需求:
搭建一个新的从库,只复制过滤源端数据库里的其中一个数据库workflow到新实例上。
一 操作步骤
1.1 在目标端新建一个数据库实例
略
1.2 在源端做备份
/home/urman-agent/bin/xtrabackup --defaults-file=/data/mysql/etc/13314/my.cnf --target-dir=workflow_bak_0514 --user=root --password=密码 --socket=/data/mysql/data/13314/mysqld.sock --databases=workflow --backup
1.3 将备份文件拷贝到目标端
scp -r workflow_bak_0514 目标端ip:/data/mysql/data/13320_temp/
1.4 恢复
1.4.1 prepare
#在目标端进行prepare,应用redo log
/home/urman-agent/bin/xtrabackup --prepare --export --target-dir=/data/mysql/data/13320_temp/workflow_bak_0514
1.4.2 生成cfg文件
/home/urman-agent/bin/xtrabackup --export --target-dir=/data/mysql/data/13320_temp/workflow_bak_0514
这样就在workflow目录下看到有cfg文件。
1.4.3 远程备份源端库表结构(空表)
mysqldump -h 源端数据库ip -P 源端ip -u root -p --single-transaction --databases workflow --set-gtid-purged=off -d > /opt/233_13314_kb.bak
1.4.4 在目标端导入空表
mysql -u root -p < /opt/233_13314_kb.bak
1.4.5 丢弃表空间
#生成sql
select concat('alter table ',table_name,' discard tablespace;') from information_schema.`TABLES` where table_schema='workflow'
#执行生成的sql
1.4.6 将备份文件里的ibd文件,cfg文件拷贝到目标端数据库目录下
[root@mysql-235 workflow]# pwd
/data/mysql/data/13320_temp/workflow_bak_0514/workflow
cp *.cfg /data/mysql/data/13316/workflow/
cp *.ibd /data/mysql/data/13316/workflow/
1.4.7 改文件属主
cd /data/mysql/data/13316/workflow
ls -ltr 看下现有文件的属主,将刚拷贝过来的cfg,ibd等文件也改成一样的属主,比如,这里是:
chown -R actiontech-mysql:mysql *
1.4.8 导入表空间
#生成sql
select concat('alter table ',table_name,' import tablespace;') from information_schema.`TABLES` where table_schema='workflow'
#执行生成的sql
1.5 配置主从复制
1.5.1 加过滤参数
#修改从库的配置文件
vi my.cnf
添加:
replicate_wild_do_table=workflow.%
#重启从库,使参数生效,示例:
systemctl stop mysqld_13316
systemctl start mysqld_13316
1.5.2 配置主从复制
1.5.2.1 set gtid_purged
获取备份文件里的xtrabackup_binlog_info
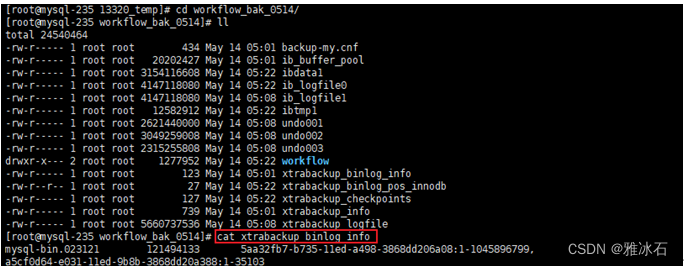
reset master;
set global gtid_purged='上面获取的位置';
1.5.2.2 change master
change master to master_host='主库ip',master_port=主库端口,master_user='universe_op',master_password='密码',master_auto_position=1;
start slave;
show slave status ;
1.5.3 手动同步函数,存储过程,触发器,事件等
手动同步下,最好是割接那天再手动同步