LeetCode_链表
- 203.移除链表元素
- 1. 题目描述
- 2. 直接使用原表删除
- 1. 思路
- 2. 代码实现
- 3. 使用虚拟头节点删除
- 1. 思路
- 2. 代码实现
- 707.设计链表
- 1.题目描述
- 2.单链表:虚拟头节点设计
- 1. 思路
- 2. 代码实现及部分逻辑解释
- 3. 需要注意的点
- 206.反转链表
- 1.题目描述
- 2. 双指针法
- 1.思路
- 2. 代码实现
- 3.递归法
- 1.思路
- 2.代码实现
203.移除链表元素
1. 题目描述
给你一个链表的头节点 head 和一个整数 val ,请你删除链表中所有满足 Node.val == val 的节点,并返回 新的头节点 。
示例:
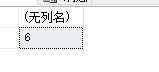
 输入:head = [1,2,6,3,4,5,6], val = 6
输入:head = [1,2,6,3,4,5,6], val = 6
输出:[1,2,3,4,5]
输入:head = [], val = 1
输出:[]
输入:head = [7,7,7,7], val = 7
输出:[]
LeetCode题详情链接: https://leetcode.cn/problems/remove-linked-list-elements/
2. 直接使用原表删除
1. 思路
链表删除元素:是将当前元素的前一个元素指向当前元素的后一个元素(即删除了当前元素节点);
需要注意的是直接在原表上删除需要特殊考虑头节点的删除。
移除头结点和移除其他节点的操作是不一样的,因为链表的其他节点都是通过前一个节点来移除当前节点,而头结点没有前一个节点。
头节点的移除: 将头结点向后移动一位,即就是从链表中移除了一个头结点。
2. 代码实现
/**
*思路:不添加虚拟头节点的原链表删除法
* 头节点需要另外考虑:如果头节点等于target,那么设置头节点的下个节点为头节点(即删除等于target的值)(比如类似这种head=[1,1,1,1],使用while)。
* 因为单链表的特性只有指向下个节点的指针,所以设置需要删除元素的位置需要处于中间。
*时间复杂度:O(n)
*空间复杂度:O(1)
*/
public ListNode removeElements(ListNode head, int val) {
while (head != null && head.val == val){
head = head.next;
}
ListNode cur = head;
while (cur != null && cur.next != null){
if (cur.next.val == val){
cur.next = cur.next.next;
}else{
cur = cur.next;
}
}
return head;
}
3. 使用虚拟头节点删除
1. 思路
如果不特殊考虑头节点的删除的话,链表的其他节点删除都是将当前元素的前一个元素指向当前元素的后一个元素(即删除了当前元素节点);
所以给头节点的前边添加一个虚拟的头节点,那么头节点就和其他节点一样操作对比删除了。
简单图解如下(删除head节点时):

2. 代码实现
/**
*思路:添加虚拟头节点的删除法
* 因为头节点需要额外考虑,所以给头节点的前边添加一个虚拟的头节点,那么头节点就和其他节点一样操作对比删除了。
* 因为单链表的特性只有指向下个节点的指针,所以设置需要删除元素的位置需要处于中间。
*时间复杂度:O(n)
*空间复杂度:O(1)
*/
public ListNode removeElements(ListNode head, int val) {
if (head == null){
return head;
}
ListNode dummy = new ListNode(-1,head);//虚拟头节点
ListNode cur = dummy;
while (cur.next != null){
if (cur.next.val == val){
cur.next = cur.next.next;
}else {
cur = cur.next;
}
}
return dummy.next;
}
707.设计链表
1.题目描述
在链表类中实现这些功能:
- get(index):获取链表中第 index 个节点的值。如果索引无效,则返回-1。
- addAtHead(val):在链表的第一个元素之前添加一个值为 val 的节点。插入后,新节点将成为链表的第一个节点。
- addAtTail(val):将值为 val 的节点追加到链表的最后一个元素。
- addAtIndex(index,val):在链表中的第 index 个节点之前添加值为 val 的节点。如果 index
等于链表的长度,则该节点将附加到链表的末尾。如果 index 大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。 - deleteAtIndex(index):如果索引 index 有效,则删除链表中的第 index 个节点。
示例:

LeetCode题详情链接: https://leetcode.cn/problems/design-linked-list/
2.单链表:虚拟头节点设计
1. 思路
使用虚拟头节点而不是直接操作头节点,可以对head头节点的处理如同链表中其他元素处理的逻辑一样(比如插入时)。
2. 代码实现及部分逻辑解释
//单链表
class ListNode {
int val;
ListNode next;
ListNode(){}
public ListNode (int val){
this.val = val;
}
}
/**
*使用虚拟头节点可以对head头节点的处理如同链表中其他元素处理的逻辑一样。
*
*/
class MyLinkedList {
int size; //size存储链表元素的个数
ListNode head; //虚拟头节点
/**
*初始化链表
*/
public MyLinkedList() {
size = 0;
head = new ListNode(0);
}
/**
* 获取第index个节点的数值,注意index是从0开始的,第0个节点就是头结点
*/
public int get(int index) {
//如果index非法,返回-1
if (index < 0 || index >= size){
return -1;
}
ListNode currentNode = head;
for (int i = 0; i <= index; i++){
//包含一个虚拟头节点,所以查找第 index+1 个节点
currentNode = currentNode.next;
}
return currentNode.val;
}
/**
* 在链表最前面插入一个节点,等价于在第0个元素前添加
*/
public void addAtHead(int val) {
addAtIndex(0,val);
}
/**
* 在链表的最后插入一个节点,等价于在(末尾+1)个元素前添加
*/
public void addAtTail(int val) {
addAtIndex(size,val);
}
/**
* 如果 index 大于链表的长度,则返回空,该节点将 不会插入 到链表中
* 如果 index 等于链表的长度,则说明是新插入的节点为链表的尾结点
* 在第 index 个节点之前插入一个新节点,例如index为0,那么新插入的节点为链表的新头节点。
*/
public void addAtIndex(int index, int val) {
if (index > size){
return;
}
if (index < 0){
index = 0;
}
size++;
//找到要插入节点的前驱
ListNode pre = head;
for (int i = 0; i < index; i++){
pre = pre.next;
}
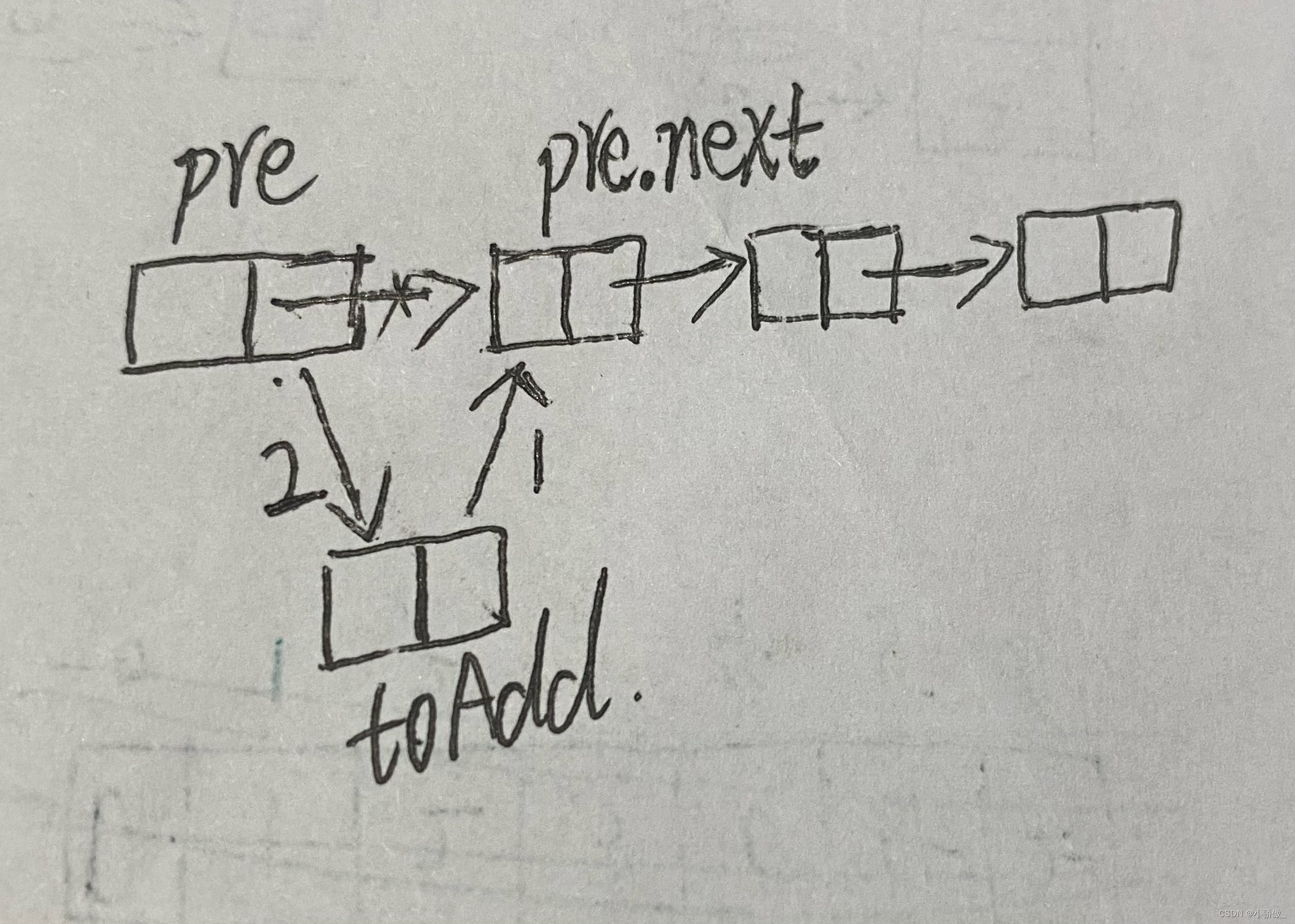
ListNode toAdd = new ListNode(val);
//这里注意插入顺序:需先赋值toAdd.next = pred.next;
//若先赋值pre.next = toAdd,则插入前的pre.next节点(即原index位置上的节点无法表示)
toAdd.next = pre.next;
pre.next = toAdd;
}
/**
* 删除第index个节点
*/
public void deleteAtIndex(int index) {
//如果index非法,返回-1
if (index < 0 || index >= size){
return;
}
size--;
//删除头节点
if (index == 0){
head = head.next;
return;
}
//找到要删除位置的前驱节点
ListNode pre = head;
for (int i = 0; i < index; i++){
pre = pre.next;
}
//删除index位置上的节点
pre.next = pre.next.next;
}
}
3. 需要注意的点
-
addAtIndex(index,val)方法插入时,需要注意插入时的赋值顺序:需先赋值toAdd.next = pred.next;
若先赋值pre.next = toAdd,则插入前的pre.next节点(即原index位置上的节点无法表示)
简单理解如图:
206.反转链表
1.题目描述
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例:
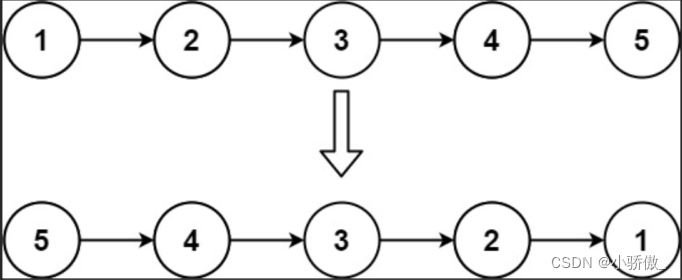
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]
输入:head = []
输出:[]
LeetCode题详情链接: https://leetcode.cn/problems/reverse-linked-list/
2. 双指针法
1.思路
观察题目发现,链表反转后即全部指针指向相反方向,原头节点指向null
所以只需要改变链表的next指针的指向,直接将链表反转,也不需要重新定义一个新的链表,那样反而是对内存空间的浪费。
- 定义两个指针: cur指针指向头结点,再定义一个pre指针,初始化为null。
- 然后开始反转: 反转头节点是将cur->next 指向pre;这里需要注意,因为此时已经改变了cur.next的指向了,所以反转时需要把cur.next保存为临时节点temp。
- 接着不断向前移动pre和cur指针的位置,继续反转,直至cur指向null时,反转结束。
- 需要注意移动指针时,需先移动pre,后移动cur; 因为若先移动cur的话,cur的位置就被修改了,pre移动时找不到原cur的位置了
- 当**cur==null(遍历的边界条件)**时,即为遍历结束。最后返回pre,因为遍历到最后,pre指向反转后链表的头节点,cur指向null。
简单图解如下:
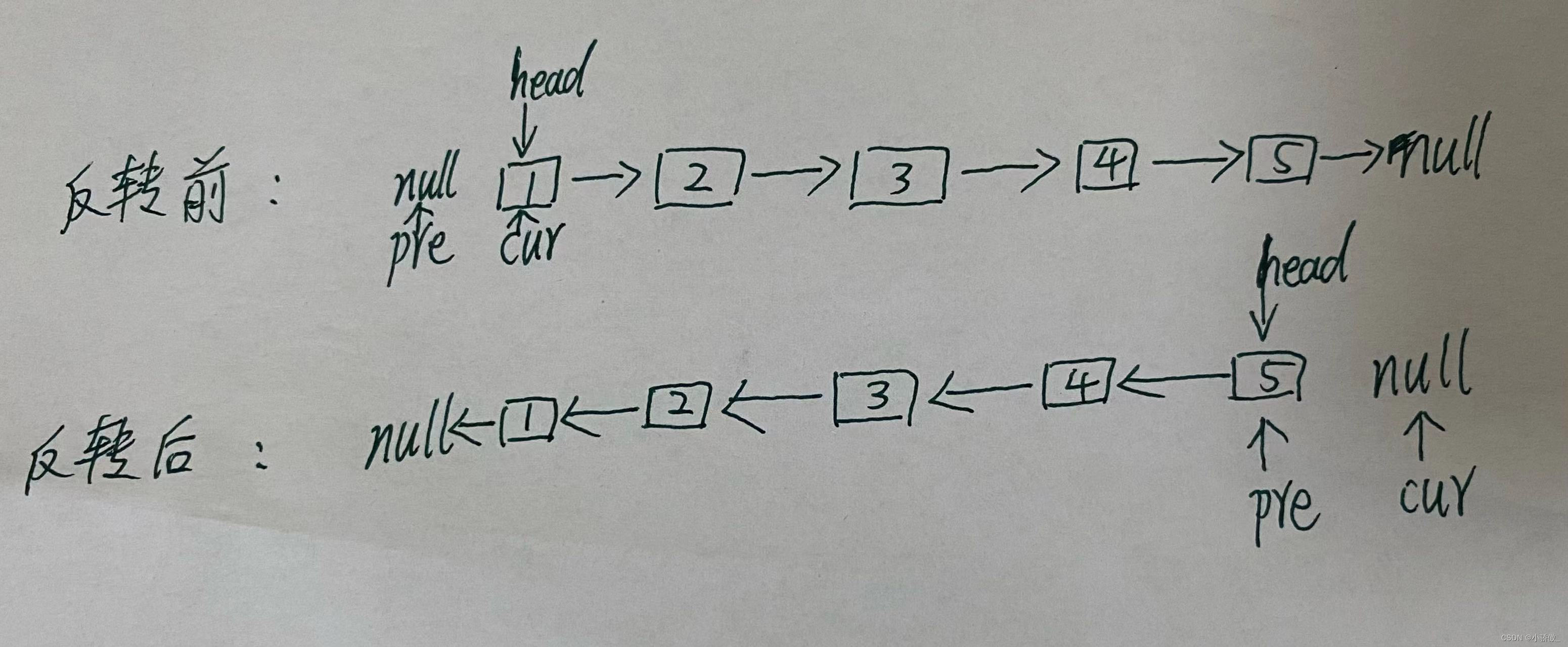
2. 代码实现
/**
* 思路:双指针法
* 观察发现反转链表后头节点指向null,剩余节点的指针指向全都相反
* 所以定义两个指针:cur指针指向头结点,再定义一个pre指针,初始化为null。
* 然后开始反转:反转头节点是将cur->next 指向pre;这里需要注意,
* 因为此时已经改变了cur.next的指向了,所以反转时需要把cur.next保存为临时节点temp。
* 然后就是不断向前移动pre和cur指针的位置,继续反转,直至cur指向null时,反转结束。
* 需要注意移动指针时,需先移动pre,后移动cur;因为若先移动cur的话,cur的位置就被修改了,pre移动时找不到原cur的位置了
* 时间复杂度:O(n),其中 n 是链表的长度,需要遍历链表一次。
* 空间复杂度:O(1)
*/
public ListNode reverseList(ListNode head) {
ListNode pre = null;
ListNode cur = head;
ListNode temp = null;
while (cur != null){
temp = cur.next;//保存cur的下一个节点
cur.next = pre; //反转操作
pre = cur; //pre移动
cur = temp;//cur移动
}
return pre;//遍历到最后,pre指向反转后链表的头节点,cur指向null
}
3.递归法
1.思路
实际递归就是将上述双指针法的共有逻辑进行了提取。所以尝试递归法之前一定要理解上述双指针法。
根据双指针的思路进行递归转换,以下为双指针思路:
- 观察发现反转链表后头节点指向null,剩余节点的指针指向全都相反
- 所以定义两个指针:cur指针指向头结点,再定义一个pre指针,初始化为null。
- 然后开始反转:反转头节点是将cur->next 指向pre;这里需要注意,
- 因为此时已经改变了cur.next的指向了,所以反转时需要把cur.next保存为临时节点temp。
- 然后就是不断向前移动pre和cur指针的位置,继续反转,直至cur指向null时,反转结束。
- 需要注意移动指针时,需先移动pre,后移动cur;因为若先移动cur的话,cur的位置就被修改了,pre移动时找不到原cur的位置了
递归时将共有处理逻辑(即转换)提出,每次更新pre和cur的位置相当于要进行下一个反转,此时再递归调用共有逻辑。
递归的出口和双指针的循环结束条件一样,即当cur==null时,调用结束。
2.代码实现
/**
* 思路:递归法
* 根据双指针的思路进行递归转换,以下为双指针思路:
* (观察发现反转链表后头节点指向null,剩余节点的指针指向全都相反
* 所以定义两个指针:cur指针指向头结点,再定义一个pre指针,初始化为null。
* 然后开始反转:反转头节点是将cur->next 指向pre;这里需要注意,
* 因为此时已经改变了cur.next的指向了,所以反转时需要把cur.next保存为临时节点temp。
* 然后就是不断向前移动pre和cur指针的位置,继续反转,直至cur指向null时,反转结束。
* 需要注意移动指针时,需先移动pre,后移动cur;因为若先移动cur的话,cur的位置就被修改了,pre移动时找不到原cur的位置了)
*
* 递归时将共有处理逻辑(即转换)提出,每次更新pre和cur的位置相当于要进行下一个反转,此时再递归调用共有逻辑。
* 递归的出口和双指针的循环结束条件一样,即当cur==null时,调用结束。
* 时间复杂度:O(n),其中 n 是链表的长度,需要遍历链表一次。
* 空间复杂度:O(n),其中 n 是链表的长度。空间复杂度主要取决于递归调用的栈空间,最多为 n 层。
*/
public ListNode reverseList(ListNode head) {
return reverse(null,head);//相当于双指针的初始化,pre=null,cur=head
}
private ListNode reverse(ListNode prev, ListNode cur) {
if (cur == null){
return prev;
}
ListNode temp = cur.next; //保存下一个节点
cur.next = prev;// 反转
return reverse(cur, temp);//相当于双指针中更新了pre和cur的位置再进行下一个的反转
}