目录
一、拷贝构造和赋值重载的传统写法和现代写法
0x01 拷贝构造的传统写法
0x02 拷贝构造的现代写法
0x03 赋值重载的传统写法
0x04 赋值重载的现代写法
0x05 总结
二、 增删改查之后的string
0x01 成员函数swap:
0x02 reserve:改变容量
0x03 push_back: 尾插字符
0x04 append: 尾插字符串
0x05 += : 可以直接复用push_back()和append()
0x06 resize
0x07 find
0x08 Insert
0x09 erase:删除
三、运算符重载
0x01 operator<
0x02 operator==
0x03 剩余运算符重载
四、operator<< 和operator>>
0x01 operator<<
0x02 operator>>
五、整体代码

一、拷贝构造和赋值重载的传统写法和现代写法
0x01 拷贝构造的传统写法
思路:先开空间,然后进行拷贝
string(const string& str1)
:_size(str1._size)
,_capacity(str1._capacity)
{
_str = new char[_capacity + 1];
strcpy(_str,str1._str);
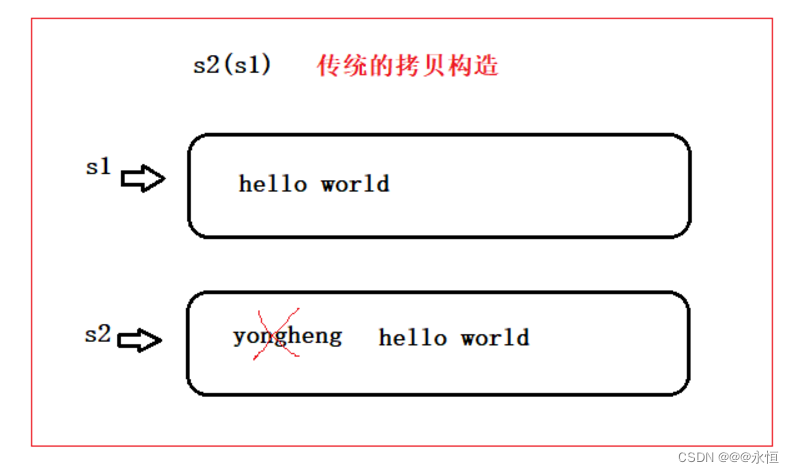
}0x02 拷贝构造的现代写法
思路:s2(s1),用s1._str给temp进行初始化,创建一个temp空间,然后将temp的_str与s2的_str进行交换,就达到了拷贝构造的作用
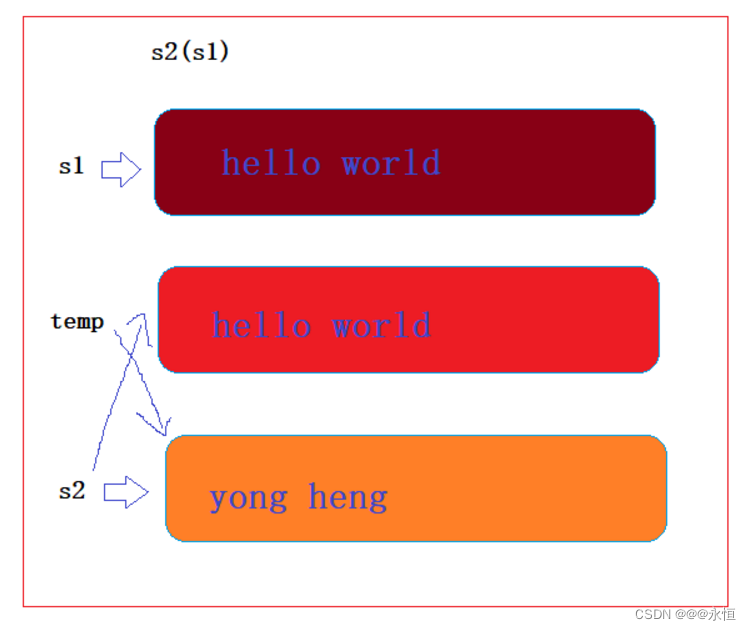
此时将temp._str与s2._str进行交换,那么就达到了拷贝构造的作用,但是这样真的可以吗?
//写法一:
string(const string& str1)
:_str(nullptr) //相当于给s2._str置为空,以便于和temp._str进行交换
{
string temp(str1._str);//将s1的char*字符串给temp进行初始化
swap(_str,temp._str);
}本质上说是不可以,temp是一个局部变量,出了作用域就要调用析构函数,但是temp就相当于指向了一个随机值(因为是string s2(s1),s2是正在创建的,所以传过去的this指针是随机值),而这块空间又不是temp进行malloc或者new出来的,进行析构必然是爆炸的实质上呢?
//写法二:编译器的一个优化
string(const string& str1)
{
string temp(str1._str);//将s1的char*字符串给temp进行初始化
swap(_str,temp._str);
}
因为自定义类型里面有指针成员的时候,编译器编译时,为了防止指针出现随机值的问题,会自动处理把所有成员变量都置为0,而this._str的0就是nullptr,这也是编译器所做的一次优化,所以析构时并不会出现什么问题,因为delete或free一个空是没有问题的,如果不放心也可以进行一次检查
//析构函数,即清理资源
~string()
{
if (_str != nullptr)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}0x03 赋值重载的传统写法
思路:赋值重载的传统写法,先创建一个指针temp,然后将s3释放,之后将s3._str指向指针temp,以达到赋值重载的作用
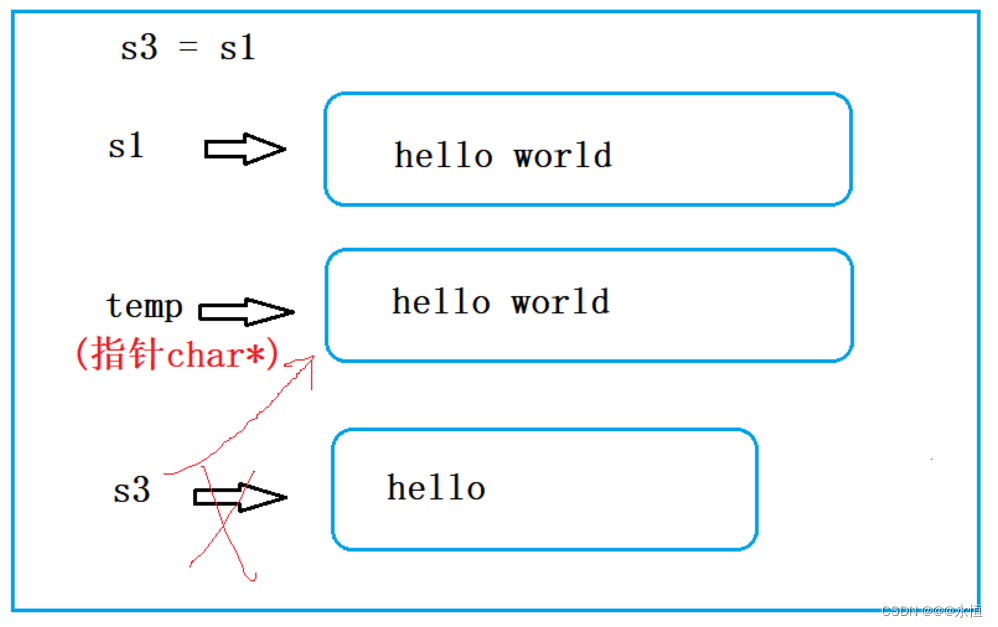
string& operator=(const string& str2)
{
if (this != &str2)//防止自己赋值给自己
{
char* temp = new char[str2._capacity + 1];
strcpy(temp, str2._str);
delete[] _str;
_str = temp;//temp是一个指针,不需要析构
}
return *this;
}0x04 赋值重载的现代写法
思路:先创建一个指针temp,然后将s3释放,之后将s3._str指向指针temp,以达到赋值重载的作用

string& operator= (const string& str2)
{
if (this != &str2)
{
string temp(str2);
swap(_str,temp._str);
}
return *this;
}赋值重载的现代写法是先通过拷贝构造,创建一个temp空间,然后将temp.str与s3.str进行互换,以达到赋值重载的作用,此后因为temp是局部变量,出了作用域会调用析构函数,因为进行交换之后,那么temp所指向的空间就是之前s3所指向的空间,因为s3是已经创建好的对象,所以所指向的不是随机值,所以析构时没有问题的,这与上面拷贝构造的随机值形成一个比较
然而却还有一个更简洁的方法:
string& operator= (string str2)
{
swap(_str,str2._str);
return *this;
}此时s3 = s1;相当于string s2(s1);s1传参过去直接进行的就是一次拷贝构造,然后再将str2.str与this.str进行交换,之后还是通过str2(局部变量)调用析构函数,将之前this所指向的空间释放,以达到赋值重载的作用
此时可能就会有这个想法:为什么不要进行判断一下*this是否和str2有相同的地址呢?
因为s3 = s1;s1可能与s3是相同的地址,而此时没有用&(引用),那么str2和s1必然不会是相同的地址,所以是可以不用判断的,这样也更加的简洁
0x05 总结
以上是未考虑增删改查的写法,即未加入size和capacity的情况,然后现在我们再考虑一下size和capacity的情况
拷贝构造:s2(s1)
string(const string& str1)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
string temp(str1._str);
swap(_str,temp._str);
swap(_size,temp._size);
swap(_capacity,temp._capacity);
}赋值重载:s3 = s1
string& operator= (string str2)
{
swap(_str,str2._str);
swap(_size,str2._size);
swap(_capacity,str2._capacity);
return *this;
}而上面的俩段代码中,又有几段代码显得有些冗余,所以不如直接写个成员函数(具有this指针),直接进行复用
void Swap(string& str)
{
swap(_str, str._str);
swap(_size, str._size);
swap(_capacity, str._capacity);
}复用后的整体代码如下:
void Swap(string& str)
{
swap(_str, str._str);
swap(_size, str._size);
swap(_capacity, str._capacity);
}
//拷贝构造
string(const string& str1)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
string temp(str1._str);
Swap(temp);
}
//赋值重载
string& operator= (string str2)
{
Swap(str2);
return *this;
}二、 增删改查之后的string
说到swap,那么就要提到库中的成员函数的swap和运用模板的swap了,这俩个swap有什么不同或者说哪个效率更好一些呢?
0x01 成员函数swap:

模板函数swap:
首先可以肯定的是这俩个swap所得到的结果是相同的,第一个swap对应的则是具体的类型,第二个swap对应的则是更多的类型,其次,从效率角度来看的话,第一个swap的效率更好一些,仅仅是对成员变量进行交换即可,而第二个全局swap,需要调用一次拷贝构造和俩次构造函数,这就大大增加了运行效率的代价,所以总体来说第一个swap的效率更好一些,而这个问题也是限于在C++98的版本下来说的.
0x02 reserve:改变容量

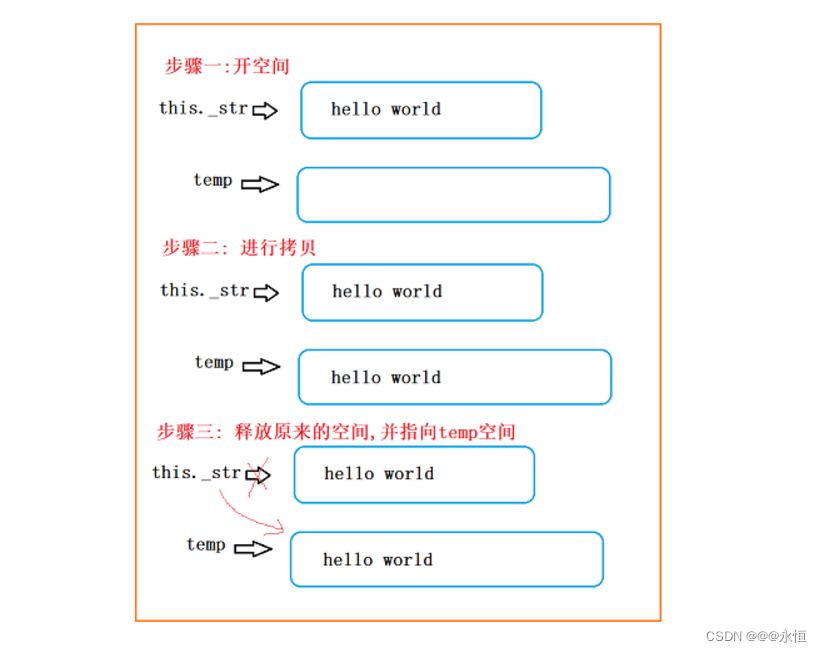
如果需要开辟的空间比原有的空间大,那么开辟一个新的空间,将原有的值拷贝到新的空间,然后释放掉原有空间,将原有的指针指向新的空间,此时许多人可能会有一个疑惑,此时不会调用析构函数吗?当然不会,因为此时的temp是一个内置类型指针,只有自定义类型才会调用析构函数
void reserve(size_t n = 0)//n表示需要改变的大小
{
if (n > _capacity)
{
char* temp = new char[n+1];//+1表示'\0'的空间
strcpy(temp, _str);
delete[] _str;
_str = temp;
_capacity = n;
}
}0x03 push_back: 尾插字符

尾插的前提是拥有足够的空间,那么首先如果当现有的有效个数等于现有的有效容量的时候,那么就会进行容量的改变,即进行扩容,扩容之后在原来的'\0'处增加字符,然后再在之后添加'\0'即可达到插入一个字符的效果
void push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity * 2);//扩容为原来的俩倍
}
_str[_size] = ch;//尾部添加字符
_size++;
_str[_size] = '\0';//再手动添加'\0'
}但是,上面的代码真的就是一定正确吗?会不会还有其他的情况?
是的,是还有一种情况,如果size和capacity的个数等为0的时候,会出现什么样的情况?

此时扩容之后的容量依旧为0,然后再插入一个字符,那么必然会导致内存问题
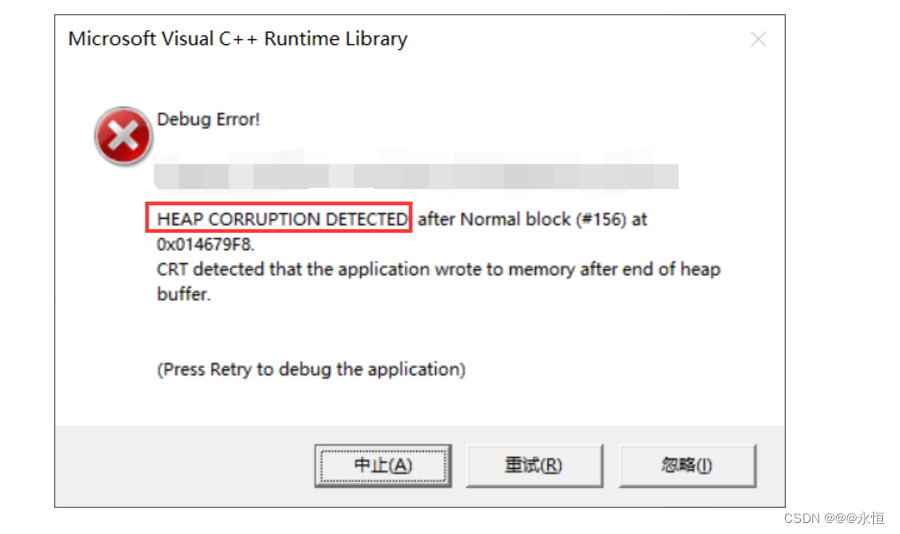
那么如何进行解决呢?
可以运用三目操作符
void push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;//尾部添加字符
_size++;
_str[_size] = '\0';//再手动添加'\0'
}0x04 append: 尾插字符串

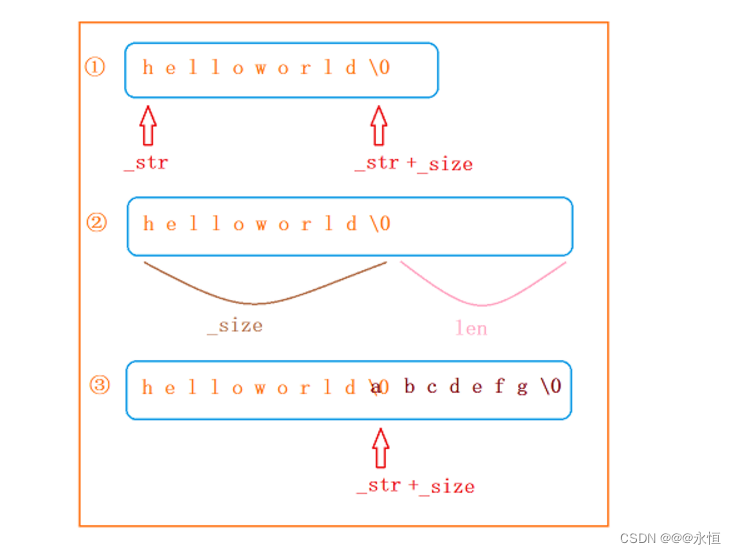
void append(const string& str)
{
//首先算出str._str的有效个数
size_t len = strlen(str._str);
//如果原来的_size+len 比之前的容量要大,则进行增容
if (_size + len > _capacity)
{
reserve(_size + len);//增容足够即可
}
strcpy(_str+_size,str._str);
_size += len;
}0x05 += : 可以直接复用push_back()和append()

//+=一个字符
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
//+= 一个字符串
string& operator+=(const char* str)
{
append(str);
return *this;
}0x06 resize
思路:开空间+初始化,与reserve的作用相似,不同的是resize会进行初始化

void resize(size_t new_capacity,char ch = '\0')
{
//如果所需容量小于现有的有效个数
if (new_capacity <= _size)
{
_str[_size] = '\0';
_size = new_capacity;
}
else//如果所需容量大于现有的有效个数
{
//检查一下是否缺容量
if (new_capacity > _capacity)
{
reserve(new_capacity);//进行扩容
}
//进行初始化
memset(_str+_size,ch, new_capacity - _size);
_size = new_capacity;
_str[_size] = '\0';
}
}resize的实现需要考虑俩个角度:
角度一:如果所需要的空间比有效个数少,则直接用'\0'去进行截断,因为标准库中的resize一般是不进行缩容的
角度二:如果所需空间比有效个数多或相等,则需要看是否有足够的空间,然后进行初始化


0x07 find

//查找一个字符
size_t find(char ch)
{
for (size_t i = 0;i < _size;i++)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}其中npos的成员变量的定义如下:
class string
{
private:
static const size_t npos;
}
const size_t string::npos = -1;//表示最大的那个整数
//寻找一个字符串
size_t find(const char* str1,size_t pos = 0)
{
const char* ptr = strstr(_str + pos,str1);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;// 比如 a(0) b(1) c(2),那么2 - 0 即使c的下标
}
}0x08 Insert
思路:此时的Insert相当于顺序表
string& Insert(size_t pos,char ch)
{
assert(pos <= _size);
//检验空间是否足够
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//移动位置
for (size_t i = _size;i >= pos;i--)
{
_str[i + 1] = _str[i];
}
_str[pos] = ch;
return *this;
}那么上面的代码是否有问题呢?
当然是有问题的,会进行一个死循环,为什么呢?因为当pos == 0时,那么i会一直减减,直到当i == 0时,此时又会进入,然后i == -1,然而i是size_t类型,就会变为一个非常大的正数,这个正数又会一直大于pos的值,然后一直进入循环,造成死循环的现象
那么怎么解决这个问题呢?
将i 写为Int类型,此时,当俩个类型不一样时,会向大的类型转换,当i == -1时,size_t -1又是一个非常大的正数,那么还是一样的,那么这时,只要将pos强制转换为int类型即可,代码如下:
string& Insert(size_t pos,char ch)
{
assert(pos <= _size);
//检验空间是否足够
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//移动位置
for (int i = _size;i > (int)pos;i--)
{
_str[i + 1] = _str[i];
}
_str[pos] = ch;
return *this;
}上面的代码虽然可以解决这个问题,但是想起来还是比较麻烦的,所以想要解决这个问题的另一种方法如下: 让i 指向\0的下一个位置来进行移动每一个空间的值
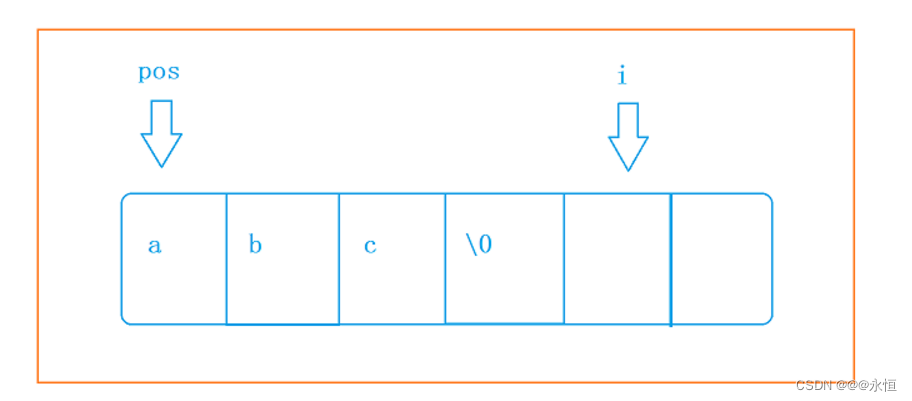
string& Insert(size_t pos,char ch)
{
assert(pos <= _size);
//检验空间是否足够
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//移动位置
for (size_t i = _size + 1;i > pos;i--)//i 指向\0的下一个位置
{
_str[i] = _str[i - 1];
}
_str[pos] = ch;
return *this;
}memmove:memmove用于拷贝字节,如果目标区域和源区域有重叠的话,memmove能够保证源串在被覆盖之前将重叠区域的字节拷贝到目标区域中,但复制后源内容会被更改。但是当目标区域与源区域没有重叠则和memcpy函数功能相同。
void memmove( void dest, const void* src, size_t count );
由src所指内存区域复制count个字节到dest所指内存区域。
Insert:字符串,此时也相当于顺序表
string& Insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
//空间是否足够
if (_size + len > _capacity)
{
reserve(_size + len);
}
//移动位置
for (size_t end = _size + len;end > pos; end--)
{
_str[end] = _str[end - len];
}
memmove(_str+pos,str,len);
_size += len;
return *this;
}进行测试一下是否正确:
int main()
{
s1.Insert(0,"Xyz");
cout << s1.c_str() << endl;
} 
那么上面的结果真的正确吗?
是不正确的,还是有一些小的瑕疵.

此时的end竟然能走到1,而正确的是,当end == pos+len (即等于3)的时候就应该不再进行循环
更改后的代码如下:
string& Insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
//空间是否足够
if (_size + len > _capacity)
{
reserve(_size + len);
}
//移动位置
for (size_t end = _size + len;end >= pos + len; end--)
{
_str[end] = _str[end - len];
}
memmove(_str+pos,str,len);
_size += len;
return *this;
}0x09 erase:删除

删除主要分为俩个角度:
第一个角度:
第二个角度:


string& erase(size_t pos = 0,size_t len = npos)
{
assert(pos < _size);//因为_size位置时'\0',所以pos位置应该是_size之前的字符
if (len == npos || pos + len >= _capacity)
{
_str[pos] = '\0';
_size = pos;
}
else
{
strcpy(_str + pos,_str + pos + len);
_size -= len;
}
return *this;
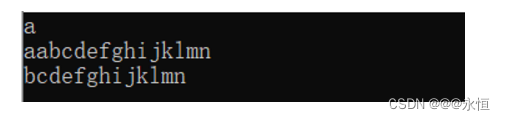
}进行测试一下是否正确:
int main()
{
s1.erase(0,2);
cout << s1.c_str() << endl;
}
三、运算符重载
0x01 operator<
//全局函数
bool operator<(const string& str1, const string& str2)
{
size_t i1 = 0;
size_t i2 = 0;
while (i1 < str1.size() && i2 < str2.size())//俩个字符串,只要有一个结束了就结束了
{
if (str1[i1] < str2[i2])
{
return false;
}
else if (str1[i1] > str2[i2])
{
return true;
}
else
{
i1++;
i2++;
}
}
//如果有一个结束了,那就是另一个大
return i1 < str1.size() ? false : true;
} 也可以用strcmp()进行比较:
strcmp:
基本形式为strcmp(str1,str2),若str1=str2,则返回零;若str1<str2,则返回负数;若str1>str2,则返回正数。
bool operator<(const string& str1, const string& str2)
{
return strcmp(str1.c_str(),str2.c_str()) < 0;
}0x02 operator==
bool operator==(const string& str1, const string& str2)
{
return strcmp(str1.c_str(), str2.c_str()) == 0;
}0x03 剩余运算符重载
其他的运算符则可以运用operator< 和operator==进行复用:
bool operator<=(const string& str1, const string& str2)
{
return str1 < str2 || str1 == str2;
}
bool operator>(const string& str1, const string& str2)
{
return !(str1 <= str2);
}
bool operator>=(const string& str1, const string& str2)
{
return !(str1 < str2);
}
bool operator!=(const string& str1, const string& str2)
{
return !(str1 == str2);
}四、operator<< 和operator>>
0x01 operator<<
ostream& operator<<(ostream& out,const string& str1)
{
//范围for
/* for (auto e : str1)
{
out << e;
}*/
for (size_t i = 0;i < str1.size();i++)
{
out << str1[i];
}
return out;
}其中,范围for的底层相当于迭代器,而迭代器又分为两组,一组是非const的, 一组是带const的
//非const迭代器
typedef char* iterator;
iterator begin()
{
return _str;//首元素地址
}
iterator end()
{
return _str + _size;//最后一个元素的下一个位置
}
//带const迭代器
typedef const char* const_iterator;
const_iterator begin()const
{
return _str;//首元素地址
}
const_iterator end()const
{
return _str + _size;//最后一个元素的下一个位置
}0x02 operator>>
istream& operator>>(istream& in,string& str1)
{
char ch = in.get();
while (ch != ' ' && ch != '\n')//cin遇到' '或'\n'时停止
{
str1 += ch;
ch = in.get();
}
return in;
}五、整体代码
#pragma once
#include<iostream>
#include<cstring>
#include<assert.h>
using namespace std;
namespace yh
{
class string
{
public:
//非const迭代器
typedef char* iterator;
iterator begin()
{
return _str;//首元素地址
}
iterator end()
{
return _str + _size;//最后一个元素的下一个位置
}
//带const迭代器
typedef const char* const_iterator;
const_iterator begin()const
{
return _str;//首元素地址
}
const_iterator end()const
{
return _str + _size;//最后一个元素的下一个位置
}
void Swap(string& str)
{
swap(_str, str._str);
swap(_size, str._size);
swap(_capacity, str._capacity);
}
//开空间
void reserve(size_t n = 0)
{
if (n > _capacity)
{
char* temp = new char[n + 1];
strcpy(temp, _str);
delete[] _str;
_str = temp;
_capacity = n;
}
}
//插入一个字符
void push_back(char ch)
{
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
_str[_size] = ch;//尾部添加字符
_size++;
_str[_size] = '\0';//再手动添加'\0'
}
//插入一个字符串
void append(const string& str)
{
//首先算出str._str的有效个数
size_t len = strlen(str._str);
//如果原来的_size+len 比之前的容量要大,则进行增容
if (_size + len > _capacity)
{
reserve(_size + len);//增容足够即可
}
strcpy(_str + _size, str._str);
_size += len;
}
//+= 一个字符
string& operator+=(char ch)
{
push_back(ch);
return *this;
}
//+= 一个字符串
string& operator+=(const char* str)
{
append(str);
return *this;
}
//resize: 开空间+初始化
void resize(size_t new_capacity, char ch = '\0')
{
//如果所需容量小于现有的有效个数
if (new_capacity <= _size)
{
_str[_size] = '\0';
_size = new_capacity;
}
else//如果所需容量大于现有的有效个数
{
//检查一下是否缺容量
if (new_capacity > _capacity)
{
reserve(new_capacity);//进行扩容
}
//进行初始化
memset(_str + _size, ch, new_capacity - _size);
_size = new_capacity;
_str[_size] = '\0';
}
}
//find 查找一个字符
size_t find(char ch)
{
for (size_t i = 0; i < _size; i++)
{
if (ch == _str[i])
{
return i;
}
}
return npos;
}
//查找一个字符串
size_t find(const char* str1, size_t pos = 0)
{
const char* ptr = strstr(_str + pos, str1);
if (ptr == nullptr)
{
return npos;
}
else
{
return ptr - _str;// 比如 a(0) b(1) c(2),那么2 - 0 即使c的下标
}
}
//Insert: 插入一个字符
string& Insert(size_t pos, char ch)
{
assert(pos <= _size);
//检验空间是否足够
if (_size == _capacity)
{
reserve(_capacity == 0 ? 4 : _capacity * 2);
}
//进行移动
for (size_t i = _size + 1; i > pos; i--)
{
_str[i] = _str[i - 1];
}
_str[pos] = ch;
return *this;
}
//Insert: 插入一个字符串
string& Insert(size_t pos, const char* str)
{
assert(pos <= _size);
size_t len = strlen(str);
//空间是否足够
if (_size + len > _capacity)
{
reserve(_size + len);
}
//移动位置
for (size_t end = _size + len; end >= pos + len; --end)
{
_str[end] = _str[end - len];
}
memmove(_str + pos, str, len);
_size += len;
return *this;
}
//删除
string& erase(size_t pos = 0, size_t len = npos)
{
assert(pos < _size);//因为_size位置时'\0',所以pos位置应该是_size之前的字符
if (len == npos || pos + len > _capacity)
{
_str[pos] = '\0';
}
else
{
strcpy(_str + pos, _str + pos + len);
_size -= len;
}
return *this;
}
//进行构造函数,即进行初始化
//默认构造函数
/* string()
:_str(new char[1])
,_size(0)
,_capacity(0)
{
_str[0] = '\0';
}*/
//全省参数构造函数
string(const char* str = "")
:_size(strlen(str))
, _capacity(_size)
{
_str = new char[_capacity + 1];
strcpy(_str, str);//再进行拷贝
}
//析构函数,即清理资源
~string()
{
if (_str != nullptr)
{
delete[] _str;
_str = nullptr;
_size = _capacity = 0;
}
}
//拷贝构造传统写法
/* string(const string& str1)
:_size(str1._size)
,_capacity(str1._capacity)
{
_str = new char[_capacity + 1];
strcpy(_str,str1._str);
}*/
//拷贝构造现代写法
//string(const string& str1)
// :_str(nullptr)
//{
// string temp(str1._str);//将s1的char*字符串给temp进行初始化
// swap(_str,temp._str);
//}
//拷贝构造增删改查写法
/* string(const string& str1)
:_str(nullptr)
,_size(0)
,_capacity(0)
{
string temp(str1._str);
swap(_str,temp._str);
swap(_size,temp._size);
swap(_capacity,temp._capacity);
}*/
//拷贝构造更加简洁版
string(const string& str1)
:_str(nullptr)
, _size(0)
, _capacity(0)
{
string temp(str1._str);
Swap(temp);
}
//赋值重载传统写法 s3 = s1;
//string& operator=(const string& str2)
//{
// if (this != &str2)//防止自己赋值给自己
// {
// char* temp = new char[str2._capacity + 1];
// strcpy(temp, str2._str);
// delete[] _str;
// _str = temp;//temp是一个指针,不需要析构
// _size = str2._size;
// _capacity = str2._capacity;//容量和大小记得更新
// }
// return *this;
//}
//赋值重载现代写法
/* string& operator= (const string& str2)
{
if (this != &str2)
{
string temp(str2);
swap(_str,temp._str);
}
return *this;
}*/
//赋值重载更简洁的方法(增删改查写法)
string& operator= (string str2)
{
Swap(str2);
return *this;
}
const char* c_str() const
{
return _str;
}
size_t size()const//因为这个this指针不改变
{
return _size;
}
char& operator[](size_t pos)
{
return _str[pos];
}
const char& operator[](size_t pos)const
{
return _str[pos];
}
private:
char* _str;
int _size;
int _capacity;
static const size_t npos;
};
const size_t string::npos = -1;
//operator<
//bool operator<(const string& str1, const string& str2)
//{
// size_t i1 = 0;
// size_t i2 = 0;
// while (i1 < str1.size() && i2 < str2.size())//俩个字符串,只要有一个结束了就结束了
// {
// if (str1[i1] < str2[i2])
// {
// return false;
// }
// else if (str1[i1] > str2[i2])
// {
// return true;
// }
// else
// {
// i1++;
// i2++;
// }
// }
// //如果有一个结束了,那就是另一个大
// return i1 < str1.size() ? false : true;
//}
bool operator<(const string& str1, const string& str2)
{
return strcmp(str1.c_str(), str2.c_str()) < 0;
}
bool operator==(const string& str1, const string& str2)
{
return strcmp(str1.c_str(), str2.c_str()) == 0;
}
bool operator<=(const string& str1, const string& str2)
{
return str1 < str2 || str1 == str2;
}
bool operator>(const string& str1, const string& str2)
{
return !(str1 <= str2);
}
bool operator>=(const string& str1, const string& str2)
{
return !(str1 < str2);
}
bool operator!=(const string& str1, const string& str2)
{
return !(str1 == str2);
}
ostream& operator<<(ostream& out, const string& str1)
{
//范围for
/* for (auto e : str1)
{
out << e;
}*/
for (size_t i = 0; i < str1.size(); i++)
{
out << str1[i];
}
return out;
}
istream& operator>>(istream& in, string& str1)
{
char ch = in.get();
while (ch != ' ' && ch != '\n')//cin遇到' '或'\n'时停止
{
str1 += ch;
ch = in.get();
}
return in;
}
}