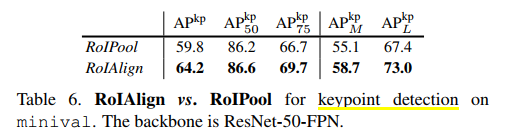
分类目录:《深入理解深度学习》总目录
正则化在深度学习的出现前就已经被使用了数十年。线性模型,如线性回归和逻辑回归可以使用简单、直接、有效的正则化策略。许多正则化方法通过对目标函数
J
J
J添加一个参数范数惩罚
Ω
(
θ
)
\Omega(\theta)
Ω(θ)限制模型的学习能力。我们将正则化后的目标函数记为:
J
~
(
θ
;
X
,
y
)
=
J
(
θ
;
X
,
y
)
+
α
Ω
(
θ
)
\tilde{J}(\theta;X, y) = J(\theta;X, y) + \alpha\Omega(\theta)
J~(θ;X,y)=J(θ;X,y)+αΩ(θ)
其中 α ∈ [ 0 , + ∞ ] \alpha\in[0, +\infty] α∈[0,+∞]是权衡范数惩罚项 Ω \Omega Ω和标准目标函数 J ( θ ; X , y ) J(\theta;X, y) J(θ;X,y)相对贡献的超参数。将 α \alpha α设为 0 0 0表示没有正则化。 α \alpha α越大,对应正则化惩罚越大。当我们的训练算法最小化正则化后的目标函数 J ~ \tilde{J} J~时,它会降低原始目标 J J J关于训练数据的误差并同时减小在某些衡量标准下参数 θ \theta θ(或参数子集)的规模。选择不同的参数范数 Ω \Omega Ω会偏好不同的解。在探究不同范数的正则化表现之前,我们需要说明一下,在神经网络中,参数包括每一层仿射变换的权重和偏置,我们通常只对权重做惩罚而不对偏置做正则惩罚。精确拟合偏置所需的数据通常比拟合权重少得多。每个权重会指定两个变量如何相互作用。我们需要在各种条件下观察这两个变量才能良好地拟合权重。而每个偏置仅控制一个单变量。这意味着,我们不对其进行正则化也不会导致太大的方差。另外,正则化偏置参数可能会导致明显的欠拟合。因此,我们使用向量 w w w表示所有应受范数惩罚影响的权重,而向量 θ \theta θ表示所有参数 (包括 w w w和无需正则化的参数)。在神经网络的情况下,有时希望对网络的每一层使用单独的惩罚,并分配不同的 α \alpha α系数。寻找合适的多个超参数的代价很大,因此为了减少搜索空间,我们会在所有层使用相同的权重衰减。
L 1 L^1 L1正则化
对模型参数
w
w
w的
L
1
L^1
L1正则化被定义为:
Ω
(
θ
)
=
∣
∣
w
∣
∣
1
=
∑
i
∣
w
i
∣
\Omega(\theta) = ||w||_1 = \sum_i|w_i|
Ω(θ)=∣∣w∣∣1=i∑∣wi∣
因此,
L
1
L^1
L1正则化的目标函数
J
~
(
w
;
X
,
y
)
\tilde{J}(w;X, y)
J~(w;X,y)为:
J
~
(
w
;
X
,
y
)
=
J
(
w
;
X
,
y
)
+
α
2
w
T
w
\tilde{J}(w;X, y) = J(w;X, y) + \frac{\alpha}{2}w^Tw
J~(w;X,y)=J(w;X,y)+2αwTw
对应的梯度:
∇
w
J
~
(
w
;
X
,
y
)
=
∇
w
J
(
w
;
X
,
y
)
+
α
sign
(
w
)
\nabla_w\tilde{J}(w;X, y) = \nabla_wJ(w;X, y) + \alpha\text{sign}(w)
∇wJ~(w;X,y)=∇wJ(w;X,y)+αsign(w)
其中
sign
(
w
)
\text{sign}(w)
sign(w)只是简单地取
w
w
w各个元素的正负号。具体来说,我们可以看到正则化对梯度的影响不再是线性地缩放每个
w
i
w_i
wi,而是添加了一项与
sign
(
w
)
\text{sign}(w)
sign(w)同号的常数。使用这种形式的梯度之后,我们不一定能得到
J
(
w
;
X
,
y
)
J(w;X, y)
J(w;X,y)二次近似的直接解析解。简单线性模型具有二次代价函数,我们可以通过泰勒级数表示。或者我们可以设想,这是逼近更复杂模型的代价函数的截断泰勒级数。在这个设定下,梯度为:
∇
w
J
~
(
w
;
X
,
y
)
=
H
(
w
−
w
∗
)
\nabla_w\tilde{J}(w;X, y) = H(w - w^*)
∇wJ~(w;X,y)=H(w−w∗)
其中, H H H是 J J J在 w ∗ w^∗ w∗处关于 w w w的Hessian矩阵。由于 L 1 L^1 L1惩罚项在完全一般化的Hessian的情况下,无法得到直接清晰的代数表达式,因此我们将进一步简化假设Hessian是对角的,即 H = diag ( [ H 1 , 1 , ⋯ , H n , n ] ) H = \text{diag}([H_{1,1}, \cdots, H_{n,n}]) H=diag([H1,1,⋯,Hn,n]),其中每个 H i , i > 0 H_{i,i} > 0 Hi,i>0。如果线性回归问题中的数据已被预处理(如可以使用 PCA),去除了输入特征之间的相关性,那么这一假设成立。
我们可以将
L
1
L^1
L1正则化目标函数的二次近似分解成关于参数的求和:
J
^
(
w
;
X
,
y
)
=
J
(
w
∗
;
X
,
y
)
+
∑
i
[
1
2
H
i
,
i
(
w
−
w
∗
)
2
+
α
∣
w
i
∣
]
\hat{J}(w;X, y) = J(w^*;X, y) + \sum_i[\frac{1}{2}H_{i,i}(w - w^*)^2+\alpha|w_i|]
J^(w;X,y)=J(w∗;X,y)+i∑[21Hi,i(w−w∗)2+α∣wi∣]
如下列形式的解析解(对每一维
i
i
i)可以最小化这个近似代价函数:
w
i
=
sign
(
w
i
∗
)
max
{
∣
w
i
∗
−
α
H
i
,
i
,
0
∣
}
w_i = \text{sign}(w_i^*)\max\{|w^*_i - \frac{\alpha}{H_{i, i}}, 0|\}
wi=sign(wi∗)max{∣wi∗−Hi,iα,0∣}
对每个 i i i,考虑 w i ∗ > 0 w^∗_i > 0 wi∗>0的情形,会有两种可能结果:
- w i ∗ ≤ α H i , i w^∗_i \leq\frac{\alpha}{H_{i, i}} wi∗≤Hi,iα:正则化后目标中的 w i w_i wi最优值是 w i = 0 w_i=0 wi=0。这是因为在方向 i i i上 J ( w ; X , y ) J(w; X, y) J(w;X,y)对 J ^ ( w ; X , y ) \hat{J}(w; X, y) J^(w;X,y)的贡献被抵消, L 1 L^1 L1正则化项将 w i w_i wi推至0。
- w i ∗ > α H i , i w^∗_i >\frac{\alpha}{H_{i, i}} wi∗>Hi,iα:在这种情况下,正则化不会将 w i w_i wi的最优值推至0,而仅仅在那个方向上移动 α H i , i \frac{\alpha}{H_{i, i}} Hi,iα的距离。
w i ∗ < 0 w^∗_i < 0 wi∗<0的情况与之类似,但是 L 1 L^1 L1惩罚项使 w i w_i wi更接近0(增加 α H i , i \frac{\alpha}{H_{i, i}} Hi,iα) 或者为0。相比 L 2 L^2 L2正则化, L 1 L^1 L1正则化会产生更稀疏(Sparse)的解。此处稀疏性指的是最优值中的一些参数为0。和 L 2 L^2 L2正则化相比, L 1 L^1 L1正则化的稀疏性具有本质的不同。
由 L 1 L^1 L1正则化导出的稀疏性质已经被广泛地用于特征选择(Feature Selection)机制。特征选择从可用的特征子集选择出有意义的特征,化简机器学习问题。著名的LASSO (Least Absolute Shrinkage and Selection Operator)模型将 L 1 L^1 L1惩罚和线性模型结合,并使用最小二乘代价函数。 L 1 L^1 L1惩罚使部分子集的权重为零,表明相应的特征可以被安全地忽略。
L 2 L^2 L2正则化
L
2
L^2
L2正则化策略通过向
目标函数添加一个正则项:
Ω
(
θ
)
=
1
2
∣
∣
w
∣
∣
2
\Omega(\theta) = \frac{1}{2}||w||^2
Ω(θ)=21∣∣w∣∣2
,使权重更加接近原点。同时, L 2 L^2 L2也被称为岭回归(Ridge Regression)或Tikhonov正则(Tikhonov Regularization)。我们可以通过研究正则化后目标函数的梯度,洞察一些权重衰减的正则化表现。
为了简单起见,我们假定其中没有偏置参数,因此
θ
\theta
θ就是
∣
∣
w
∣
∣
||w||
∣∣w∣∣。这样一个模型具有以下总的目标函数:
J
~
(
w
;
X
,
y
)
=
J
(
w
;
X
,
y
)
+
α
2
w
T
w
\tilde{J}(w;X, y) = J(w;X, y) + \frac{\alpha}{2}w^Tw
J~(w;X,y)=J(w;X,y)+2αwTw
与之对应的梯度为:
∇
w
J
~
(
w
;
X
,
y
)
=
∇
w
J
(
w
;
X
,
y
)
+
α
w
\nabla_w\tilde{J}(w;X, y) = \nabla_wJ(w;X, y) + \alpha w
∇wJ~(w;X,y)=∇wJ(w;X,y)+αw
使用单步梯度下降更新权重,即执行以下更新:
w
=
w
−
ϵ
(
∇
w
J
(
w
;
X
,
y
)
+
α
w
)
=
(
1
−
ϵ
α
)
w
−
ϵ
(
∇
w
J
(
w
;
X
,
y
)
w = w - \epsilon(\nabla_wJ(w;X, y) + \alpha w) = (1 - \epsilon\alpha)w - \epsilon(\nabla_wJ(w;X, y)
w=w−ϵ(∇wJ(w;X,y)+αw)=(1−ϵα)w−ϵ(∇wJ(w;X,y)
我们可以看到,加入权重衰减后会引起学习规则的修改,即在每步执行通常的梯度更新之前先收缩权重向量(将权重向量乘以一个常数因子)。这是单个步骤发生的变化。我们进一步简化分析,令
w
∗
w^∗
w∗为未正则化的目标函数取得最小训练误差时的权重向量,即
w
∗
=
arg
min
w
J
(
w
)
w^∗ = \arg\min_wJ(w)
w∗=argminwJ(w),并在
w
∗
w^∗
w∗的邻域对目标函数做二次近似。如果目标函数确实是二次的(如以均方误差拟合线性回归模型的情况),则该近似是完美的。近似的
J
^
(
θ
)
\hat{J}(\theta)
J^(θ)如下:
J
^
(
θ
)
=
J
(
w
∗
)
+
1
2
(
w
−
w
∗
)
+
H
(
w
−
w
∗
)
\hat{J}(\theta) = J(w^*) + \frac{1}{2}(w - w^*) + H(w - w^*)
J^(θ)=J(w∗)+21(w−w∗)+H(w−w∗)
其中,
H
H
H是
J
J
J在
w
∗
w^∗
w∗处计算的Hessian矩阵(关于
w
w
w)。因为
w
∗
w^∗
w∗被定义为最优,即梯度消失为0,所以该二次近似中没有一阶项。同样地,因为
w
∗
w^∗
w∗是
J
J
J的一个最优点,我们可以得出
H
H
H是半正定的结论。当
J
^
\hat{J}
J^取得最小时,其梯度:
∇
w
J
(
w
)
=
H
(
w
−
w
∗
)
\nabla_wJ(w) = H(w - w^*)
∇wJ(w)=H(w−w∗)
为 0。为了研究权重衰减带来的影响,我们在上式中添加权重衰减的梯度。现在我们探讨最小化正则化后的
J
^
\hat{J}
J^。我们使用变量
w
~
\tilde{w}
w~表示此时的最优点:
α
w
~
+
H
(
w
−
w
∗
)
=
0
(
H
+
α
I
)
w
~
=
H
w
∗
w
~
=
(
H
+
α
I
)
−
1
H
w
∗
\begin{align*} \alpha\tilde{w} + H(w-w^*) = 0 \\ (H + \alpha I)\tilde{w} = Hw^* \\ \tilde{w} = (H + \alpha I)^{-1}Hw^* \end{align*}
αw~+H(w−w∗)=0(H+αI)w~=Hw∗w~=(H+αI)−1Hw∗
当
α
\alpha
α趋向于
0
0
0时,正则化的解
w
~
\tilde{w}
w~会趋向
w
∗
w^∗
w∗。那么当
α
\alpha
α增加时,因为
H
H
H是实对称的,所以我们可以将其分解为一个对角矩阵
Λ
\Lambda
Λ和一组特征向量的标准正交基
Q
Q
Q,并且有
H
=
Q
Λ
Q
T
H = Q\Lambda Q^T
H=QΛQT,可得:
w
~
=
Q
(
Λ
+
α
I
)
−
1
Λ
Q
T
w
∗
\tilde{w} = Q(\Lambda + \alpha I)^{-1}\Lambda Q^Tw^*
w~=Q(Λ+αI)−1ΛQTw∗。我们可以看到权重衰减的效果是沿着由
H
H
H的特征向量所定义的轴缩放
w
∗
w^∗
w∗。具体来说,我们会根据
λ
i
λ
i
+
α
\frac{\lambda_i}{\lambda_i+\alpha}
λi+αλi因子缩放与
H
H
H第
i
i
i个特征向量对齐的
w
∗
w^∗
w∗的分量。沿着
H
H
H特征值较大的方向 (如
λ
i
≫
a
\lambda_i\gg a
λi≫a)正则化的影响较小。而
λ
i
≪
a
\lambda_i\ll a
λi≪a的分量将会收缩到几乎为零。
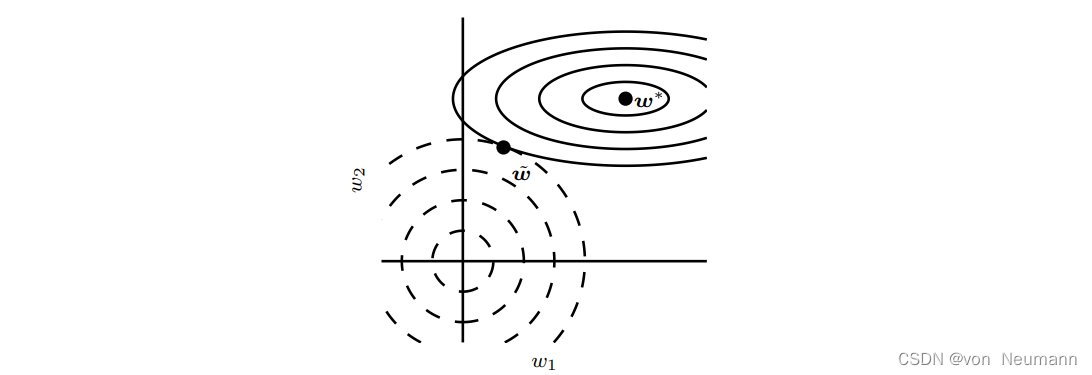
只有在显著减小目标函数方向上的参数会保留得相对完好。在无助于目标函数减小的方向(对应 Hessian 矩阵较小的特征值)上改变参数不会显著增加梯度。这种不重要方向对应的分量会在训练过程中因正则化而衰减掉。
目前为止,我们讨论了权重衰减对优化一个抽象通用的二次代价函数的影响。我们可以研究线性回归,它的真实代价函数是二次的,因此我们可以使用相同的方法分析。再次应用分析,我们会在这种情况下得到相同的结果,但这次我们使用训练数据的术语表述。线性回归的代价函数是平方误差之和: Loss = ( X w − y ) T ( X w − y ) \text{Loss}=(Xw-y)^T(Xw-y) Loss=(Xw−y)T(Xw−y),我们添加 L 2 L^2 L2正则项后,目标函数变为: Loss = ( X w − y ) T ( X w − y ) + 1 2 α w T w \text{Loss}=(Xw-y)^T(Xw-y)+\frac{1}{2}\alpha w^Tw Loss=(Xw−y)T(Xw−y)+21αwTw,这将普通方程的解从 w = ( X T X ) − 1 X T y w=(X^TX)^{-1}X^Ty w=(XTX)−1XTy变为 w = ( X T X + α I ) − 1 X T y w=(X^TX+\alpha I)^{-1}X^Ty w=(XTX+αI)−1XTy。式中的矩阵 X T X X^TX XTX与协方差矩阵 1 m X T X \frac{1}{m}X^TX m1XTX成正比。 L 2 L^2 L2正则项将这个矩阵替换为 ( X T X + α I ) − 1 (X^TX+\alpha I)^{-1} (XTX+αI)−1 。这个新矩阵与原来的是一样的,不同的仅仅是在对角加了 α \alpha α。这个矩阵的对角项对应每个输入特征的方差。我们可以看到, L 2 L^2 L2正则化能让学习算法感知到具有较高方差的输入 x x x,因此与输出目标的协方差较小(相对增加方差)的特征的权重将会收缩。
如果我们使用Hessian矩阵 H H H为对角正定矩阵的假设(与 L 1 L^1 L1正则化分析时一样),重新考虑这个等式,我们发现 w i ~ = H i , i H i , i + α w i ∗ \tilde{w_i}=\frac{H_{i, i}}{H_{i, i} + \alpha}w_i^* wi~=Hi,i+αHi,iwi∗ 。如果 w i ∗ w_i^* wi∗不是零,那么 w i ~ \tilde{w_i} wi~也会保持非零。这表明 L 2 L^2 L2正则化不会使参数变得稀疏,而 L 1 L^1 L1正则化有可能通过足够大的 α \alpha α实现稀疏。
参考文献:
[1] Lecun Y, Bengio Y, Hinton G. Deep learning[J]. Nature, 2015


![String类 [下]](https://img-blog.csdnimg.cn/0e589f1adfe3467d8fbf25b9bded99dc.png)