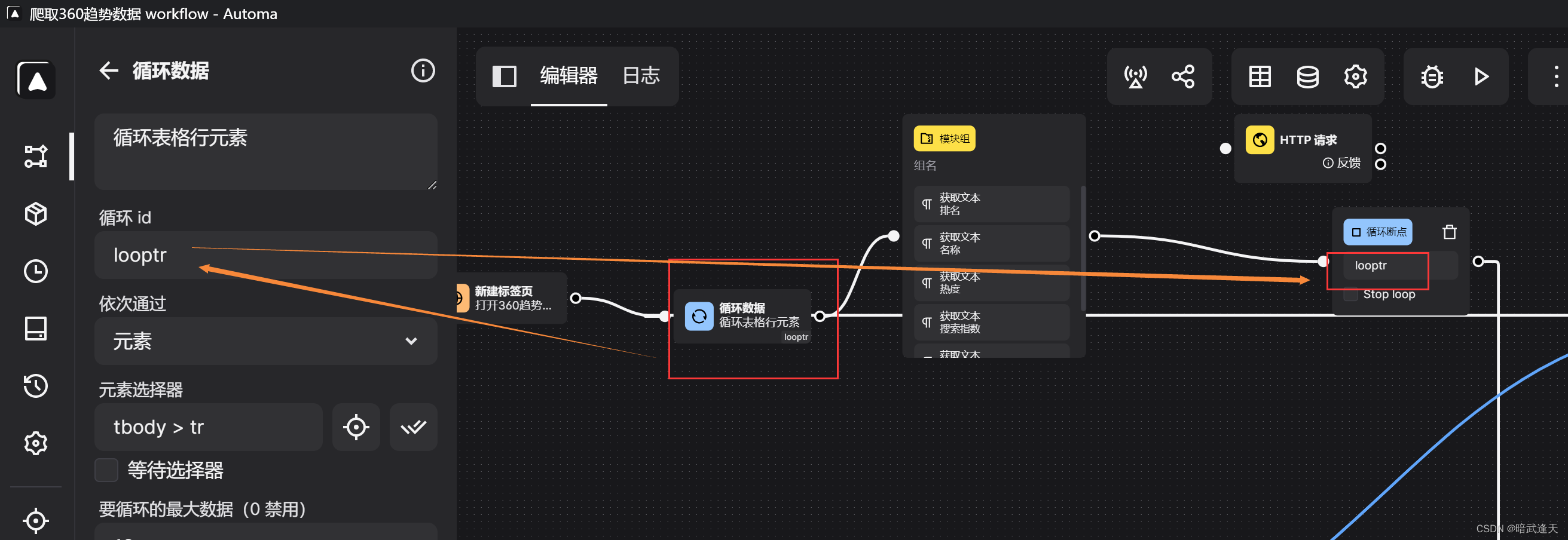
添加循环退出条件
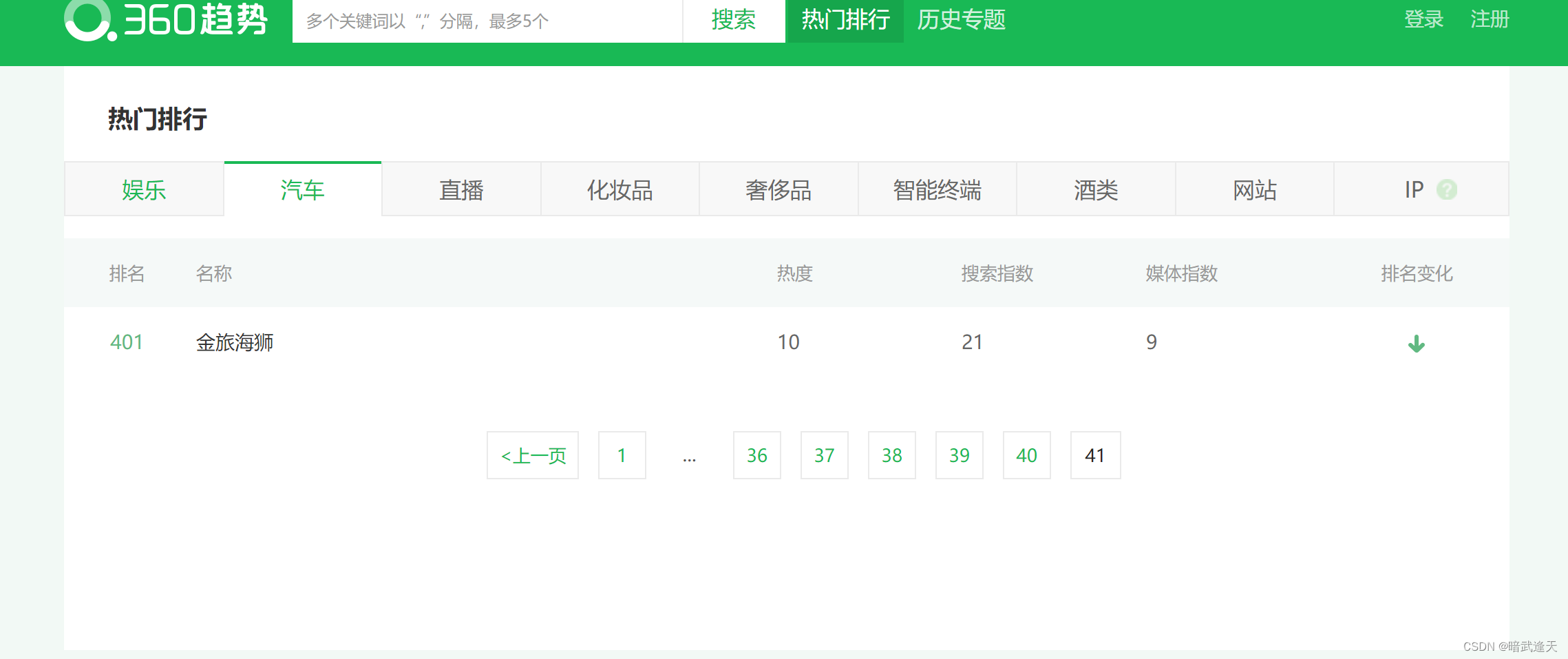
可以看出这里总共有41页,所以我们可以判断最后的标签数字是否是41,如果是则退出爬取流程,这个处理方法不是最优解,因为这需要提前知道网页数据的页数,但是先这样处理,后面最优解会再优化下
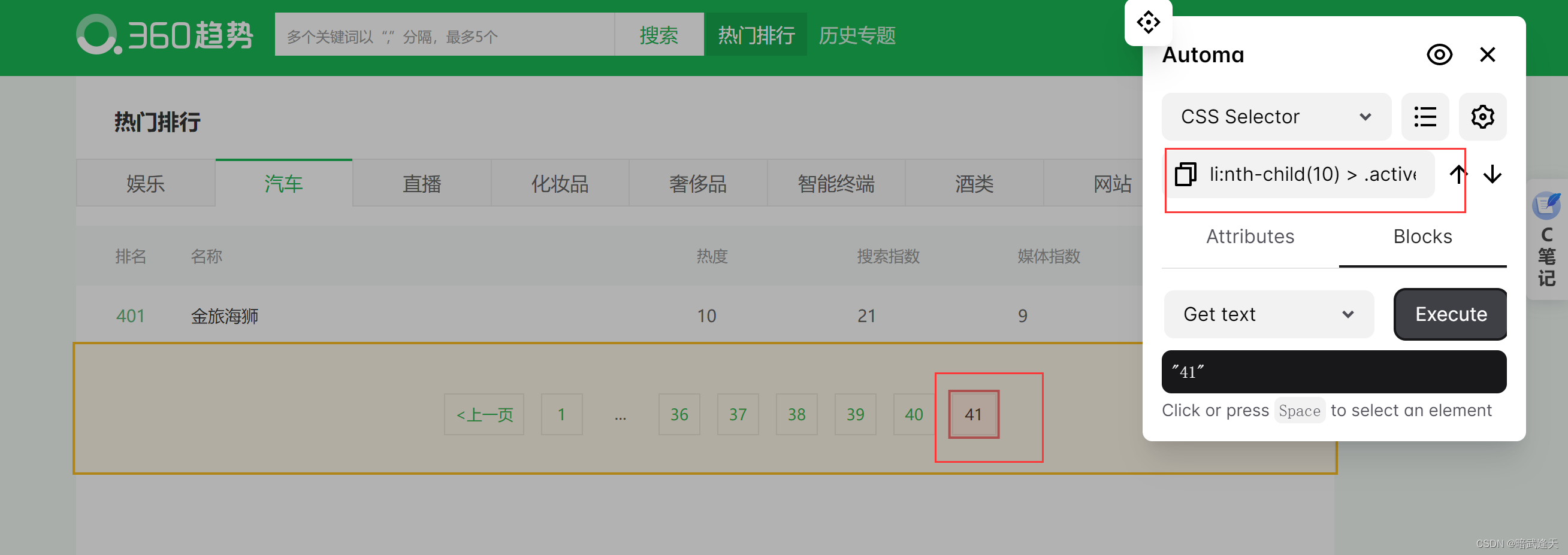
所以这里可以直接拿取到当前元素判断当前元素数字是否是41,作为流程爬取的结束条件
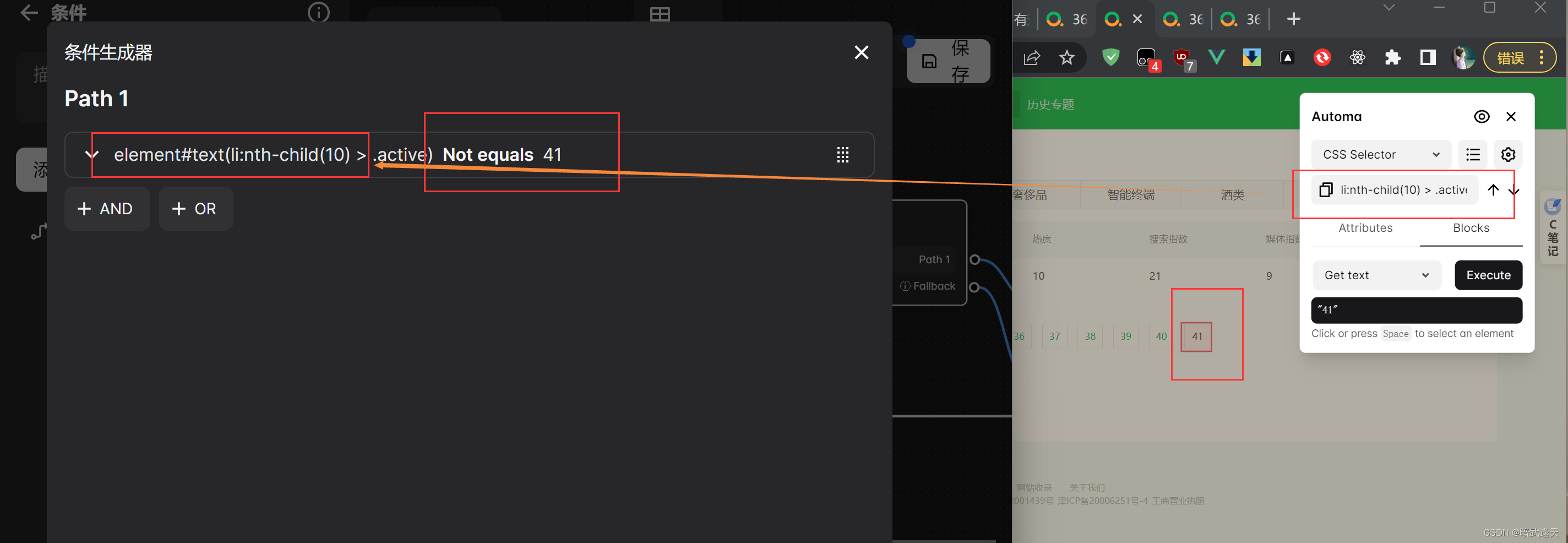
如果不是41,则直接点击下一页
拿取到"下一页"的元素定位
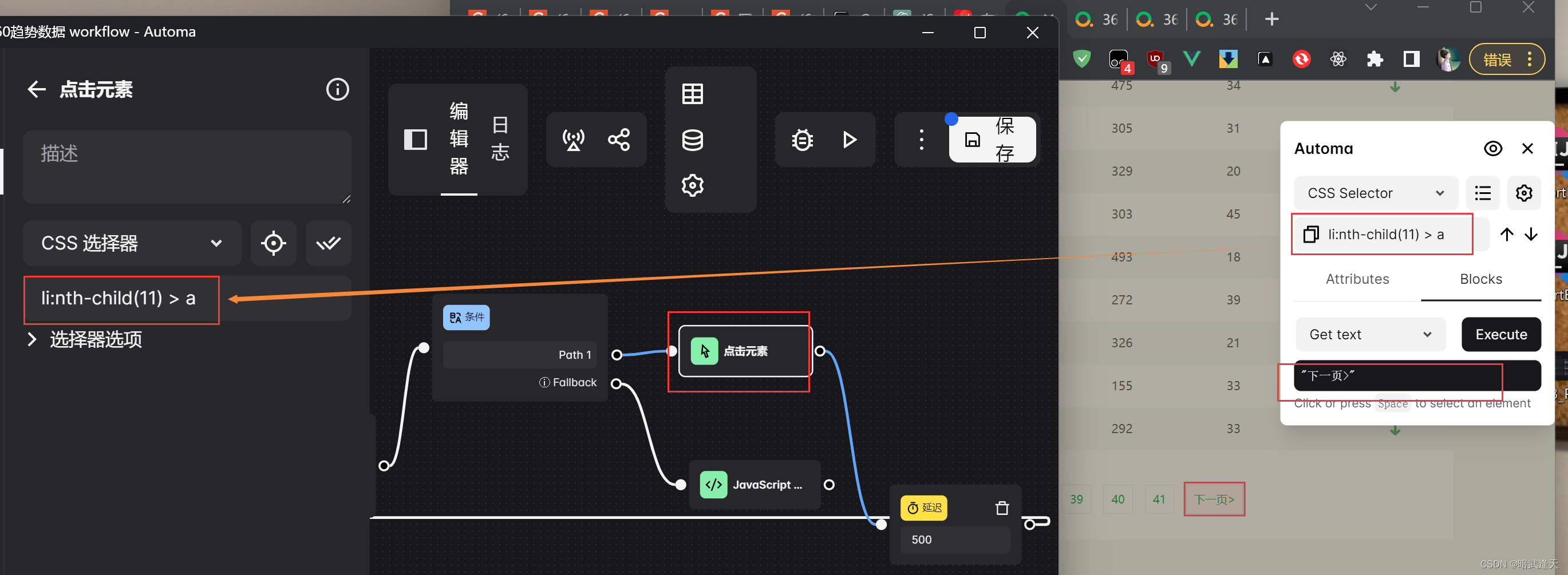
再添加延时效果 延迟500ms
然后先测试是否可以爬取到数据
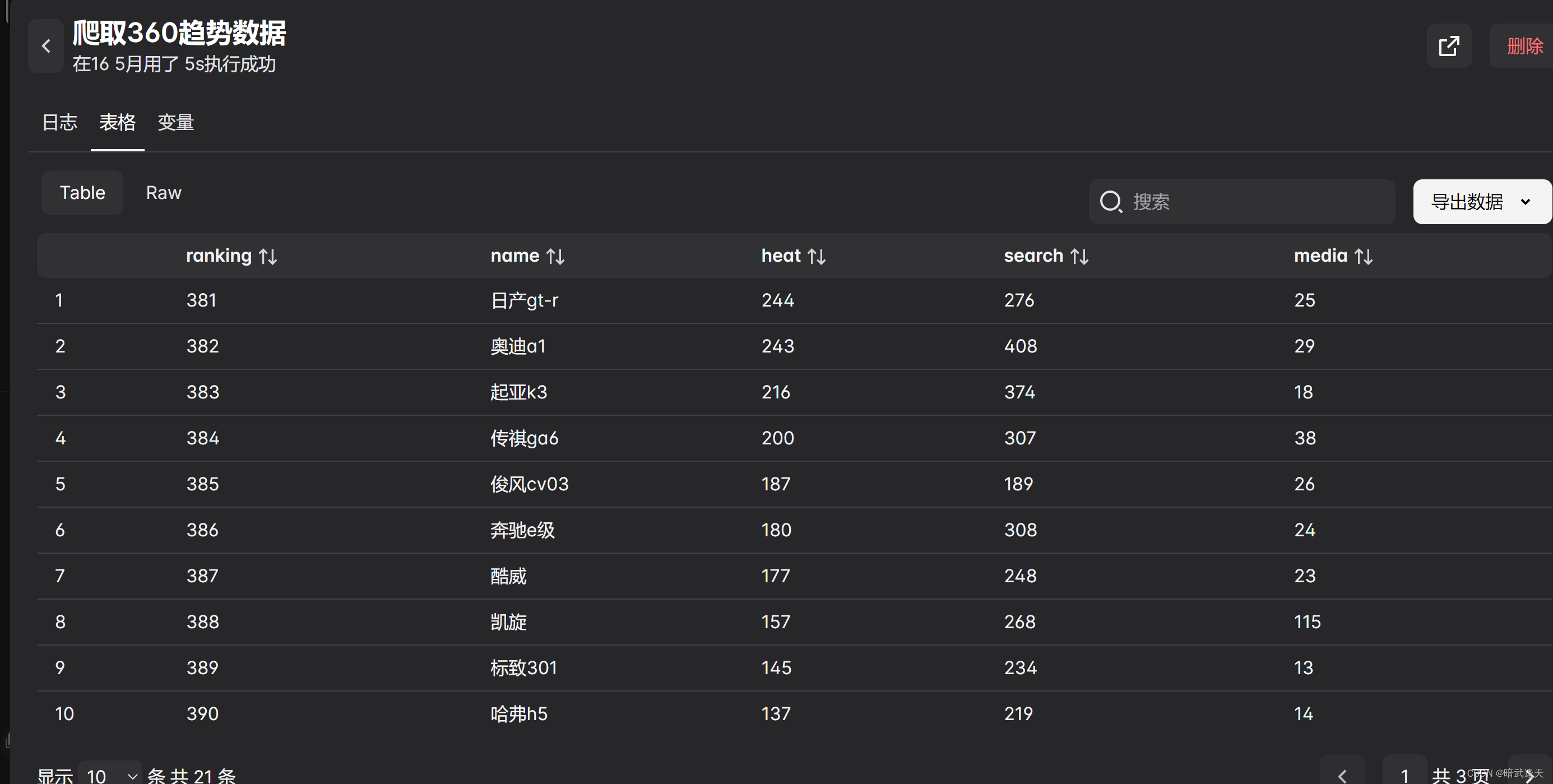
爬取到了数据
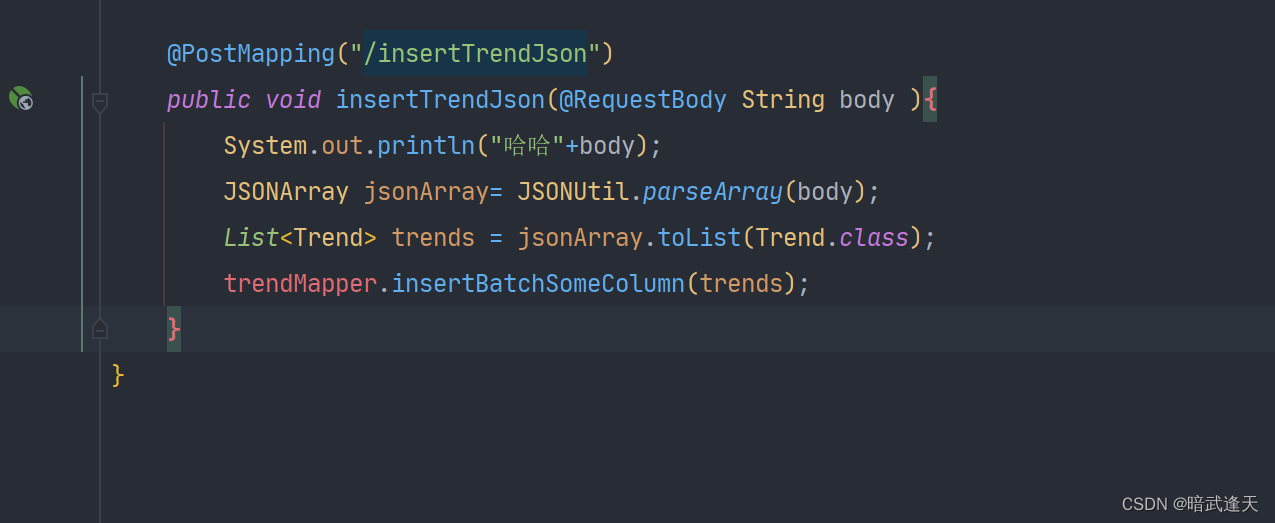
然后书写java后台,这里选择后台接口接参为 json格式
注意automa插件不能直接发送请求给localhost:端口号或者127.0.0.1:端口
这里可以将服务后台部署到外网可以访问的服务器,或者直接搭建内网穿透
首先建立表库
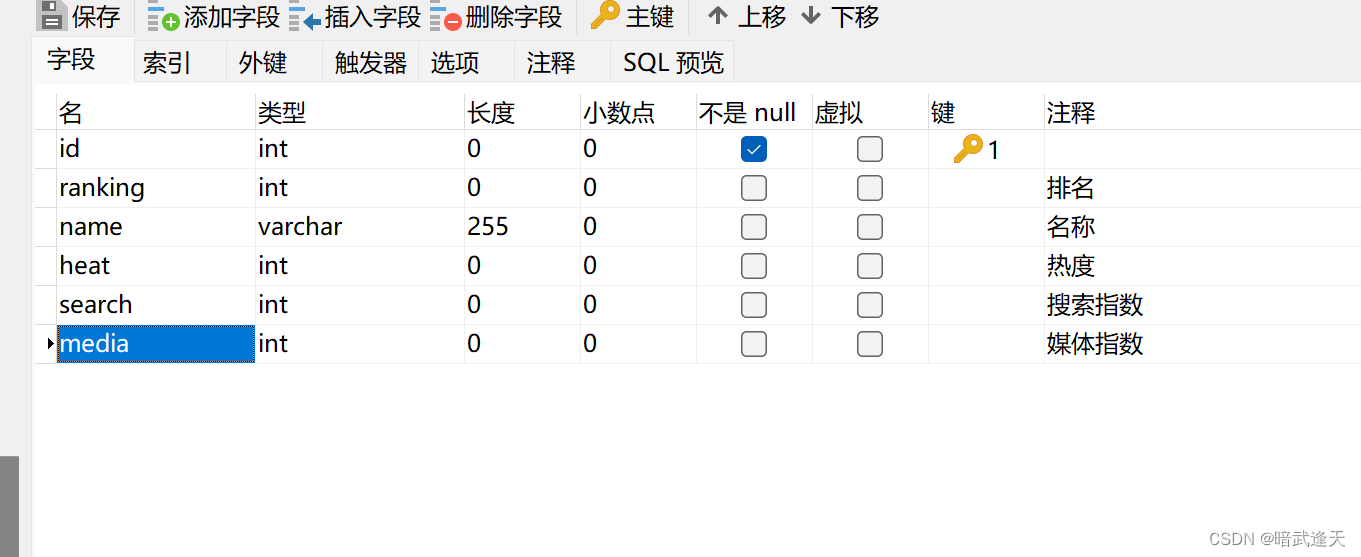
java后台简单展示下,只展示controller层 实体,服务层等不再展示
这里用natapp搭建内网穿透进行测试
在流程循环最后添加javaScript代码块
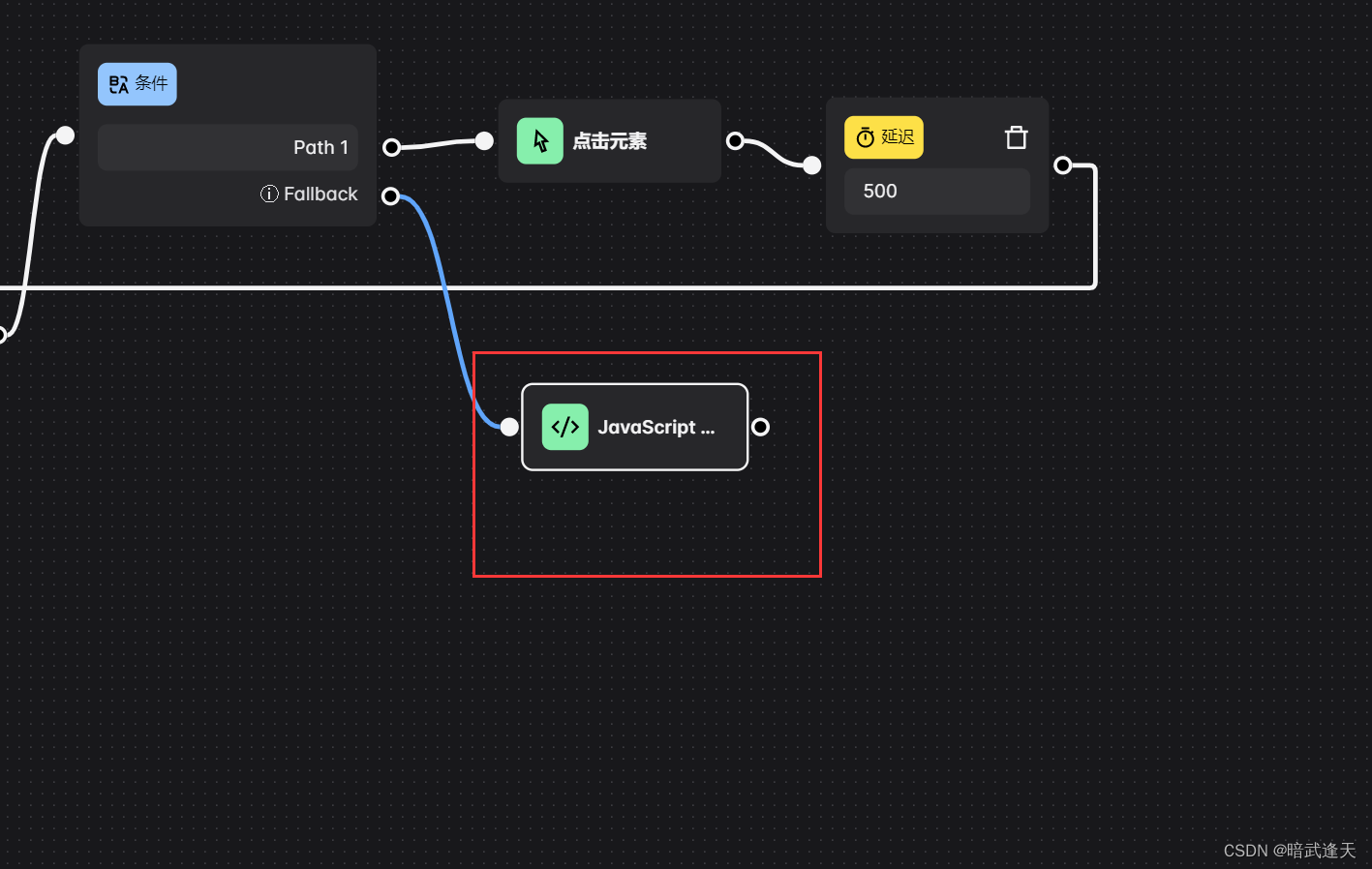
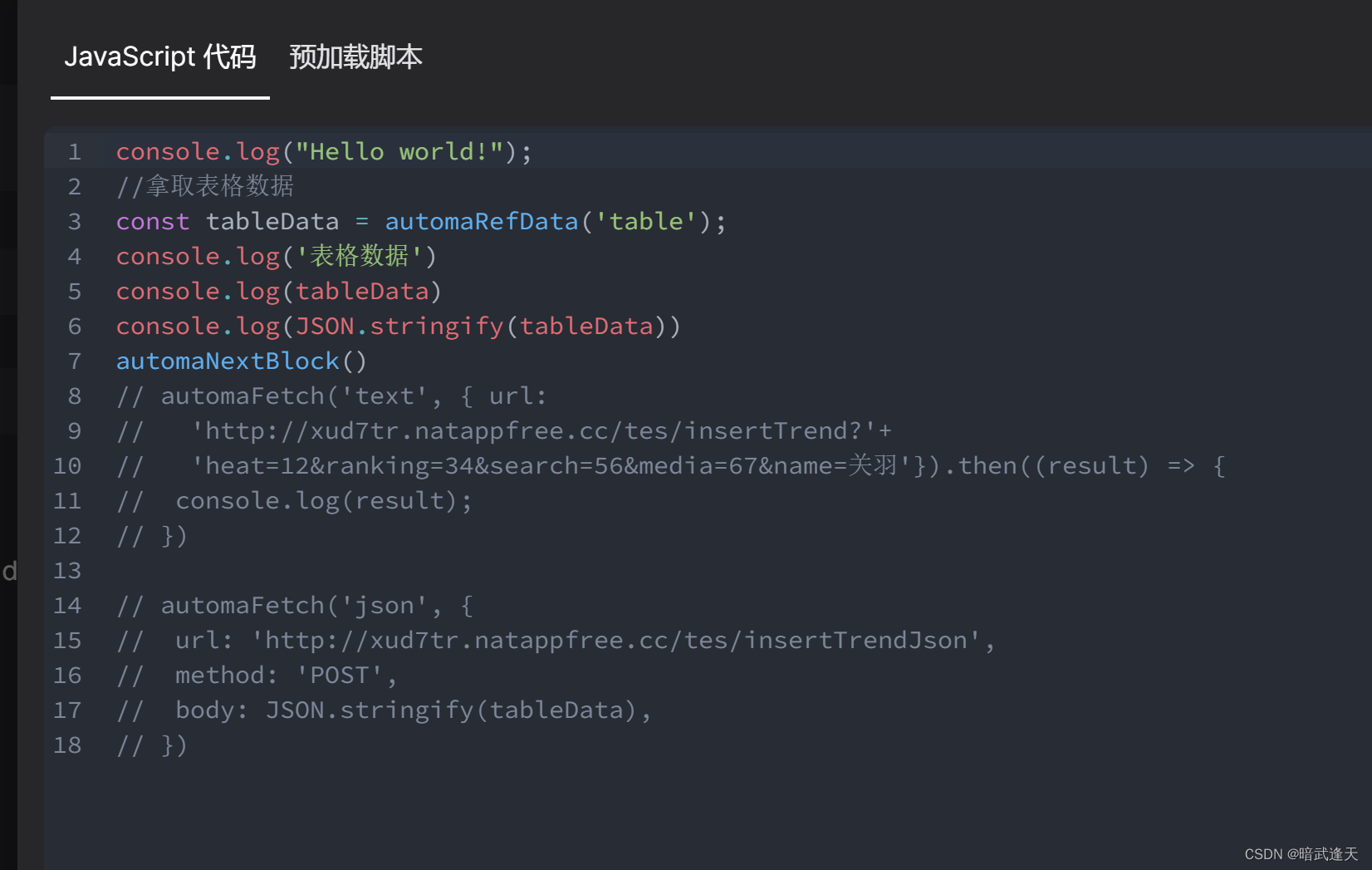
先测试下看看能不能拿到表格数据
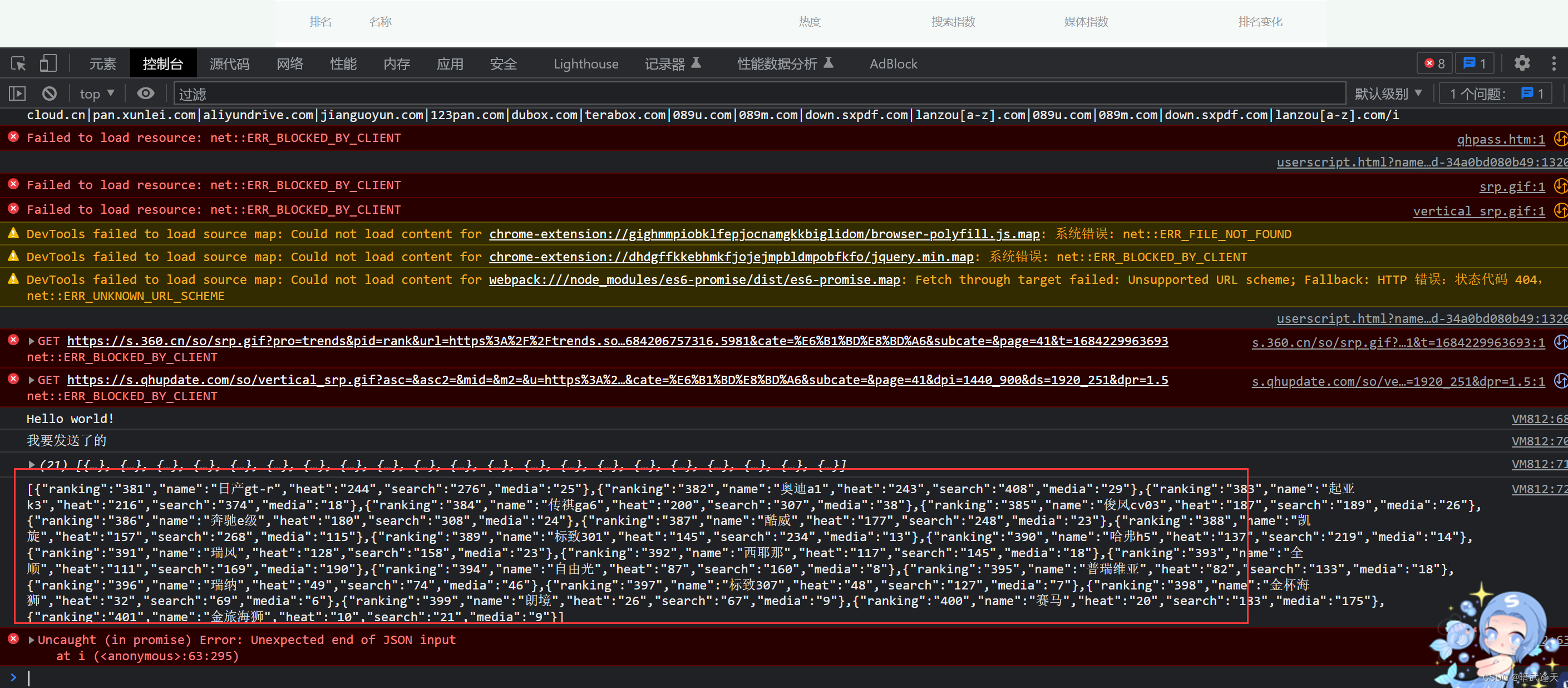
可以拿到
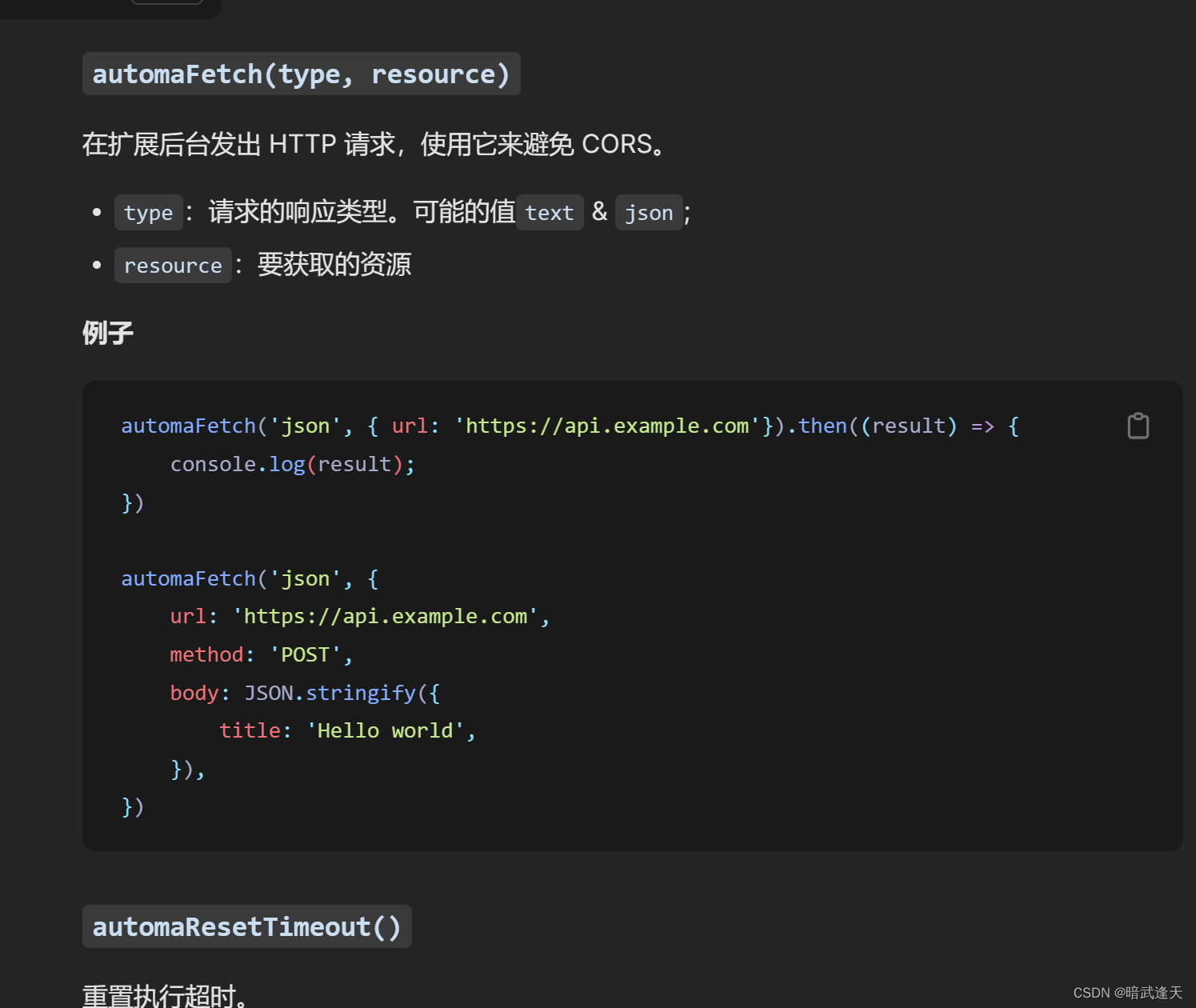
然后使用automa内置的发送请求方法
官方文档
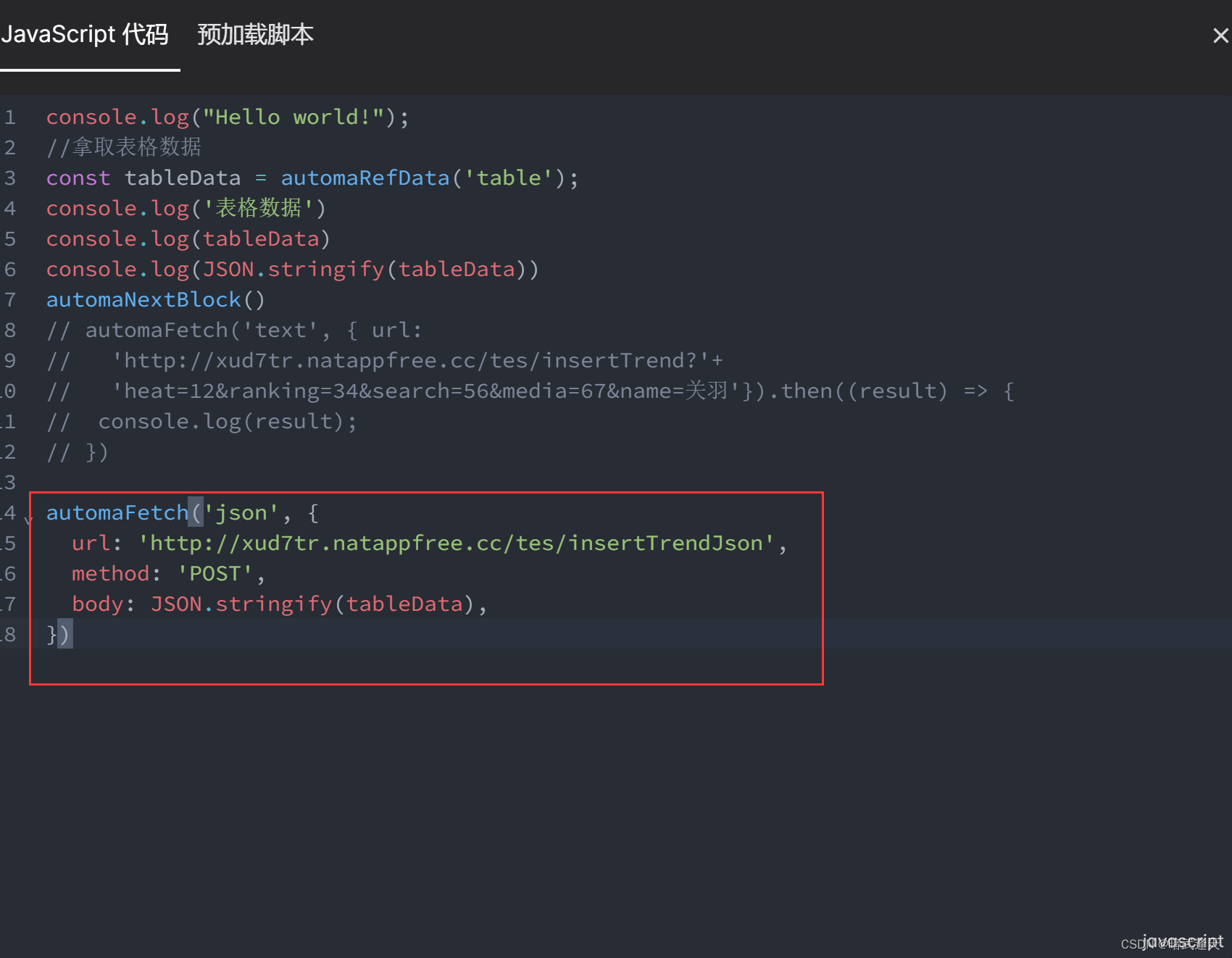
好了,发起请求测试
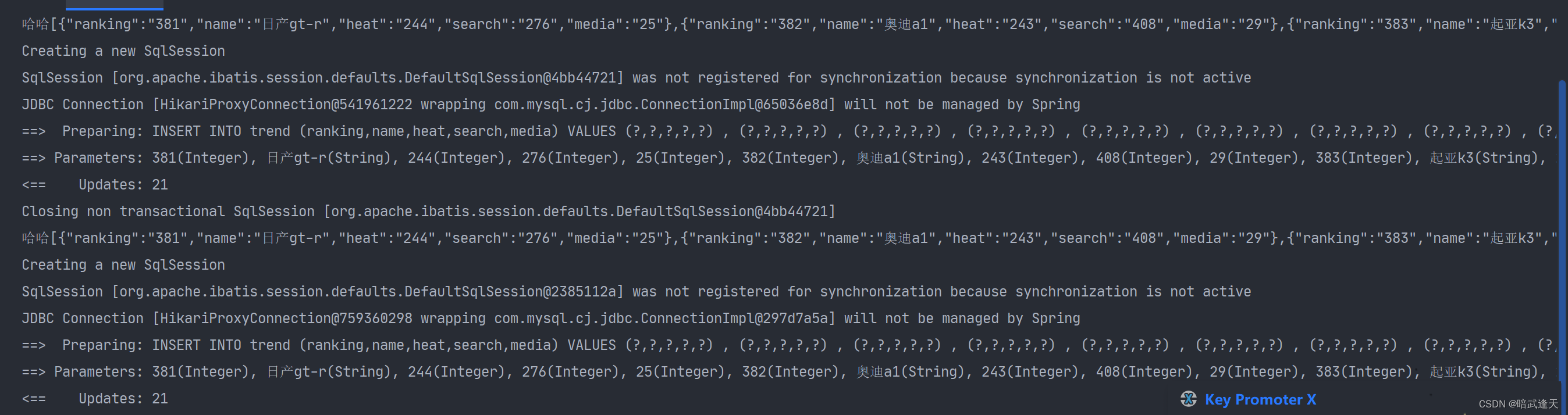
nice,测试成功!