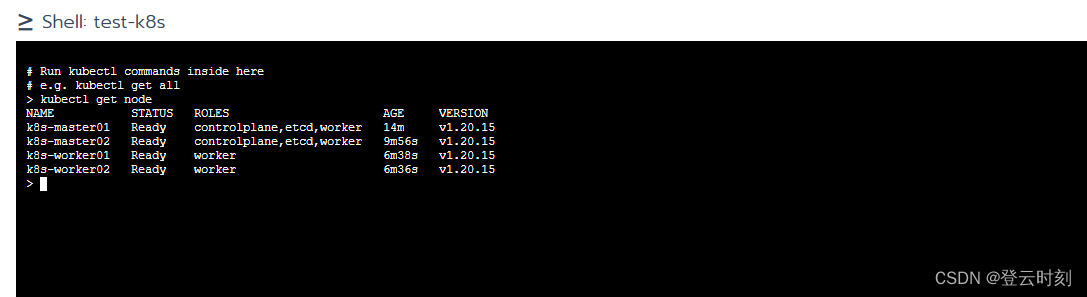
流和缓冲区都是用来描述数据的。计算机中,数据往往会被抽象成流,然后传输。比如读取一个文件,数据会被抽象成文件流;播放一个视频,视频被抽象成视频流。处理节点为了防止过载,又会使用缓冲区削峰(减少瞬间压力)。在传输层协议当中,应用往往先把数据放入缓冲区,然后再将缓冲区提供给发送数据的程序。发送数据的程序,从缓冲区读取出数据,然后进行发送。流和缓冲区几乎是学习所有语言的程序员都会接触到的东西,也是面试的重点。
流
流代表数据,具体来说是随着时间产生的数据,类比自然界的河流。你不知道一个流什么时候会完结,直到你将流中的数据都读完。
读取文件的时候,文件被抽象成流。流的内部构造,决定了你每次能从文件中读取多少数据。从流中读取数据的操作,本质上是一种迭代器。流的内部构造决定了迭代器每次能读出的数据规模。比如你可以设计一个读文件的流,每次至少会读出 4k 大小,也可以设计一个读文件的程序,每次读出一个字节大小。通常情况读取数据的流,是读取流;写入数据的流,是写入流。那么一个写入流还能被理解成随着时间产生的数据吗?其实是一样的,随着时间产生的数据,通过写入流写入某个文件,或者被其他线程、程序拿走使用。
这里请你思考一个问题:流中一定有数据吗?看上去的确是这样。对于文件流来说,打开一个文件,形成读取流。读取流的本质当然是内存中的一个对象。当用户读取文件内容的时候,实际上是通过流进行读取,看上去好像从流中读取了数据,而本质上读取的是文件的数据。从这个角度去观察整体的设计,数据从文件到了流,然后再到了用户线程,因此数据是经过流的。但是仔细思考这个问题,可不可以将数据直接从文件传输到用户线程呢?比如流对象中只设计一个整数型指针,一开始指向文件的头部,每次发生读取,都从文件中读出内容,然后再返回给用户线程。做完这次操作,指针自增。通过这样的设计,流中就不需要再有数据了。可见,流中不一定要有数据。再举一个极端的例子,如果我们设计一个随机数的产生流,每次读取流中的数据,都调用随机数函数生成一个随机数并返回,那么流中也不需要有数据的存储。
为什么要缓冲区?
在上面的例子当中,我们讨论的时候发现,设计文件流时,可以只保留一个位置指针,不用真
的将整个文件都读入内存,像下图这样
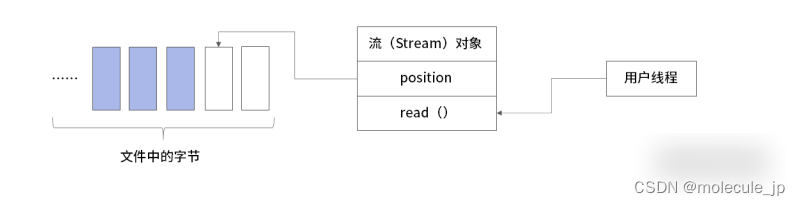
把文件看作是一系列线性排列连续字节的合集,用户线程调用流对象的读取数据方法,每次从文件中读取一个字节。流中只保留一个读取位置 position,指向下一个要读取的字节。看上去这个方案可行,但实际上性能极差。因为从文件中读取数据这个操作,是一次磁盘的I/O 操作,非常耗时。正确的做法是每次读取 2k、4k 这样大小的数据,这是因为操作系统中的内存分页通常是这样的大小,而磁盘的读写往往是会适配页表大小。而且现在的文件系统主要都是日志文件系统,存储的并不是原始数据本身,也就是说多数情况下你看到的文件并不是
一个连续紧密的字节线性排列,而是日志。
当你向磁盘读取 2k 数据,读取到的不一定是 2k 实际的数据,很有可能会比 2k 少,这是因为文件内容是以日志形式存储,会有冗余。
我们用下面这张图来描述下需求:
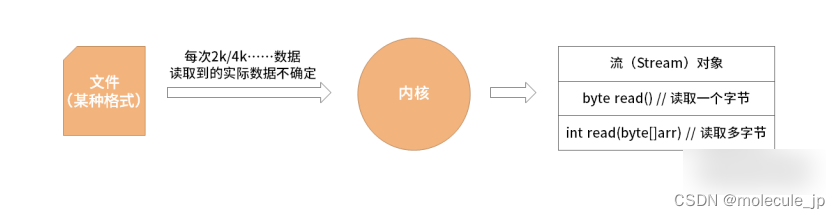
如上图所示,内核每次从文件系统中读取到的数据是确定的,但是里边的有效数据是不确定的。流对象的设计,至少应该支持两种操作:一种是读取一个字节,另一种是读取多个字节。而无论读取一个字节还是读取多个字节,都应该适配内核的底层行为。也就是说,每次流对象读取一个字节,内核可能会读取 2k、4k 的数据。这样的行为,才能真的做到减少磁盘的 I/O操作。那么有同学可能会问:内核为什么不一次先读取几兆数据或者读取更大的数据呢?这有两个原因。
1.
如果是高并发场景下,并发读取数据时内存使用是根据并发数翻倍的,如果同时读取的数据量过大,可能会导致内存不足。
2.
读取比 2k/4k……大很多倍的数据,比如 1M/2M 这种远远大于内存分页大小的数据,并不能提升性能。
所以最后我们的解决办就是创建两个缓冲区。
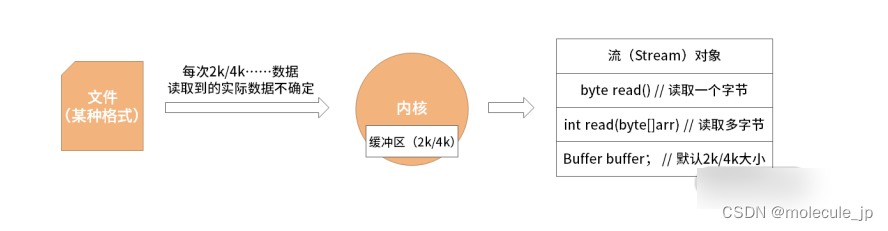
上图中内核中的缓冲区,用于缓冲读取文件中的数据。流中的缓冲区,用于缓冲内核中拷贝过来的数据。有同学可能不理解,为什么不把内核的缓冲区直接给到流呢?这是因为流对象工作在用户空间,内核中的缓冲区工作在内核空间。用户空间的程序不可以直接访问内核空间的数据,这是操作系统的一种保护策略。
缓冲区
上面的设计中,我们已经开始用缓冲区解决问题了。那么具体什么是缓冲区呢?缓冲区就是一块用来做缓冲的内存区域。在上面的例子当中,为了应对频繁的字节读取,我们在内存当中设置一个 2k 大小缓冲区。这样读取 2048 次,才会真的发生一次读取。同理,如果应对频繁的字节写入,也可以使用缓冲区。不仅仅如此,比如说你设计一个秒杀系统,如果同时到达的流量过高,也可以使用缓冲区将用户请求先存储下来,再进行处理。这个操作我们称为削峰,削去流量的峰值。缓冲区中的数据通常具有朴素的公平,说白了就是排队,先进先出(FIFO)。从数据结构的设计上,缓冲区像一个队列。在实际的使用场景中,缓冲区有一些自己特别的需求,比如说缓冲区需要被重复利用。多次读取数据,可以复用一个缓冲区,这样可以节省内存,也可以减少分配和回收内存的开销。举个例子:读取一个流的数据到一个缓冲区,然后再将缓冲区中的数据交给另一个流。 比如说读取文件流中的数据交给网络流发送出去。首先,我们要将文件流的数据写入缓冲区,然后网络流会读取缓冲区中的数据。这个过程会反反复复进行,直到文件内容全部发送。

这个设计中,缓冲区需要支持这几种操作:
1.
写入数据
2.
读出数据
3.
清空(应对下一次读写)
那么具体怎么设计这个缓冲区呢?首先,数据可以考虑存放到一个数组中,下图是可以存 8 个
字节的缓冲区:

写入数据的时候,需要一个指针指向下一个可以写入的位置,如下图所示:

每次写入数据,position 增 1,比如我们顺序写入 a,b,c,d 后,缓冲区如下图所示:
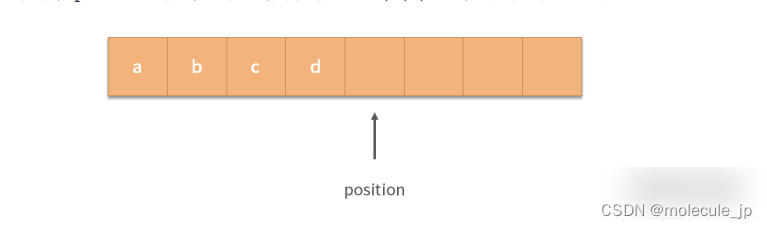
那么如果这个时候,要切换到读取状态该怎么做呢?再增加一个读取指针吗?聪明的设计者想到了一个办法,增加一个 limit 指针,随着写入指针一起增长,如下图所示:
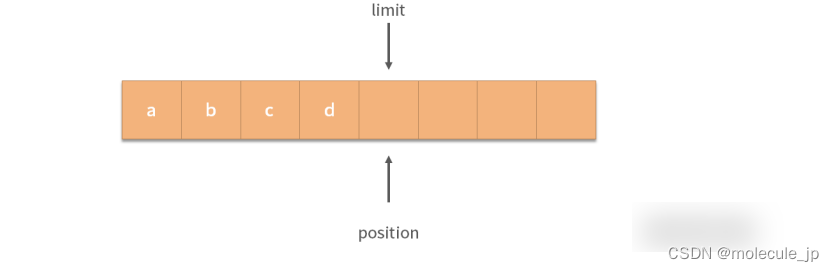
当需要切换到读取状态的时候,将 position 设置为 0,limit 不变即可。下图中,我们可以从0 开始读取数据,每次读取 position 增 1。
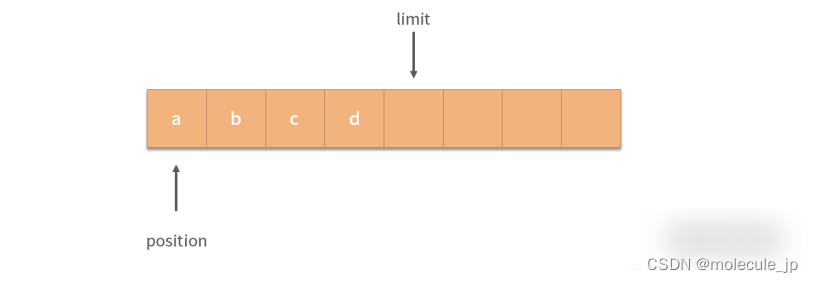
我们将 position 设置为 0,limit 不变的操作称为flip操作,flip 本意是翻转,在这个场景中是读、写状态的切换。读取操作可以控制循环从 position 一直读取到 limit,这样就可以读取出 a,b,c,d。那么如果要继续写入应该如何操作呢? 这个时候就需要用到缓冲区的clear操作,这个操作会清空缓冲区。具体来说,clear操作会把 position,limit 都设置为 0,而不需要真的一点点擦除缓冲区中已有的值,就可以做到重复利用缓冲区了。写入过程从 position = 0 开始,position 和 limit 一起自增。读取时,用flip操作切换缓冲区读写状态。读取数据完毕,用clear操作重置缓冲区状态。
总结
总结一下,流是随着时间产生的数据。数据抽象成流,是因为客观世界存在着这样的现象。数据被抽象成流之后,我们不需要把所有的数据都读取到内存当中进行计算和迭代,而是每次处理或者计算一个缓冲区的数据。缓冲区的作用是缓冲,它在高频的 I/O 操作中很有意义。针对不同场景,也不只有这一种缓冲区的设计,比如用双向链表实现队列(FIFO 结构)可以作为缓冲区;Redis 中的列表可以作为缓冲区;RocketMQ,Kafka 等也可以作为缓冲区。针对某些特定场景,比如高并发场景下的下单处理,可能会用订单队列表(MySQL 的表)作为缓冲区。因此从这个角度来说,作为开发者我们首先要有缓冲的意识,去减少 I/O 的次数,提升 I/O 的性能,然后才是思考具体的缓冲策略。
flip 操作意味翻转,是切换缓冲区的读写状态,在 flip 操作中,通常将 position 指针置 0,limit 指针不变。