前言 异常检测一直是机器学习中一个活跃的研究领域,由于风险管理、合规、安全、将抗和医疗风险以及人工智能安全等广泛领域的需求和应用不断增加,异常检测发挥和越来越重要的总用。近年来,随着深度学习和计算机视觉技术的不断发展,已经引入了大量的深度异常检测方法,在解决各种实际应用中具有挑战性的检测问题方面,表现出明显优于传统异常检测的性能。
本教程禁止转载。同时,本教程来自知识星球【CV技术指南】更多技术教程,可加入星球学习。
Transformer、目标检测、语义分割交流群
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
CV各大方向专栏与各个部署框架最全教程整理
为全面介绍异常检测的相关内容,我们决定以专栏的形式与大家一起分享异常检测领域的相关文章。本专栏将包含16篇左右的推文,分为异常检测概述、文章解读、总结梳理三个部分,专栏初步安排如下:
-
(1)异常检测知识概述
-
(2)基本任务,评估指标,常用数据集等基础内容
-
(3)-(4)传统的异常检测方法
-
(5)-(8)Anomaly Detection & One-class 异常检测
-
(9)-(12)Multi-class Novelty Detection & Open Set Recognition 异常检测
-
(13)-(15)Out-of-distrubution 异常检测
-
(16)总结梳理
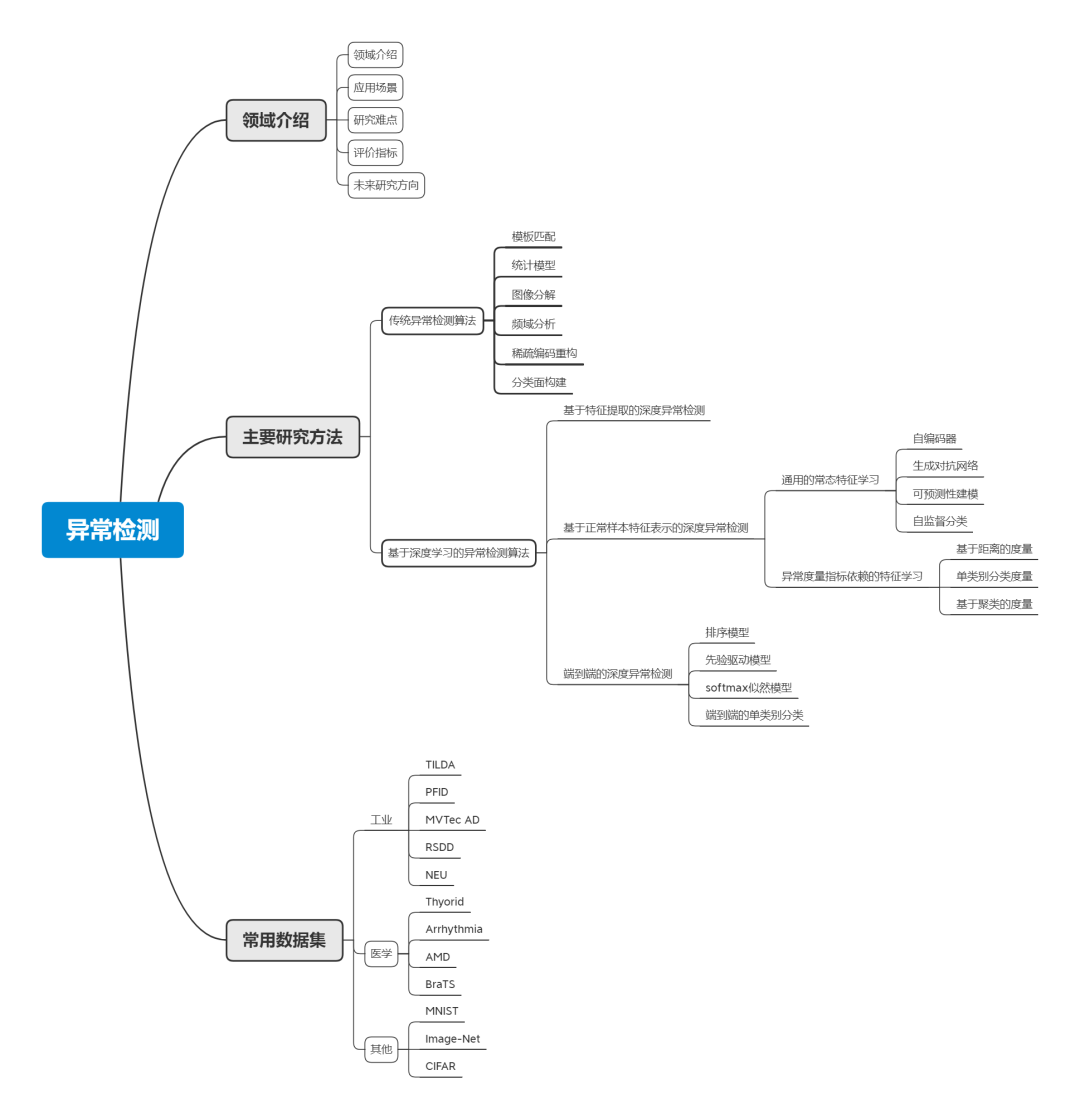
异常检测的主要研究方法和常用数据集如下图所示:
-
目录
-
异常检测相关概念
-
异常检测的定义
-
异常检测几种不同的术语
-
异常检测的应用
-
异常检测的发展
-
-
异常检测的难点
-
下篇内容预告
-
参考文献
异常检测相关概念
异常检测的定义
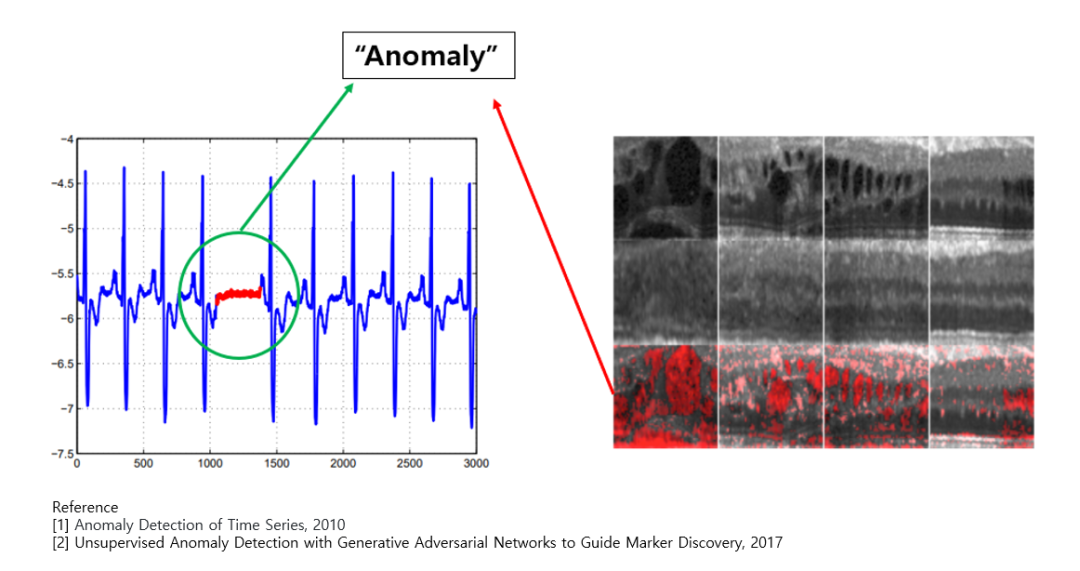
异常检测是一种用于识别不符合预期行为的异常模式(称为异常值)的技术。通常,这被视为一个无监督学习问题(也可是半监督或弱监督学习),其中异常样本是先验未知的,并且假设大部分训练数据集由“正常”数据组成。
在大多数的机器学习模型当中都是基于closed-world假设来进行训练,其中我们会假设测试数据与训练数据有相同的分布,称为in-distribution(ID)。但是,当模型在open-world的场景中进行部署时,测试样本可能处于分布之外,称为out-of-distribution(OOD),因此对于这种情况需要谨慎处理,这便是异常检测研究的重点问题。
简单来说,我们可以”将异常“与预先定义的“正常”视为两个对比性的概念。比如,我们想要建立一个食物检测器去区分待检测物体’hotdog‘或’not-hotdog‘。那么我们可以把‘hotdog’看成正常实例,而’not-hotdog‘看成其对立的异常实例。在这个例子当中需要注意的是,’hotdog‘是一个同质的概念,我们不区分它的大小、价格、原材料等。至于其他的目标,如牛排、米饭或者是其他的猫狗这样的待测物体都统一的被视为’异常‘实例。
总之,在异常检测相关任务中,关键是同等地对待正常实例,并在某些特定的情况和场景下检测出所有可能的异常样本。
异常检测几种不同的术语
我们可以用一个统一的框架,即广义的Out-of-Distribution(广义的OOD)来描述异常检测的相关问题。OOD包括五个相关的子领域,分别为Anomaly Detection(AD)、Novelty Detection(ND)、Open Set Recogntion(OSR)、Out-of-Distribution(OOD)和Outlier Detection(OD)。这5个子领域之间在某种意义上是相似的,其共同的目标是在open-world的假设下检测分布以外的样本。
Anomaly Detection(AD)
AD目标是在测试过程中检测所有偏离预先定义正常性的异常样本。这种偏差可能是由协变量偏移(covariate shift)或语义偏移(semantic shift)所引起的(注意,在AD中这两种偏移只存在其一)。因此,可以将AD进一步细分为sensory AD和semantic AD。
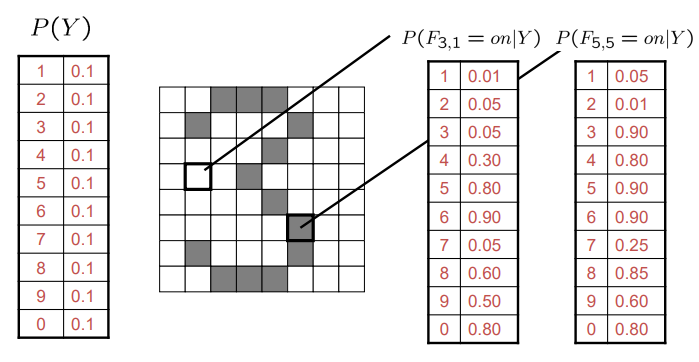
在sensory AD任务中,正常实例是从分布P(X)中采样得到,而在测试时异常实例来自于另一种分布P'(X),并且P(X)!= P'(X),sensory AD的目标便是去检测出从P'(X)采样的实例。sensory AD仅仅包含协变量偏移而不包含语义偏移,即P(Y)=P'(Y)。相反的,对于semantic AD来说,只有语义偏移即P(Y)!= P'(Y),其目标是检测出训练属于新类别的实例。
Novelty Detection(ND)
ND目标是检测出任何不属于训练数据类别的测试样本。检测到的新颖样本(这里的新样本是指模型在训练过程中没有遇到过的新类别的样本)通常会为未来的分析做准备。例如模型本身的增量学习。根据训练数据的类别,我们可以将ND进一步分为两种模式,即One-class ND和multi-class ND。
其中,One-class ND表示在训练集中只包含一个类别的数据,而Multi-class ND则表示在训练集中有多种类别的数据。不论是单类别还是多类别,ND只会将新样本与ID的样本区分开来,两种任务属于二分类的问题。
Open Set Recognition(OSR)
在closed-world训练得到的模型有时会以较高的置信度将来自未知类别的样本错误的划分到已知的类别,这种情况称为模型的"过度自信"。OSR的提出可以用来解决这种用"known known classes"来表示"unknown unknown classes"的问题。
OSR需要多类分类器同时工作,以此来正确的将来自"known known classes"的样本进行正确分类,并检测出来自"unknown unknown classes"的样本。
Out-of-Distribution(OOD)
OOD目标是检测与训练集没有任何重叠标签的测试样本。OOD检测种的样本来自于ID进行语义偏移后的分布,即P(Y)!= P'(Y)。在OOD,ID中的数据可以是单类别也可以是多类别的。当数据为多类别时,OOD检测不能对ID分类的能力造成影响(也就是说在检测出异常的同时要保证模型对正常样本的分类性能)。
Outlier Detection(OD)
OD目标是检测由协变量或语义偏移引起的与给定观测集中其他样本明显不同的样本。在前面几个任务ID在训练期间的分布已经定义好,而对于OD来说ID是指大多数的观测值。OD任务中异常值既可以是由协变量偏移引起又可以是由语义偏移所引起。
总的来说,以上的五个子领域都可以概括为广义OOD问题。下图展示了广义OOD的整体框架:

异常检测的应用
由于风险管理、合规、安全、金融监控、健康和医疗风险以及人工智能安全等广泛领域的需求和应用不断增加,异常检测发挥着越来越重要的作用。
-
欺诈检测:在金融行业,异常检测可以用来检测信用卡欺诈、保险欺诈等欺诈行为
-
工业监控:异常检测可以用来检测机器故障、异常工艺、质量问题等
-
医疗诊断:异常检测可以用来帮助医生诊断疾病,例如癌症早期诊断、心脏病诊断等
-
航空航天:异常检测可以用来检测飞机、火箭等设备的故障、安全问题等
-
网络安全:异常检测可以用来检测网络入侵、恶意软件等安全问题
-
城市规划:异常检测可以用来检测城市交通拥堵、环境污染等问题,帮助城市规划部门进行决策
-
营销分析:异常检测可以用来识别异常的营销趋势,帮助企业制定更好的营销策略
下图展示了异常检测在工业当中的应用:

以上只是异常检测应用的一小部分,随着深度学习的不断发展,相信异常检测可以应用在更多的领域当中。
异常检测的发展
异常检测可以基于多种方法来实现,其主要经历了基于统计的方法、机器学习的方法和深度学习的方法三个阶段:
-
基于统计的方法 基于统计的方法是最早也是最常见的检测方法之一。这类方法基于对数据的分布特性建模,通过计算数据点与数据分布的距离或差异性来判断数据点是否异常。常用的基于统计的方法包括均值和标准差法、离群点检测法、箱线图法等。虽然基于统计的方法易于实现和解释,但其准确性和鲁棒性有一定的限制,尤其是在数据量较大、维度较高等复杂场景下。
-
传统的机器学习方法 机器学习的方法是近几十年来在异常检测领域中得到广泛应用的方法之一。该方法基于训练数据集,通过构建一个异常检测的模型来检测新数据点是否异常。基于传统的机器学习方法大致包含6个类别:基于模板匹配、基于统计模型、基于图像分解、基于频域分析、基于系数编码重构和基于分类面构建的异常检测方法。这类方法可以适应复杂的数据分布,同时具有较高的准确性和可扩展性。但是,传统的异常检测方法需要大量的标注数据并且模型的泛化能力也可能受到一定的限制。
-
深度学习的方法 近年来,深度学习在学习高维数据、时间数据、空间数据和图形数据等复杂数据的表达表示方面表现出了巨大的能力,突破了不同学习任务的界限。Deep learning for anomaly detection,简称深度异常检测,旨在通过神经网络学习特征表示或异常分数以进行异常检测。已经引入了大量的深度异常检测方法,在解决各种实际应用中具有挑战性的检测问题方面,表现出明显优于传统异常检测的性能。常用的深度学习方法包括自编码、卷积神经网络、生成对抗网络以及图神经网络等。深度学习的出现极大促进了异常检测的快速发展,但基于深度学习的异常检测算法仍有许多困难待以解决。
在本专栏中,我们主要介绍有关深度学习的异常检测方法,下图展示了三种主要深度异常检测方法的概念框架
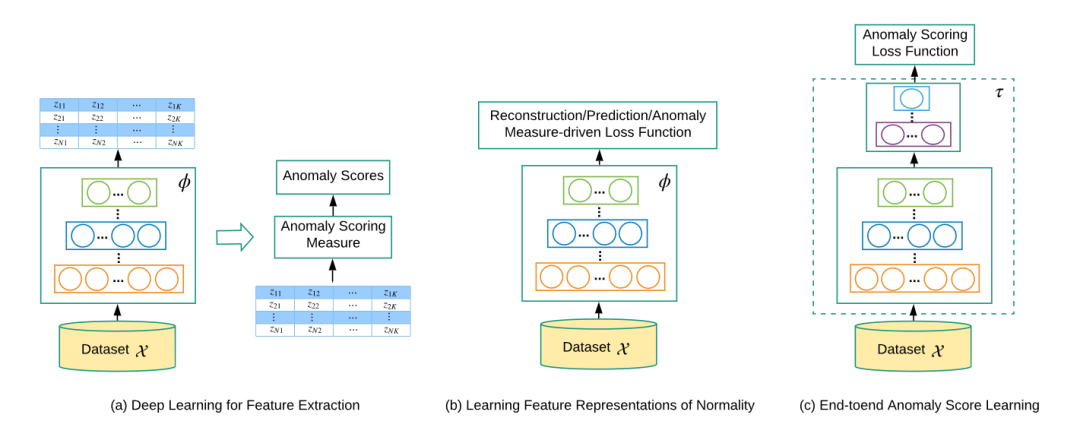
异常检测的难点
由于其独特性,异常检测呈现出与大多数分析和学习问题和任务截然不同的问题复杂性。本节总结了复杂异常数据中的此类内在复杂性和未解决的检测挑战。与那些关于多数、常规或明显模式的问题和任务不同,异常检测解决少数、不可预测/不确定和罕见的事件,从而导致所有(深度和浅层)检测方法出现一些独特的问题复杂性:
-
未知性异常的出现与许多未知的东西有关,例如具有未知突然行为、数据结构和分布的实例(样本)。这些异常的样本在没有发生时都是未知的,比如说新型恐怖袭击、欺诈和网络入侵。
-
异构异常类异常大多数都是不规则的,因此某一类别的异常可能会表现出与另一类异常完全不同的异常特性。例如,在视频监控中,抢劫、交通事故、入室盗窃等异常事件在视觉上有很大的不同。
-
稀有性和类别不平衡一般来说,与通常占据绝大多数的正常实例相比,异常实例只占据了数据的一小部分。因此,我们难以去获取大量标注的异常实例。这导致在大多数应用程序中无法使用大规模标记数据。类别的不平衡也是由于异常的错误分类通常比正常实例的错误分类成本高得多。
-
异常的多样性在 文中主要探索了三种完全不同的异常。第一类是点异常(Point Anomalies),是相对于大多数其他个体实例异常的个体实例,例如,患者的异常健康指标。第二类是条件异常(Conditional Anomalies),也指个别异常实例,但在特定上下文中,即数据实例在特定上下文中异常,否则正常。在现实世界的应用程序中,上下文可能会有很大的不同,例如,特定时间上下文中的温度突然下降/升高,或异常空间上下文中的快速信用卡交易。第三类则是组异常(Group Anomalies)又名集体异常,是相对于其他数据实例整体异常的数据实例的子集;集体异常的个体成员可能不是异常,例如,社交网络中由虚假账户形成的异常密集的子图作为集合是异常,但这些子图中的个体节点可以像真实账户一样正常。
下篇内容预告
本篇文章我们理解了异常检测的定义、不同术语之间的联系和区别、基本任务、发展历程以及异常检测的难点。在下一篇文章中我们将进一步了解异常检测的评价指标以及几种常用的数据集。具体内容请参考下篇【异常检测的评价指标与数据集】。
参考文献
[1] Lukas Ruff et al., 2018; Deep One-Class Classification
[2] G. Pang, C. Shen, L. Cao, and A. van den Hengel, “Deep Learning for Anomaly Detection: A Review,” ACM Comput. Surv., vol. 54, no. 2, pp. 1–38, Mar. 2022, doi: 10.1145/3439950.
[3] 吕承侃,沈飞,张正涛等.图像异常检测研究现状综述[J].自动化学报,2022,48(06):1402-1428.DOI:10.16383/j.aas.c200956.
[4] Yang, J., Zhou, K., Li, Y., and Liu, Z., “Generalized Out-of-Distribution Detection: A Survey”, 2021. doi:10.48550/arXiv.2110.11334.
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章
上线一天,4k star | Facebook:Segment Anything
3090单卡5小时,每个人都能训练专属ChatGPT,港科大开源LMFlow
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
实践教程|GPU 利用率低常见原因分析及优化
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
CNN的反击!InceptionNeXt: 当 Inception 遇上 ConvNeXt
神经网络的可解释性分析:14种归因算法
无痛涨点:目标检测优化的实用Trick
详解PyTorch编译并调用自定义CUDA算子的三种方式
深度学习训练模型时,GPU显存不够怎么办?
CV各大方向专栏与各个部署框架最全教程整理
计算机视觉入门1v3辅导班
计算机视觉各个方向交流群