文章目录
- 1. Representation Learning
- 1.1 Metric learning
- (1) large margin local embedding LMLE
- ①##### ②##### ③
- (2) Range loss
- (3) CRL
- (4) KCL
- (5) Hybrid
- (6) PaCo
- (7) DRO-LT
- 1.2 Sequential training
- (1) HFL
- (2) Unequal-training
- 1.3 Prototype learning
- (1) OLTR
- (2) IEM
- 1.4 Transfer learning
- (1) UD
- (2) Decoupling
- (3) MiSLAS
- 2. Classifier Design
- (1) Decoupling
- (2) RTC
- (3) De-confound-TDE
- (4) GIST
- 3. Decoupled Training
- (1) Decoupling
- (2) KCL
- (3) MiSLAS
- (4) OFA
- (5) SimCal
- (6) DisAlign
- (7) DT2
- 4. Ensemble Learning
- (1) BBN
- (2) LTML
- (3) SimCal
- (4) BAGS
- (5) LFME
- (6) ACE
- (7) ResLT
- (8) RIDE
- (9) TADE
- 5. Discussions
除了类别重平衡和信息增强外,研究人员还探索了在不平衡学习中
改进网络模块
\mathbb{改进网络模块}
改进网络模块的方法。这些方法可分为四类:表征学习改进特征提取器,分类器设计增强模型分类器,解耦训练增强特征提取器和分类器的学习,集成学习改进整体结构。
1. Representation Learning
表征学习 表征学习 表征学习现有的不平衡表征学习方法基于四种主要范式,即Metric learning、Sequential training、Prototype learning和Transfer learning。
1.1 Metric learning
Metric learning 度量学习旨在设计特定任务的距离度量,以确定目标之间的相似性或差异性;在不平衡学习中,基于度量学习的方法设计基于距离的损失,以探索更具区分性的特征空间。
(1) large margin local embedding LMLE
large margin local embedding LMLE 大边缘局部嵌入3.1.1.2 & 3.3.1.1Paper解读引入一种五元组损失来进行表征学习,可以保持簇间和类间的margin。
①##### ②##### ③
(2) Range loss
Range lossPaper解读使用一个小批次内所有样本对之间的总距离,它使用整个批次的统计信息,而不是样本级别的统计信息,从而缓解了总体类别数据数量不平衡的偏差;更具体地说,Range loss通过最大化小批量中任意两个类中心的距离来扩大类间距离,并通过最小化类内样本之间的最大距离来减少类内变化。通过这种方式,Range loss可以获得具有更好识别能力和更少不平衡偏差的特征。
(3) CRL
Class rectification loss CRL 类校正损失Paper解读通过增强尾类样本表示,以具有更大程度的类内紧凑性和类间距离。为此,CRL为尾部类构造大量hard-pair三联体,并应用Class rectification loss(类似the triplet loss三联体损失)作为类平衡约束。这样,学习模型克服了类不平衡对表征学习的负面影响。
(4) KCL
最近的研究也探讨了长尾问题的对比学习。KCL k-positive对比学习3.3.1.1 & 3.3.3 Paper解读解读2提出了一个k-positive的对比损失来学习一个平衡的特征空间,这有助于缓解类的不平衡,提高模型的泛化。
k-positive对比学习:①继承了对比学习在学习平衡特征空间方面的优势;②提高了特征空间的判别能力。
与缺乏语义区分的对比学习方法不同,KCL 利用可用的样本语义标签,通过将具有锚的相同标签的 k 个样本的语义嵌入到对比损失中,学习具有理想平衡性和区分性的表示。
(5) Hybrid
随后,HybridPaper解读引入了一种原型的对比学习策略来增强长尾学习。
(6) PaCo
PaCo 参数化对比学习Paper解读进一步创新了有监督的对比学习,增加了一组参数化的可学习类中心,将类中心作为分类器的权值,类中心起着与分类器相同的作用。
(7) DRO-LT
DRO-LTPaper解读对原型对比学习进行了分布鲁棒优化的扩展,使得学习的模型对数据分布移位具有更强的鲁棒性。
1.2 Sequential training
Sequential training 序列学习解读
(1) HFL
Hierarchical feature learning HFL 分层特征学习 Paper解读发现每个类别在有区分度的视觉表征中都有各自独特的特征。因此,HFL 层次化地将目标聚类到视觉上相似的类别组中,形成分层聚类树。在该聚类树中,原始节点中的模型在ImageNet-1K上进行预训练;每个子节点中的模型继承其父节点的模型参数,然后基于簇节点中的样本进行微调。通过这种方式,从拥有大量类别的组中获得的知识逐步迁移到拥有较少类别的子组中。
(2) Unequal-training
Unequal-training 不等训练[74]Paper解读提出将数据集分为头类和尾类子集,并在训练过程中区别对待。首先,Unequal-training利用头类样本训练出具有相对鉴别性和抗噪声的特征,并引入新的抗噪声损失。然后,利用尾类样本,通过hard identities mining 和新的center-dispersed loss增强表征的类间辨别能力。这里,中心分散损失是基于每个类的归一化特征。
1.3 Prototype learning
基于Prototype learning 原型学习的方法旨在学习特定于类别的特征原型,以提高不平衡学习的性能。
(1) OLTR
OLTR 开放式长尾识别Paper解读2解读1创新性地探索了在开放世界中处理不平衡识别的特征原型的想法,其中测试集包括头部类、尾部类和开放类 (开放类表示训练集中不存在的测试类别)。OLTR 维护了一个包含区分性特征原型的视觉元记忆,并使用从视觉中提取的特征记忆来扩充原始特征。通过这种方式,学习到的特征空间具有更强的辨别能力,来自新类的样本特征将远离存储,更接近原点。这样的特征空间使 OLTR 能够区分闭集类并检测新类。此外,OLTR 还探索了一种自注意力机制来增强特征学习。
OLTR模型有两个主要模块:
- dynamic meta embedding动态元嵌入:在头尾类之间联系和传递知识
动态元嵌入结合了直接图像特征和相关的记忆特征,特征范数表示对已知类的熟悉程度。
卷积神经网络CNN的softmax层被用来分类,CNN的倒数第二层被当做特征,最后一层被当做线性分类器。特征和分类器以端到端的方式从大数据中联合训练。让 u d i r e c t u^{direct} udirect表示从输入图像中提取的直接特征,最终的分类准确率很大程度上取决于这个直接特征的质量。
虽然前馈CNN分类器能够很好地处理大的训练数据,但它缺乏来自尾类小数据足够的监督更新。我们提议用一个在记忆模块中连接视觉概念的特征记忆 u m e m o r y u^{memory} umemory来丰富直接特征 u d i r e c t u^{direct} udirect。让 u m e t a u^{meta} umeta表示生成的特征元嵌入,它被反馈到最后一层进行分类。记忆特征 u m e m o r y u^{memory} umemory和元嵌入 u m e t a u^{meta} umeta都依赖于直接特征 u d i r e c t u^{direct} udirect。
与直接功能不同,记忆特征从训练类别中捕获视觉概念,这些概念是用一个更浅的模型从记忆中检索出来的。- modulated attention 调制注意:保持头尾类之间的区别。
(2) IEM
随后, inflated episodic memory IEM 膨胀情景记忆Paper解读通过动态更新方案进一步创新了元嵌入记忆,其中每个类都有独立的、可微的记忆块,而每个记忆块记录了对应类别最具鉴别性的特征原型。由于动态记忆库只包含最具鉴别性的特征原型,因此不受类数不平衡问题的影响。此外,IEM还探索了区域自注意机制,以进一步增强表征学习。
1.4 Transfer learning
迁移学习在3.2.1节中,我们介绍了一些基于迁移学习的不平衡方法,如SSP(3.2.1.2 & 3.3.1.4)和LEAP(3.2.1.1 & 3.3.1.4),这些方法改进了表征学习。
(1) UD
unsupervised discovery UD 无监督发现 Paper提出使用自监督学习来帮助从具有长尾目标的图像中发现新的、更细粒度的目标。具体来说,首先,UD 使用预训练的 class-agnostic mask proposal network 类别不可知的掩码提议网络为所有可能的目标生成目标边界框和分割掩码;然后,UD基于边界框和语义掩码的特征,应用三种新的自监督三元组损失来学习双曲特征空间;最后,基于学习的特征,UD进行无监督聚类和 exclusive label assignation 专有标签分配,以发现新的、更细粒度的目标。
(2) Decoupling
除上述学习方案外,Decoupling 解耦3.1.1.1 & 3.3.1.4 & 3.3.2 &3.3.3 Paper解读创新了长尾表示学习,采用不同的抽样策略,包括实例平衡、类平衡、平方根和渐进平衡抽样。
(3) MiSLAS
在实例平衡抽样之后,MiSLAS3.2.2.2 & 3.3.1.4 & 3.3.3 Paper解读实证研究了数据混淆对长尾表示学习的影响。
2. Classifier Design
表4 分类器的摘要,其中w、f、b、φ和p分别表示模型分类器、样本特征、偏差、softmax函数和预测概率。此外,d是指数移动平均特征的单位向量。程度因子用τ表示,其他与分类器相关的超参数包括γ和α。

分类器设计 分类器设计 分类器设计,除了表征学习,研究人员还设计了不同类型的分类器来处理不平衡问题。在一般的视觉问题中,深度学习通常是使用线性分类器: p = φ ( w ⊤ + b ) p = φ(w^\top+b) p=φ(w⊤+b),其中 φ φ φ 表示softmax函数,偏差项 b b b 可以丢弃。
然而,长尾不平衡通常会导致头部类的分类器权重范数大于尾部类,这使得线性分类器容易偏向优势类。为解决该问题,一些研究提出尺度不变的余弦分类器: p = φ ( ( w ⊤ f ∣ ∣ w ∣ ∣ ∣ ∣ f ∣ ∣ ) / τ + b ) p = φ((\frac{w^\top f}{||w|| ||f||})/τ + b) p=φ((∣∣w∣∣∣∣f∣∣w⊤f)/τ+b),其中分类器权重和样本特征均被归一化。其中 τ τ τ 是程度系数,应合理选择,否则会对分类器性能产生不利影响。
(1) Decoupling
Decoupling中提出了
τ
−
τ-
τ−normalized分类器3.1.1.1 & 3.3.1.4 & 3.3.2 &3.3.3 Paper解读通过
τ
−
τ-
τ−normalized过程调整分类器权重规范来纠正决策边界的不平衡。形式上,使得
w
~
=
w
∣
∣
w
∣
∣
2
τ
\tilde w = \frac{w}{||w||^τ_2}
w~=∣∣w∣∣2τw,其中
τ
τ
τ 为normalized的程度因子。当
τ
=
1
τ = 1
τ=1 时,
τ
−
τ-
τ−normalized简化为L2 normalized,而当
τ
=
0
τ = 0
τ=0 时,没有缩放。请注意,超参数
τ
τ
τ 也可以用类平衡采样进行训练,得到的分类器被命名为 the learnable weight scaling classifier 可学习权重缩放分类器。此外, the nearest class mean classifier 最近类平均分类器 对训练集中的每个类计算L2 normalized的平均特征,然后使用余弦相似度或者欧氏距离基于最近邻算法进行预测。
decoupling将分类网络分解为representation learning 和 classification
(2) RTC
Realistic taxonomic classifier RTC 现实分类器 Paper提出用层次分类来解决类的不平衡。具体来说,RTC将图像映射到类分类树结构中,其中的层次结构由一组分类节点和节点关系定义。不同的样本在不同的层次上进行自适应分类,其中预测的层次取决于样本的分类难度和分类器置信度。这样的设计有利于在中间层次上做出正确的决策,而不是在叶层上做出错误的决策。
(3) De-confound-TDE
De-confound-TDE 动量因果效应3.1.3 & 3.3.2 Paper解读提出了因果分类器,在长尾学习中通过因果推理来保留好的动量,去除坏的动量因果效应。良好的因果效应表明了稳定梯度和加速训练的有利因素,而不良的因果效应表明了累积的长尾偏差导致了较差的尾类表现。为了更好地近似偏差信息,因果分类器应用多头策略将模型权重和数据特征的通道(或维度)平均划分为
K
K
K组。形式上,因果分类器通过
p
=
φ
(
τ
K
∑
k
=
1
K
(
w
k
)
⊤
f
k
(
∣
∣
w
k
∣
∣
+
γ
)
∣
∣
f
k
∣
∣
)
p = φ(\fracτK\sum^K _{k =1} \frac{(w^k)^\top f^k}{ (||w^k||+γ)||f^k||})
p=φ(Kτ∑k=1K(∣∣wk∣∣+γ)∣∣fk∣∣(wk)⊤fk)计算原始logits,其中
τ
τ
τ 是程度,
γ
γ
γ是超参数。当
γ
=
0
γ = 0
γ=0时,这个分类器本质上是余弦分类器。在推理中,因果分类器通过减去输入为空时的预测来去除坏的因果效应,即
p
=
φ
(
τ
K
∑
k
=
1
K
(
w
k
)
⊤
f
k
(
∣
∣
w
k
∣
∣
+
γ
)
∣
∣
f
k
∣
∣
)
−
−
α
c
o
s
(
x
k
,
d
^
k
)
(
w
k
)
⊤
d
^
k
∣
∣
w
k
∣
∣
+
γ
)
p = φ(\fracτK\sum^K _{k =1} \frac{(w^k)^\top f^k}{ (||w^k||+γ)||f^k||})-−α\frac{cos(x^k, \hat d^k)(w^k)^\top \hat d^k}{||w^k||+γ})
p=φ(Kτ∑k=1K(∣∣wk∣∣+γ)∣∣fk∣∣(wk)⊤fk)−−α∣∣wk∣∣+γcos(xk,d^k)(wk)⊤d^k),其中
d
d
d 是指数移动平均特征的单位向量,
α
α
α是控制直接和间接影响的权衡参数。更直观的是,分类器在训练过程中通过计算指数移动平均特征来记录偏差,然后在推理过程中通过从预测对数中减去偏差来去除坏的因果效应。
(4) GIST
a Geometric Structure Transfer Network GIST 几何结构转移网络3.1.1 & 3.3.2 Paper解读提出了GIST分类器,将头类的几何结构转移到尾类。具体来说,GIST分类器由特定于类的权重中心(用于编码类位置)和一组位移(用于编码类几何形状)组成。GIST分类器利用头部类别相对较大的位移来增强尾部类别的权重中心,能够在尾部类别上获得更好的性能。
3. Decoupled Training
解耦训练 解耦训练 解耦训练将学习过程解耦为表征学习和分类器训练两部分。
- decoupling representation and classifier
- decoupling feature embedding and classifier
(1) Decoupling
Decoupling 解耦3.1.1.1 & 3.3.1.4 & 3.3.2 &3.3.3 Paper解读是引入两阶段训练方案的开创性工作,该文第一阶段对表征学习的不同采样策略进行了实证评估,第二阶段通过固定训练好的特征提取器来评估不同的分类器训练方案。在分类器学习阶段,有四种方法,包括使用类平衡采样重新训练分类器、最近类别均值分类器、τ-normalized分类器和可学习的权重伸缩方案。主要结论有两方面:在不平衡任务中,实例平衡采样是表征学习的最佳策略;重新调整分类器可以带来显著地性能提升。
(2) KCL
随后,KCL k-positive对比学习3.3.1.1 & 3.3.3 Paper通解读解读2过经验观察到平衡的特征空间有利于长尾学习。因此,它创新了解耦训练方案,通过开发k-positive的对比损失来学习更类平衡和类判别的特征空间,从而获得更好的长尾学习性能。
(3) MiSLAS
MiSLAS3.2.2.2 & 3.3.1.4 & 3.3.3 Paper解读观察到,在两阶段解耦训练方案下,数据mixup有利于特征学习,但对分类器训练的影响为负/可忽略不计。因此,MiSLAS提出在第一阶段通过数据混合来加强表示学习。在第二阶段,MiSLAS应用标签感知平滑策略,以更好地实现模型泛化,并通过不断更新批处理归一化层中的运行均值和方差,进一步解决两个训练阶段之间的分布变化。
(4) OFA
最近的一些研究通过增强分类器训练阶段来创新解耦训练方案。Online feature augmentation OFA 在线特征增强3.2.1.1 $ 3.3.3 Paper解读创新了尾类特征增强的分类器再训练方法,将尾类提取的class-specific特征与头类提取的class-generic特征相结合。
(5) SimCal
Simple Calibration SimCal 简单校准3.1.1.1 & 3.3.3 & 3.3.4 Paper解读提出了一种用于长尾实例分割的新型双层类平衡抽样策略,通过校准分类头来增强分类器训练阶段。
(6) DisAlign
Distribution Alignment DisAlign 分布对齐3.1.2 & 3.1.3 & 3.3.3 Paper解读用一种新的自适应校准策略创新了分类器训练。具体来说,通过最小化校准预测分布和平衡参考分布之间的KL-Divergence来学习新的自适应校准函数,用于调整原始分类器的输出对数。综上所述,DisAlign本质上应用了一个额外的分类器层,通过将校准的预测分布匹配到一个相对平衡的类分布来校准原始分类器。
(7) DT2
最近,DT2Paper将解耦训练方案应用到场景图生成任务中,证明了解耦训练在处理视觉关系学习中的长尾类失衡方面的有效性。
4. Ensemble Learning
基于
集成学习
集成学习
集成学习的方法生成和组合多个网络模块 (即多个专家),以解决不平衡学习问题。图3总结了现有基于集成学习的主要方案。
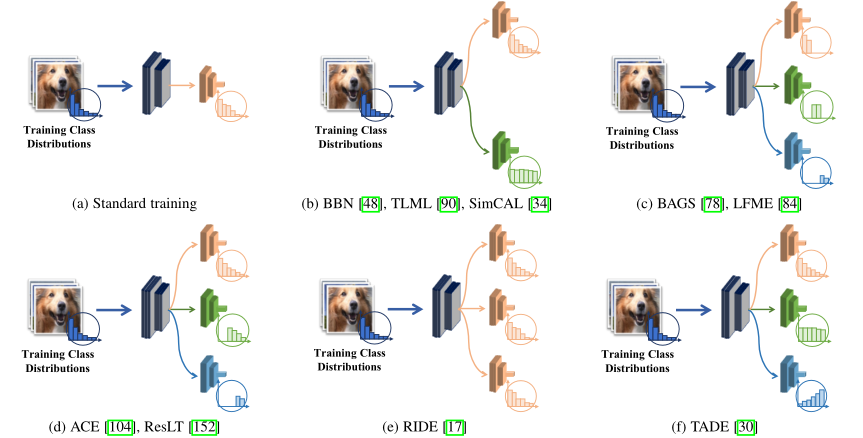
图3 现有的基于集成的长尾学习方法的插图。经过训练的专家可能具有不同的技能,例如,擅长于不同的类别分布或不同的类别子集。
(1) BBN
bilateral-branch network BBN 双边分支网络3.1.1.2 & 3.3.4Paper解读提出使用两个网络分支,即传统学习分支和再平衡分支来处理长尾识别。其中,传统的学习分支采用均匀抽样来模拟原始的长尾训练分布;再平衡分支应用反向采样器在每个小批中采样更多的尾级样本,以提高尾级性能。在训练过程中,将两个分支的预测动态结合,使BBN的学习重点从头部类逐渐转变为尾部类(通过重新平衡分支)。
(2) LTML
long-tailed multi-label visual recognition LTML 长尾多标签视觉识别3.1.1.2 & 3.3.4 Paper探索了解决长尾多标签分类的双边分支网络方案。具体来说,LTML使用sigmoid交叉熵损失对每个分支进行多标签分类训练,并强制使用logit一致性损失来提高两个分支的一致性。此外,LTML应用标签平滑和logit补偿来提高模型的泛化能力。
(3) SimCal
Simple Calibration SimCal 简单校准3.1.1.1 & 3.3.3 & 3.3.4 Paper解读(类似于BBN)探索了一种双分类头方案来解决长尾实例分割。具体来说,SimCal维护了两个分类头:原始分类头和校准的分类头。基于一种新的双级采样策略,校准后的分类头能够提高尾类的性能,而原始分类头旨在保持头类的性能。
(4) BAGS
balancing group softmax BAGS 平衡组softmax3.1.1.2 & 3.3.4 Paper解读探索了一种多头方案来解决长尾目标检测问题,而不是双侧分支。具体来说,BAGS从一个观察中获得了灵感,即学习一个样本更少的更均匀的分布有时比学习一个样本更多的长尾分布更容易。因此,BAGS首先将类划分为几个子组,每个子组中的类具有相似数量的训练数据。然后,BAGS在共享特征提取器上应用多个分类头进行预测,其中不同的分类头在不同的数据子组上进行训练。这样,每个分类头对训练数据数量相似的类进行softmax操作,从而避免了类不平衡的负面影响。此外,BAGS还在每个分组中引入了“其他”类,以缓解不同头部类之间的矛盾。
(5) LFME
LFME 多专家学习3.2.1.3 & 3.3.4 Paper解读(与BAGS类似)将长尾数据集划分为几个“类长尾性”更小的子集,用不同的样本子集训练多个专家。在这些专家的基础上,LFME通过自适应知识蒸馏从多个教师专家中学习统一的学生模型。
(6) ACE
ally complementary experts ACE 盟友互补专家3.1.1.2 & 3.3.4 Paper解读没有将类划分为几个平衡的子组,而是将类划分为几个技能不同的子集:一个子集包含所有类;一种包含中间类和尾部类;另一个只有尾部类。ACE然后用不同类的子集训练多个专家,使不同的专家具有特定的和互补的技能。此外,考虑到各个子集有不同的样本数,ACE还应用了分布式自适应优化器来调整不同专家的学习率。
(7) ResLT
ResLT Paper解读也进行了类似ACE思想的探索。
(8) RIDE
RIDE 路由多样化分布感知专家3.2.1.3 & 3.3.4 Paper解读在没有数据分割的情况下,基于所有训练样本,使用softmax损失对每个专家进行独立训练,并实施基于KL-divergence的损失,以提高不同专家的多样性。在此基础上,RIDE应用了专家分配模块来提高计算效率。请注意,用softmax损失单独训练每个专家可以大大提高长尾学习的整体性能。
(9) TADE
Test-time aggregating diverse experts TADE 测试时间聚合不同专家Paper解读探索了多专家方案来处理测试分布不可知的长尾识别,其中测试类分布可以是均匀的,也可以是长尾的。具体而言,TADE开发了一种新的跨谱多专家框架,并通过引入多样性促进专家指导损失来创新专家培训方案训练不同的专家处理不同的类别分布。通过这种方式,学习的专家更加多样化,导致更好的集成性能,并集成跨越可能的类分布的广泛范围。基于这一特性,TADE进一步引入了一种新的测试时间自监督学习方法,即预测稳定性最大化,仅基于未标记的测试数据,自适应聚集专家,以更好地处理未知测试类分布。
5. Discussions
表征学习和分类器设计是深度不平衡学习的基本问题,值得进一步探索。近年来,解耦训练越来越受到研究者的关注,类平衡分类器学习的第二阶段不会引入太多的计算开销,却会带来显著的性能提升。不过,累积的训练阶段使解耦训练不太实用,无法与其他不平衡问题 (如目标检测和实例分割)中现有的公式化方法集成。尽管如此,解耦训练思想简单,可以很容易地用于设计解决各种不平衡学习问题的新方法。
相比于其他类型的不平衡学习方法,基于集成学习的方法通常在头部类和尾部类上都能获得更好的性能。然而,由于集成学习方法使用多个专家,通常会导致更高的计算成本,通常可以使用共享特征提取器来缓解该问题。此外,面向效率的专家分配和知识蒸馏(3.2.1.3)策略也可以降低计算复杂度。
![容器中的operator[]注意事项](https://img-blog.csdnimg.cn/1006e338c1e04e7ca158ae4d998d1f4c.png#pic_center)












![[Android Studio Tool]在Android Studio项目中如何使用CSV文件](https://img-blog.csdnimg.cn/886a90589e7847ddae750a2b3b5879cf.png)