文章目录
- 1. Re-sampling
- 1.1 Class-balanced re-sampling
- (1) Decoupling
- ① 网络架构
- ② Sampling策略
- ③ Classifier的学习策略
- (2) SimCal
- ① 比较
- (3) DCL
- (4) Balanced meta-softmax
- (5) FASA
- (6) LOCE
- (7) VideoLT
- 1.2 Scheme-oriented sampling
- (1) LMLE
- (2) PRS
- (3) BBN
- (4) LTML
- (5) GIST
- (6) BAGS
- (7) LST
- (8) ACE
- 2. Cost-sensitive Learning
- 2.1 Class-level re-weighting
- (1) Balanced meta-softmax
- (2) LADE
- (3) CB
- (4) FL
- (5) Meta-Weight-Net
- (6) DisAlign
- (7) Distribution-balanced loss
- (8) Equalization loss v2
- (9) Seesaw loss
- (10) ACSL
- 2.2 Class-level re-margining
- (1) LDAM
- (2) Bayesian estimate
- (3) DB
- (4) LOCE
- (5) PML
- (6) RoBal
- 3. Logit Adjustment
- (1) RoBal
- (2) LADE
- (3) UNO-IC
- (4) De-confound-TDE
- (5) DisAlign
- 4. Discussions
类重平衡 \mathbb{类重平衡} 类重平衡是长尾学习的主流范式,在模型训练过程中平衡不同类的训练样本数。我们从基于重采样的方法开始,然后是代价敏感的学习和logit调整。
1. Re-sampling
重采样
重采样
重采样是近几十年来解决类不平衡最广泛使用的方法之一,[32],[34],[112],[113],[114],[115],[116]。重采样的常见做法是随机过采样ROS和随机欠采样 RUS。为了重新平衡类,ROS随机重复尾部类的样本,而RUS随机丢弃头部类的样本。然而,当类极度倾斜时,ROS倾向于过拟合到尾部类,而RUS倾向于降低头部类的模型性能。最近的长尾学习研究不再采用随机重抽样,而是发展了各种抽样方法,包括Class-balanced re-sampling 和Scheme-oriented sampling。
重采样-方案
1.1 Class-balanced re-sampling
类平衡重采样方法如下:
(1) Decoupling
从Decoupling 解耦3.1.1.1 & 3.3.1.4 & 3.3.2 &3.3.3 Paper解读开始,通过实验评估了长尾识别上表示学习的各种采样策略。具体的抽样策略包括:实例平衡抽样、类平衡抽样、平方根抽样和渐进平衡抽样。在实例平衡抽样中,每个样本被抽样的概率是相等的,而在类平衡抽样中,每个类被选择的概率是相等的。此外,平方根抽样[117]是实例平衡抽样的一种变体,其中每个类的抽样概率与对应类的样本量的平方根有关。渐进平衡抽样[32]在实例平衡抽样和类平衡抽样之间逐步插入。
① 网络架构
将分类网络分解为 representation learning 和 classification 两部分,系统的研究了这两部分对于Long-tailed问题的影响。
- 数据不平衡不会影响高质量Representations的学习。即random sampling策略往往会学到泛化性更好的representations;
- 使用random sampling 学习representations,然后调整classifier的学习作为
strong baseline。 - 首先使用不同的sampling策略
训练representations:random sampling、class-balanced sampling、mixture of them ; - 然后使用不同的方法来获得有
平衡决策边界的classifier:使用class-balanced sampling 来re-training线性分类器的参数;对学到的 representations 使用KNN进行分类;通过normalize classifier的weight来使得weight的尺度变得更加balanced,并添加了一个temperature参数来调节normalization的过程。
② Sampling策略
作者将三种Sampling方法统一为公式1,即从类别
j
j
j 中挑选一个样本的概率
p
j
p_j
pj。其中,
n
j
n_j
nj 代表的是类别
j
j
j 的样本数量,
C
C
C 是类别数量,
q
∈
[
0
,
1
]
q\in[0,1]
q∈[0,1] 。
q
=
1
q=1
q=1:random sampling / Instance-balanced sampling;
q
=
0
q=0
q=0:Class-balanced Samling;
q
=
1
2
q=\frac12
q=21:Square-root Sampling;
p
j
=
n
j
q
∑
i
=
1
C
n
i
q
(1)
p_j=\frac{n^q_j}{\sum^{C}_{i=1}n^q_i}\tag1
pj=∑i=1Cniqnjq(1)
有人提出在训练前期使用IB random-sampling策略,后期使用 CBclass-balanced sampling。由此,作者提出了一个Softer版本的结合方式,PB Progressively-balanced Sampling。如公式2所示。其中,
t
t
t 为当前训练的Epoch,
T
T
T 为总的训练Epoch。
p
j
P
B
(
t
)
=
(
1
−
t
T
)
p
j
I
B
(
t
)
+
t
T
p
j
C
B
(
t
)
(2)
p_j^{PB}(t)=(1-\frac tT)p_j^{IB}(t)+\frac tTp_j^{CB}(t)\tag2
pjPB(t)=(1−Tt)pjIB(t)+TtpjCB(t)(2)
③ Classifier的学习策略
- cRT Classifier Re-training
固定住representations部分,随机初始化classifier的weight和bias参数,并使用class-balanced sampling再训练少量epoch。 - NCM Nearest Class Mean classifier
首先将training set里的每个类别计算feature representaitions的均值,然后在test set上执行最近邻查找。或者将mean features进行L2-Normalization之后,使用余弦距离或者欧氏距离计算相似度,余弦相似度可以通过其本身的normalization特性来缓解weight imbalance的问题。 -
τ
−
\tau-
τ−-normalized
τ
−
\tau-
τ−normalized classifier
令 W = w j ∈ R d × C W={w_j}\in R^{d\times C} W=wj∈Rd×C ,其中, w j ∈ R d w_j\in R^d wj∈Rd 是类别 j j j 的classifier权重。按照公式3对 w j w_j wj 进行rescale。其中, ∣ ∣ ⋅ ∣ ∣ ||·|| ∣∣⋅∣∣ 代表的是L2-Norm,当 τ = 1 \tau=1 τ=1 时,就是标准的L2-Normalization;当 τ = 0 \tau=0 τ=0 时,表示没有进行scaling操作。 τ ∈ ( 0 , 1 ) \tau \in(0,1) τ∈(0,1) ,其值是通过cross-validation来选择的。
w i ~ = w i ∣ ∣ w i ∣ ∣ τ (3) \tilde{w_i}=\frac {w_i}{||w_i||^\tau}\tag3 wi~=∣∣wi∣∣τwi(3) - LWS Learnable weight scaling
如果将公式3写为公式4的形式,我们可以将 f i f_i fi 看作是一个可学习的参数,我们通过固定住representations和classifier两部分的weighs来只学习这个scaling factors。
w i ~ = f i ∗ w i , w h e r e f i = 1 ∣ ∣ w i ∣ ∣ τ (3) \tilde{w_i}=f_i*w_i,where f_i=\frac1{||w_i||^\tau}\tag3 wi~=fi∗wi,wherefi=∣∣wi∣∣τ1(3)
(2) SimCal
Simple Calibration SimCal 简单校准3.1.1.1 & 3.3.3 & 3.3.4 Paper解读提出了一种新的双层类平衡采样策略来处理长尾实例分割。具体来说,双层采样策略将图像级重采样和实例级重采样相结合,以缓解实例分割中的类不平衡。
① 比较
- bi-level sampling scheme:decoupling(3.1.1.1)类似,先用正常数据训练模型,然后固定模型参数,用平衡采样的数据再训练分类器部分。这两个分类器都要保留,长尾分类器&平衡分类器
- Dual Head Inference:BBN(3.1.1.2)类似,只有采样方式略有不同,两个分类器,,一个用长尾分类器,在头部表现好;另一个平衡分类器,在尾部类表现好,两个一起做决策。
参考##### ②##### ③
(3) DCL
Dynamic curriculum learning DCL 动态课程学习Paper解读开发了一种新的课程策略,对数据进行动态采样以实现类再平衡。具体来说,在训练过程中,从一个类中采样的实例越多,之后对这个类采样的概率就越低。遵循这一思想,DCL首先进行随机抽样,学习一般表示,然后根据课程策略对更多的尾类实例进行抽样,以处理长尾类失衡。
(4) Balanced meta-softmax
Balanced meta-softmax 平衡元softmax3.1.1.1 &3.1.2.1 Paper解读开发了一种基于元学习的采样方法,用于估计长尾学习不同类的最佳采样率。具体而言,所提出的元学习方法是一种双层优化策略,通过优化元平衡验证集上的模型分类性能来学习最佳样本分布参数。
(5) FASA
Feature augmentation and sampling adaptation FASA 特征增强和自适应采样Paper提出利用元平衡验证集上的模型分类损失(作为度量)来调整不同类的特征采样率,从而对代表性不足的尾类进行更多的采样。
(6) LOCE
Long-tailed object detector with classification equilibrium LOCE 分类平衡的长尾目标识别Paper解读提出使用平均分类预测分数(即运行预测概率)来监控模型在不同类别上的训练,并指导记忆增强特征采样以提高尾类性能。
(7) VideoLT
VideoLTPaper引入了一种新的FrameStack方法来解决长尾视频识别问题,该方法可以进行帧级采样来重新平衡类分布。具体来说,在训练过程中,FrameStack会根据运行模型的性能动态调整不同类的采样率,从尾部类(通常运行性能较低)中采样更多的视频帧,从头部类中采样更少的视频帧。
1.2 Scheme-oriented sampling
面向方案的采样旨在促进长尾学习的特定学习方案,如度量学习和集成学习。
(1) LMLE
large margin local embedding LMLE 大边缘局部嵌入3.1.1.2 & 3.3.1.1Paper解读开发了一种新的度量学习的五元组抽样方案,以学习既保持聚类间边缘又保持类间边缘的高质量特征。与triplet loss 三元组损失[118]不同的是,LMLE采用了一个五元组采样器,对四个对比组进行采样,包括一个正对和三个负对。正对是距离最近的类内样本,负对包括两个类内样本(类内最近和类内最远)和最近的类间样本。在此之后,LMLE引入了一个五元态损失,以鼓励采样的五元态遵循特定的距离顺序。通过这种方式,学习的表示不仅保留了类内聚类的局部性,而且保留了类间的区别。此外,五元组损失中的每个数据批包含相同数量的来自不同类的样本,用于类重新平衡。
(2) PRS
Partitioning reservoir sampling PRS 分区储层抽样Paper提出了一种基于重放的采样方法来处理连续的长尾学习。一个关键的挑战是重放内存无法考虑类不平衡的问题,因为没有关于未来输入的信息可用。为了解决这个问题,PRS开发了一种在线内存维护算法,动态地维护来自不同类的样本的运行统计信息。基于运行统计数据,PRS可以针对不同的类动态调整内存大小和采样/输出操作方案。
(3) BBN
bilateral-branch network BBN 双边分支网络3.1.1.2 & 3.3.4Paper解读基于一种新的双边采样策略,开发了两个网络分支(即传统学习分支和再平衡分支)来处理类不平衡。具体而言,BBN对传统学习分支采用均匀采样来模拟原始的长尾训练分布;同时,BBN在再平衡分支中使用反向采样器,对更多的尾类样本进行采样,提高尾类性能。最后的预测是两个网络分支的加权和。
(4) LTML
随后,long-tailed multi-label visual recognition LTML 长尾多标签视觉识别3.1.1.2 & 3.3.4 Paper扩展了双边分支网络来解决长尾多标签分类问题。
(5) GIST
Geometric structure transfer GIST 几何结构转移3.2.1.2 & 3.2.1.1 & 3.3.2 Paper解读也探索了这种从头到尾类知识转移的双边抽样策略。
pre-training and fine-tuning 解耦 和 knowledge transfer知识迁移
- 先看上图(b),蓝色的点是 class-specific 的,不同类别之间互相独立学习得到; 蓝色箭头,则是所有类别共享的(这就可以做文章了,在many-shot类别上把这个Displacement vector 学好,然后就可以“丝滑”的迁移给medium、few-shot 类别使用)。蓝色的箭头,驱动着数据把"边界几何信息"学习到,走到红色的点位置处(Constellation vector)。>2. 再对应的看上图(a),可以认为,黑色的一个个小圈,就是每个数据类别的一些Constellations。
- 分类算法的目的就在于,画出黑色的虚线,实现不同类别的区分。
- 在实现这一目的之前,本文的做法就是,找出每个类别的“几何边界”(class geometry),也就是(a)中的红圈和绿圈。
5.那么这俩圈怎么来的呢?那就是(b)中的第三子图一步步得到的了: 1) 先定每个类别的location蓝点,2) 然后以class-shared的方式,学习Constellations vector 和 Displacement vector,把各个类别的“边界感”给“模拟”出来,就得到我们要的红绿圈了。
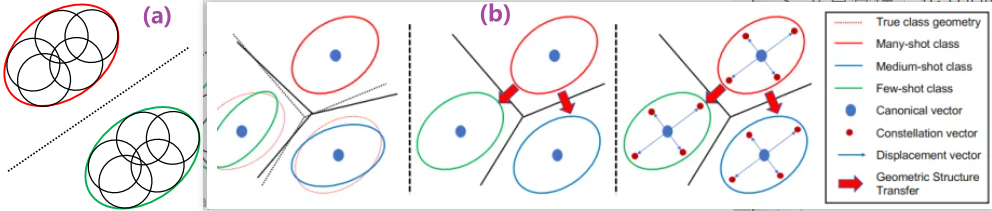
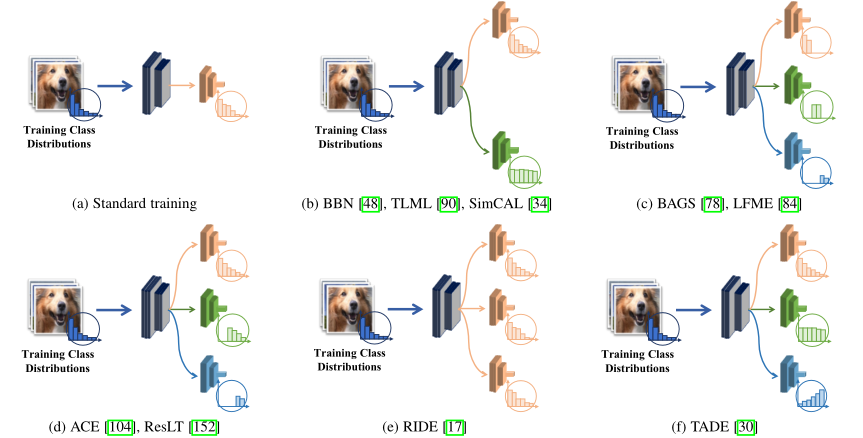
(6) BAGS
balancing group softmax BAGS 平衡组softmax3.1.1.2 & 3.3.4 Paper解读除了对双边分支进行采样外,还提出根据每个类的样本数量将类划分为几个平衡组,每个组的类训练数据数量相似。在此基础上,BAGS使用不同的样本组训练不同的分类头,使它们对训练数据数量相似的类进行softmax操作,从而避免了由于不平衡而导致的严重偏倚分类器。
(7) LST
之后,learning to segment the tail LST 学习分割尾部Paper解读也将训练样本分成几个平衡的子集,并基于类增量学习对每个子集进行处理。为了解决类增量学习中的灾难性遗忘问题,LST开发了一种类平衡的数据回复/采样策略,保持相对平衡的样本集用于知识蒸馏。
(8) ACE
ally complementary experts ACE 盟友互补专家3.1.1.2 & 3.3.4 Paper解读没有将样本分成几个平衡的组,而是将样本分成几个功能多样化的子集,其中一个子集包含所有类,一个子集包含中间和尾部类,另一个子集只包含尾部类。基于这些子集,ACE训练了具有特定和互补功能的不同专家进行集成学习。
2. Cost-sensitive Learning
成本敏感学习
成本敏感学习
成本敏感学习试图通过在训练期间调整不同类的损失值来重新平衡类[119]、[120]、[121]、[122]、[123]、[124]、[125]。近年来的研究开发了各种代价敏感的长尾学习方法来处理类不平衡,包括类重加权和类re-margin。
损失函数
表3 损失汇总。在这个表中,z 和 p 表示预测的logits和样本x的softmax概率,其中zy和py对应类y。此外,n表示训练数据的总数,ny表示类y的样本数。此外,π 表示样本频率的向量,其中 πy = ny / n 表示类y的标签频率。如果没有更具体的数值,ω 表示类权重,∆表示类margin(边缘)。与损失相关的参数包括γ。

2.1 Class-level re-weighting
类重加权最直观的方法是直接使用训练样本的标签频率进行损失重加权,即加权softmax损失(表3)。根据样本影响[105]或模型预测与平衡的参考分布[29]之间的分布对齐,通过调整标签频率对损失权重的影响,可以进一步改善损失。
(1) Balanced meta-softmax
Balanced meta-softmax 平衡元softmax3.1.1.1 &3.1.2.1 Paper解读除了对损失值进行重加权外,还提出在训练过程中使用标签频率来调整模型预测,从而通过先验知识来缓解类不平衡的偏差。
(2) LADE
接着LADE 理清长尾标签分布3.1.2.1 &3.1.3 Paper解读1解读2
引入标签分布分出损失,从长尾训练分布中将学习的模型分出来,然后在测试标签频率可用的情况下,对任意测试类分布进行模型自适应。
(3) CB
CB 类平衡损失Paper解读1链接没有使用标签频率,而是引入了有效数的新概念来近似不同类别的期望样本数。这里,有效数是训练样本数的指数函数。遵循这个概念,CB损失强制一个类平衡的重加权项,与有效类数量成反比,以解决类的不平衡(参见表3)。
(4) FL
FL 焦点损失Paper解读探讨了重加权的类别预测难度。具体来说,Focal loss观察到类不平衡通常会增加预测概率低于头部类的尾部类的预测难度,因此,Focal loss使用预测概率反向重加权类(表3),以便它可以将更高的权重分配给较难的尾部类,而将较低的权重分配给较容易的头部类。
(5) Meta-Weight-Net
除了使用预定义的权重函数外,还可以从数据中学习类的权重。在Meta-Weight-Net 元权重网Paper解读中,在平衡验证集的指导下,更新由单层 MLP 近似的权重函数用于拟合长尾分布,以便在统一测试集上学习性能良好的模型。
(6) DisAlign
此外,Distribution Alignment DisAlign 分布对齐DisAlign3.1.2.1 & 3.1.3 & 3.3.3 Paper解读开发了自适应校准函数来校准模型分类器。通过最小化调整后的预测分布和给定的平衡参考分布之间的KL-Divergence,自适应地学习校准函数。
(7) Distribution-balanced loss
长尾学习中的另一个问题是负梯度过度抑制[19],[126]。即在softmax或sigmoid交叉熵中,一个类的每一个正样本都可以被视为其他类的负样本,导致尾类得到更多的抑制梯度。为了解决这个问题,Distribution-balanced loss 分布平衡损失Paper解读1解读2解读3通过一种新的负容差正则化来缓解梯度过抑制。同时,它还评估每个类别的期望采样频率与实际采样频率之间的差距,然后使用这两个频率的比值来重新计算不同类别的权重损失值。
(8) Equalization loss v2
Equalization loss 均衡损失Paper解读当尾类样本作为大量头部类样本的负对时,直接降低尾类样本的损失值。Equalization loss v2 均衡损失v2Paper解读1解读2解读3通过将多类检测问题建模为一组独立的子任务,其中每个子任务关注一个类,进一步扩展了均衡损失。更具体地说,均衡损失v2引入了一种新的梯度引导的重加权机制,动态地增加正梯度的权重,降低负梯度的权重,用于每个子任务上的模型训练。
(9) Seesaw loss
Seesaw loss 跷跷板损失Paper解读使用两个重加权因子:缓解因子和补偿因子,对每个类别的正梯度和负梯度进行重新平衡。为了解决梯度过度抑制的问题,在训练过程中,减缓因子根据不同类别间累积样本数的动态比值来减轻对尾类的惩罚。同时,如果观察到假阳性样本,补偿因子将惩罚权重提高到相应的类别,以改善模型的甄别。
(10) ACSL
Adaptive class suppression loss ACSL 自适应类抑制损失Paper解读使用输出置信度来决定是否对负标签的梯度进行抑制。具体来说,如果一个负面标签的预测概率大于预先定义的阈值,则应该混淆模型,因此将该类的权重设置为1,以提高模型的辨别能力。否则,权重设置为0,以避免负过度抑制。
论文汇总-小样本目标检测提出 Adaptive Class Suppression Loss(ACSL),有效地防止相邻类别的训练不一致,提高稀有类别的判别能力。
2.2 Class-level re-margining
类重边缘试图通过调整不同类的学习特征和模型分类器之间的最小margin(即距离)来处理类的不平衡。
Margin
(1) LDAM
Label-Distribution-Aware Margin Loss LDAM 标签分布感知边际损失Paper解读1解读2解读3通过强制基于标签频率的类依赖margin,和具有更大margin的尾部类,扩展了现有的soft margin损失。然而,简单地使用LDAM损失在经验上不足以处理类的不平衡。因此,LDAM进一步引入了一种递延重平衡优化计划,即在学习了一段时间LDAM损失后,以类平衡的方式对LDAM损失进行重加权,从而对类进行重平衡。
(2) Bayesian estimate
Bayesian estimate 贝叶斯估计Paper解读发现类预测的不确定性与训练标签频率成反比,即尾部类更不确定。受此启发,贝叶斯估计提出利用估计的类不确定性进行重margin损失,使得类不确定性较高的尾类损失值更高,从而特征与分类器之间的margin更大。
(3) DB
Domain Balancinng DB 域平衡Paper解读研究了一个长尾域问题,即少量域(包含多个类)频繁出现,而其他域较少。为了解决这一问题,本文提出了一种基于类间特征紧凑性的域频率指标,并利用该指标对尾域的特征空间进行重margin划分。
(4) LOCE
LOCE 分类平衡器Paper解读使用平均分类预测分数来监测不同类的学习状态,并应用它来指导类margin调整,以提高尾类的表现。
论文5-使用平均分类得分来表示每个类别的模型的学习状态,并通过平衡损失EBL 和记忆增强特征采样 MFS 方法来平衡分类。
(5) PML
Progressive margin loss PML 渐进边际损失Paper用两个margin项调整长尾学习的类margin:有序margin和变分margin。有序margin旨在提取区分特征,维持年龄顺序关系。变分margin试图逐步抑制头类来处理长尾训练样本中的类不平衡。
(6) RoBal
RoBal3.1.2.2 &3.1.3 Paper解读认为,现有的重margin方法鼓励尾类有更大的边距,可能会降低头部类的特征学习。因此,RoBal强制使用一个额外的margin项来扩大头部类的特征margin。
RoBal长尾分布下的对抗鲁棒性,由两个专用模块组成,尺度一致性分类器和两阶段重平衡策略(训练阶段进行margin工程 & 推理阶段进行边界调整)
3. Logit Adjustment
L
o
g
i
t
调整
Logit调整
Logit调整,即基于标签频率对模型logits进行事后移动,是在类不平衡问题中获得较大的类间相对余量的经典思想。解读
(1) RoBal
最近,一项研究全面分析了长尾识别中的logit调整方法,从理论上表明logit调整是Fisher一致的,可以使平均类误差最小化。遵循这一思想,RoBal3.1.2.2 &3.1.3 Paper解读应用了一种后处理策略,根据训练标签频率调整余弦分类边界。
(2) LADE
LADE 理清长尾标签分布3.1.2.1 &3.1.3 Paper没有使用训练数据的标签频率,而是提出使用测试数据的标签频率(如果有的话)进行后调整模型输出,这样训练后的模型就可以针对任意测试类分布进行校准。
(3) UNO-IC
UNO-IC 不平衡数据集的后验校正Paper解读(从最优贝叶斯分类器的角度出发)提出使用一个超参数,在平衡元验证集上进行调优,校准模型分类器以处理类不平衡,从而在统一测试集上获得更好的性能。
(4) De-confound-TDE
De-confound-TDE 动量因果效应3.1.3 & 3.3.2 Paper解读引入了一个因果分类器(参考第3.3.2节),该分类器在训练过程中通过计算特征的指数移动平均向量来记录偏差信息,然后在推理过程中通过减去偏差信息来去除不良的因果效应。
decouple VS De-confound-TDE
- decouple:两阶段都在train过程中。一阶段长尾分布下训练representation + classifier;二阶段直接通过暴力resample来优化classifier。
- de-confound:可以看作两阶段。一阶段在train过程中,通过重采样和normalized的措施来训练representation + classifier;二阶段在test过程中,用一阶段中统计的bias来缓解测试中的class bias,得到TDE。
(5) DisAlign
Distribution Alignment DisAlign 分布对齐DisAlign3.1.2.1 & 3.1.3 & 3.3.3 Paper解读应用了自适应校准函数进行logit调整,其中校准函数是通过将校准的预测分布匹配到相对平衡的类分布来学习的。
4. Discussions
与其他长尾学习范式相比,类重平衡方法相对简单,但可以达到相当甚至更好的性能。其中一些方法,特别是成本敏感的学习方法,在理论上受到启发或保证能够处理长尾问题。这些优点使类重平衡成为现实应用程序的一个很好的候选。
然而,这种类型的方法的一个缺点是,大多数类重平衡方法以头类性能为代价来提高尾类性能,这就像在性能跷跷板上玩一样。尽管整体性能得到了提高,但它不能从本质上解决信息缺乏的问题,特别是由于数据量有限而导致的尾部类。为了解决这一限制,一个可行的解决方案是对所有类进行信息增强,如下所示。







![容器中的operator[]注意事项](https://img-blog.csdnimg.cn/1006e338c1e04e7ca158ae4d998d1f4c.png#pic_center)