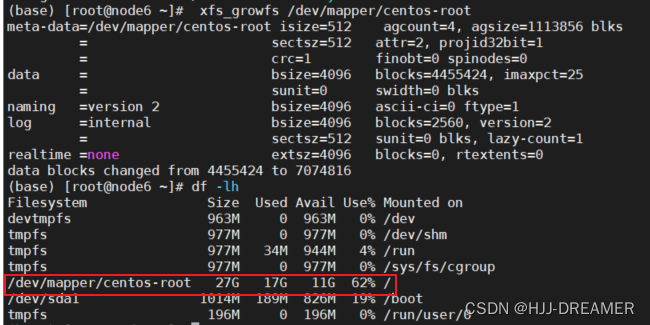
数据编码是将数据转换为计算机可读取和处理的二进制格式的过程。在数据存储中,正确的数据编码非常重要,因为它能够保证数据的完整性、可靠性和可读性。
- 数据编码可以确保数据在存储过程中不会发生错误。通过使用适当的数据编码规则,可以防止数据被意外地篡改或损坏,从而确保数据的完整性和可靠性。
- 数据编码可以节省存储空间。通过使用更紧凑的编码格式,可以将数据占用的存储空间降到最小,从而节省存储空间和存储成本。
- 数据编码也能够提高数据的可读性和可维护性。通过使用易于理解和维护的编码格式,可以使数据更易于被人类读取和理解,并且在需要修改数据时,也更容易进行维护。
- 在内存中,数据保存在对象,结构体,列表,数组,哈希表,树等中。 这些数据结构针对CPU的高效访问和操作进行了优化(通常使用指针)。
- 如果要将数据写入文件,或通过网络发送,则必须将其编码(encode)为某种自包含的字节序列(例如,JSON文档)。 由于每个进程都有自己独立的地址空间,一个进程中的指针对任何其他进程都没有意义,所以这个字节序列表示会与通常在内存中使用的数据结构完全不同。从内存中表示到字节序列的转换称为编码、序列化;反过来称为解码、反序列化
如果我们要设计一个数据编码格式,我们需要考虑哪些方面的问题呢?
1、对于数据类型与数据结构的支持。需要确定自己的数据编码格式支持哪些数据类型,并且要能够正确地将数据类型转换为二进制格式,编码格式支持哪些数据结构,例如数组、列表等。这个是基础
2、数据紧凑性与解码效率。这个就涉及到数据编码算法了,考虑如何使用尽可能少的字节来编码数据,从而节省存储空间和传输带宽。越复杂的算法会节省越多的存储空间,但解码需要的时间也越长,所以鱼和熊掌不可兼得
3、易用性和可读性。需要考虑如何使编码格式易于使用和理解,以及如何使编码后的数据易于被人类读取和理解。但通常来说,强大的可读性,意味着对于数据紧凑性的牺牲,比如JSON
4、双向兼容性。向后兼容:新代码可以读旧数据。向前兼容:旧代码可以读新数据。向后兼容性通常并不难实现:新代码当然知道由旧代码使用的数据格式,因此可以显示地处理它;向前兼容性可能会更棘手,因为旧版的程序需要忽略新版数据格式中新增的部分。
语言特定的格式
不同的编程语言本身具有其特有的编码格式,比如Java的java.io.Serializable、Kryo,Ruby有 Marshal,Python有 pickle等。这些编码格式与编程语言深度绑定的同时,也带来了一些问题:
- 与特定的编程语言深度绑定,其他语言很难读取这种数据。
- 安全问题:如果攻击者可以让应用程序解码任意的字节序列,他们就能实例化任意的类,这会导致一些安全隐患,如远程执行任意代码
- 前向后向兼容性问题
- 效率问题
所以除非临时使用,采用语言特定的内置编码格式缺乏扩展性,一般尽量减少去使用,特别是对外开放的接口服务
JSON,XML和CSV
JSON,XML是总所周知的可以被很多编程语言编写与读取的标准化编码格式,JSON,XML和CSV是文本格式,因此具有可读性,但对应的也有各自的问题,比如XML太冗长复杂(复杂的嵌套关系);CSV能够支持的功能太弱。除此之外,还有一些其他问题:
- 数字的编码多有歧义之处。XML和CSV不能区分数字和字符串(除非引用外部模式)。JSON虽然区分字符串和数字,但不区分整数和浮点数,而且不能指定精度。
- 大数据精度丢失
- JSON和XML对Unicode字符串(即人类可读的文本)有很好的支持,但是它们不支持二进制数据(不带字符编码(character encoding)的字节序列)。虽然我们可以用Base64将二进制编码为文本,但会增加33%左右的大小
- CSV没有任何模式,因此应用程序需要定义每行和每列的含义。如果应用程序更改添加新的行或列,则必须手动处理该变更。
他们与其他编码格式相比,占用了更多的存储空间,JSON比XML简洁,但与二进制格式一比,还是太占空间。这一原因导致大量二进制编码版本JSON & XML的出现,JSON(MessagePack,BSON,BJSON,UBJSON,BISON和Smile等)(例如WBXML和Fast Infoset)。但这些都是在某一特定的领域使用场景比较多,没有JSON比XML这样广泛的应用。这些格式中的一些扩展了一组数据类型(例如,区分整数和浮点数,或者增加对二进制字符串的支持),另一方面,它们没有盖面JSON / XML的数据模型。特别是由于它们没有规定模式,所以它们需要在编码数据中包含所有的对象字段名称。
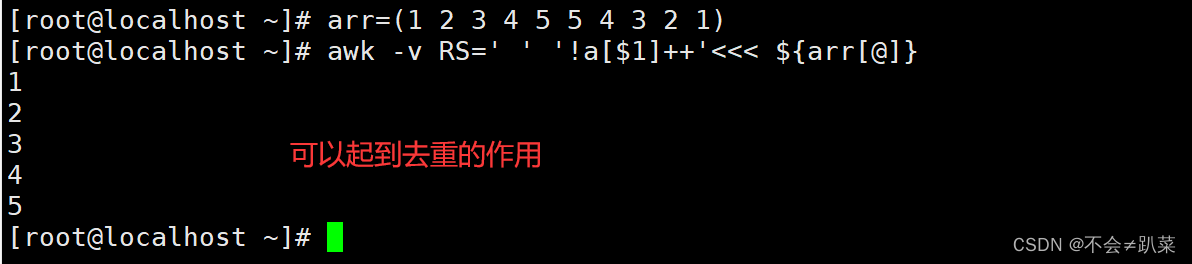
例如MessagePack的编码:

存储形式如下
- 第一个字节 0x83 表示接下来是3个字段(低四位= 0x03 )的对象 object(高四位=
0x80 )。 (如果想知道如果一个对象有15个以上的字段会发生什么情况,字段的数量
塞不进4个bit里,那么它会用另一个不同的类型标识符,字段的数量被编码两个或四个字
节)。 - 第二个字节 0xa8 表示接下来是8字节长的字符串(最高四位= 0x08)。
- 接下来八个字节是ASCII字符串形式的字段名称 userName 。由于之前已经指明长度,不
需要任何标记来标识字符串的结束位置(或者任何转义)。 - 接下来的七个字节对前缀为 0xa6 的六个字母的字符串值 Martin 进行编码,依此类推。
Thrift与Protocol Buffers
Thrift和Protocol Buffers都是一种高效的数据序列化/反序列化框架,它们都被广泛应用于分布式系统中。
Thrift是由Facebook公司开源的一种数据序列化框架,它最初被设计用于解决跨语言服务调用的问题。它支持多种编程语言,并提供了自己的IDL(Interface Definition Language)语言,用于定义接口和数据结构。通过IDL定义,Thrift可以生成对应的客户端和服务端代码。Thrift使用二进制格式进行数据序列化,因此在网络传输中传输效率较高。
Protocol Buffers是由Google公司开源的一种数据序列化框架,类似于Thrift,它也支持多种编程语言,并且提供了自己的IDL语言,用于定义数据结构。Protocol Buffers的IDL语言相比Thrift更加简单,但是却可以定义更加丰富的数据类型。Protocol Buffers同样使用二进制格式进行数据序列化,并且具有较高的序列化和反序列化效率。
Thrift和Protocol Buffers都需要一个模式来编码任何数据。是基于相同原理的二进制编码库。
Thrift接口定义语言(IDL)来描述模式:

Protocol Buffers的等效模式:

每个字段都有一个类型注释(用于指示它是一个字符串,整数,列表等),还可以根据需要指定长度(字符串的长度,列表中的项目数) 。出现在数据中的字符串 (“Martin”, “daydreaming”, “hacking”) 也被编码为ASCII(或者说,UTF-8)。
Thrift和Protocol Buffers每一个都带有一个代码生成工具,它采用了类似于这里所示的模式定义,并且生成了以各种编程语言实现模式的类。
使用Thrift 二进制协议的编码内容:
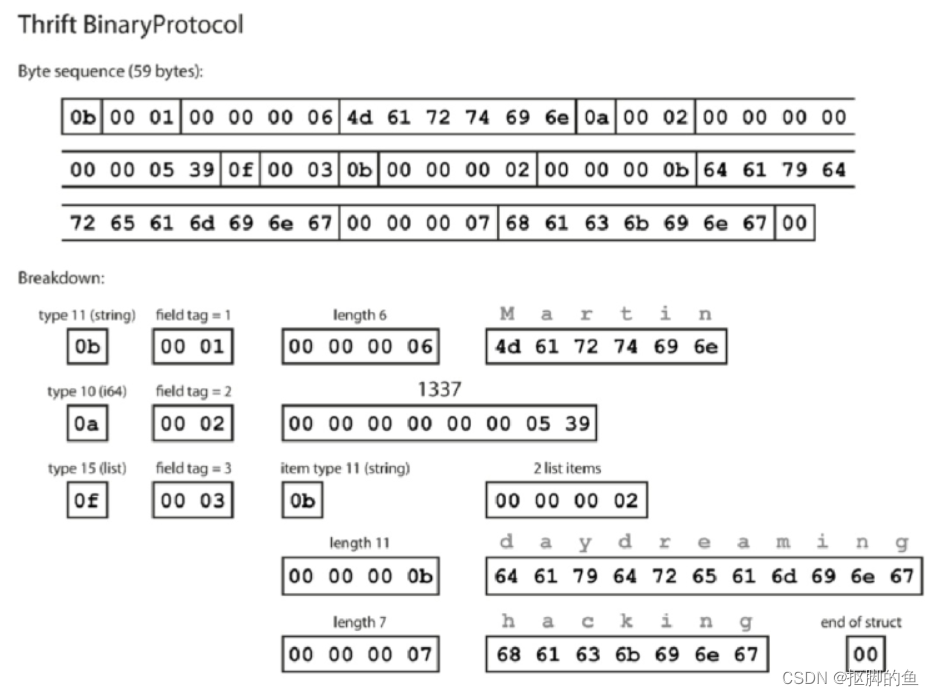
与JSON等相比,最大的区别是没有字段名 (userName, favoriteNumber, interest) 。相反,编码数据包含字段标签,它们是数字 (1, 2和3) 。这些是模式定义中出现的数字。字段标记就像字段的别名,这样就不用记录字符串名称,节省空间。
使用Protocol编码内容:
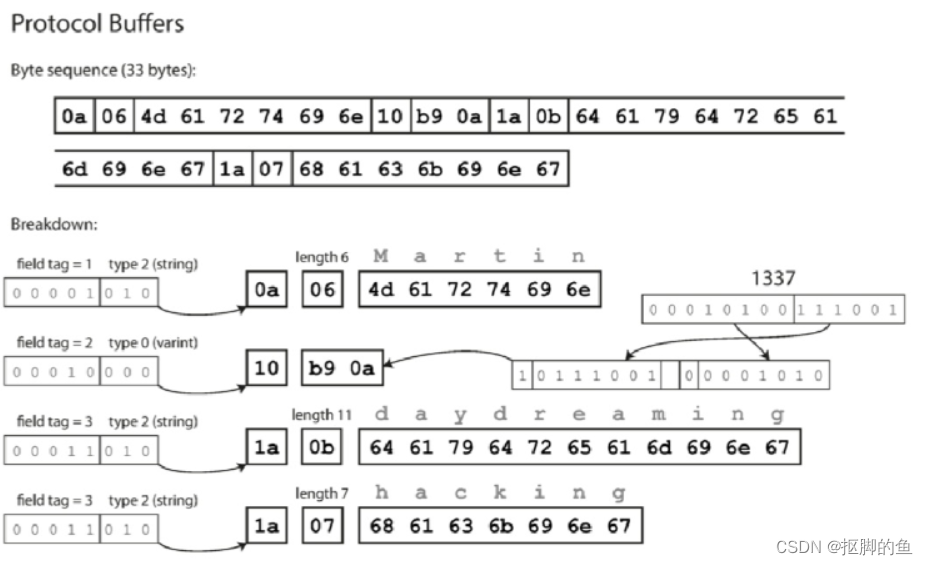
从上面的内容我们可以看出,编码识别的关键在于标签号码的标识(“userName”这个字符串可以理解为仅仅是一个标记,不会影响实际的数据内容),比如上面的userName用序号1标识,favoriteNum用序号2标识,一次类推。序号的标记让我们能够确认在什么位置应该解析什么样的数据。可以更改架构中字段的名称,因为编码的数据永远不会引用字段名称,但不能更改字段的标记,因为这会使所有现有的编码数据无效。
那么如何维护前后兼容性问题呢?
对于向前兼容,忽略不能识别的标签号码字段,但必须保证第一版数据模式部署后,后面新加的字段都应该是非必须的,不然就肯定会检查失败;对于向后兼容,只要每个字段都是一个唯一的标签号码,新代码就可以读取旧数据。因此,一个重要的细节就是模式的初始部署之后添加的每个字段必须是可选的或具有默认值。删除一个字段就像添加一个字段,倒退和向前兼容性问题相反,只能删除非必须字段。
问题来了,有没有可能我们可以去掉标签号码标识。当然可以,那就要介绍Avro了
Avro
Apache Avro是一种数据序列化系统,它使用JSON格式定义数据结构和协议,支持快速、紧凑、跨语言和跨平台的数据序列化和反序列化。它是一种可扩展的数据交换格式,通常用于大规模数据存储、数据处理和数据通信等领域。
Avro也使用模式来指定正在编码的数据的结构。 它有两种模式语言:一种(Avro IDL)用于人工编辑,一种(基于JSON),更易于机器读取。
Avro IDL编写的示例模式:

等价的JSON表示:

首先,请注意架构中没有标签号码。 如果我们使用这个模式编码我们的例子记录,Avro二进制编码只有32个字节长,这是我们所见过的所有编码中最紧凑的。

那么问题是如何支持模式演变?或者说如果字段顺序错乱,能否识别并正确解析?如果我新增一个字段,新旧版本如何兼容呢?
答案就是读者模式与作者模式。
我用一个简单的比喻:假设你是一家快递公司的快递员,需要将包裹从寄件人送到收件人手中。在这个场景中,快递员就是数据的传输通道,寄件人就是数据的“作者”,收件人就是数据的“读者”。
在Avro中,数据的“作者模式”就好比是寄件人将包裹交给了快递员,快递员将包裹送到收件人手中。在这种模式下,数据的“作者”可以自由地定义和修改数据结构和协议,而数据的“读者”需要根据定义好的数据结构和协议来读取数据。因此,这种模式也被称为“寄信人先写信”。
而数据的“读者模式”就好比是收件人在快递员手中收到了包裹,根据包裹上的信息来确认包裹是否正确。在这种模式下,数据的“读者”需要先定义好数据结构和协议,然后再去读取数据。因此,这种模式也被称为“先知道信的样子再收信”。
在Avro中,读者模式和作者模式分别用于定义数据结构和协议以及读取数据。作者模式用于“寄信人先写信”,可以自由地定义和修改数据结构和协议;而读者模式用于“先知道信的样子再收信”,可以根据定义好的数据结构和协议来读取数据。
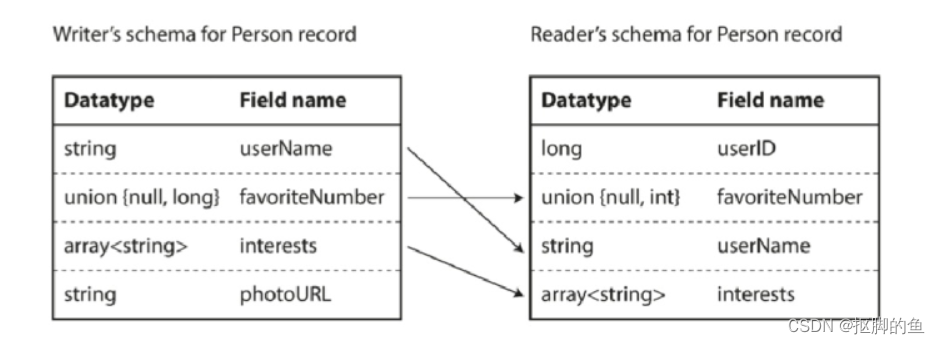
同样需要注意的一点是,为了保持兼容性,只能添加或删除具有默认值的字段。在一些编程语言中,null是任何变量可以接受的默认值,但在Avro 中并不是这样:如果要允许一个字段为 null ,则必须使用联合类型。例如, union {null,long,string} 字段;表示该字段可以是数字或字符串,也可以是 null 。如果它是union的分支 之一,那么只能使用null作为默认值。Avro没有像Protocol Buffers和Thrift那样的 optional 和 required 标记(它有联合类型
和默认值)
以上对于Avro讲述了这么多,那么我们去掉了标签号码标识,除了能节省空间外,更重要的优势是什么?或者说在模式中保留一些数字有什么问题?
关键在于支持了动态生成模式
假如你有一个关系数据库,你想要把它的内容转储到一个文件中,使用Avro,你可以很容易地从关系模式生成一个Avro模式(在 我们之前看到的JSON表示中),并使用该模式对数据库内容进行编码,并将其全部转储到Avro对象容器文件中。您为每个数据库表生成一个记录模式,每个列成为该记录中的一个字段。数据库中的列名称映射到Avro中的字段名称。
现在,如果数据库模式发生变化(例如,一个表中添加了一列,删除了一列),则可以从更新的数据库模式生成新的Avro模式,并在新的Avro模式中导出数据。数据导出过程不需要注 意模式的改变 - 每次运行时都可以简单地进行模式转换。任何读取新数据文件的人都会看到记 录的字段已经改变,但是由于字段是通过名字来标识的,所以更新的作者的模式仍然可以与 旧的读者模式匹配。如果使用Thrift或Protocol Buffers,则字段标记可能必须手动分配