awk的基本应用
- 一、awk的工作原理
- 二、实际应用
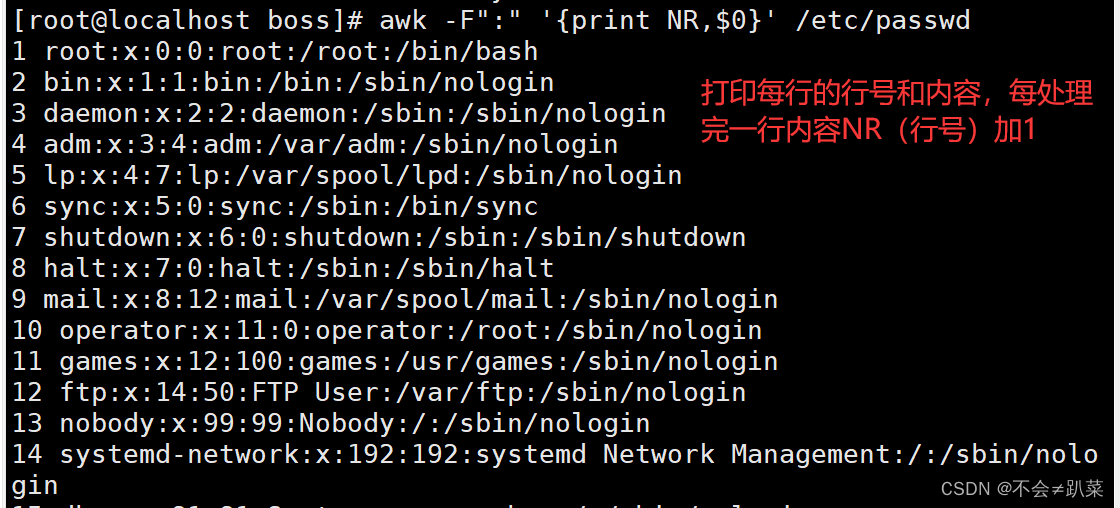
- 按行输出文本
- 按字段输出文本
- 时间的使用
- 查看各个功能
一、awk的工作原理
awk与sed和grep共成为文本三剑客,都是针对文本非常实用的工具。
awk的工作原理:
遂行读取文本,默认以空格或者tab(制表符)键为分隔符进行分隔,将分隔所得的各个字段保存到内建变量中,并按模式或者条件执行编辑命令。
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个“字段”然后再进行处理。awk信息的读入也是遂行读取的,执行结果可以通过print的功能将字段数据打印显示。在使用awk命令的过程中,可以使用逻辑操作符“&&”表示"与"、“||”表示“或”、“!”表示“非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。
其命令格式为:
awk 选项 ‘模式或条件{操作}’ 文件1 文件2 .。。。
awk -f 脚本文件 文件1 文件2
awk常见的内建变量(可直接用)如下所示:
FS:列分隔符。指定每行文本的字段分隔符,默认为空格或制表位。与“-F”作用相同
NF:当前处理的行的字段个数
NR:当前处理的行的行号(序数)。
$0:当前处理的行的整行内容。
$n:当前处理行的第n个字段(第n列)。
FILENAME:被处理的文件名。
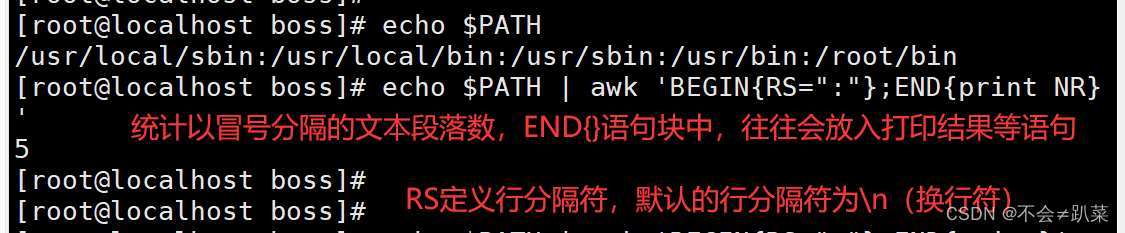
RS:行分隔符。awk从文件上读取资料时,将根据RS的定义吧资料切割成许多条记录,而awk一次仅读取一条记录,以进行处理。预设值是‘\n’
二、实际应用
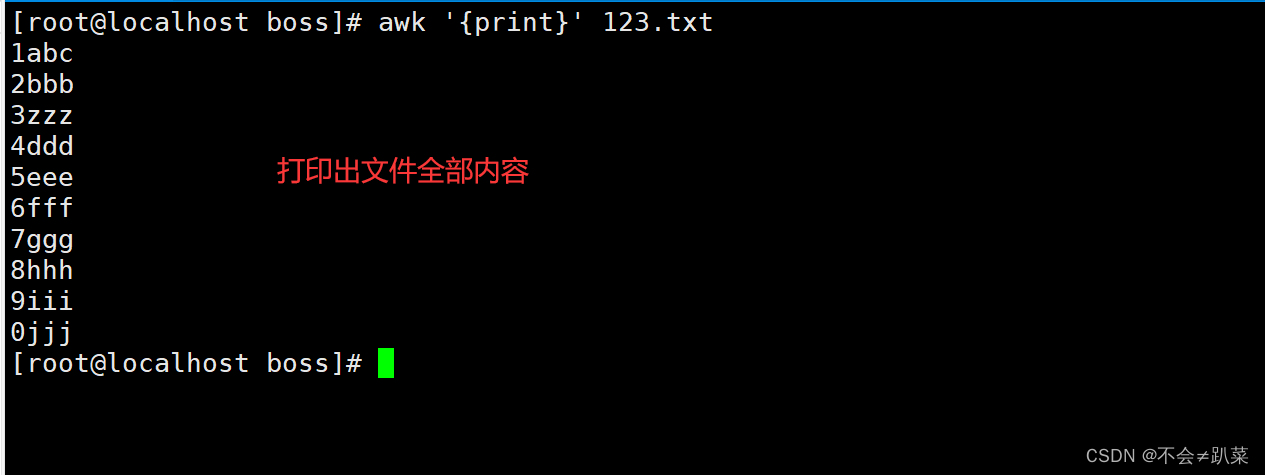
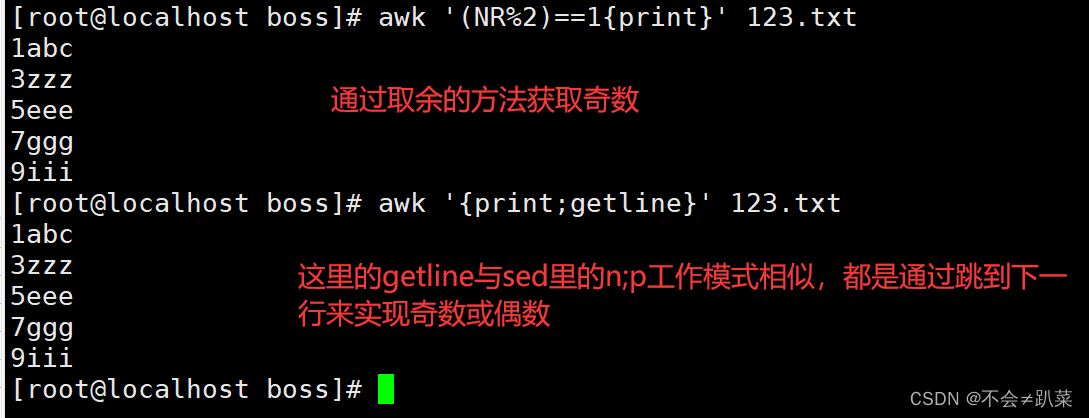
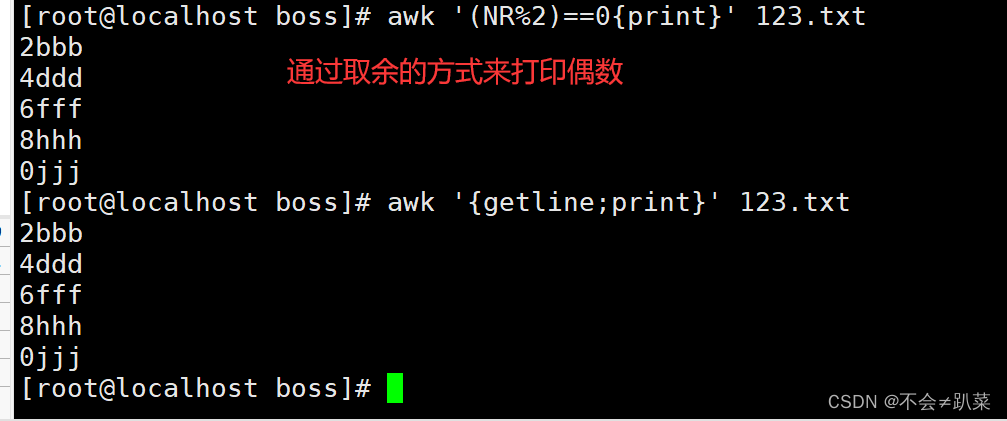
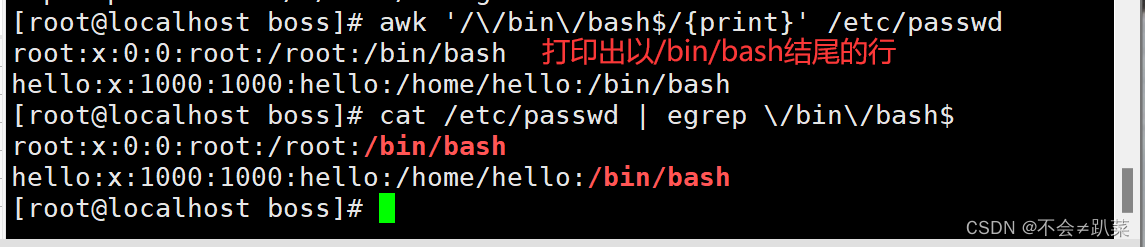
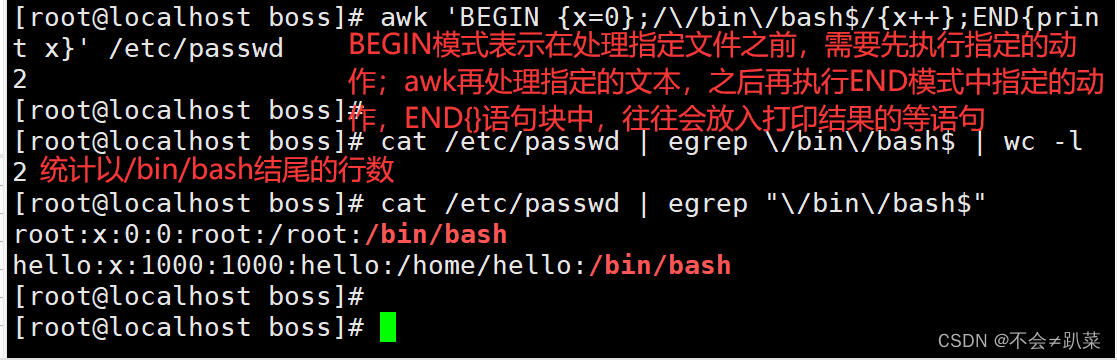
按行输出文本




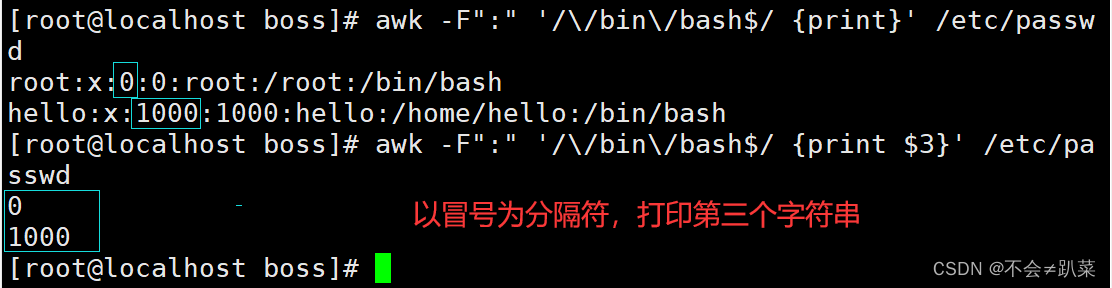
按字段输出文本

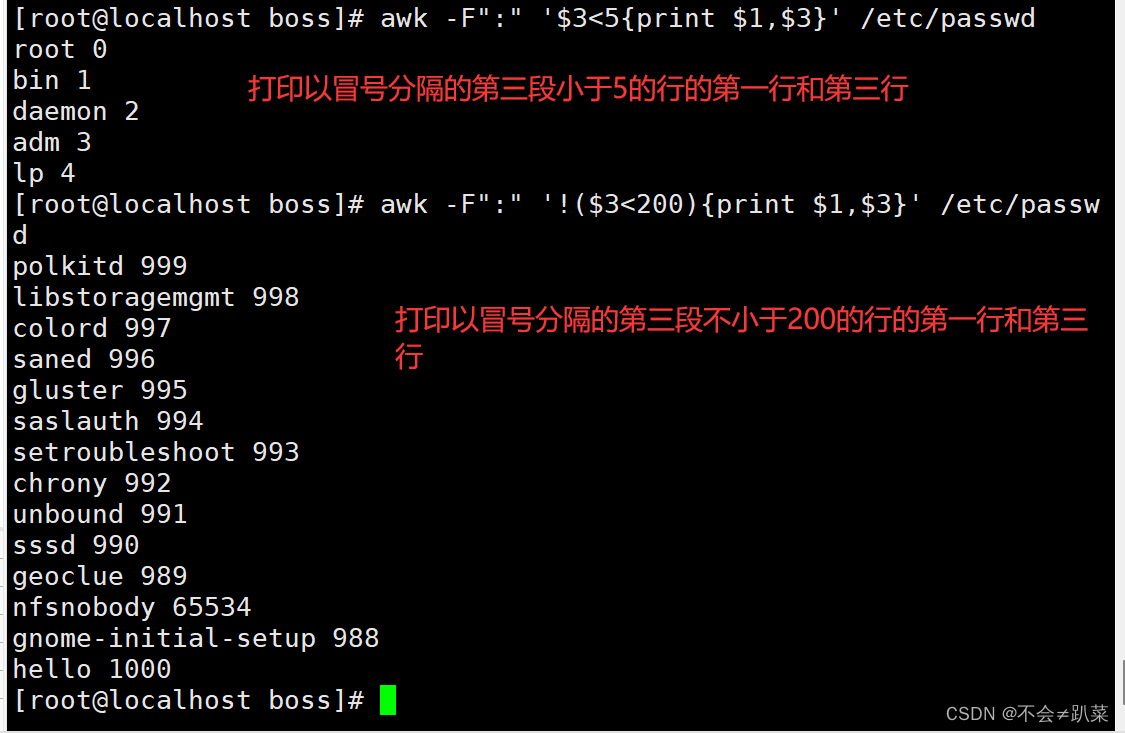
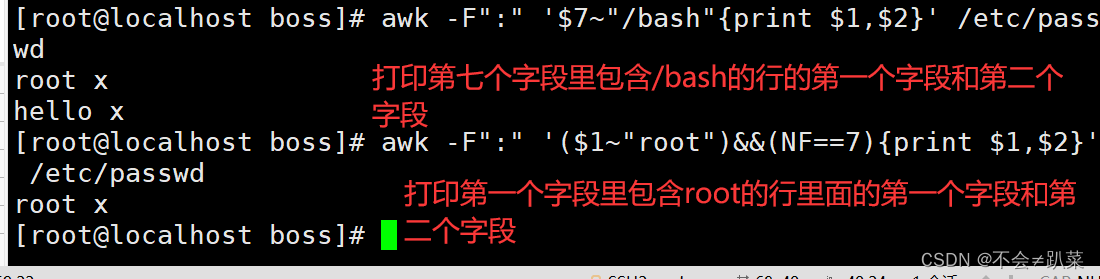

时间的使用




查看各个功能


BEGIN中的命令只执行一次,awk数组的下标除了可以使用数字,也可以使用字符串,但是字符串必须加双引号
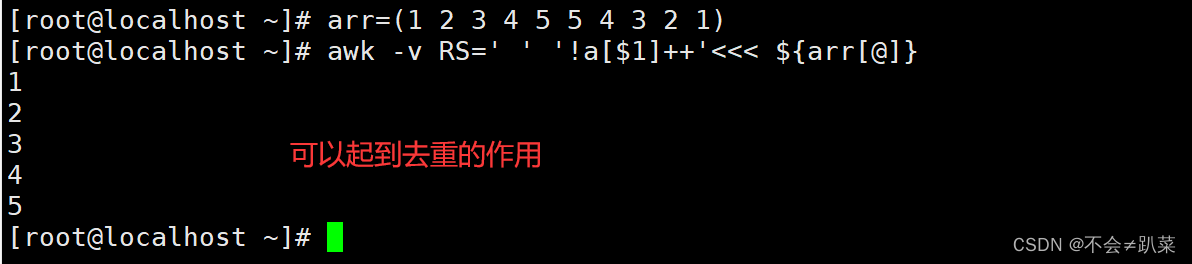
-v:设置变量
<<<:表示将后面的内容作为前面命令的标准输入
awk’1’:就算awk‘1{print}’,允许打印读入的行内容
awk’0’:就算awk‘0{print}’,不允许打印读入的行内容
var++的形式:先读取var的变量值,再对var值+1
awk 处理第一行时:先读取 a[$1] 值再自增,a[$1] 即 a[1] 值为空(即0),即为 awk ‘!0’,即为 awk ‘1’,即为 awk’1{print}’
awk 处理第二行时:先读取 a[$1] 值再自增,a[$1] 即 a[1] 值为 1,即为 awk ‘!1’,即为 awk ‘0’,即为 awk ‘0{print}’
ip=ifconfig ens33 | awk '/inet /{print $2}'
echo “本地IP地址是:”$ip
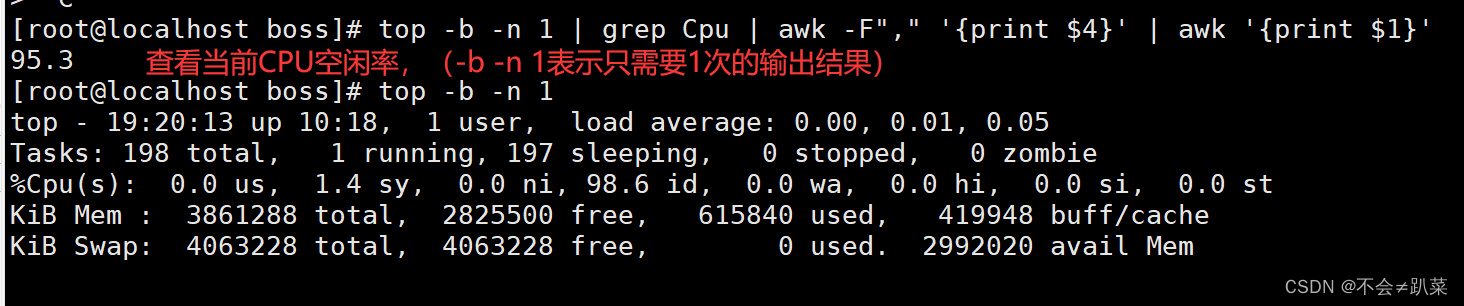
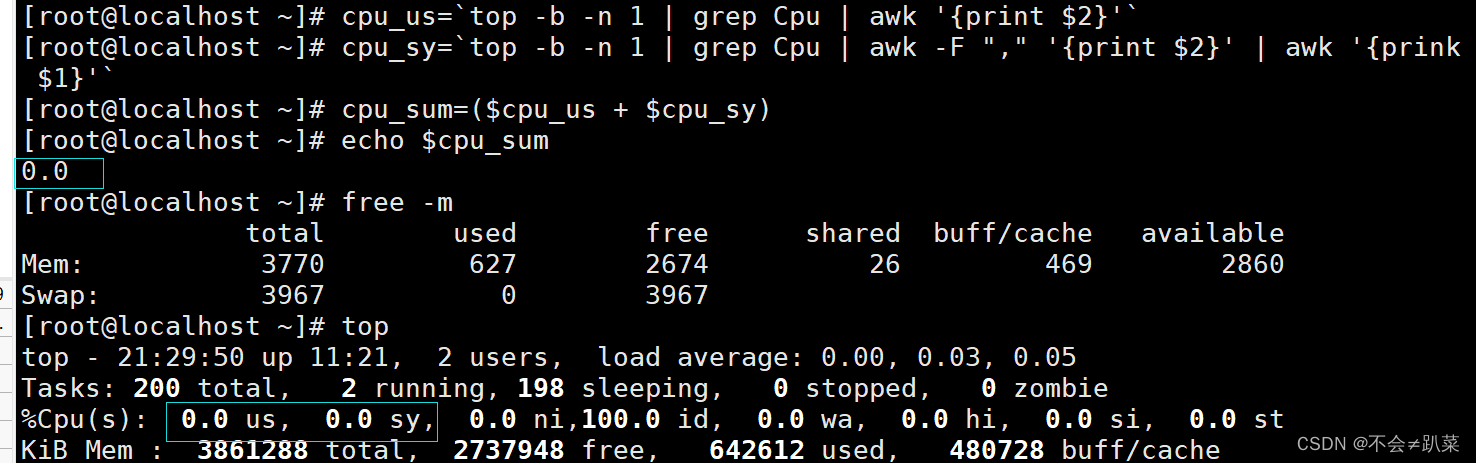
cpu=uptime | awk '{print $NF}'
#awk中NF为当前行的列数,
N
F
是最后一列
e
c
h
o
"
本机
C
P
U
最近
15
分钟的负载是
:
"
NF是最后一列 echo "本机CPU最近15分钟的负载是:"
NF是最后一列echo"本机CPU最近15分钟的负载是:"cpu
net_in=ifconfig ens33 | awk '/RX p/{print $5}'
echo “入站网卡流量为:”$net_in
net_out=ifconfig ens33 | awk '/TX p/{print $5}'
echo “出站网卡流量为:”$net_out
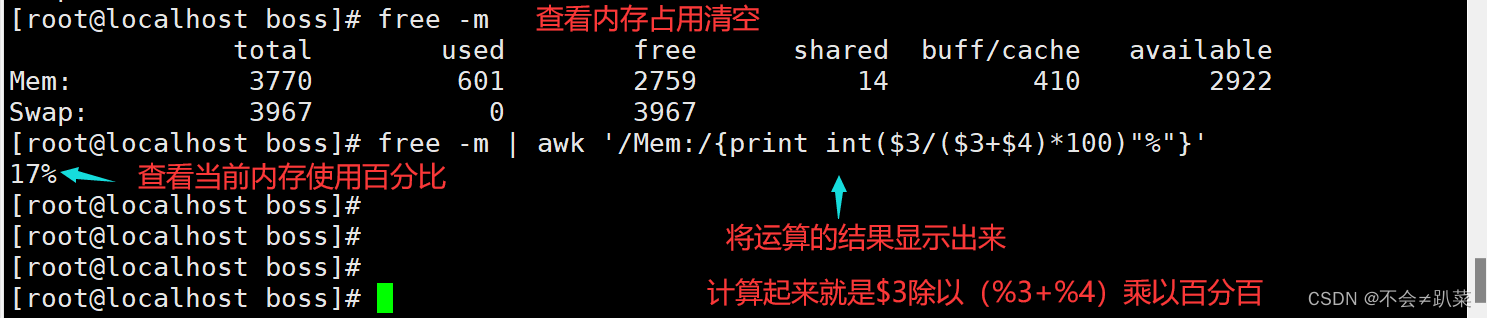
mem=free -m | awk '/^Mem/{print $4)'
echo “内存剩余容量为:”$mem
disk=df -h | awk '/sda1/{print $4}'
echo "根分区剩余容量为:"
d
i
s
k
u
s
e
r
=
‘
c
a
t
/
e
t
c
/
p
a
s
s
w
d
∣
w
c
−
l
‘
e
c
h
o
"
本地账户数量为
:
"
disk user=`cat /etc/passwd |wc -l` echo "本地账户数量为:"
diskuser=‘cat/etc/passwd∣wc−l‘echo"本地账户数量为:"user
login=who | wc -l
echo "当前登陆计算机的账户数量为:"
l
o
g
i
n
p
r
o
c
e
s
s
=
‘
p
s
a
u
x
∣
w
c
−
l
‘
e
c
h
o
"
当前计算机启动的进程数量为
:
"
login process=`ps aux | wc -l` echo "当前计算机启动的进程数量为:"
loginprocess=‘psaux∣wc−l‘echo"当前计算机启动的进程数量为:"process
soft=rpm -qa | wc -l
echo “当前计算机已安装的软件数量为:”$soft










![[深度学习思想] ControlNet 工作原理](https://img-blog.csdnimg.cn/9099f9420709438ca724b8b36a458a80.png)