1.Jsoup
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
需求是需要获取某个网站上的排行榜数据,用作App展示,所以就想到了Jsoup框架。
我看网上其实有很多的Jsoup博客,讲的挺好的,但是有些许差异,有的也将错了,我还是推荐去官网学习,内容很少,也很简便:
Load a Document from a URL: jsoup Java HTML parser
里面讲了如何从html文件,url地址,file加载内容,也讲了通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据,很详细也写的挺简单的,是全英文,看不太懂可以装个翻译插件,或者google浏览器翻个墙,他自己就给你翻译了。
这里我就不详细展开了,很多很杂但也很基础,讲个例子吧:比如获取2022年billboard榜单的前100位歌手数据(排名,封面,名字)
Top Artists – Billboard

实现代码:Kotlin
1.使用getListData方法获取歌手信息列表;
2.Dispatchers.IO - 此调度程序经过了专门优化,适合在主线程之外执行磁盘或网络 I/O。示例包括使用Room组件、从文件中读取数据或向文件中写入数据,以及运行任何网络操作。
3.Jsoup.connect(url).get()获取到Document对象,拿到对象后,就可以用那几种方式获取自己想要的数据了。
fun getListData(result:RequestCallBack<MutableList<ArtistInfo>>): List<ArtistInfo>? {
CoroutineScope(Dispatchers.IO).launch {
val artistList = mutableListOf<ArtistInfo>()
val url = "https://www.billboard.com/charts/year-end/top-artists/"
try {
val document = Jsoup.connect(url).get()
Log.d("TTTT", "jsoup:$document")
val listDoc: Elements =
document.getElementsByClass("o-chart-results-list-row-container")
Log.d("TTTT", "jsoup:size ${listDoc.size}")
val artistSize = if (listDoc.size > 50) 50 else listDoc.size
for (i in 0 until artistSize) {
val sortNum = listDoc[i].select("span").text()
Log.d("TTTT", "jsoup:$sortNum")
val artistName = listDoc[i].select("h3").text()
Log.d("TTTT", "jsoup:$artistName")
val img = listDoc[i].select("img").attr("data-lazy-src").toString()
Log.d("TTTT", "jsoup:$img")
val artistInfo = ArtistInfo().apply {
this.artist = artistName
this.rank = sortNum.toInt()
this.coverOnline = img
}
artistList.add(artistInfo)//加入列表
App.getInstance().getArtistDao().insertOrReplace(artistInfo)//单个歌手数据插入数据库,用的greenDao
}
result.success(artistList)//返回歌手列表数据,UI上展示
} catch (exception: IOException) {
exception.printStackTrace()
}
}
return null
}
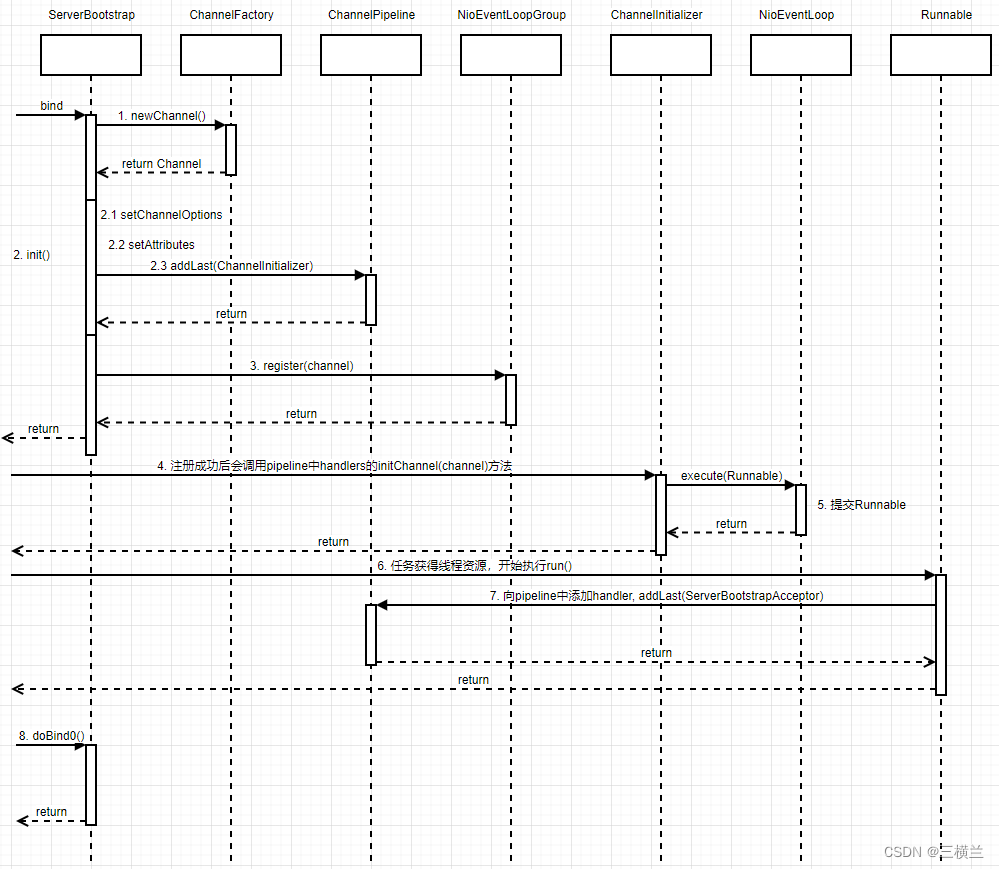
当然,怎么去知道网页的数据在何种标签,哪个class下面呢,自然是去浏览器F12查看数据咯
1.首先是element查看当前网页的源代码,在旁边的黄色标记的箭头,你点击后,再去点左边网页的元素,你就知道,它的数据在哪里了。
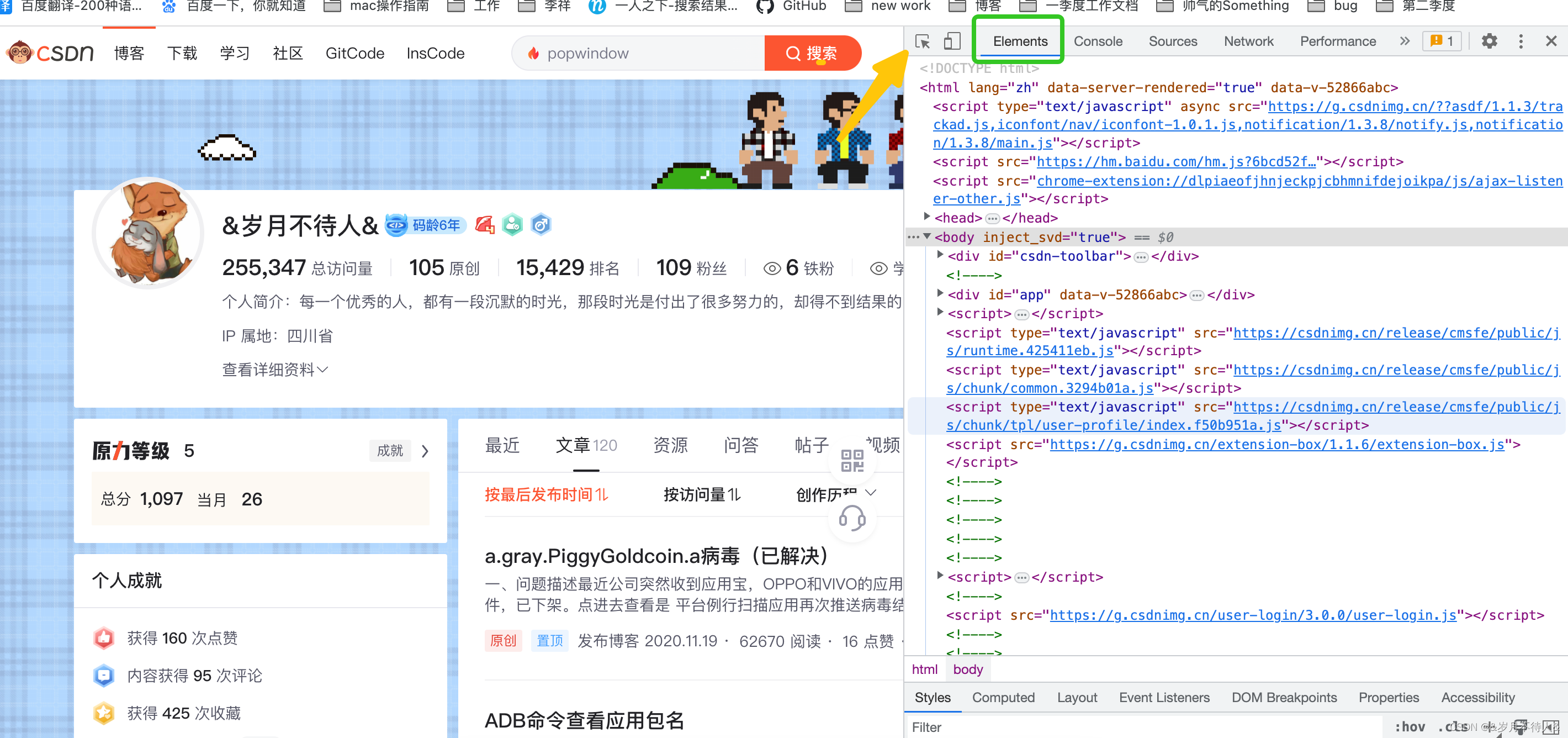
2.在network中,点到返回的各个数据中,选到response就可以看到,请求返回的数据,也可以观察其数据结构(有js、json等数据格式)
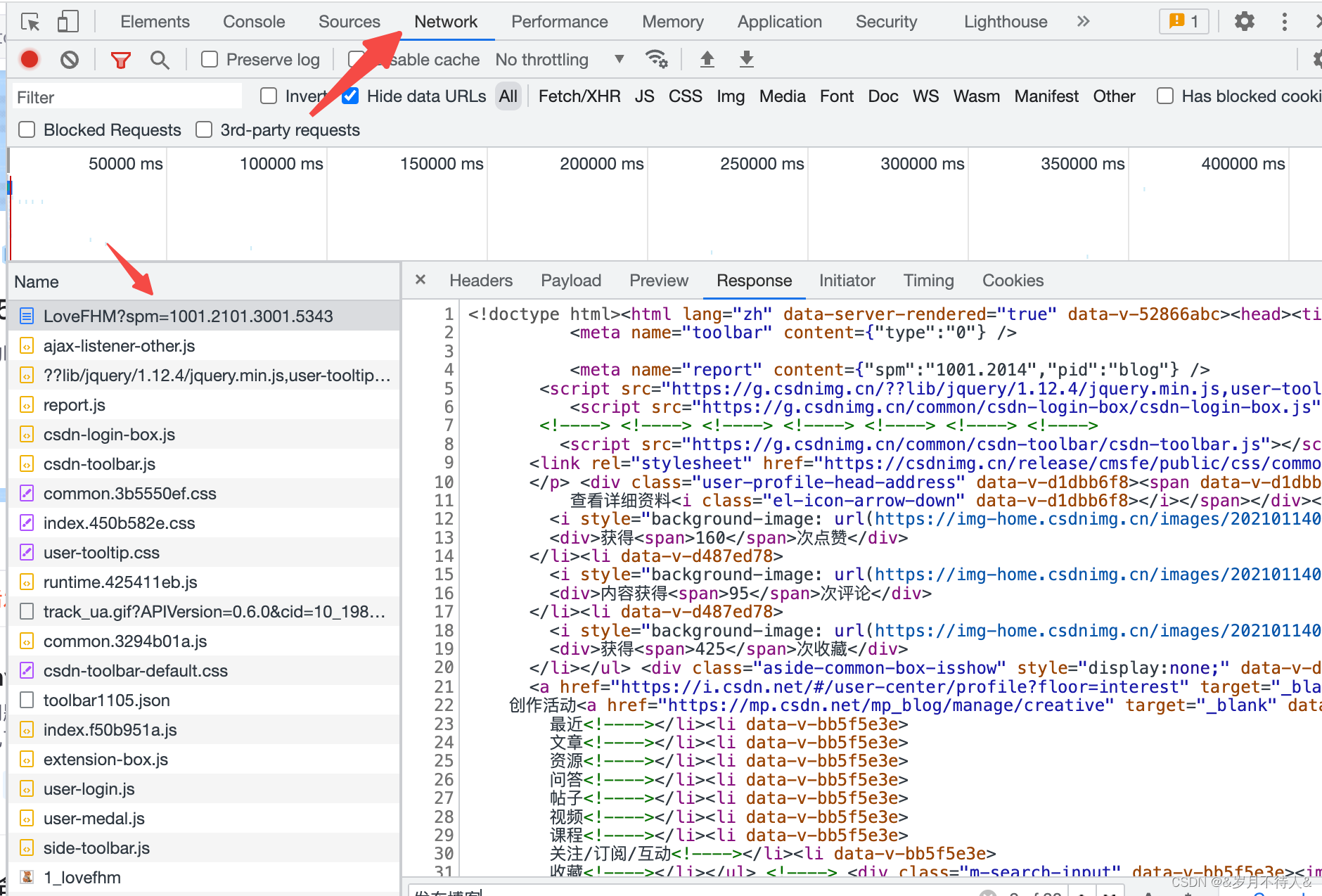
这个框框里的选项很有用,可以看到请求方式,参数,预览页,返回数据等等 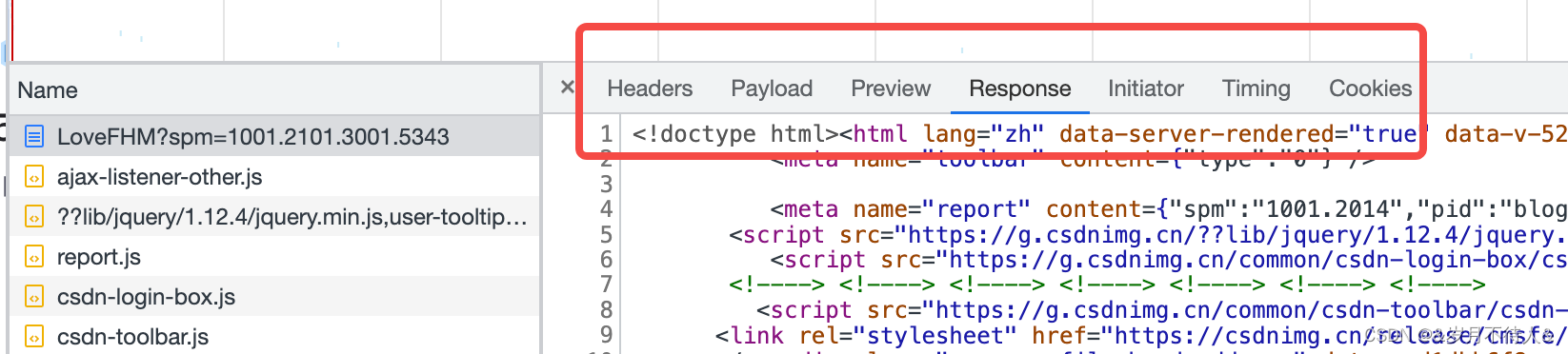
2.局限性
使用Jsoup还是挺快乐的,我在爬取国内大多数的网站的时候,大多数的数据都可以拿到。
但是,我在爬取某些网页的时候,发现某些数据拿不到,拿不全,我发现有些网页,他的数据并不是一次获取的,按F12发现,他会并行请求很多数据再展示,所以,Jsoup是否可以真的获得动态网页的数据吗???我在百度Jsoup 爬取动态网页发现一堆文章,但是我看其文章其实爬的数据都是一次性拿到的,真的懵逼。Jsoup是否有局限性呢?
所以我个人觉得Jsoup爬虫,该方式是有一定局限性的,就是你通过jsoup爬虫更适合爬静态网页,所以不特殊配制的情况下只能爬当前页面的部分数据。如果需要爬一个网站所有数据,通过接口,通过上传正确的参数,或许更容易爬到该网站的该有的数据信息。
emmmm,在爬取一个网站的音乐数据时,用Jsoup好久都没搞出来。最后还是F12查询接口,参数用接口获取到的数据。
接口获取数据的话,繁琐些,但是如果网站没做反爬虫,拿取数据还是没问题的。
tips:Jsoup或许可以通过配置请求体(data),配置header那些去获取动态网页的数据,但是个人觉得有些麻烦,爬的页面有点多,还是选择了接口
3.接口爬取数据思路
主要流程:
1.目标网页,看下图,观察header等等里面的数据,获取接口,需要的参数等等
2.这时候你会发现,接口返回的response里的Json数据,这可怎么看啊??这儿推荐一个超级好用的网址。
Online JSON Viewer
3.有网址了先别急,先用postman去模拟访问数据,看自己配的数据是否真的可以访问网址并获取到争取的数据。postman拿到的数据也可以放到上面的网址里面去查看数据结构,因为网址接口爬取的数据会很大,postman不好观察。
4.建立请求/返回的实体类,然后用android网络框架去访问它就行了。
这儿只提供下思路,具体实现就不说了。思路有了做起来很快的。
个人爬取数据仅作个人学习,老铁们记得好自为之啊,哈哈哈