文章目录
- 链表介绍
- 单链表初始化
- 单链表打印
- 增加节点
- 单链表的头插
- 单链表的尾插
- 在给定位置之后插入
- 在给定位置之前插入
- 删除节点
- 单链表的头删
- 单链表的尾删
- 删除给定位置之后的节点
- 删除给定位置处的节点
- 查找节点
- 修改节点
- 单链表销毁
链表介绍
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
• 图示:

实际中,链表的结构多种多样:
链表分为多种结构:单向\双向,带头\不带头,循环\非循环
• 单向/双向

• 带头/不带头

• 循环/非循环

通过以上的这些情况组合起来,就有八种链表结构。即带头单向循环链表、带头单向非循环链表、带头双向循环链表、带头双向非循环链表、无头单向循环链表、无头单向非循环链表、无头双向循环链表、无头双向非循环链表。
实际上最常用的是:无头单向非循环链表,带头双向循环链表。本篇博客讲解的是无头单向非循环链表。
单链表初始化
链表是由一个个结点链接而成,创建一个链表之前,我们首先要创建一个结点类型,该类型由两部分组成:数据域和指针域。
typedef int SLTDataType;//篇博客以存放整型数据为例
typedef struct SListNode
{
SLTDataType data;//数据域:用于存储该结点的数据
struct SListNode* next;//指针域:用于存放下一个结点的地址
}SListNode;
单链表打印
打印链表时,我们需要从头指针指向的位置开始,依次向后打印,直到指针指向NULL时,结束打印。
//打印链表
void SListPrint(SListNode* plist)
{
SListNode* cur = plist;//接收头指针
while (cur != NULL)//判断链表是否打印完毕
{
printf("%d->", cur->data);//打印数据
cur = cur->next;//指针指向下一个结点
}
printf("NULL\n");//打印NULL,表明链表最后一个结点指向NULL
}
增加节点
仔细想想,每当我们需要增加一个结点之前,我们必定要先申请一个新结点,然后再插入到相应位置,于是我们可以将该功能封装成一个函数。
//创建一个新结点,返回新结点地址
SListNode* BuySLTNode(SLTDataType x)
{
SListNode* node = (SListNode*)malloc(sizeof(SListNode));//向新结点申请空间
if (node == NULL)
{
printf("malloc fail\n");
exit(-1);
}
node->data = x;//将数据赋值到新结点的数据域
node->next = NULL;//将新结点的指针域置空
return node;//返回新结点地址
}
单链表的头插
头插时,我们只需要先让新结点的指针域指向头指针指向的位置(即原来的第一个结点),然后让头指针指向新结点即可。
//头插
void SListPushFront(SListNode** pplist, SLTDataType x)
{
SListNode* newnode = BuySLTNode(x);//申请一个新结点
newnode->next = *pplist;//让新结点的指针域指向地址为pos的结点的下一个结点
*pplist = newnode;//让地址为pos的结点指向新结点
}
注:这两步操作的顺序不能颠倒,若先让头指针指向新结点,那么就无法找到原来第一个结点的位置了。
单链表的尾插
尾插的时候我们需要先判断链表是否为空,若为空,则直接让头指针指向新结点即可;若不为空,我们首先需要利用循环找到链表的最后一个结点,然后让最后一个结点的指针域指向新结点。
//尾插
void SListPushBack(SListNode** pplist, SLTDataType x)
{
SListNode* newnode = BuySLTNode(x);//申请一个新结点
if (*pplist == NULL)//判断是否为空表
{
*pplist = newnode;//头指针直接指向新结点
}
else
{
SListNode* tail = *pplist;//接收头指针
while (tail->next != NULL)//若某结点的指针域为NULL,说明它是最后一个结点
{
tail = tail->next;指针指向下一个结点
}
tail->next = newnode;//让最后一个结点的指针域指向新结点
}
}
注:新结点创建的时候指针域就已经置空,所以尾插时不需要再将新结点的指针域置空。
在给定位置之后插入
在给定位置后插入结点也只需要两步:先让新结点的指针域指向该位置的下一个结点,然后再让该位置的结点指向新结点即可。
//在给定位置之后插入
void SListInsertAfter(SListNode* pos, SLTDataType x)
{
assert(pos);//确保传入地址不为空
SListNode* newnode = BuySLTNode(x);//申请一个新结点
newnode->next = pos->next;//让新结点的指针域指向地址为pos的结点的下一个结点
pos->next = newnode;//让地址为pos的结点指向新结点
}
注:这两步操作也不能颠倒顺序,理由与头插时相同。
在给定位置之前插入
要想在给定位置的前面插入一个新结点,我们首先还是要找到该位置之前的一个结点,然后让新结点的指针域指向地址为pos的结点,让前一个结点指向新结点即可。需要注意的是,当给定位置为头指针指向的位置时,相当于头插。
//在给定位置之前插入
void SListInsertBefore(SListNode** pplist, SListNode* pos, SLTDataType x)
{
assert(pos);//确保传入地址不为空
SListNode* newnode = BuySLTNode(x);//申请一个新结点
if (pos == *pplist)//判断给定位置是否为头指针指向的位置
{
newnode->next = pos;//让新结点的指针域指向地址为pos的结点
*pplist = newnode;//让头指针指向新结点
}
else
{
SListNode* prev = *pplist;//接收头指针
while (prev->next != pos)//找到地址为pos的结点的前一个结点
{
prev = prev->next;
}
newnode->next = prev->next;//让新结点的指针域指向地址为pos的结点
prev->next = newnode;//让前一个结点指向新结点
}
}
删除节点
单链表的头删
头删较为简单,若为空表,则不必做处理;若不为空表,则直接让头指针指向第二个结点,然后释放第一个结点的内存空间即可。
//头删
void SListPopFront(SListNode** pplist)
{
if (*pplist == NULL)//判断是否为空表
{
return;
}
else
{
SListNode* tmp = *pplist;//记录第一个结点的位置
*pplist = (*pplist)->next;//让头指针指向第二个结点
free(tmp);//释放第一个结点的内存空间
tmp = NULL;//及时置空
}
}
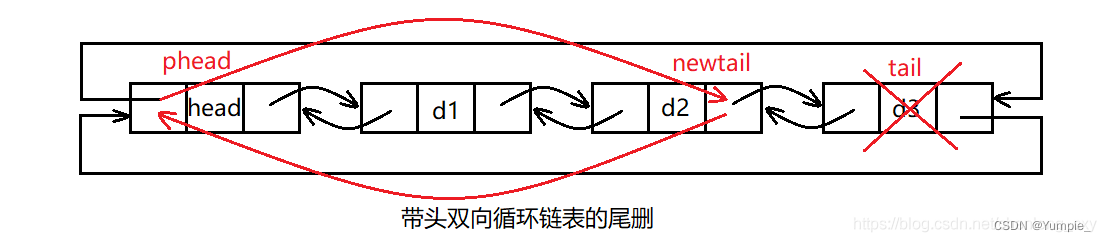
单链表的尾删
尾删相对麻烦一些,我们需要考虑三种不同的情况:
1、当链表为空时,不做处理。
2、当链表中只有一个结点时,直接释放该结点,然后将头指针置空。
3、当链表中有多个结点时,我们需要先找到最后一个结点的前一个结点,然后将最后一个结点释放,将前一个结点的指针域置空,使其成为新的尾结点。
//尾删
void SListPopBack(SListNode** pplist)
{
if (*pplist == NULL)//判断是否为空表
{
return;
}
else if ((*pplist)->next == NULL)//判断是否只有一个结点
{
free(*pplist);//释放该结点
*pplist = NULL;//及时置空
}
else
{
SListNode* prev = *pplist;//接收头指针
SListNode* tail = (*pplist)->next;//接收第二个结点的地址
while (tail->next != NULL)//当tail指向最后一个结点时停止循环
{
prev = tail;//使prev始终指向tail的前一个结点
tail = tail->next;//tail指针后移
}
free(tail);//释放最后一个结点
tail = NULL;//及时置空
prev->next = NULL;//将倒数第二个结点的指针域置空,使其成为新的尾节点
}
}
删除给定位置之后的节点
要删除给定位置之后的值,我们首先判断传入地址是否为最后一个结点的地址,若是,则不做处理,因为最后一个结点后面没有结点可删除。若不是最后一个结点,我们首先让地址为pos的结点指向待删除结点的后一个结点,然后将待删除结点释放即可。
//删除给定位置之后的值
void SListErasetAfter(SListNode* pos)
{
assert(pos);//确保传入地址不为空
if (pos->next == NULL)//判断传入地址是否为最后一个结点的地址
{
return;
}
SListNode* after = pos->next;//待删除的结点
pos->next = after->next;//让pos结点指向待删除的结点的下一个结点
free(after);//释放结点
after = NULL;//及时置空
}
删除给定位置处的节点
要删除给定位置的结点,我们首先要判断该结点是否为第一个结点,若是,则操作与头删相同;若不是,我们就需要先找到待删除结点的前一个结点,然后让其指向待删除结点的后一个结点,最后才能释放待删除的结点。
//删除给定位置的值
void SListErasetCur(SListNode** pplist, SListNode* pos)
{
assert(pos);//确保传入地址不为空
if (pos == *pplist)//判断待删除的结点是否为第一个结点
{
*pplist = pos->next;//让头指针指向第二个结点
free(pos);//释放第一个结点
pos=NULL;//及时置空
}
else
{
SListNode* prev = *pplist;//接收头指针
while (prev->next != pos)//找到待删除结点的前一个结点
{
prev = prev->next;
}
prev->next = pos->next;//让待删除的结点的前一个结点指向待删除结点的后一个结点
free(pos);//释放待删除结点
pos = NULL;//及时置空
}
}
查找节点
查找数据相对于前面的来说就非常简单了,我们只需要遍历一遍链表,在遍历的过程中,若找到了目标结点,则返回结点的地址;若遍历结束也没有找到目标结点,则直接返回空指针。
//查找数据
SListNode* SListFind(SListNode* plist, SLTDataType x)
{
SListNode* cur = plist;//接收头指针
while (cur != NULL)//遍历链表
{
if (cur->data == x)//判断结点是否为待找结点
return cur;//返回目标结点的地址
cur = cur->next;//指针后移
}
return NULL;//没有找到数据为x的结点
}
修改节点
修改数据更加简单。
//修改数据
void SListModify(SListNode* pos, SLTDataType x)
{
pos->data = x;//将结点的数据改为目标数据
}
单链表销毁
1> 对于动态开辟的内存空间,在使用后一定要记得的进行释放(避免造成内存泄漏)
2>因为链表节点是一个个开辟的,同样的释放也需要一个个进行释放
3>循环遍历释放当前节点前需保存后一个节点的地址,避免地址丢失无法释放
4>释放完后,还需将链表指针给置空(避免使用野指针)
//链表节点释放
void SListDestory(SLTNode** pphead)
{
//避免传入错误(直接报错便于找到错误位置)
assert(pphead);
//遍历释放
SLTNode* cur = *pphead;
while (cur)
{
//保存下一个地址
SLTNode* next = cur->next;
free(cur);
cur = next;
}
//置空
*pphead = NULL;
return;
}

![[深度学习思想] ControlNet 工作原理](https://img-blog.csdnimg.cn/9099f9420709438ca724b8b36a458a80.png)