论文题目:《LLaMA: Open and Efficient Foundation Language Models》
论文链接:https://arxiv.org/pdf/2302.13971.pdf
github链接:https://github.com/facebookresearch/llama/tree/main
huggingface链接:https://huggingface.co/decapoda-research/llama-7b-hf
1 模型简介
LLaMA 是 Meta AI 发布的包含 7B、13B、33B 和 65B 四种参数规模的基础语言模型集合,LLaMA-13B 仅以 1/10 规模的参数在多数的 benchmarks 上性能优于 GPT-3(175B),LLaMA-65B 与业内最好的模型 Chinchilla-70B 和 PaLM-540B 比较也具有竞争力。
主要贡献:
- 开源一系列语言模型,可以与SOTA模型竞争
- LLaMA-13B比GPT-3的性能更好,但是模型大小却是十分之一
- LLaMA-65B与Chinchilla-70B和PaLM-540B的实力相当
- 使用公开数据集即可部分复现最先进的性能(86%左右的效果)
2 研究背景
在给定预算的条件下,最好的模型并不一定是最大的模型,在更多的数据上训练的较小的模型反而会达到更好的性能。Hoffmann工作的目的是决定如何确定数据集和模型大小的规模,但是他忽略了推理的成本。所以在这篇文章中,给定一个目标的性能等级,更推荐的模型不是最快训练的,但是是最快推理的。产生的模型称为LLaMA,参数范围从7B到65B,与现在最好的LLM相当。
LLaMA-13B比GPT-3在大多数benchmarks上性能都要好,但是模型大小缩减到十分之一。Meta团队相信这个模型有助于LLM的使用和研究的大众化,因为可以在单个GPU上运行。在更高的规模量上,65B参数量模型与当前最好的LLM(比如Chinchila或PaLM-540B)相比更具有竞争力。LLaMA的另一个优势是它是使用公开数据集进行训练。
3 训练方法
这项工作的训练方法相似于Brown的工作,并且受到Hoffmann(Chinchilla scaling laws)的启发。模型使用标准优化器进行优化。后面会单独解读下《 Scaling Laws for Neural Language Models》,该文主要建模了模型性能与非embedding参数 N,数据集大小 D 与计算量 C之间的关系。最主要的发现:
- 性能主要与模型大小相关,而与模型结构弱相关
- 性能与上面三个因素有比较贴合的power-law关系
从实验来看,模型越大越好,小模型确实达不到大模型大力出奇迹的效果,而模型结构也并没有那么重要(虽然有很多工作是在改进模型结构本身)。结论部分更强调了大模型比大数据更重要
3.1 预训练数据
我们的训练数据集是多个来源的混合,如表 1 所示,涵盖了不同的领域。 在大多数情况下,我们重复使用已用于培训其他 LLM 的数据源,但仅限于使用公开可用且与开源兼容的数据。 这导致以下混合数据及其在训练集中所占的百分比:

3.2 模型结构
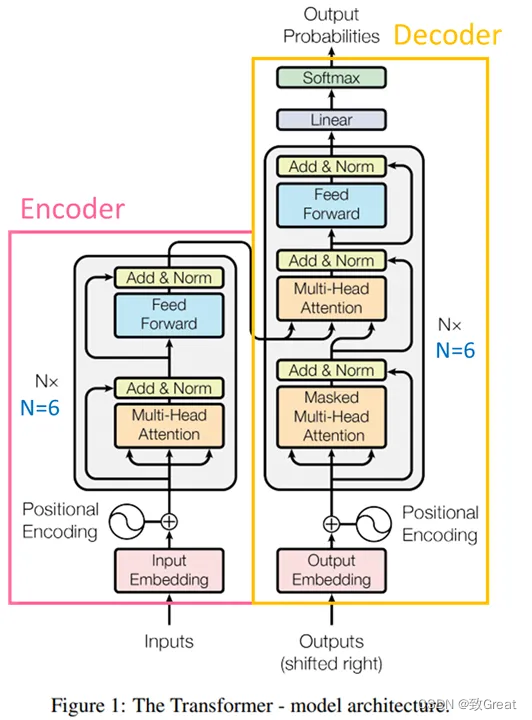
整体架构仍然是Transformer的解码器模块,该模块参考论文Attention is all you need。下面是在Transformer架构上的进一步的3个改进。
- [GPT3] 使用RMSNorm(即Root Mean square Layer Normalization)对输入数据进行标准化,RMSNorm可以参考论文:Root mean square layer normalization。
a ˉ i = a i RMS ( a ) g i , where RMS ( a ) = 1 n ∑ i = 1 n a i 2 . \begin{align} \begin{split} & \bar{a}i = \frac{a_i}{\text{RMS}(\mathbf{a})} g_i, \quad \text{where}~~ \text{RMS}(\mathbf{a}) = \sqrt{\frac{1}{n} \sum{i=1}^{n} a_i^2}. \end{split}\nonumber \end{align} aˉi=RMS(a)aigi,where RMS(a)=n1∑i=1nai2.
为了提高训练的稳定性,在每个transformer子层的input处进行正则化,而不是在output处,使用的正则化方法是RMSNorm。
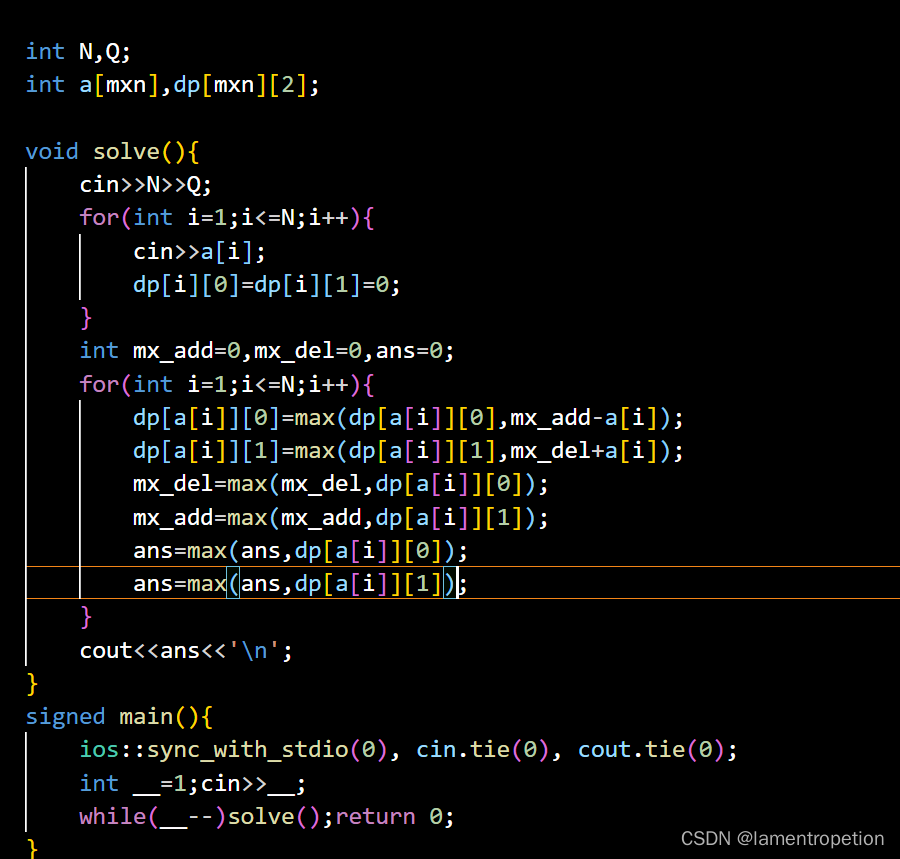
LLaMA源码中实现方式为:
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
- [PaLM]使用激活函数SwiGLU, 该函数可以参考PALM论文:Glu variants improve transformer。
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
- [GPTNeo]使用Rotary Embeddings进行位置编码,该编码可以参考论文 Roformer: Enhanced transformer with rotary position embedding。
3.3 优化器
使用了AdamW优化器,并使用cosine learning rate schedule,使得最终学习率等于最大学习率的10%,设置0.1的权重衰减和1.0的梯度裁剪。warmup的step为2000,并根据模型的大小改变学习率和批处理大小(详见表2)。

3.4 高效实现
- 作者做了一些优化来提高模型的训练速度。首先,使用因果多头注意的有效实现来减少内存使用和运行时间。该实现可在xformers库中获得。
https://github.com/facebookresearch/xformers
- 为了进一步提高训练效率,通过检查点减少了在向后传递过程中重新计算的激活量。更准确地说,节省了计算成本高的激活,比如线性层的输出。这是通过手动实现transformer层的backward函数来实现的,而不是依赖于PyTorch的autograd。
这个指的是gradient checkpointing,这个策略是用时间(重新计算这些值两次的时间成本)来换空间(提前存储这些值的内存成本)。
-
此外,还尽可能地覆盖激活的计算和gpu之间通过网络的通信(由于all_reduce操作)。
-
训练65b参数模型时,代码在2048 A100 GPU和80GB RAM上处理大约380个token/秒/GPU。这意味着在包含1.4T token的数据集上进行训练大约需要21天。
4 实验结果
作者主要对比了在Zero-shot、Few-shot上的结果。
4.1 常识推理(Common Sense Reasoning)
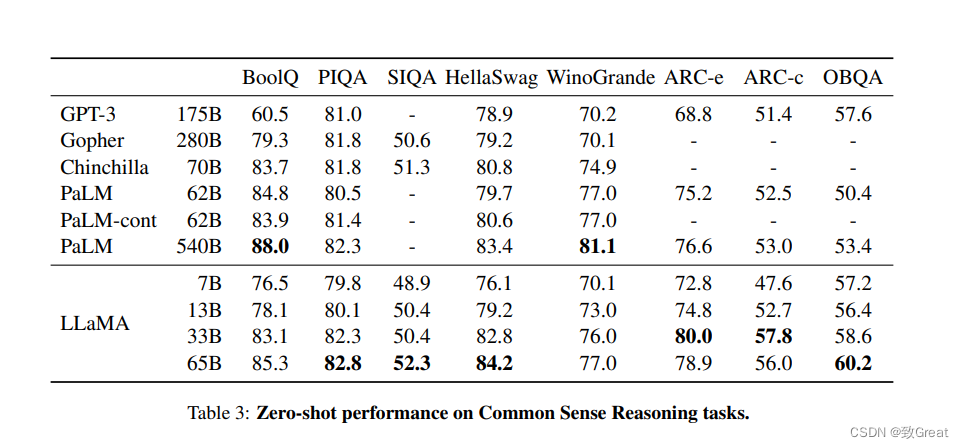
可以观察到13B和GPT-3 175B的结果实际上是非常相近的。
4.2 闭卷问答(Closed-book QA)


LLaMA模型要优于PaLM 540B模型
4.3 阅读理解(Reading Comprehension)
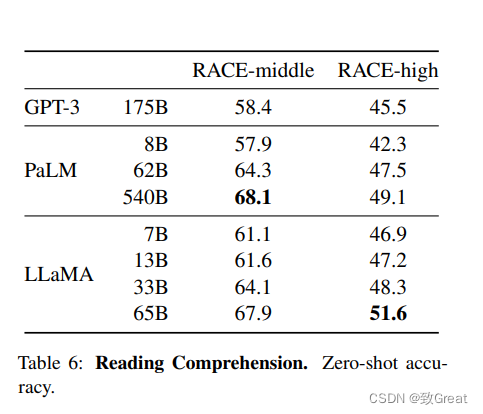
可以看到LLaMA对标到540B的PaLM。
4.4 数学推理(Mathematical reasoning)
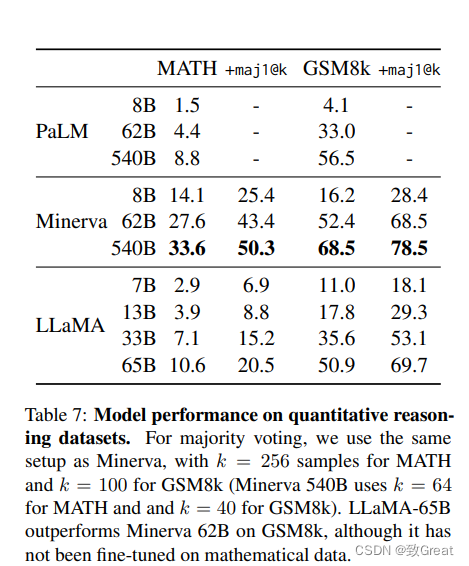
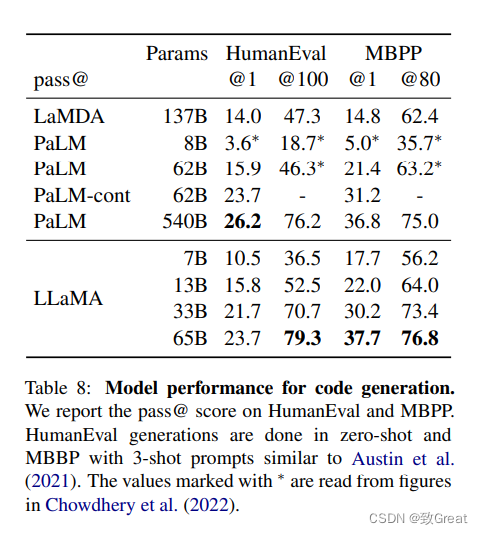
4.5 代码生成(Code generation)
4.6 大规模多任务语言理解(Massive Multitask Language Understanding)

可以观察到LLaMA-65B在大多数领域平均落后于Chinchilla70B和PaLM-540B几个百分点。一种可能的解释是,预训练数据中使用了有限数量的书籍和学术论文,即ArXiv, Gutenberg和book3,总计只有177GB,而这些模型在高达2TB的书籍上进行了训练。Gopher、Chinchilla和PaLM使用的大量书籍可能也解释了为什么Gopher在这个基准测试中表现优于GPT-3,而在其他基准测试中却不相上下
4.7 训练过程中的性能演变(Evolution of performance during training)

在训练期间,我们在一些问题回答和常识基准上跟踪了模型的性能,并在图2中报告了它们。在大多数基准测试中,性能稳步提高,并且与模型的训练困惑度相关(见图1)。例外是SIQA和WinoGrande。最值得注意的是,在SIQA上,我们观察到性能上有很多差异,这可能表明这个基准测试不可靠。在WinoGrande上,性能与训练困惑度不相关:LLaMA-33B和LLaMA-65B在训练过程中表现相似。
5 指令调优
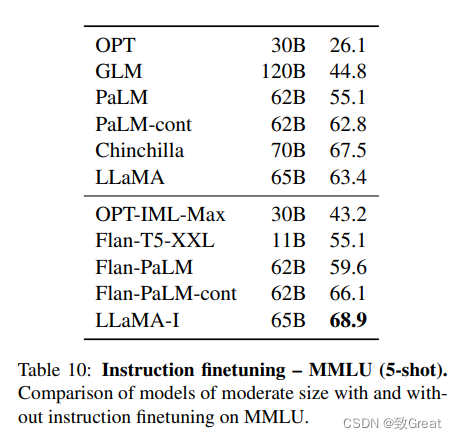
指令模型LLaMA-I在MMLU上的结果,并与现有中等规模的指令微调模型,进行了比较。尽管这里使用的指令调优方法很简单,但在MMLU上达到了68.9%。LLaMA-I (65B)在现有中等规模的指令微调模型上的表现优于MMLU,但仍远未达到最先进的水平,在MMLU上的GPT code-davincii-002为77.4。
6 模型代码
https://github.com/facebookresearch/llama/blob/main/llama/model.py
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
作者对每个Transformer子层的输入进行归一化,而不是对输出进行归一化。注意看Transformer中黄色方块(Add & Norm)部分,都是在输出部分的,现在把这个操作调整到前面对输入进行Norm操作。
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
@torch.inference_mode()
def forward(self, tokens: torch.Tensor, start_pos: int):
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full((1, 1, seqlen, seqlen), float("-inf"), device=tokens.device)
mask = torch.triu(mask, diagonal=start_pos + 1).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h[:, -1, :]) # only compute last logits
return output.float()
7 论文结论
本文中提出了一系列公开发布的语言模型,并实现与最先进的基础模型相竞争的结果。最值得注意的是,LLaMA-13B的性能优于GPT-3,但体积比GPT-3小10倍以上,LLaMA-65B与Chinchilla-70B和PaLM-540B竞争。
与之前的研究不同,论文的研究表明,不使用专有数据集,而只使用公开可用的数据集进行训练,可以达到最先进的性能。作者希望向研究界发布这些模型将加速大型语言模型的发展,并有助于提高它们的鲁棒性,减轻已知的问题,如毒性和偏见。
此外,作者像Chung等人一样观察到,根据指令对这些模型进行微调会产生有希望的结果计划在未来的工作中进一步研究这一点。
最后,作者计划在未来发布在更大的预训练语料库上训练的更大的模型,因为作者在扩展语料时已经看到了性能的不断提高
![[离散数学] 函数](https://img-blog.csdnimg.cn/2b8b696d09444c03b1bbae9fe6075fd4.png)




![NSSCTF-[深育杯 2021]Press](https://img-blog.csdnimg.cn/ffcac2e9d6e242abbd0e972387bbe105.png)