RoI Pooling和RoI Align是两种常用的目标检测中的RoI特征提取方法。它们的主要区别在于:如何将不同大小的RoI对齐到固定大小的特征图上,并在这个过程中保留更多的空间信息。
一、RoI Pooling
RoI Pooling最早是在Fast R-CNN中提出的,它的基本思路是:
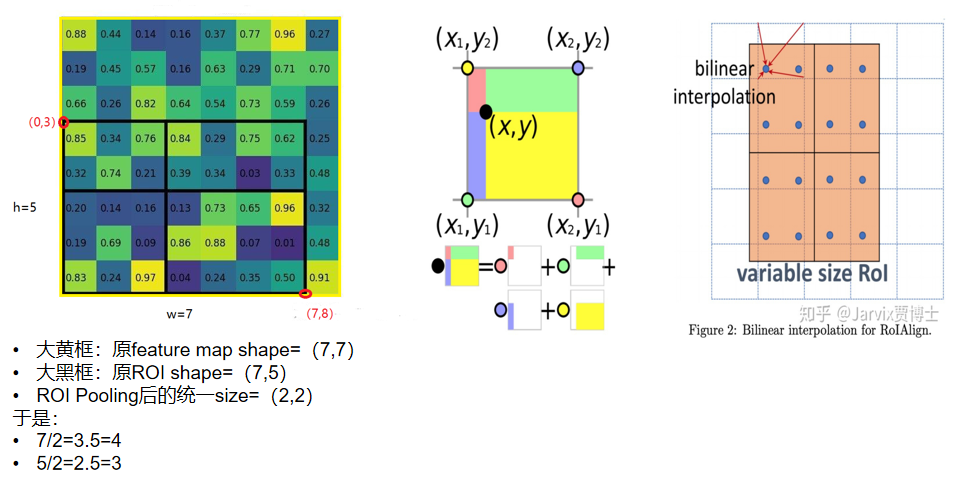
将一个个大小不同的RoI,变成一个固定大小的网格(比如7*7),然后在每个网格上进行最大池化,输出固定大小的特征图。
RoI Pooling实质上是什么呢?
RoI层只是SPPnets中使用的空间金字塔池化层的特殊情况,其中只有一个金字塔层。
(The RoI layer is simply the special-case of the spatial pyramid pooling layer used in SPPnets in which there is only one pyramid level.)
RoI Pooling的步骤:
- 将
bounding box区域按输出要求的size进行等分,很可能等分后,各顶点落不到真实的像素点。采取**向上取整(ceil)和向下取整(floor)**到对应的单元尺寸大小; - 在每个bin中的各个像素点,做最大池化,作为这个bin的输出值;
- 最后就能得到固定大小的输出。
这个方法的优点是简单快速,但是它的缺点是会造成信息的损失,为什么?
比如,当一个RoI的大小不是网格大小的整数倍时,通过分别采取向上取整(ceil)和向下取整(floor)到对应的单元尺寸大小。这种操作都会对应着轻微的区域特征错位(misaligned), 在RoI和提取到的特征之间引入了偏差。
这些偏差可能不会影响对分类任务,但它对预测像素精度掩模有很大的负面影响。
二、RoI Align
为了解决RoI Pooling存在的缺陷,RoI Align被提出。RoI Align的基本思路与RoI Pooling相似,但是它将RoI划分成更小的子区域(比如2x2),然后在每个子区域上进行双线性插值(本质上是目标像素所相邻的四个像素, 分别以像素对应的对角像素与目标像素的构成的矩形区域为权重,像素大小为值的加权和),输出固定大小的特征图。
RoI Align的步骤:
- 将bbox区域按输出要求的size进行等分,很可能等分后,各顶点落不到真实的像素点上;
- 在每个bin中再取固定等分的4个点(作者实验后发现取4效果较好),每一个蓝点距离它最近的4个真实像素点的值加权(双线性插值),赋值给蓝点像素;
- 求得这个蓝点的值一个bin内会算出4个新值,在4个新值中取最大池化,作为这个bin的输出值;
- 最后就能得到固定大小的输出。
RoI Align相比于RoI Pooling的优点是更加精确,能够保留更多的空间信息。特别是在处理小的RoI时,RoI Align的效果更加明显。但是RoI Align的缺点是计算量较大,因为需要进行插值操作。
总体来说,RoI Align相比于RoI Pooling更加精确,但是需要付出更多的计算代价。在实际应用中,根据需求和计算资源的限制,可以选择适当的RoI特征提取方法。
更多图文部分,参考这里:ROI Pooling和ROI Align
三、总结
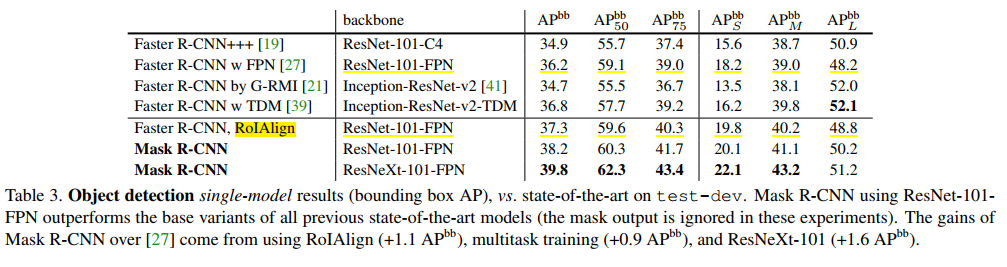
在mask rcnn论文中,作者在Faster R-CNN网络中引入RoI Pooling和RoI Align,对结果进行了对比,如下:
同时,对keypoint detection任务中引入RoI Pooling和RoI Align,结果对比:
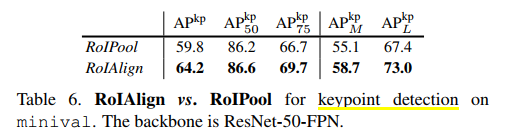
都能发现,即便是对于对像素点无需非常精确的目标检测任务,换用更优的ROI处理方式,同样都得到了更优的结果,进一步证明了该改进方法的优越性。