YOLOv5:解读yolo.py
- 前言
- 前提条件
- 相关介绍
- yolo.py
- parse_model()函数
- Detect类
- Model类
- 参考
前言
- 记录一下自己阅读yolo.py代码的一些重要点,方便自己查阅。特别感谢,在参考里,列举的博文链接,写得很好,对本人阅读理解yolo.py代码,有很大帮助。
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏或我的个人主页查看
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)
前提条件
- 熟悉Python
相关介绍
- Python是一种跨平台的计算机程序设计语言。是一个高层次的结合了解释性、编译性、互动性和面向对象的脚本语言。最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越多被用于独立的、大型项目的开发。
- PyTorch 是一个深度学习框架,封装好了很多网络和深度学习相关的工具方便我们调用,而不用我们一个个去单独写了。它分为 CPU 和 GPU 版本,其他框架还有 TensorFlow、Caffe 等。PyTorch 是由 Facebook 人工智能研究院(FAIR)基于 Torch 推出的,它是一个基于 Python 的可续计算包,提供两个高级功能:1、具有强大的 GPU 加速的张量计算(如 NumPy);2、构建深度神经网络时的自动微分机制。
- YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。它是一个在COCO数据集上预训练的物体检测架构和模型系列,代表了Ultralytics对未来视觉AI方法的开源研究,其中包含了经过数千小时的研究和开发而形成的经验教训和最佳实践。
yolo.py
- yolo.py是yolov5的模型搭建部分。
parse_model()函数
- parse_model函数用来解析模型文件(从Model中传来的字典形式),并搭建网络结构。
- 输入参数:
- d:model_dict,默认为解析yolov5s.yaml文件的参数,形式为字典,比如{‘nc’:80,…}
- ch:通道数,默认为[3]
- 返回参数:
- nn.Sequential(*layers): 网络的每一层的层结构
- sorted(save): 把所有层结构中from不是-1的值记下 并排序 [4, 6, 10, 14, 17, 20, 23]
def parse_model(d, ch): # model_dict, input_channels(3)
"""用在上面Model模块中
解析模型文件(字典形式),并搭建网络结构
这个函数其实主要做的就是: 更新当前层的args(参数),计算c2(当前层的输出channel) =>
使用当前层的参数搭建当前层 =>
生成 layers + save
:params d: model_dict 模型文件 字典形式 {dict:7} yolov5s.yaml中的6个元素 + ch
:params ch: 记录模型每一层的输出channel 初始ch=[3] 后面会删除
:return nn.Sequential(*layers): 网络的每一层的层结构
:return sorted(save): 把所有层结构中from不是-1的值记下 并排序 [4, 6, 10, 14, 17, 20, 23]
"""
# 日志
LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")
# 锚框, number of class, 网络深度, 网络宽度(通道)
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
# print(anchors, nc, gd, gw) # [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]] 80 0.33 0.5
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors_num * (classes_num + 5)
# 开始搭建网络
# layers: 保存每一层的层结构
# save: 记录下所有层结构中from中不是-1的层结构序号
# c2: 保存当前层的输出channel
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
# from(当前层输入来自哪些层), number(当前层次数 初定), module(当前层类别), args(当前层类参数 初定)
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
# eval(string) 得到当前层的真实类名 例如: m= Focus -> <class 'models.common.Focus'>
m = eval(m) if isinstance(m, str) else m # eval strings
# 可忽略
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except NameError:
pass
# 真正的当前层次数n = n * depth_multiple # depth gain 控制深度 如v5s: n*0.33 n: 当前模块的次数(间接控制深度)
n = n_ = max(round(n * gd), 1) if n > 1 else n # depth gain
# m 表示网络模块module
if m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,
BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:
# c1: 当前层的输入的channel数 c2: 当前层的输出的channel数(初定) ch: 记录着所有层的输出channel
c1, c2 = ch[f], args[0]
# if not output no=75 只有最后一层c2=no 最后一层不用控制宽度,输出channel必须是no
if c2 != no: # if not output
# width gain 控制宽度 如v5s: c2*0.5 c2: 当前层的最终输出的channel数(间接控制宽度)
c2 = make_divisible(c2 * gw, 8)
# 在初始arg的基础上更新 加入当前层的输入channel并更新当前层
# [in_channel, out_channel, *args[1:]]
args = [c1, c2, *args[1:]]
# 如果当前层是BottleneckCSP/C3/C3TR, 则需要在args中加入bottleneck的个数
# [in_channel, out_channel, Bottleneck的个数n, bool(True表示有shortcut 默认,反之无)]
if m in [BottleneckCSP, C3, C3TR, C3Ghost]:
args.insert(2, n) # number of repeats # 在第二个位置插入bottleneck个数n
n = 1 # 恢复默认值1
elif m is nn.BatchNorm2d:
args = [ch[f]] # BN层只需要返回上一层的输出channel
elif m is Concat:
c2 = sum(ch[x] for x in f) # Concat层则将f中所有的输出累加得到这层的输出channel
elif m is Detect: # Detect(YOLO Layer)层
args.append([ch[x] for x in f]) # 在args中加入三个Detect层的输出channel
if isinstance(args[1], int): # number of anchors # number of anchors 几乎不执行
args[1] = [list(range(args[1] * 2))] * len(f)
elif m is Contract: # 不怎么用
c2 = ch[f] * args[0] ** 2
elif m is Expand: # 不怎么用
c2 = ch[f] // args[0] ** 2
else: # Upsample
c2 = ch[f] # args不变
# m_: 得到当前层module 如果n>1就创建多个m(当前层结构), 如果n=1就创建一个m
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
# 打印当前层结构的一些基本信息 # t = module type 'modules.common.Focus'
t = str(m)[8:-2].replace('__main__.', '') # module type
# number params 计算这一层的参数量
np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
LOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # print
# append to savelist 把所有层结构中from不是-1的值记下 [6, 4, 14, 10, 17, 20, 23]
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
# 将当前层结构module加入layers中
layers.append(m_)
if i == 0: # 第一层
ch = [] # 去除输入channel [3]
# 把当前层的输出channel数加入ch
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
Detect类
- Detect类是用来构建Detect层的,将输入feature map 通过一个卷积操作和公式计算到我们想要的shape,为后面的计算损失或者NMS作准备。
- yolov3
- yolov5
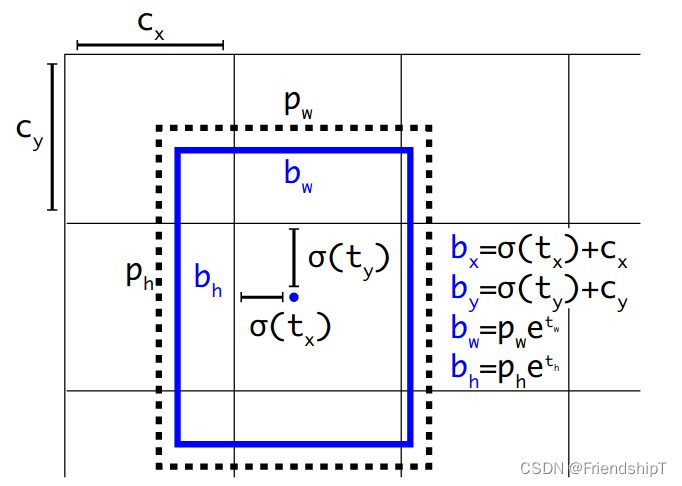
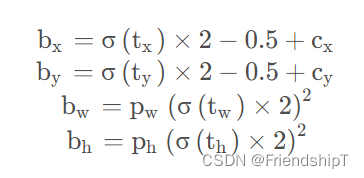

class Detect(nn.Module):
"""Detect模块是用来构建Detect层的,将输入feature map 通过一个卷积操作和公式计算到我们想要的shape, 为后面的计算损失或者NMS作准备"""
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
"""
detection layer 相当于yolov3中的YOLOLayer层
:params nc: number of classes
:params anchors: 传入3个feature map上的所有anchor的大小(P3、P4、P5)
:params ch: [128, 256, 512] 3个输出feature map的channel
"""
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor = number of classes + x_y_w_h_confidence_num,例如voc为20+5=25
self.nl = len(anchors) # number of detection layers # 默认为3
self.na = len(anchors[0]) // 2 # number of anchors # 默认为3
self.grid = [torch.zeros(1)] * self.nl # init grid # [tensor([0.]), tensor([0.]), tensor([0.])]
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid # [tensor([0.]), tensor([0.]), tensor([0.])]
# anchors:list列表 -> torch.tensor张量 -> float()浮点数值 -> view()重构维度shape(nl,na,2)=(3,3,2)
# anchors以[w, h]对的形式存储 3个feature map 每个feature map上有三个anchor(w,h)
# register_buffer
# 模型中需要保存的参数一般有两种:一种是反向传播需要被optimizer更新的,称为parameter; 另一种不要被更新称为buffer
# buffer的参数更新是在forward中,而optim.step只能更新nn.parameter类型的参数
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
# output conv 对每个输出的feature map都要调用一次conv1x1
# nn.ModuleList是一个包含子模块的列表,可以像普通Python列表一样进行索引,但其中包含的模块已经正确注册,并且将由所有Module方法显示。
# nn.Conv2d(in_channels=x, out_channels=self.no * self.na, kernel_size=1, stride=1, padding=1)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
# use in-place ops (e.g. slice assignment) 一般都是True 默认不使用AWS Inferentia加速
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
"""
:return train: 一个tensor list 存放三个元素 [bs, anchor_num, grid_w, grid_h, xywh+c+classes_num]
分别是 [1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25]
inference: 0 [1, 19200+4800+1200, 25] = [bs, anchor_num*grid_w*grid_h, xywh+c+classes_num]
1 一个tensor list 存放三个元素 [bs, anchor_num, grid_w, grid_h, xywh+c+classes_num]
[1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25]
"""
z = [] # inference output
for i in range(self.nl): # 对3个feature map分别进行处理
x[i] = self.m[i](x[i]) # conv xi[bs, 128/256/512, 80, 80] to [bs, self.no * self.na, 80, 80]
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85) 这个是以nc=80为例
# [bs, 75, 80, 80] to [1, 3, 25, 80, 80] to [1, 3, 80, 80, 25] 这个是以nc=20为例
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
# 构造网格
# 因为推理返回的不是归一化后的网格偏移量 需要再加上网格的位置 得到最终的推理坐标 再送入nms
# 所以这里构建网格就是为了记录每个grid的网格坐标 方面后面使用
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
# 默认执行 不使用AWS Inferentia
# 这里的公式和yolov3、v4中使用的不一样 是yolov5作者自己用的 效果更好
y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
# y[..., 2:4] = torch.exp(y[..., 2:4]) * self.anchor_wh # wh yolo method
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh power method
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xy
wh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, y[..., 4:]), -1)
# z是一个tensor list 三个元素 分别是[1, 19200, 25] [1, 4800, 25] [1, 1200, 25]
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device # 使用硬件设备cpu or cuda:0 ...
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)], indexing='ij')
else:
yv, xv = torch.meshgrid([torch.arange(ny, device=d), torch.arange(nx, device=d)])
grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()
anchor_grid = (self.anchors[i].clone() * self.stride[i]) \
.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()
return grid, anchor_grid
Model类
- Model类是整个模型的搭建模块。主要看__init__()和forward()两个函数即可。
- 输入参数:
- cfg:模型配置文件,默认为’yolov5s.yaml’
- ch:输入图片通道数,默认为3
- nc: number of classes 数据集的类别个数
- forword()返回参数:
- 训练training: 一个tensor list 存放三个元素
[bs, anchor_num, grid_w, grid_h, xywh+confidence+classes_num]
即为:
[[1, 3, 80, 80, 20(VOC类别数)+5(x_y_w_h_confidence)]
[1, 3, 40, 40, 20(VOC类别数)+5(x_y_w_h_confidence)]
[1, 3, 20, 20, 20(VOC类别数)+5(x_y_w_h_confidence)]]- 推理inference:
- 0:[1, 19200+4800+1200, 20+5] =
[bs, anchor_num * grid_w * grid_h, xywh+confidence+classes_num]- 1:一个tensor list 存放三个元素
[bs, anchor_num, grid_w, grid_h, xywh+confidence+classes_num]
即为:
[[1, 3, 80, 80, 20(VOC类别数)+5(x_y_w_h_confidence)]
[1, 3, 40, 40, 20(VOC类别数)+5(x_y_w_h_confidence)]
[1, 3, 20, 20, 20(VOC类别数)+5(x_y_w_h_confidence)]]
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
"""
:params cfg:模型配置文件
:params ch: input img channels 一般是3 RGB文件
:params nc: number of classes 数据集的类别个数
:anchors: 一般是None
"""
super().__init__()
# 解析yolov5s.yaml里的参数,返回一个字典形式
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg, encoding='ascii', errors='ignore') as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels 默认是3通道
# nc日志,# 设置类别数 一般不执行, 因为nc=self.yaml['nc']恒成立
if nc and nc != self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
# anchors日志,重写anchor,一般不执行, 因为传进来的anchors一般都是None
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
# 创建网络模型
# self.model: 初始化的整个网络模型(包括Detect层结构)
# self.save: 所有层结构中from不等于-1的序号,并排好序 [4, 6, 10, 14, 17, 20, 23]
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist
# default class names ['0', '1', '2',..., '19']
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
# self.inplace=True 默认True 不使用加速推理
# AWS Inferentia Inplace compatiability
# https://github.com/ultralytics/yolov5/pull/2953
self.inplace = self.yaml.get('inplace', True)
# Build strides, anchors
# 获取Detect模块的stride(相对输入图像的下采样率)和anchors在当前Detect输出的feature map的尺度
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 256 # 2x min stride
m.inplace = self.inplace
# 计算三个feature map下采样的倍率 [8, 16, 32]
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
# 求出相对当前feature map的anchor大小 如[10, 13]/8 -> [1.25, 1.625]
m.anchors /= m.stride.view(-1, 1, 1)
# 检查anchor顺序与stride顺序是否一致
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once 初始化偏置
# Init weights, biases
initialize_weights(self) # 调用torch_utils.py下initialize_weights初始化模型权重
self.info() # 打印模型信息
LOGGER.info('')
def forward(self, x, augment=False, profile=False, visualize=False):
if augment: # 是否在测试时也使用数据增强 Test Time Augmentation(TTA)
return self._forward_augment(x) # augmented inference, None 上下flip/左右flip
# 默认执行 正常前向推理
return self._forward_once(x, profile, visualize) # single-scale inference, train
def _forward_augment(self, x):
"""
TTA Test Time Augmentation
"""
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)=(2-ud上下flip, 3-lr左右flip)
y = [] # outputs
for si, fi in zip(s, f):
# scale_img缩放图片尺寸
xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))
yi = self._forward_once(xi)[0] # forward
# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
# _descale_pred将推理结果恢复到相对原图图片尺寸
yi = self._descale_pred(yi, fi, si, img_size)
y.append(yi)
y = self._clip_augmented(y) # clip augmented tails
return torch.cat(y, 1), None # augmented inference, train
def _forward_once(self, x, profile=False, visualize=False):
"""
:params x: 输入图像
:params profile: True 可以做一些性能评估
:params feature_vis: True 可以做一些特征可视化
:return train: 一个tensor list 存放三个元素 [bs, anchor_num, grid_w, grid_h, xywh+c+20classes]
分别是 [1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25]
inference: 0 [1, 19200+4800+1200, 25] = [bs, anchor_num*grid_w*grid_h, xywh+c+20classes]
1 一个tensor list 存放三个元素 [bs, anchor_num, grid_w, grid_h, xywh+c+20classes]
[1, 3, 80, 80, 25] [1, 3, 40, 40, 25] [1, 3, 20, 20, 25]
"""
# y: 存放着self.save=True的每一层的输出,因为后面的层结构concat等操作要用到
# dt: 在profile中做性能评估时使用
y, dt = [], [] # outputs
for m in self.model:
# 前向推理每一层结构 m.i=index m.f=from m.type=类名 m.np=number of params
# if not from previous layer m.f=当前层的输入来自哪一层的输出 s的m.f都是-1
if m.f != -1: # if not from previous layer
# 这里需要做4个concat操作和1个Detect操作
# concat操作如m.f=[-1, 6] x就有两个元素,一个是上一层的输出,另一个是index=6的层的输出 再送到x=m(x)做concat操作
# Detect操作m.f=[17, 20, 23] x有三个元素,分别存放第17层第20层第23层的输出 再送到x=m(x)做Detect的forward
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
# 打印日志信息 FLOPs time等
if profile:
self._profile_one_layer(m, x, dt)
x = m(x) # run # run正向推理
# 存放着self.save的每一层的输出,因为后面需要用来作concat等操作要用到 不在self.save层的输出就为Non
y.append(x if m.i in self.save else None) # save output
# 特征可视化 可以自己改动想要哪层的特征进行可视化
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
return x
def _descale_pred(self, p, flips, scale, img_size):
# de-scale predictions following augmented inference (inverse operation)
if self.inplace:
p[..., :4] /= scale # de-scale
if flips == 2:
p[..., 1] = img_size[0] - p[..., 1] # de-flip ud
elif flips == 3:
p[..., 0] = img_size[1] - p[..., 0] # de-flip lr
else:
x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scale
if flips == 2:
y = img_size[0] - y # de-flip ud
elif flips == 3:
x = img_size[1] - x # de-flip lr
p = torch.cat((x, y, wh, p[..., 4:]), -1)
return p
def _clip_augmented(self, y):
# Clip YOLOv5 augmented inference tails
nl = self.model[-1].nl # number of detection layers (P3-P5)
g = sum(4 ** x for x in range(nl)) # grid points
e = 1 # exclude layer count
i = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indices
y[0] = y[0][:, :-i] # large
i = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indices
y[-1] = y[-1][:, i:] # small
return y
def _profile_one_layer(self, m, x, dt):
c = isinstance(m, Detect) # is final layer, copy input as inplace fix
o = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPs
t = time_sync()
for _ in range(10):
m(x.copy() if c else x)
dt.append((time_sync() - t) * 100)
if m == self.model[0]:
LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")
LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')
if c:
LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# https://arxiv.org/abs/1708.02002 section 3.3
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
LOGGER.info(
('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
LOGGER.info('Fusing layers... ')
for m in self.model.modules():
if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
delattr(m, 'bn') # remove batchnorm
m.forward = m.forward_fuse # update forward
self.info()
return self
def info(self, verbose=False, img_size=640): # print model information
model_info(self, verbose, img_size)
def _apply(self, fn):
# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffers
self = super()._apply(fn)
m = self.model[-1] # Detect()
if isinstance(m, Detect):
m.stride = fn(m.stride)
m.grid = list(map(fn, m.grid))
if isinstance(m.anchor_grid, list):
m.anchor_grid = list(map(fn, m.anchor_grid))
return self
参考
[1] https://github.com/ultralytics/yolov5
[2] 【YOLOV5-5.x 源码解读】yolo.py_yolov5 yolo.py_满船清梦压星河HK的博客-CSDN博客
[3] YOLOV5-预测结果解码流程 - 知乎 (zhihu.com)
[4] 目标检测 YOLOv5 边框预测(bounding box prediction)_yolov5的边框预测公式_西西弗Sisyphus的博客-CSDN博客
- 记录一下自己阅读yolo.py代码的一些重要点,方便自己查阅。特别感谢,在参考里,列举的博文链接,写得很好,对本人阅读理解yolo.py代码,有很大帮助。
- 由于本人水平有限,难免出现错漏,敬请批评改正。
- 更多精彩内容,可点击进入YOLO系列专栏或我的个人主页查看
- YOLOv5:添加SE、CBAM、CoordAtt、ECA注意力机制
- YOLOv5:yolov5s.yaml配置文件解读、增加小目标检测层
- YOLOv5:IoU、GIoU、DIoU、CIoU、EIoU
- YOLOv7训练自己的数据集(口罩检测)
- YOLOv8训练自己的数据集(足球检测)