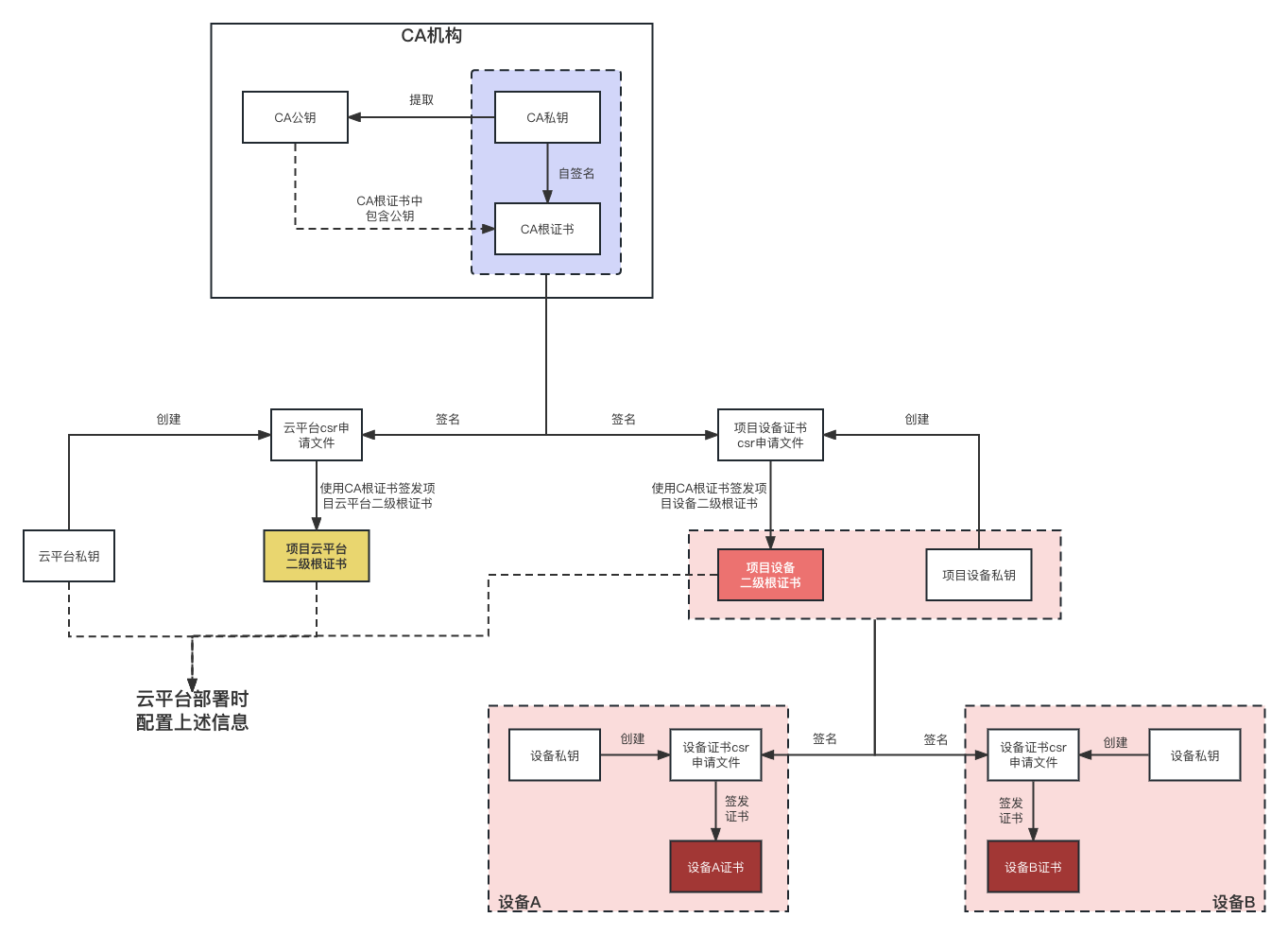
1 问题
在学习深度学习的过程中,欲探究激活函数Relu对精度和损失的影响。
2 方法
测试设置激活函数时和没有设置激活函数时网络的性能。
控制其余变量:
Beach_size=128
optimizer = torch.optim.SGD
网络为三层全连接网络(784->512->10)
训练周期=50
测试代码如下
| from torchvision import datasets from torchvision.transforms import ToTensor from torch import nn import torch from torch.utils.data import DataLoader import torch.nn.functional as F import matplotlib.pyplot as plt from collections import defaultdict # (5)定义三层全连接网络 # (5.1)创建一个新的类继承nn.Module class MyNet(nn.Module): # (5.2) 定义网络有哪些层,这些层都作为成员变量 def __init__(self) -> None: super().__init__() # 第一层,第一个全连接层Full Connection(FC) # in_features表示该层的前面一层神经元个数 # out_features表示当前这的一层神经元个数 # 对应图里面layer2 self.fc1 = nn.Linear(in_features=784, out_features=512) # in_features就是这一层的输入是多少纬的向量, # 对应layer3 也是就输出层 self.fc2 = nn.Linear(in_features=512, out_features=10) # feature特征 # (5.3) 定义数据在网络中的流动 x就表示输入 # x - 28*28的图像 def forward(self, x): x=torch.flatten(x,1) x = self.fc1(x) # 输出:512,Layer 2 # x=F.relu(x) out = self.fc2(x) # 输出:10,Layer 3 return out #(7)训练网络 #loss_list:记录每一个周期的平均loss数据 def train(dataloader,net,loss_fn,optimizer): size = len((dataloader.dataset)) epoch_loss=0.0 batch_num=len(dataloader)#有多少个batch net.train() correct = 0 #准确率 #一个batch一个batch的训练网络 for batch_ind, (X,y) in enumerate(dataloader): X,y=X.to(device),y.to(device) #gpu上运行X,y pred = net(X) #衡量y与y_hat之前的loss #y:128 ,pred:128*10 CrossEntropyLoss处理的 loss=loss_fn(pred,y) #基于loss信息利用优化器从后向前更新网络的全部参数 optimizer.zero_grad() loss.backward() optimizer.step() # print(f"batch index: {ind},loss:{loss.item()}")#item()方法将单个tensor转化成一个数字 epoch_loss+=loss.item() #每一个batch产生一个loss correct+=(pred.argmax(1)==y).type(torch.float).sum().item() #f-str if batch_ind % 100==0: print(f'[{batch_ind+1 :>5d} / {batch_num :>5d}], loss:{loss.item()}') #统计一个周期的平均loss avg_loss=epoch_loss/batch_num avg_accurcy = correct / size return avg_accurcy,avg_loss def test(dataloder,net,loss): size=len(dataloder.dataset) batch_num = len(dataloder) net.eval() losses=0 correct = 0 with torch.no_grad(): for X,y in dataloder: X,y = X.to(device),y.to(device) pred = net(X) loss = loss_fn(pred,y) losses+=loss.item() #一个batch产生一个loss correct+=(pred.argmax(1) ==y).type(torch.int).sum().item() accuracy = correct / size avg_loss = losses /batch_num print(f'accuracy is {accuracy*100}%') return accuracy,avg_loss #数据的获取 class getData: def __init__(self): self.train_ds = datasets.MNIST( root='data', download=True, train=True, transform=ToTensor(), # 将原始的数据格式(PIL)转换为Tensor格式 ) # 测试集:评估模型的性能/效果 self.text_ds = datasets.MNIST( root='data', download=True, train=False, transform=ToTensor(), ) # print(train_ds[0]) # print(text_ds[0]) # (3) self.train_loader = DataLoader( dataset=self.train_ds, batch_size=128, # 将60000个数据分成每一段的大小是128 shuffle=True, # 每一次我去拿那个128的数据都是打乱的,不是有序的。1-60000 打乱数据的次序,一般用于训练集,不需要在测试集 ) # (4) # 训练集共有469个batch 469*128 # print("训练集的batch{}".format(len(train_loader))) self.test_loader = DataLoader( dataset=self.text_ds, batch_size=128, ) if __name__=='__main__': #(0)测试机器是否支持GPU batch_size=128 device='cuda' if torch.cuda.is_available() else 'cpu' # print(device) train_ds = datasets.MNIST( root='data', download=True, train=True, transform=ToTensor(), # 将原始的数据格式(PIL)转换为Tensor格式 ) # 测试集:评估模型的性能/效果 text_ds = datasets.MNIST( root='data', download=True, train=False, transform=ToTensor(), ) #(1.1)将训练集划分为训练集+验证集 train_ds,val_ds= torch.utils.data.random_split(train_ds,[50000,10000]) # (3) train_loader = DataLoader( dataset=train_ds, batch_size=batch_size, # 将60000个数据分成每一段的大小是128 shuffle=True, # 每一次我去拿那个128的数据都是打乱的,不是有序的。1-60000 打乱数据的次序,一般用于训练集,不需要在测试集 ) val_loder = DataLoader( dataset=val_ds, batch_size=batch_size, ) # (4) # 训练集共有469个batch 469*128 # print("训练集的batch{}".format(len(train_loader))) test_loader = DataLoader( dataset=text_ds, batch_size=batch_size, ) #(6)网络的输入、输出以及测试网络的性能(不经过任何训练的网络) net=MyNet().to(device)#to()GPU上运行该网络 #网络训练模型 #X, 真实的标签y, 网络预测的标签y_hat #目标: y_hat越来越接近y #算法:mini-bacth 梯度下降 #优化器 #具体实现梯度下降算法的传播 #SGD随机梯度下降学习度 #y=ax+b optimizer=torch.optim.SGD(net.parameters(),lr=0.15) #损失函数 #衡量yy与y_hat之前的差异 loss_fn=nn.CrossEntropyLoss() #训练一下 # train(train_loader,net,loss_fn,optimizer) #一个周期表示一个完整的训练集 #训练100个周期epoch train_loss=[] #记录所有周期的平均loss train_acc_list,train_loss_list,val_acc_list,val_loss_list=[],[],[],[] #找出周期内最好的模型 #评价标准:验证集的精度 best_acc=0 for epoch in range(50): print('-'*50) print(f'eopch:{epoch+1}') train_accuracy,train_loss=train(train_loader,net,loss_fn,optimizer) val_accuracy,val_loss =test(train_loader,net,loss_fn) print(f'train acc:{train_accuracy},train_val:{train_loss}') train_acc_list.append(train_accuracy) train_loss_list.append(train_loss) val_acc_list.append(val_accuracy) val_loss_list.append(val_loss) if val_accuracy > best_acc: best_acc = val_accuracy #保存当前模型 torch.save(net.state_dict(),'model_best.pth') #(7)评估模型` #加载最好的模型 net.load_state_dict(torch.load('model_best.pth')) print('the best val_acc is:') test(test_loader,net,loss_fn) plt.figure() ax1=plt.subplot(121) plt.plot([i for i in range(len(train_acc_list))],train_acc_list,ls='-',c='b') plt.title('accuracy') plt.xlabel('epoch') plt.ylabel('number') ax = plt.subplot(122) plt.plot([i for i in range(len(train_loss_list))], train_loss_list, ls='-', c='b') plt.title('loss') plt.xlabel('epoch') plt.ylabel('number') plt.show() |
最后无激活函数时结果如图所示:
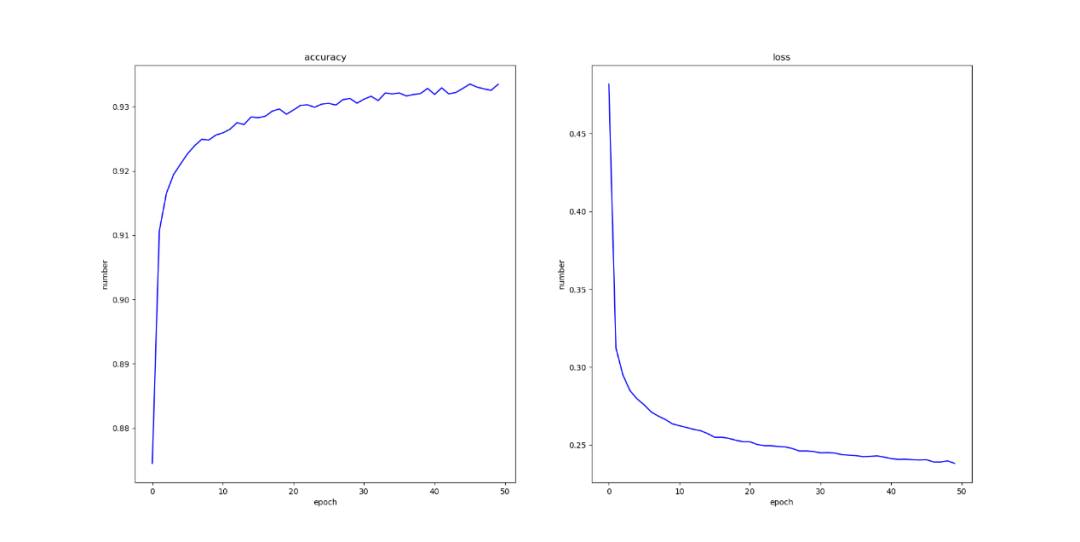
有激活函数时结果如图所示:
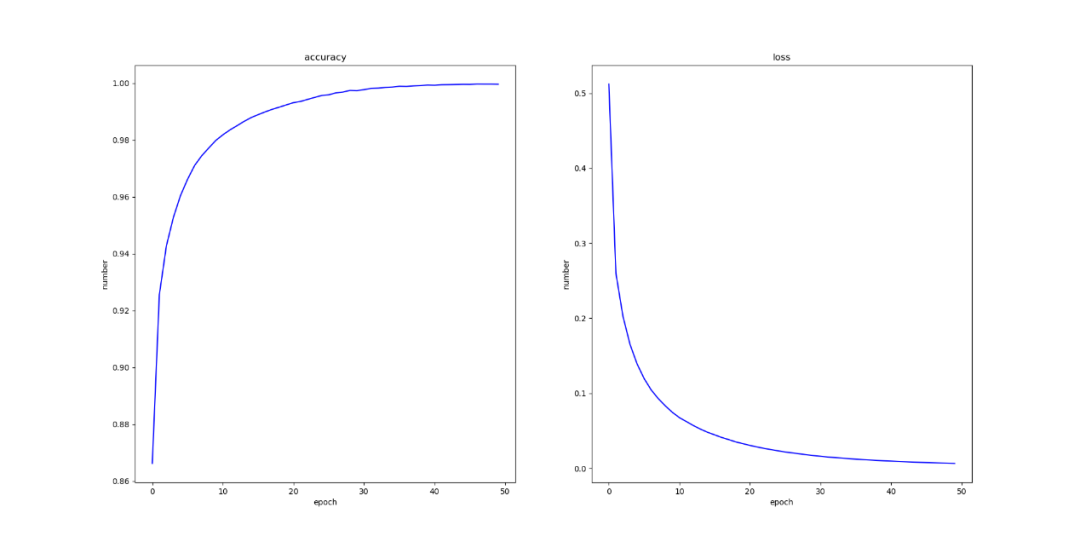
3 结语
通过实验发现,在未使用激活函数时,通过不断地训练模型,模型的准确率和损失率都时比较稳定地上升和下降,但是在上升和下降地过程中会出现抖动地情况,但是使用激活函数之后,模型的准确率和损失率就会上升和下降的非常平滑,更有利于实验的进行,以及对模型行为的预测。