Apache Kafka 是当今事件流的事实标准。Kafka 如此成功的部分原因是它能够处理大量数据,每秒吞吐量达到数百万条记录,这在生产环境中并非闻所未闻。Kafka设计的一部分使这成为可能,那就是分区。
Kafka 使用分区将数据负载分散到集群中的代理之间,它也是并行性的单元;更多的分区意味着更高的吞吐量。由于 Kafka 使用键值对,因此在同一分区上获取具有相同键的记录至关重要。
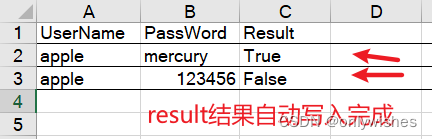
考虑一个银行应用程序,它使用客户 ID 生成给 Kafka 的每笔交易。将所有这些事件放在同一个分区上至关重要;这样,使用者应用程序将按照记录到达的顺序处理记录。保证具有相同键的记录在正确分区上的机制是一个简单但有效的过程:取键模的哈希值为分区数。下图显示了这个概念的实际应用:
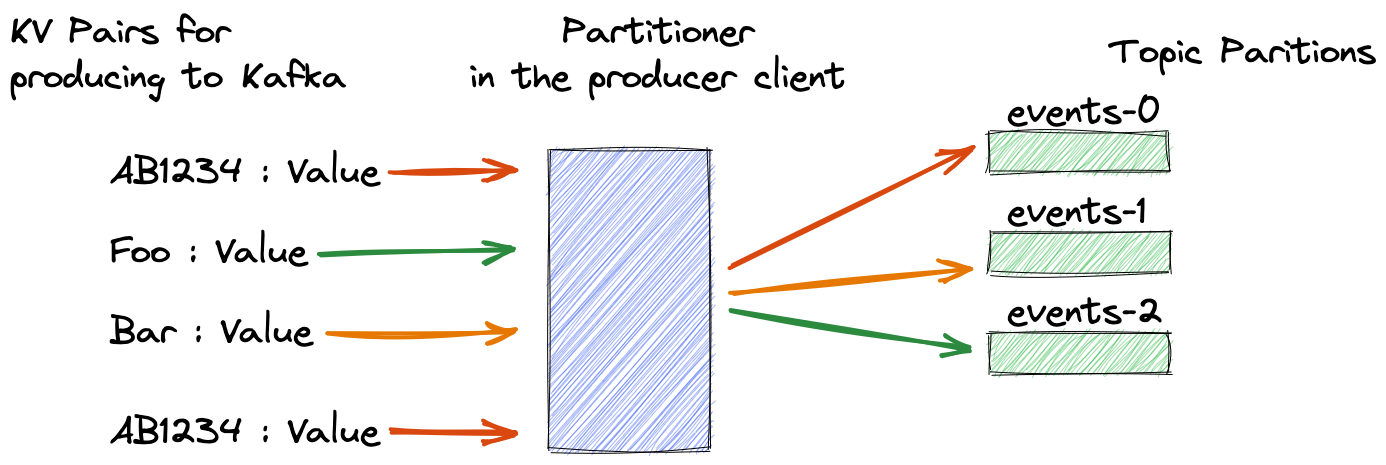
在高级别上,CRC32 或 Murmur2 等哈希函数接受输入并生成固定大小的输出,例如 64 位数字。相同的输入总是产生相同的输出,无论是用Java,Python还是任何其他语言实现的。分区程序使用哈希结果一致地选择分区,因此相同的记录键将始终映射到相同的 Kafka 分区。我不会在这个博客中详细介绍,但知道有几种哈希算法可用就足够了。
我今天想讨论的不是分区是如何工作的,而是 Kafka 生产者客户端中的分区程序。创建者使用分区程序来确定给定键的正确分区,因此在创建者客户端中使用相同的分区程序策略至关重要。
由于创建者客户端具有默认分区程序设置,因此此要求应该不是问题。例如,当将 Java 生产者客户端与 Apache Kafka 发行版一起使用时,该类提供了一个默认分区程序,该分区程序使用 Murmur2 哈希函数来确定给定键的分区。KafkaProducer
但是其他语言的 Kafka 生产者客户端呢?优秀的librdkafka项目是Kafka客户端的C/C++实现,广泛用于非JVM Kafka应用程序。此外,其他语言(Python,C#)的Kafka客户端构建在它之上。librdkafka 的默认分区程序使用 CRC32 哈希函数来获取密钥的正确分区。
这种情况本身不是问题,但很容易成为问题。Kafka 代理与客户端的语言无关;只要它遵循 Kafka 协议,您就可以使用任何语言的客户端,并且代理很乐意接受他们的生产和消费请求。鉴于今天的多语言编程环境,你可以让组织内的开发团队使用不同的语言工作,比如Python和Java。但是在没有任何变化的情况下,两组将以不同的哈希算法的形式使用不同的分区策略:使用 CRC32 的 librdkafka 生产者和使用 Murmur2 的 Java 生产者,因此具有相同键的记录将登陆不同的分区!那么,这种情况的补救措施是什么?
Java 仅通过默认分区程序提供一种哈希算法;由于实现分区程序很棘手,因此最好将其保留为默认值。但是 librdkafka 生产者客户端提供了多个选项。其中一个选项是murmur2_random分区程序,它使用 murmur2 哈希函数并将空键分配给随机分区,这与 Java 默认分区程序的行为相当。KafkaProducer
例如,如果在 C# 中使用 Kafka 创建器客户端,则可以使用以下行设置分区策略:
ProducerConfig.Partitioner = Partitioner.Murmur2Random;.Partitioner = Partitioner.Murmur2Random;现在,您的 C# 和 Java 生产者客户端使用兼容的分区方法!
使用非 Java Kafka 客户机时,启用与 Java 创建器客户机相同的分区策略是一个很好的主意,以确保所有生成者对不同的键使用一致的分区。