深度学习自然语言处理 原创
作者:林哲乐
论文:Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes
地址:https://arxiv.org/pdf/2305.02301.pdf
录取:ACL2023进NLP群—>加入NLP交流群
个人解读
为优化LLM为“小模型/少数据/好效果”,提供了一种新思路:”一步步蒸馏”(Distilling step-by-step)
具体做法:训练出一个更小的模型,同时输出推理过程和标签
总结
大模型部署耗费内存/算力,训练特定任务的小模型采用:
微调(BERT、T5)
蒸馏(Vicuna)
但仍需要大量数据
本文提出”一步步蒸馏”(Distilling step-by-step)机制:
模型更小
数据更少
实验证明效果更佳(770M的T5,效果优于540B的PaLM)
引言
1. LLM的作用
以LLM作为粗标注,同时标注时会给出推理过程,如“思维链”CoT
e.g.:
“A gentleman is carrying equipment for golf, what does he likely have?
(a)club, (b) assembly hall, (c) meditation center, (d)meeting, (e) church”
答案是(a),在上述选择中,只有球杆用于高尔夫球。
上述逻辑会用于多任务训练的额外数据
2. 任务准确性&所需训练数据
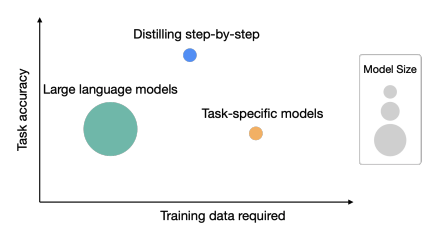
相关工作
1. 知识蒸馏
从大的“老师模型”蒸馏出“学生模型”,缺点是“老师模型”产生的数据有噪声
本文做法:蒸馏标签、老师模型的推理过程,以降低对无标签数据的需求量
2. 人类推理过程
规范模型行为
作为额外的模型输入
作为高质量标签
缺点:代价高昂
3. 大模型推理过程
可用于产生高质量的推理步骤,作为提示输入到大模型
作为微调数据,进行“self-improve”大模型
一步步蒸馏
概览图: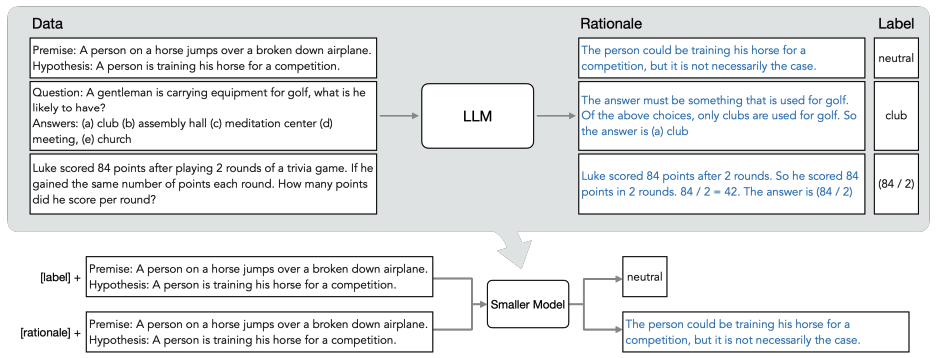
分为两步:
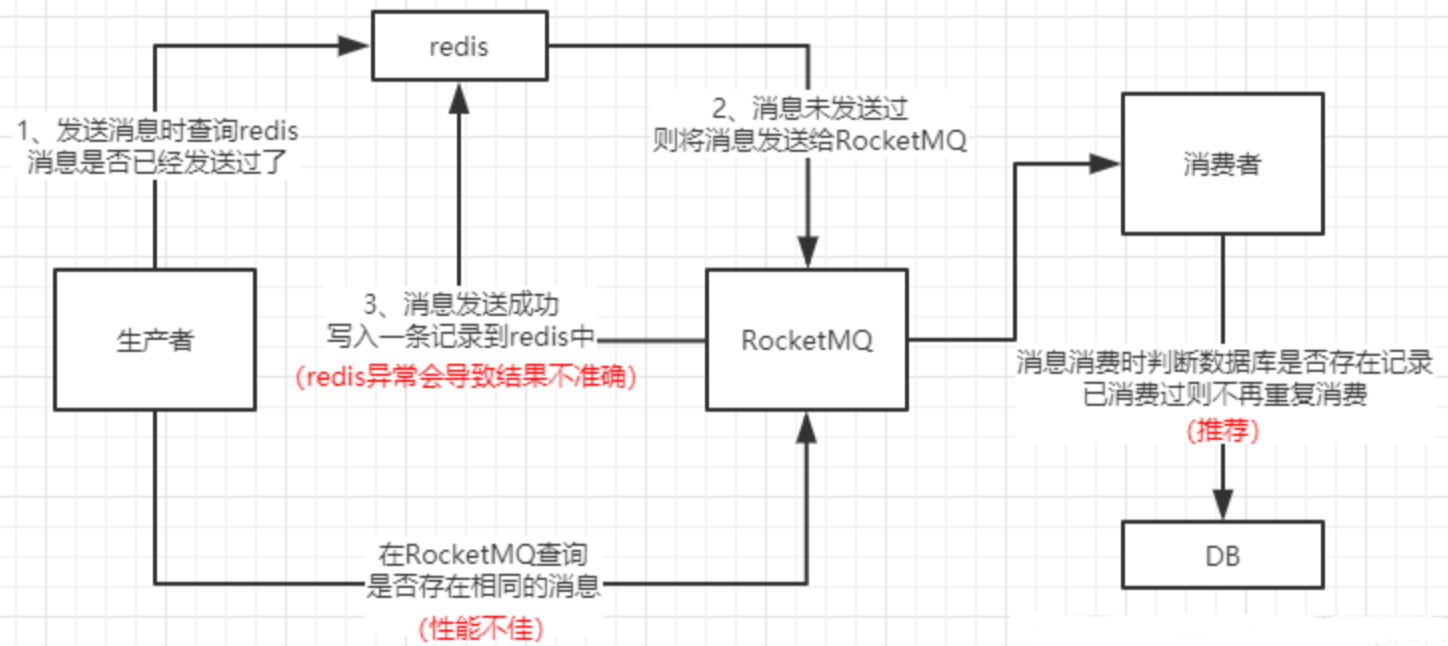
已有LLM和无标签数据,利用推理过程,输出标签
以推理过程作为额外数据(细节信息较多),训练更小的模型
基于这样一个特性:LLM产生的推理过程能够用于它自身的预测
假设prompt是个三元组,其中是输入,是标签,是推理过程
数据集记作,x是输入,y是标签,且二者都是自然语言
这个文本到文本的框架包括的自然语言处理任务有:分类、自然语言推理、问答等等
常见的做法:用监督数据微调预训练模型。
缺少人工标签,特定任务的蒸馏是用LLM教师模型生成伪噪声训练标签,代替
待降低交叉熵损失:
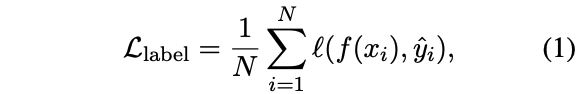
其中\hat{y_i}$是模型蒸馏得到的标签
将推理过程\hat{r_i}$融入训练过程的方式:
放到input后面,一同输入到模型,此时的损失计算:
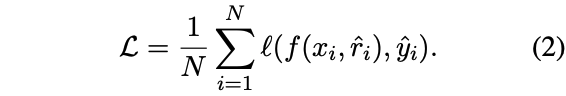
需要先用LLM产生推理过程,此时LLM是必要条件
(本文)转化为多任务学习问题,训练模型:
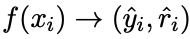
同时产生标签、推理过程
采用后者的方式,此时的损失计算为: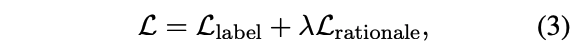
其中,推理过程生成的损失为: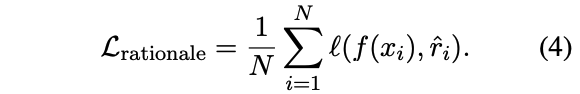
推理过程生成是预测之前的中间一步,而不是测试过程中产生的(如同公式2),所以测试时不再需要LLM,这就是所谓的"一步步蒸馏"。
另外,预先定义任务前缀,如[label]是标签,[rationale]是推理过程
实验
从两方面证明“一步步蒸馏”的有效性:
与传统的微调和蒸馏对比,效果有所提升
模型更小、部署代价更小
以最小的模型规模、数据量作为标准,“一步步蒸馏”的模型优于LLM
基准模型
LLM:540B的PaLM
下游模型:T5
T5-Base (220M)
T5-Large (770M)
T5-XXL (11B)
数据集
e-SNLI (自然语言推理):https://github.com/OanaMariaCamburu/e-SNLI
ANLI(自然语言推理):https://huggingface.co/datasets/anli
CQA(问答):https://www.tau-nlp.sites.tau.ac.il/commonsenseqa
SVAMP(算术数学词问题):https://github.com/arkilpatel/SVAMP
与一步步蒸馏对比的其他方法
标准的微调(有标签)
标准的任务蒸馏(无标签)
减少训练数据
对比结果1
在标签较少时,一步步蒸馏优于标准微调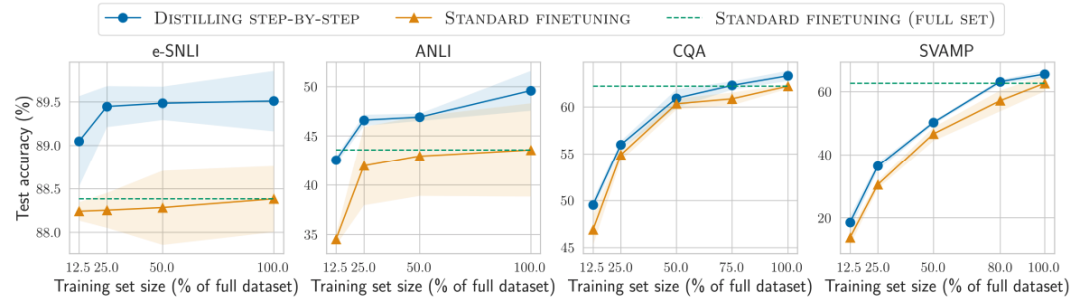
对比结果2
在标签较少时,一步步蒸馏优于标准蒸馏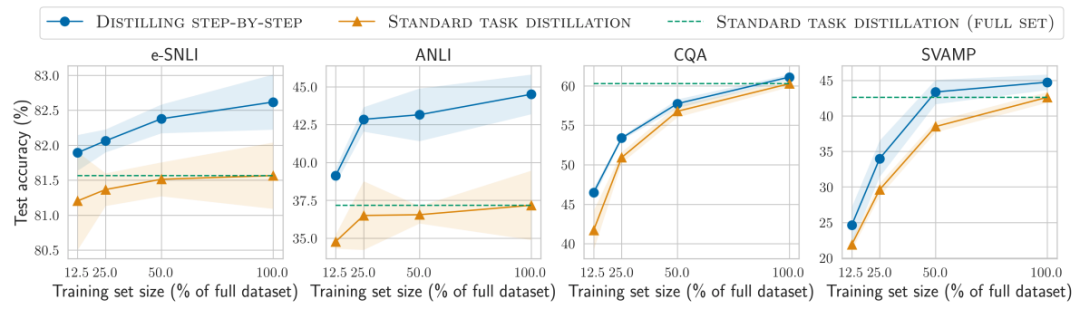
降低模型大小
各种baseline模型大小不一时,一步步蒸馏都更优
通过使用更小的特定任务模型一步步蒸馏逐步优于LLM
对比结果3
在所有考虑的4个数据集上总是可以优于少样本CoT、PINTO调优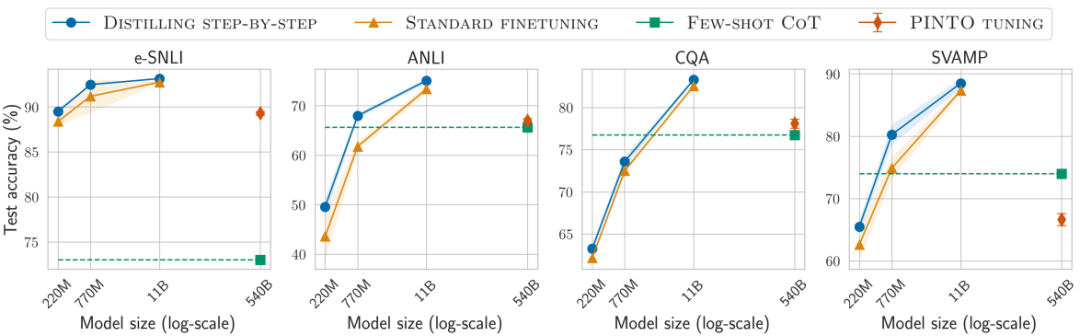
对比结果4
在4个数据集中的3个上也优于教师模型LLM
增强无标签数据,可进一步改进一步步蒸馏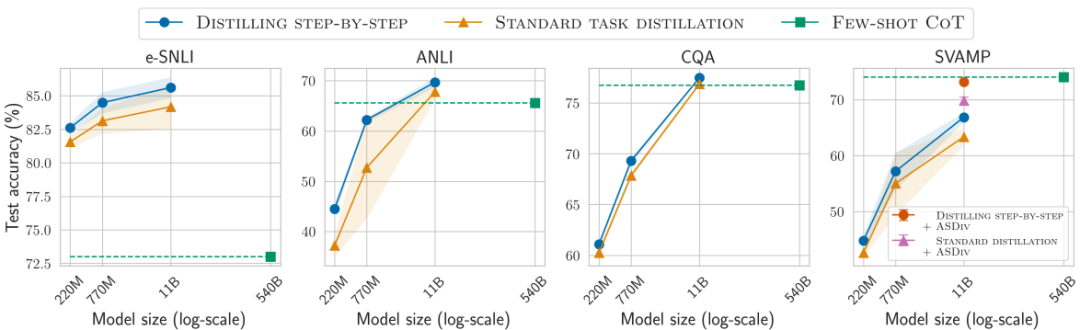
使用最小模型大小和最小训练数据
对比结果5
用更小模型、更少数据,一步步蒸馏优于LLM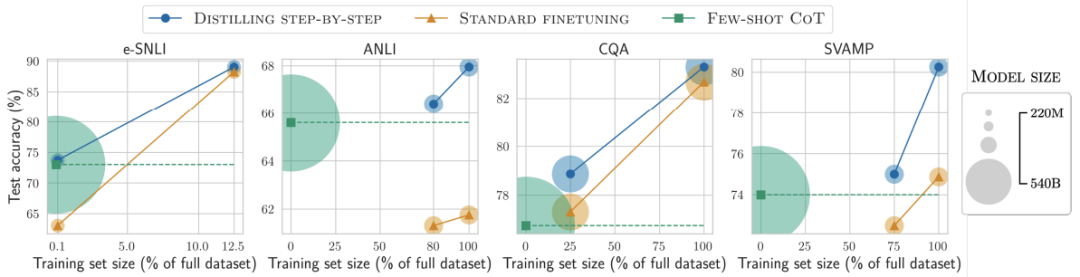
对比结果6
标准的微调和蒸馏需要更多的数据和更大的模型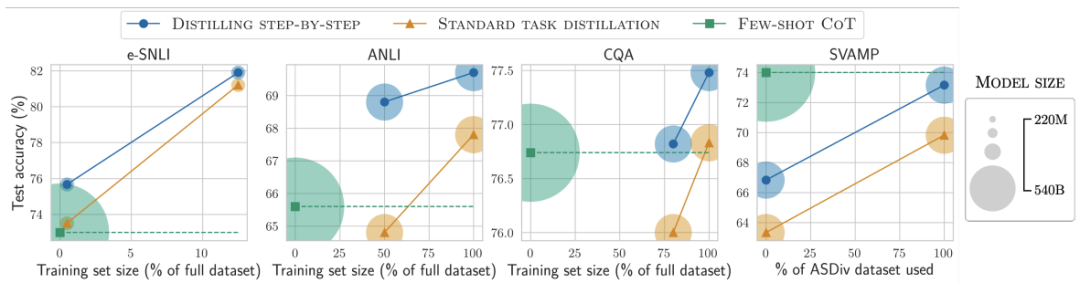
总结
实验证明,一步步蒸馏降低了训练数据量、特定任务的模型大小、优于初始LLM的性能
局限性:
用户需要提供带标签数据
LLM推理能力有限,尤其面对复杂推理和规划问题
进NLP群—>加入NLP交流群