一、消费模式
1、pull(拉)模式(kafka采用这种方式)
consumer采用从broker中主动拉取数据。
存在问题:如果kafka中没有数据,消费者可能会陷入循环中,一直返回空数据
2、push(推)模式
由broker决定消息发送频率,很难适应所有消费者的消费速率。
二、总体工作流程

案例一:单独消费者,并订阅主题
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
//集群地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
//反序列化方式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//消费者组,必须指定
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
//创建消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//订阅主题
List<String> topicList = new ArrayList<>();
topicList.add("first");
kafkaConsumer.subscribe(topicList);
//消费数据
while (true){
try {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println(record.key() + "---------" + record.value());
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
控制台输出

案例二:单独消费者,订阅主题+分区
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
//集群地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
//反序列化方式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//消费者组,必须指定
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
//创建消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//订阅主题+分区
List<TopicPartition> topicPartitionList = new ArrayList<>();
topicPartitionList.add(new TopicPartition("first", 0));
kafkaConsumer.assign(topicPartitionList);
//消费数据
while (true){
try {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println(record.key() + "---------" + record.value());
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
只消费了发往分区0的数据


案例三:消费者组
启动
多个消费案例一的消费者,会自动指定消费的分区(partition)
启动3个消费者,一个消费者消费一个分区

三、消费者组
由多个consumer组成(
条件:groupid相同),是逻辑上的一个订阅者。
- 每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费
- 消费者组之间互不影响
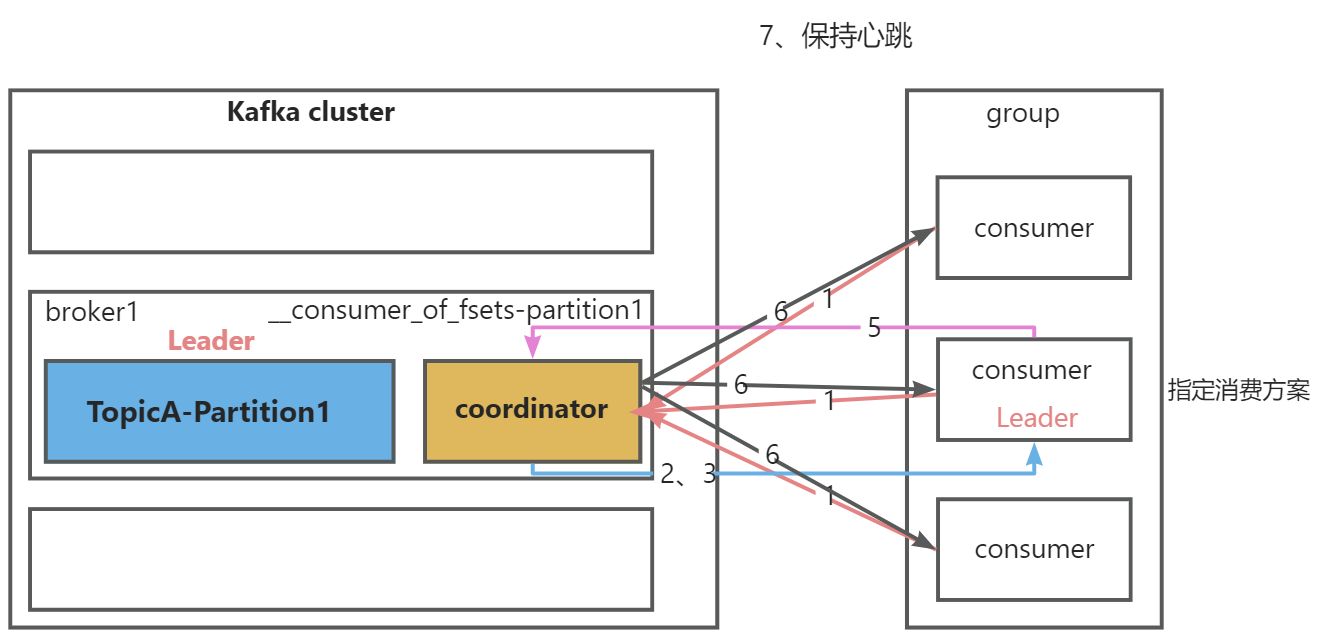
1、初始化流程
coordinator:辅助实现消费者组的初始化和分区的分配
coordinator节点选择=groupid的hashCode值%50(__consumer_offsets的分区数量)
例如:groupid的hashCode=1,1%50=1,那么__consumer_offsets主题的1号分区,在哪个broker上,就选择这个节点的coordinator作为这个消费者组的老大,消费者组下所有的消费者提交offset的时候,就往这个分区去提交offset
- 1.组内每个消费者向选中的
coordinator节点发送joinGroup请求 - 2.
coordinator节点选择一个consumer作为leader - 3.
coordinator节点把要消费的topic情况,发送给消费者leader - 4.
消费者leader负责制定消费方案 - 5.把消费方案发送给
coordinator节点 - 6.
coordinator节点把消费方案发送给各consumer - 7.每个消费者都会和
coordinator节点保持心跳(默认3s),一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理的时间过长(max.poll.interval.ms=5分钟),也会被移除,并触发再平衡
2、分区分配以及再平衡
到底由哪个消费者来消费哪个partition的数据
- 分配策略:Range、RoundRobin、Sticky、CooperativeStick
- 配置参数:partition.assignment.strategy(默认:Range+CooperativeStick)
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.Properties;
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
//集群地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
//反序列化方式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//消费者组,必须指定
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
//设置分区分配策略,多个策略使用逗号拼接
properties.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName());
//创建消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//订阅主题
List<String> topicList = new ArrayList<>();
topicList.add("first");
//再平衡的时候,会触发ConsumerRebalanceListener
kafkaConsumer.subscribe(topicList, new ConsumerRebalanceListener() {
// 重新分配完分区之前调用
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.println("==============回收的分区=============");
for (TopicPartition partition : partitions) {
System.out.println("partition = " + partition);
}
}
// 重新分配完分区后调用
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.println("==============重新得到的分区==========");
for (TopicPartition partition : partitions) {
System.out.println("partition = " + partition);
}
}
});
//消费数据
while (true){
try {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println(record);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
range
分配策略:对同一个topic里面的分区序号排序,对消费者按字母排序,通过partition数量/consumer数量(如果除不尽,那么前面几个消费者将会多消费1个分区)
这个只是针对一个topic而言,C0消费者多消费一个分区影响不是很大,但是如果这个消费者组消费多个topic,容易产生数据倾斜
- 再平衡机制:某一个消费者挂掉后,45秒内产生的数据,将会由某一个消费者代为消费;45秒后产生的数据,会重新分配
RoundRobin
分配策略:对集群中所有的Topic而言,把所有的partition和所有的consumer都列出来,然后按照hashCode进行排序,最后通过轮询算法来分配partition给各个消费者- 再平衡机制:轮询分配(不是按数据,是按分区)
Sticky
分配策略:分配带粘性,执行一次新的分配时,考虑原有的分配- 再平衡机制:打散,尽量均匀分配(不是按数据,是按分区)
四、offset
1、默认维护位置
主题:__consumer_offset
key:group.id + topic + 分区号
value:当前offset的值
每隔一段时间,kafka内部会对这个topic进行压缩(compact),也就是每一个
group.id + topic + 分区号保留最新数据
2、自动提交offset
是否开启自动提交:
enable.auto.commit默认true
自动提交时间间隔:auto.commit.interval.ms默认5s
基于时间的提交,难以把握
3、手动提交offset
类别:同步提交(
commitSync)、异步提交(commitAsync)
相同点:提交一批数据的最高偏移量
不同点:同步阻塞当前现场,失败会自动重试;异步没有重试机制,可以提交失败。
4.指定offset消费
如果没有初始偏移量(消费者第一次消费)或者服务器上不存在当前偏移量(被删除),如何指定offset进行消费
auto.offset.reset=earliest(默认) | latest | none
在代码中设置方式为properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"earliest")
- earliest:自动将偏移量重置为最早的偏移量(
--from-beginning) - latest:自动将偏移量重置为最新的偏移量
- none:没有偏移量,抛出异常
除了这三中,还可以自己来指定位置或者指定时间
指定位置开始消费案例:
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
//集群地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
//反序列化方式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//消费者组,必须指定
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
//创建消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//订阅主题
List<String> topicList = new ArrayList<>();
topicList.add("first");
kafkaConsumer.subscribe(topicList);
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0){
kafkaConsumer.poll(Duration.ofSeconds(1));
//获取到消费者分区分配信息(有了分区分配信息才能开始消费)
assignment = kafkaConsumer.assignment();
}
//遍历所有分区,并指定offset从100的位置开始消费
for (TopicPartition partition : assignment) {
kafkaConsumer.seek(partition, 100);
}
//消费数据
while (true){
try {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println(record);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
指定时间开始消费案例:把指定的时间转为offset
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import java.time.Duration;
import java.util.*;
public class KafkaConsumerTest {
public static void main(String[] args) {
Properties properties = new Properties();
//集群地址
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092,hadoop103:9092");
//反序列化方式
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//消费者组,必须指定
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test_group");
//创建消费者
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//订阅主题
List<String> topicList = new ArrayList<>();
topicList.add("first");
kafkaConsumer.subscribe(topicList);
Set<TopicPartition> assignment = new HashSet<>();
while (assignment.size() == 0){
kafkaConsumer.poll(Duration.ofSeconds(1));
//获取到消费者分区分配信息(有了分区分配信息才能开始消费)
assignment = kafkaConsumer.assignment();
}
HashMap<TopicPartition, Long> timestampMap = new HashMap<>();
for (TopicPartition partition : assignment) {
//一天前的毫秒数
timestampMap.put(partition, System.currentTimeMillis() - 1*24*3600*1000);
}
//获取毫秒数对应的offset位置
Map<TopicPartition, OffsetAndTimestamp> offsetAndTimestampMap = kafkaConsumer.offsetsForTimes(timestampMap);
OffsetAndTimestamp offsetAndTimestamp;
//给每个patition设置offset位置
for (TopicPartition partition : assignment) {
offsetAndTimestamp = offsetAndTimestampMap.get(partition);
kafkaConsumer.seek(partition, offsetAndTimestamp.offset());
}
//消费数据
while (true){
try {
ConsumerRecords<String, String> consumerRecords = kafkaConsumer.poll(Duration.ofSeconds(1));
for (ConsumerRecord<String, String> record : consumerRecords) {
System.out.println(record);
}
}catch (Exception e){
e.printStackTrace();
}
}
}
}
五、消费者事务
使用消费者事务,进行精准一次消费,将消费过程和提交offset过程做原子操作绑定。解决重复消费和漏消费问题
- 重复消费:由自动提交offset引起。
- 漏消费:设置手动提交offset,提交offset时,数据还未落盘,消费者进程被kill,那么offset已经提交,但是数据未处理,导致这部分内存中数据丢失
六、数据挤压
- 消费能力不足:增加分区数量,同时提高消费者数量(注意:分区数量≥消费者数量)
- 处理不及时:
拉去数据
/
处理时间
<
生产速度
拉去数据/处理时间<生产速度
拉去数据/处理时间<生产速度,提高每批次拉去的数量。
fetch.max.bytes(一次拉取得最大字节数,默认:5242880=50m)、max.poll.records(一次poll数据最大条数,默认:500条)