视觉辅助的常识知识获取
摘要:大规模的常识知识库为广泛的AI应用提供了能力,其中常识知识的自动提取extraction of commonsense knowledge (CKE)是一个基本和具有挑战性的问题。文本中的CKE因其固有的稀疏性和文本中常识的报道偏差reporting bias而闻名。另一方面,视觉感知包含了丰富的关于现实世界实体的常识知识,如(人、能拿的东西、瓶子),这可以作为获得基础常识知识的有前途的来源。在这项工作中,我们提出CLEVER,它将CKE描述为一个远端监督的多实例学习问题,其中模型学习从一组关于实体对的图像中总结常识关系,而不需要对图像实例进行任何人为注释。为了解决这一问题,CLEVER利用视觉语言预训练模型来深入理解袋子中的每个图像,并从袋子中选择信息实例,通过一种新颖的对比注意力机制来总结常识性的实体关系。综合实验结果表明,CLEVER方法能够较好地提取常识性知识,比基于语言模型的预训练方法提高了3.9个AUC点和6.4个mAUC点。预测的常识得分与人的判断具有较强的相关性,斯皮尔曼系数为0.78。此外,提取出来的常识也可以根植于具有合理解释性的图像中。
数据和源码下载:AAAI2023VisuallyGroundedCommonsenseKnowledgeAcquisition源码-深度学习文档类资源-CSDN下载
在这项工作中,我们提出了CLEVER,它将CKE作为一个远程的假设多实例简化问题(拉斯罗普和洛扎诺-p‘erez1997),其中模型学习从一袋图像中总结实体对的一般常识关系,如图1所示。常识性关系标签是通过将现有kb中的关系事实与图像袋对齐而自动创建的,以提供远程监督的学习信号。通过这种方式,常识性学习可以很容易地在一般领域进行扩展,而不需要进行昂贵的手动图像注释。
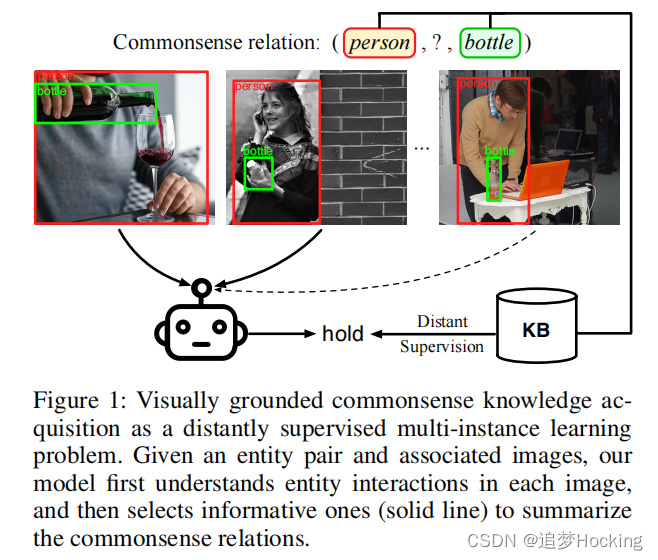
图1.视觉基础常识知识获取作为一个远程监督多实例学习问题。给定一个实体对和相关的图像,我们的模型首先理解每个图像中的实体交互,然后选择信息丰富的图像(实线)来总结常识关系。
为了抽取关于一对查询实体的常识事实,模型需要首先理解它们在包的每个图像中的语义交互,然后选择信息丰富的图像(即表达查询实体之间感兴趣的交互的图像)来合成常识关系。然而,我们的试点实验表明,由于现实世界的常识关系的复杂性,现有的多实例学习方法不能很好地服务于任务。因此,我们提出了一个专门的框架,通过视觉语言预训练(VLP)模型来建模图像级实体交互,并通过一种新的对比注意机制来选择有意义的图像来总结袋级常识关系。
保留和人工评价的综合实验结果表明,CLEVER可以提取质量良好的常识知识,超过基于plm的方法3.9 AUC和6.4 mAUC点。预测的常识得分与人类判断有很强的相关性,达到0.7的斯皮尔曼等级相关系数8。此外,所提取的常识也可以建立成具有合理可解释性的图像。与纯粹基于黑箱形式产生文本表面形式的基于PLM的方法相比,可以利用CLEVER的可解释性来为KBs中的常识知识提供支持证据,这对下游应用程序很有用。
我们的贡献总结为四方面: (1)我们建议将CKE表述为一个远程监督的多实例学习问题,它可以很容易地扩展到在一般领域的常识关系,而无需手动图像注释。(2)我们对来自不同数据源的现有和适应的CKE方法进行了广泛的实验,显示了它们的有效性和局限性。(3)我们提出了一个专门的CKE框架,该框架将VLP模型与一种新的对比注意机制集成起来,以处理复杂的常识性关系学习。(4)我们进行了全面的实验,证明了该框架的有效性。
World Knowledge Acquisition世界知识获取。事实世界知识的提取,例如,(鲍勃·迪伦,作曲家,《在风中爆炸》),是补充世界知识库的重要工具。世界知识获取以文本作为知识来源(阮和格里什曼2015;苏阿雷斯等2019;吴等2019;董等2020;陈等2021;姚等2019,2021a;张等2021年),尝试多模式世界知识获取(Wen等2021年)。为了减轻人类的注释,Mintz等人(2009)提出了远程监督,将KBs与文本对齐,以创建有噪声的关系标签。接下来的工作重点是在多实例学习公式下处理远程监督中的噪声(Riedel,Yao,和McCallum 2010;曾等,2015;Liu等,2018)。采用最广泛的方法是选择性注意模型(Lin et al. 2016),它基于注意机制在袋子中选择高质量的实例。相比之下,我们的目标是从图像包中提取常识性知识。我们在实验中发现,现有的多实例学习模型不能很好地服务于复杂的常识性学习,因此我们提出了一种专门的任务学习方法。
Pilot Experiment and Analysis 试点实验与分析
为了研究现有CKE方法的有效性和局限性,我们首先对来自不同信息源的代表性方法进行了实证研究,包括基于文本、基于PLM和基于图像的模型。
问题定义。CKE的目的是提取常识性关系三元组(s,r,o),它描述了实体(s,o)之间看似合理的相互作用。例如,(人,可以拿着,瓶子)反映了一个人可以拿瓶子的常识。还包括一个特殊的NA关系,表明实体对之间没有关系。
Benchmark Construction基准建设。我们构建了基于视觉基因组(Krishna et al. 2017)的CKE基准测试,其中包含了真实世界图像数据中关于实体的关系三元组。具体来说,我们选择了具有前100个实体类型和关系类型的不同的三元组。对于自动分离评估(Mintz et al. 2009),我们将三元组分为不相交的训练、验证和测试集。每个实体对都与包含这些实体的视觉基因组图像相关联。训练/验证/测试数据分别包含13780/1166/3496个常识性事实、6443/678/1964个实体对和55911/5224/13722张图像。
现有的CKE模型。我们选择具有代表性的CKE模型进行实证研究。(1)基于文本的模型。我们采用了RTP(Schuster et al. 2015),这是一种广泛使用的三元组解析器,它基于依赖树从标题中提取常识性三元组。我们从包含3M标题的概念标题(Sharma et al. 2018)中提取三元组,并根据其在标题数据中的频率获得全局三联体的置信度。(2)基于PLM的模型。我们采用LAMA(Petroni et al. 2019)来探索BERT中的知识通过填充包含查询实体对和掩蔽关系的提示模板(例如,“人[面具]瓶”)。根据Lin等人(2020),我们使用训练集中的三元组,基于相同的提示进一步微调模型,以更好地学习常识知识。继Peng等人(2020年)之后,我们还采用了一个普通的精细化BERT模型,该模型使用[CLS]令牌基于实体名称来预测关系。
基于图像的CKE的多实例学习。直观地说,图像是丰富的真实世界实体交互的原始视觉感知,可以作为CKE的一个可扩展和有前途的信息源。然而,大多数现有的基于图像的CKE方法要么在关系类型上受到限制,要么需要手动进行图像注释。
对于通用的和可扩展的常识知识库构建,我们需要从没有人工注释的大规模图像中提取一般类型的常识知识。为此,我们建议将CKE表述为一个多实例学习问题,其中实体之间的常识关系r是从一个包含实体对的图像B(s,o)= {vi} N i=1中总结出来的。受Mintz等人(2009)的启发,我们将现有的常识kb与图像袋对齐,以提供远程监督的学习信号。具体地说,image bag图像袋B(s,o)用KB中(s,o)之间的关系r进行标记,假设袋中至少有一个图像子集表示三元组(s,r,o),并且袋中可能有一些图像不表示三元组。为了提取常识性三元组,模型需要首先理解包的每个图像中的实体交互,然后选择有意义的实体交互来综合常识性关系。
我们注意到一些工作探索从文本中提取世界知识中类似公式的问题。为了研究现有的多实例学习方法对基于图像的CKE的有效性,我们采用了具有代表性的方法,使用平均池化(Lin等2016)、至少一种策略(Zeng等2015)或注意机制(Lin等2016)来选择和总结实例包。
具体来说,给定一个三元组(s,r,o),我们首先选择一个包含查询实体对的图像包。在实践中,候选图像的数量可能会很大(例如,∼1000),而只有一小部分反映了实体的交互。受Zellers等人(2018)的启发,为了组成适当大小的图像袋,我们选择了查询实体的顶部空间重叠(即像素上的交集相交)的图像,这些图像更有可能表现出交互。使用自适应的神经基元(Zellers et al. 2018)模型,将包的每个图像中的查询实体对编码到特征表示{vi} N i=1中,这是一种广泛使用的基于cnn的实体对编码器。
为了获得bag表示B(s,o),(1)平均池(AVG)计算实例表示的平均值:B(s,o)=1NPNi=1vi;(2)基本策略(ONE)(Zeng等人2015)选择最可能的实例:B(s,o)=vj,其中vj在给定训练三联体的黄金关系r∗上获得最高分数;

(3)注意机制(ATT)(Lin et al. 2016)计算实例表示的加权和: B(s,o)= P N i=1 αivi,其中注意权重基于黄金关系查询计算: αi = Softmaxi(vi > r∗)。袋表示B(s,o)通过一个softmax分类器对黄金标签r∗进行优化。在推理过程中,由于关系标签未知,ONE和ATT对对应的关系预测得分枚举关系查询。
除了基于多实例学习的方法外,我们还将视觉关系检测模型应用于基于图像的CKE。为了模拟一个可扩展的场景,我们从视觉基因组中为每个关系随机选择一个中等数量(即100个)的图像级注释,并训练一个神经主题(Zellers et al. 2018)模型来预测特定图像中的实体对之间的关系。在推理过程中,通过对包中所有图像的关系分数进行最大池化,得到一个包的关系分数。
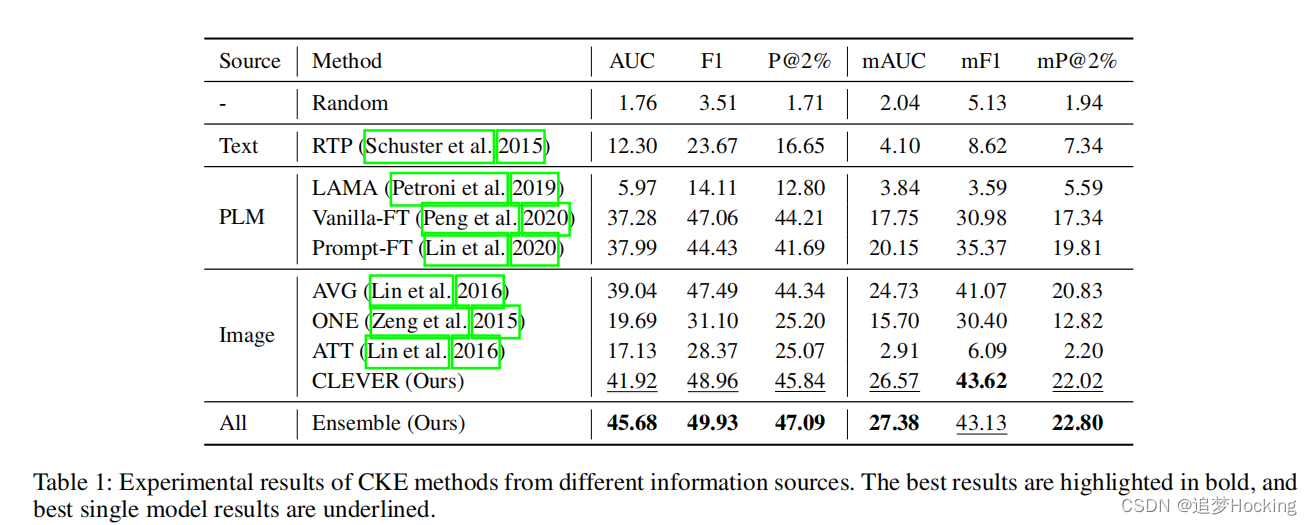
结果。根据之前的知识获取工作(Zeng et al. 2015;Lin et al. 2016),为了提供严格的评估,我们绘制了保留的三组预测的精确-召回曲线,并报告了曲线下面积(AUC)。除了传统的微观结果外,我们还报告了mAUC,即宏观曲线下的面积(即不同关系的平均曲线)来评价长尾关系的性能。从图2中,我们有以下观察结果:
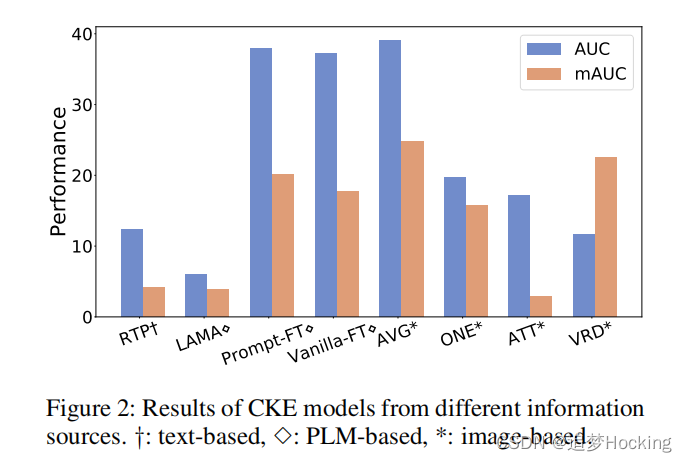
(1)基于文本的方法(RTP)和PLMs(LAMA)在CKE上的知识探索。原因是文本中固有缺乏常识知识,模型没有针对任务进行微调。对该任务进行进一步的微调plm(提示ft和香草ft)可以提高性能,从而取得良好的效果。
(2)从图像中获得的视觉感知可以为常识性知识的获取提供丰富的信息。基于一种相对合适的总结方法(AVG),基于图像的多实例学习模型比所有现有的CKE模型获得了最好的效果。
(3)多实例学习公式是开放域可扩展的基于图像的CKE的必要条件。尽管使用了更多的图像级关系注释(例如,每个关系有100个图像级注释),但采用了适应性的图像级视觉关系检测模型(VRD)在CKE上表现不佳。
(4)对现有的多实例学习方法的简单适应不能很好地服务于CKE。所有型号的整体性能仍然不能令人满意。值得注意的是,尽管ONE和ATT在从文本中获取世界知识方面具有竞争力,但它们在CKE上表现不佳。其原因是,与世界知识的关系方案相比,常识关系表现出更高的复杂性,其中具有重叠语义的细粒度关系(如站立和行走),而下义-超对称冲突(如站立和行走)经常发生。与AVG相比,ONE和ATT的仅黄金查询问题阻碍了它们区分复杂的常识关系。关于方法论问题的更详细的讨论。
试点实验结果表明,需要开发专门的方法来解决常识性知识获取的独特挑战。从本质上说,由于常识关系的复杂性,基于多实例学习CKE提出两个层面的挑战: (1)在图像层面,模型需要首先要理解每个图像中的复杂的实体交互,(2)在bag包层面,模型需要选择信息实例总结实体之间的细粒度的常识关系。我们从图像中提出了一个专用的CKE模型,如图3所示,(1)通过强大的视觉语言预训练vision-language pre-training(VLP)模型实现了对实体之间的图像级交互的深入理解,(2)通过对比注意机制选择有意义的图像来总结包级常识关系。
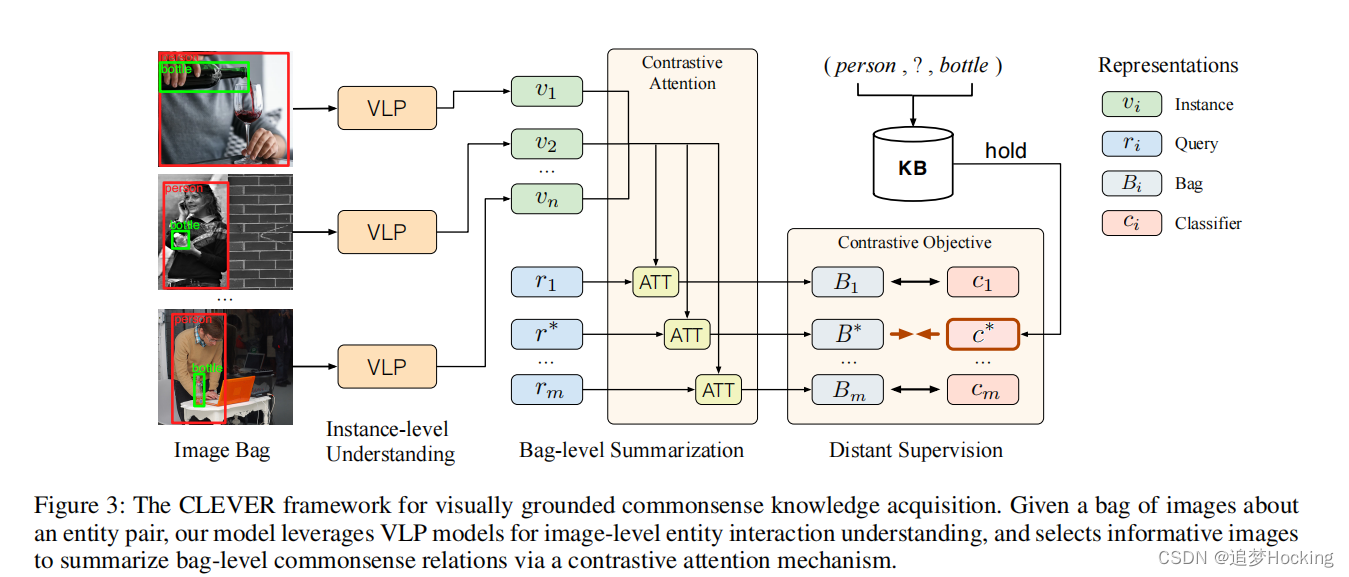
图3 基于视觉基础的常识性知识获取的CLEVER框架。给定一组关于实体对的图像,我们的模型利用VLP模型来理解图像级的实体交互,并通过对比注意机制选择信息性图像来总结袋子级的常识关系。
图像级实体交互理解的视觉语言预训练模型。最近,VLP模型以基础角色推动了许多多模态任务的先进水平(博马萨尼等人,2021年),如视觉问题回答和视觉基础。然而,很少有研究探索利用VLP方法来为实体对建模复杂的视觉关系。我们证明,预先训练的Transformers可以作为强大的基础模型来解决复杂的图像级实体交互。
给定一个查询实体对(s,o)和相关的图像袋B(s,o)= {vi} N i=1,该袋中的每个查询实体对实例通过基于检测器的VLP模型被编码为深度表示vi。在这项工作中,我们采用了VinVL(Zhang et al. 2021b),一个最先进的VLP模型作为编码器。具体来说,每个图像中的查询和上下文实体首先由对象检测器进行编码,以获得一系列的视觉特征{u1,u2,……,un}。实体标签的视觉特征和标记嵌入{t1,t2,…然后输入预先训练的变压器,以获得深度多模态隐藏表示{h 1 u,h 2 u,…,h n u,h 1 t,h 2 t,…,h n t }。图像级实体对表示是通过视觉和文本隐藏表示的串联得到的: vi =。

尽管很简单,但该方法在图像级实体交互建模中显示出三个重要的优势: (1)实体(包括查询和上下文实体)的消息通过多个自我关注的布局来融合来帮助模拟复杂的实体交互。(2)将实体的视觉信息和文本信息融合成深度的多模态表示形式。(3)利用预先训练好的深度视觉语言表征来促进常识性理解。

其中ci是ri的分类器嵌入。通过这种方式,对比注意在黄金关系和负向关系的袋表示之间施加了明确的界限,以处理复杂的常识关系的总结。对比注意也可以被视为关系查询和图像实例之间的一种交叉注意(Vaswani et al. 2017),这可能从多层堆叠中获益。我们把它留给以后的工作吧。
为CKE集成多源信息。直观地说,多个异构的数据源可以为常识性学习提供互补的信息。我们表明,这种互补性可以通过来自每个信息源的简单模型集成来利用,其中聚合的三重态得分是来自每个信息源的预测得分的加权和。
实验性的设置。(1)基准测试和基线。如试点实验部分所述,我们在由视觉基因组构建的CKE基准上进行实验,并与来自不同信息源的强基线进行比较。我们还包括了一个随机的基线它可以随机地预测实体对的关系。对于多源信息集成,我们集成了聪明、RTP和Vanilla-FT。(2)评估指标。为了提供多维评价,我们还报告了曲线上的最大f1,以及精度@K%(P@K%)三重态预测。
主要结果。从表1中的实验结果来看,我们有以下观察结果: (1)在微观和宏观指标上,聪明一致地在所有基线模型中都取得了最好的结果。具体来说,igriny提高了基于图像的模型的性能,并显著优于之前基于PLM的最佳结果3.9 AUC和6.4 mAUC点。结果表明,聪明可以从视觉感知中提取常识,具有良好的质量。(2)集成多源信息进一步提高了比单源模型的性能。这表明CKE可以从利用不同来源的互补信息中获益。
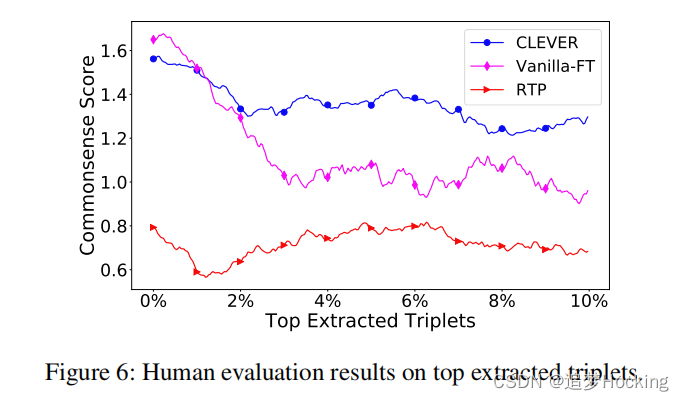
人类评估。除了保留的评估之外,我们还对顶级预测进行了人工评估。我们选择在每个源上达到最佳微性能的模型,包括RTP,香草-ft和聪明。具体来说,对于每个模型,我们以1:50的比例从前10%的三胞胎预测中抽样,结果得到1200个三胞胎用于人类评估。每个三联体用三个inde标记等待注释者来决定常识性得分:难以置信(0),可信但罕见(1),常见(2)。我们在图6中报告了由人类注释者给出的局部平均的三重态常识得分。我们可以观察到,在大多数情况下,由聪明人提取的三胞胎被分配了显著更高的常识分数。此外,聪明的人的常识得分与人类得分的0.78,说明我们模型的常识得分可以很好地与人类判断一致。原因是对比注意机制可以隐式地利用实例的冗余来反映常识程度,其中一个包中的多个信息实例可以有助于更高的常识得分。
可解释性。除了竞争表现之外,聪明的一个关键优势是,提取的常识知识可以通过对图像实例的对比注意力得分来基于视觉感知。如图5所示,信息图像具有较大的常识学习的注意力分数。与基于PLM的方法相比,纯粹基于文本标记之间的相关性产生常识知识,聪明使可信的常识知识获取在提取过程中具有更好的可解释性。从应用的角度来看,所选的信息图像也可以作为KBs中提取的三联体的支持证据以便在下游应用程序中更好地利用知识。

消融研究。我们通过用基于cnn的编码器替换VLP编码器,并分别用现有的多实例学习方法替换对比注意机制来进行消融研究。从表2中的结果中,我们可以看到,这两个组件对最终的结果都有贡献。结果表明,图像级实体交互理解和包级总结对于良好的CKE性能都很重要。
Effect of Bag Size袋尺寸的影响。直观地说,一个包中的多个图像可以提供关于一个实体对的不同和互补的信息,以便进行健壮的常识学习。为了研究袋子尺寸的影响,我们对不同尺寸的智能进行了实验。从图4的结果中,我们观察到: (1)学习常识性交互需要一定数量的图像。当使用非常小的袋子尺寸时,性能显著下降。(2)当袋尺寸大于20时,性能改善不显著。我们假设的原因是,虽然一个更大的包提供了更丰富的常识信息,但它也用更嘈杂的实例来挑战模型。因此,需要开发更先进的方法来更好地利用更大的图像袋中的丰富信息,并将其留给未来的工作。

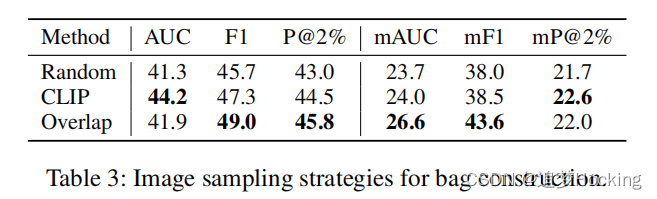
实例抽样策略在袋施工中的影响。考虑到通常包含一个实体对的大量开放图像,我们希望选择那些可能在低水平下表达常识性交互的实例建造这个袋子的成本。除了空间重叠策略外,我们还采用了另外两种抽样策略: (1)随机抽样。随机选择一些候选图像来组成这个包。(2)基于clip的采样。为实体对构造了一个文本查询:s与o有某种关系。然后,我们使用CLIP(Radford et al. 2021)对文本查询和候选图像进行编码,并选择相似度得分最高的图像。从表3中可以看出: (1)来自CLIP的实体交互先验和空间重叠有助于选择信息丰富的图像进行构建袋。(2) CLIP对空间重叠没有明显的优势。原因是空间重叠对实体对交互包含了更多的归纳偏差,而CLIP被优化来处理一般句子。因此,由于袋的简单和效率,我们选择空间重叠。
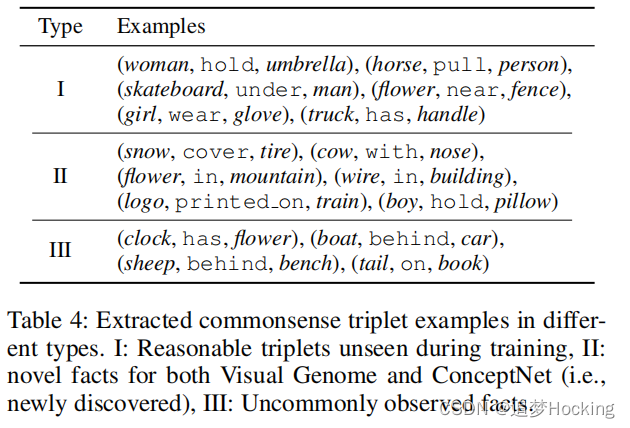
案例研究。我们提供了表4中sring中提取的三胞胎的示例。我们可以看到,我们的模型可以提取在训练过程中看不到的合理的常识性知识,最重要的是,提取新的事实来补充常识性kb。我们注意到,我们的模型有时可以从意外的场景图像中产生异常观察到的事实。我们建议读者参考附录,了解我们的模型为III型的例子选择的支持图像。