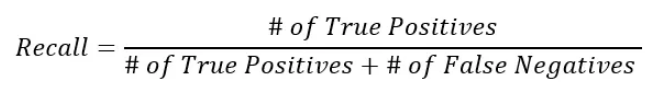如果数据都是存储在一台服务器上,如果出事就完犊子了,比如:
- 如果服务器发生了宕机,由于数据恢复是需要点时间,那么这个期间是无法服务新的请求的;
- 如果这台服务器的硬盘出现了故障,可能数据就都丢失了。
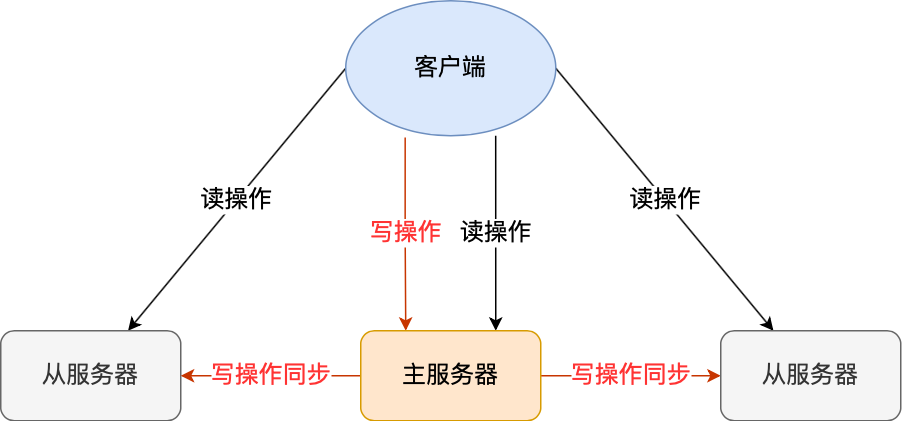
要避免这种单点故障,最好的办法是将数据备份到其他服务器上,让这些服务器也可以对外提供服务,这样即使有一台服务器出现了故障,其他服务器依然可以继续提供服务。

多台服务器要保存同一份数据,这里问题就来了。
这些服务器之间的数据如何保持一致性呢?数据的读写操作是否每台服务器都可以处理?
Redis 提供了主从复制模式,来避免上述的问题。
这个模式可以保证多台服务器的数据一致性,且主从服务器之间采用的是「读写分离」的方式。
主服务器可以进行读写操作,当发生写操作时自动将写操作同步给从服务器,而从服务器一般是只读,并接受主服务器同步过来写操作命令,然后执行这条命令。
也就是说,所有的数据修改只在主服务器上进行,然后将最新的数据同步给从服务器,这样就使得主从服务器的数据是一致的。
同步这两个字说的简单,但是这个同步过程并没有想象中那么简单,要考虑的事情不是一两个。
我们先来看看,主从服务器间的第一次同步是如何工作的?
第一次同步
多台服务器之间要通过什么方式来确定谁是主服务器,或者谁是从服务器呢?
我们可以使用 replicaof(Redis 5.0 之前使用 slaveof)命令形成主服务器和从服务器的关系。
比如,现在有服务器 A 和 服务器 B,我们在服务器 B 上执行下面这条命令:
# 服务器 B 执行这条命令
replicaof <服务器 A 的 IP 地址> <服务器 A 的 Redis 端口号>接着,服务器 B 就会变成服务器 A 的「从服务器」,然后与主服务器进行第一次同步。
主从服务器间的第一次同步的过程可分为三个阶段:
- 第一阶段是建立链接、协商同步;
- 第二阶段是主服务器同步数据给从服务器;
- 第三阶段是主服务器发送新写操作命令给从服务器。
是采用全量复制的方式,也就是主服务器会把所有的数据都同步给从服务器。
所以,第一阶段的工作时为了全量复制做准备。
那具体怎么全量同步呀呢?我们可以往下看第二阶段。
第二阶段:主服务器同步数据给从服务器
接着,主服务器会执行 bgsave 命令来生成 RDB 文件,然后把文件发送给从服务器。
从服务器收到 RDB 文件后,会先清空当前的数据,然后载入 RDB 文件。
这里有一点要注意,主服务器生成 RDB 这个过程是不会阻塞主线程的,因为 bgsave 命令是产生了一个子进程来做生成 RDB 文件的工作,是异步工作的,这样 Redis 依然可以正常处理命令。
但是,这期间的写操作命令并没有记录到刚刚生成的 RDB 文件中,这时主从服务器间的数据就不一致了。
那么为了保证主从服务器的数据一致性,主服务器在下面这三个时间间隙中将收到的写操作命令,写入到 replication buffer 缓冲区里:
- 主服务器生成 RDB 文件期间;
- 主服务器发送 RDB 文件给从服务器期间;
- 「从服务器」加载 RDB 文件期间;
第三阶段:主服务器发送新写操作命令给从服务器
在主服务器生成的 RDB 文件发送完,从服务器收到 RDB 文件后,丢弃所有旧数据,将 RDB 数据载入到内存。完成 RDB 的载入后,会回复一个确认消息给主服务器。
接着,主服务器将 replication buffer 缓冲区里所记录的写操作命令发送给从服务器,从服务器执行来自主服务器 replication buffer 缓冲区里发来的命令,这时主从服务器的数据就一致了。
至此,主从服务器的第一次同步的工作就完成了.
增量复制
主从服务器在完成第一次同步后,就会基于长连接进行命令传播。
可是,网络总是不按套路出牌的嘛,说延迟就延迟,说断开就断开。
如果主从服务器间的网络连接断开了,那么就无法进行命令传播了,这时从服务器的数据就没办法和主服务器保持一致了,客户端就可能从「从服务器」读到旧的数据。
从 Redis 2.8 开始,网络断开又恢复后,从主从服务器会采用增量复制的方式继续同步,也就是只会把网络断开期间主服务器接收到的写操作命令,同步给从服务器。
主要有三个步骤:
- 从服务器在恢复网络后,会发送 psync 命令给主服务器,此时的 psync 命令里的 offset 参数不是 -1;
- 主服务器收到该命令后,然后用 CONTINUE 响应命令告诉从服务器接下来采用增量复制的方式同步数据;
- 然后主服务将主从服务器断线期间,所执行的写命令发送给从服务器,然后从服务器执行这些命令。
那么关键的问题来了,主服务器怎么知道要将哪些增量数据发送给从服务器呢?
答案藏在这两个东西里:
- repl_backlog_buffer,是一个「环形」缓冲区,用于主从服务器断连后,从中找到差异的数据;
- replication offset,标记上面那个缓冲区的同步进度,主从服务器都有各自的偏移量,主服务器使用 master_repl_offset 来记录自己「写」到的位置,从服务器使用 slave_repl_offset 来记录自己「读」到的位置。
那 repl_backlog_buffer 缓冲区是什么时候写入的呢?
在主服务器进行命令传播时,不仅会将写命令发送给从服务器,还会将写命令写入到 repl_backlog_buffer 缓冲区里,因此 这个缓冲区里会保存着最近传播的写命令。
网络断开后,当从服务器重新连上主服务器时,从服务器会通过 psync 命令将自己的复制偏移量 slave_repl_offset 发送给主服务器,主服务器根据自己的 master_repl_offset 和 slave_repl_offset 之间的差距,然后来决定对从服务器执行哪种同步操作:
- 如果判断出从服务器要读取的数据还在 repl_backlog_buffer 缓冲区里,那么主服务器将采用增量同步的方式;
- 相反,如果判断出从服务器要读取的数据已经不存在 repl_backlog_buffer 缓冲区里,那么主服务器将采用全量同步的方式。
当主服务器在 repl_backlog_buffer 中找到主从服务器差异(增量)的数据后,就会将增量的数据写入到 replication buffer 缓冲区,这个缓冲区我们前面也提到过,它是缓存将要传播给从服务器的命令。
总结
主从复制共有三种模式:全量复制、基于长连接的命令传播、增量复制。
主从服务器第一次同步的时候,就是采用全量复制,此时主服务器会两个耗时的地方,分别是生成 RDB 文件和传输 RDB 文件。为了避免过多的从服务器和主服务器进行全量复制,可以把一部分从服务器升级为「经理角色」,让它也有自己的从服务器,通过这样可以分摊主服务器的压力。
第一次同步完成后,主从服务器都会维护着一个长连接,主服务器在接收到写操作命令后,就会通过这个连接将写命令传播给从服务器,来保证主从服务器的数据一致性。
如果遇到网络断开,增量复制就可以上场了,不过这个还跟 repl_backlog_size 这个大小有关系。
如果它配置的过小,主从服务器网络恢复时,可能发生「从服务器」想读的数据已经被覆盖了,那么这时就会导致主服务器采用全量复制的方式。所以为了避免这种情况的频繁发生,要调大这个参数的值,以降低主从服务器断开后全量同步的概率。