文章目录
- 论文链接
- 摘要
- 1 contribution
- 3 Multimodal Graph Transformer
- 3.1 Background on Transformers
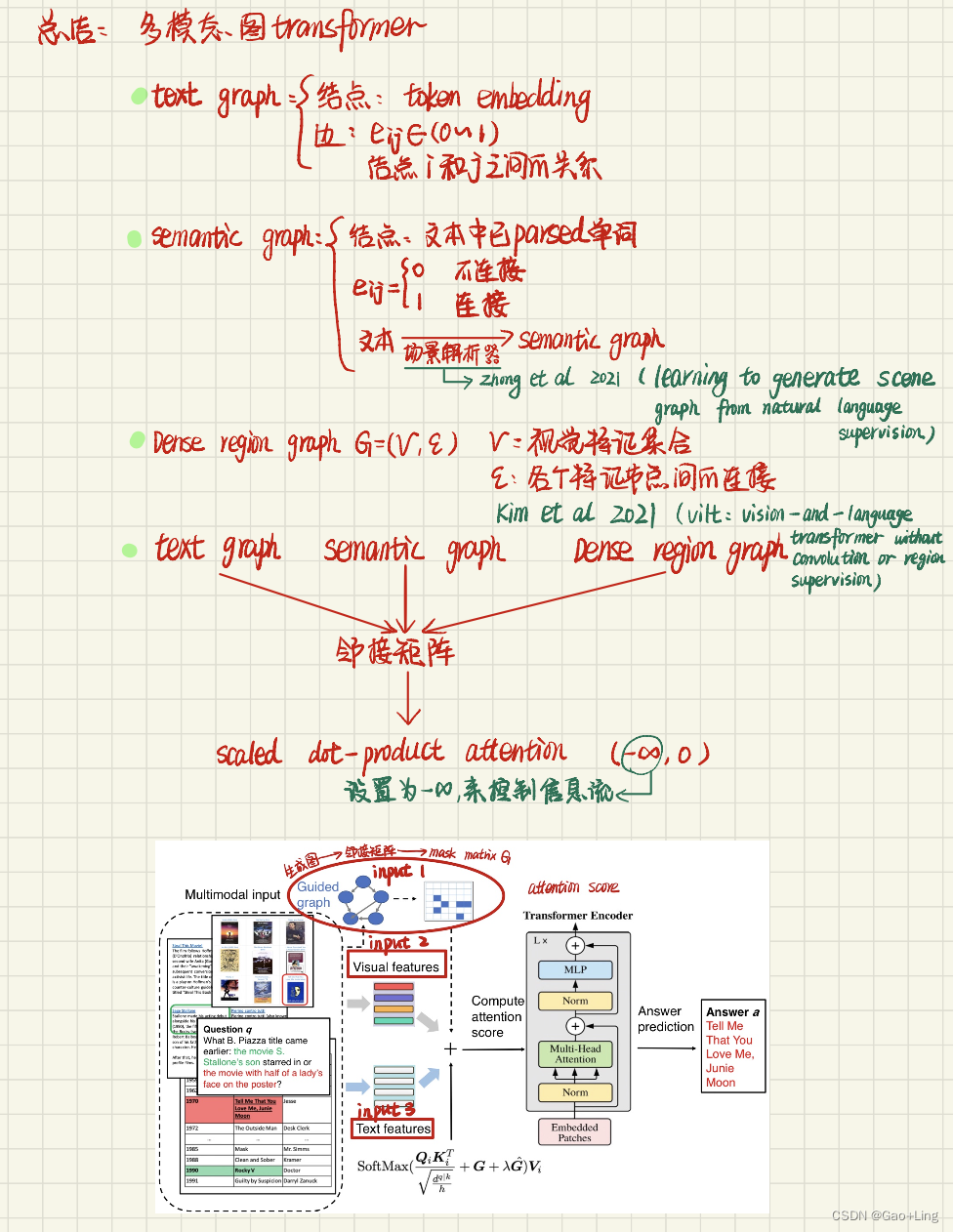
- 3.2 Framework overview 框架概述
- 3.3 Multimodal graph construction多模态图的构建
- Text graph
- Semantic graph
- Dense region graph
- Graph-involved quasi-attention
- 总结
论文链接
论文名:Multimodal Graph Transformer for Multimodal Question Answering
论文链接
摘要
尽管Transformer模型在视觉和语言任务中取得了成功,但它们经常隐式地从大量数据中学习知识,而不能直接利用结构化的输入数据。另一方面,结构化学习方法,如集成先验信息的图神经网络(gnn),几乎无法与Transformer模型竞争。
在这项工作中,我们的目标是从这两个世界中受益,并提出了一种新的多模态图转换器,用于需要跨多模态执行推理的问答任务。我们引入了一种涉及图形的即插即用类注意机制,将从文本和视觉数据中获得的多模态图形信息作为有效的先验信息整合到vanilla自注意力中。
具体来说,我们构建文本图、密集区域图和语义图来生成邻接矩阵,然后将它们与输入的视觉和语言特征组合在一起进行下游推理。
这种用图形信息规范自注意的方法显著提高了推理能力,并有助于对齐来自不同模态的特征。我们在GQA、VQAv2和MultiModalQA数据集上验证了Multimodal Graph Transformer在其Transformer基线上的有效性。
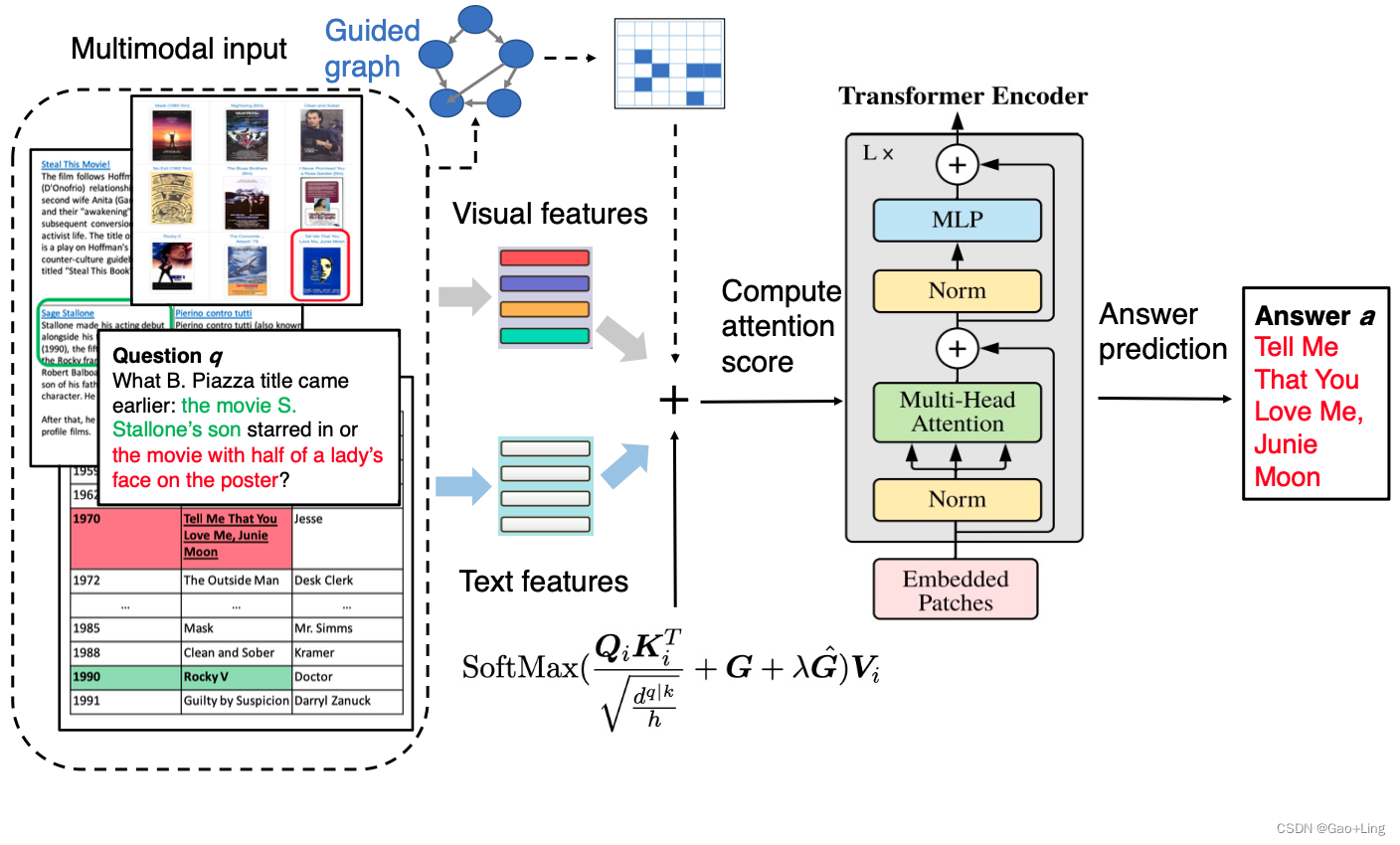
图1: Multimodal Graph Transformer 的概述。它将视觉特征、文本特征及其相应生成的图形作为输入。首先将生成的图转换为邻接矩阵来导出掩模矩阵g。计算Transformer中修改的准注意分数来推断答案。式中,G是由视觉端和语言端邻接矩阵连接而成的图诱导矩阵。G是可训练偏差。将不同模态的输入特征与图形信息融合,进行下游推理。
1 contribution
为了弥补现有方法的不足,本文提出了一种基于即插即用图的多模态问答方法。我们的方法是Multimodal Graph Transformer,因为它是建立在完善的变压器(Vaswani等人,2017a)主干上的,尽管有几个关键的基本区别。
首先,我们引入了一个系统的方案,将文本图、密集区域图和语义图从视觉和语言任务转换为邻接矩阵以用于我们的方法。
其次,我们不是直接计算注意力分数,而是以图诱导邻接矩阵为核心学习新提出的准注意力分数,以表明学习相对重要性作为一种高效的归纳偏差对计算准注意力分数的重要性。
第三,与以往Transformer的方法完全从数据中学习自注意不同,我们在自注意计算中引入图结构信息来指导Transformer的训练,如图1所示。
主要 贡献 总结如下:
• 我们提出了一种新的多模态图转换器学习框架,将非结构化数据的多模态图学习与Transformer模型相结合。
• 我们引入了一个模块化的即插即用图形类注意机制,该机制具有可训练的偏差项,以指导训练过程中的信息流。
• 所提出方法的有效性在GQA, VQA-v2和MultiModalQA任务上得到了经验验证。
3 Multimodal Graph Transformer
3.1 Background on Transformers
Transformer层(Vaswani et al., 2017b)由两个模块组成:多头注意力和前馈网络(FFN)。
具体来说,每个头是由四个主要代表矩阵:
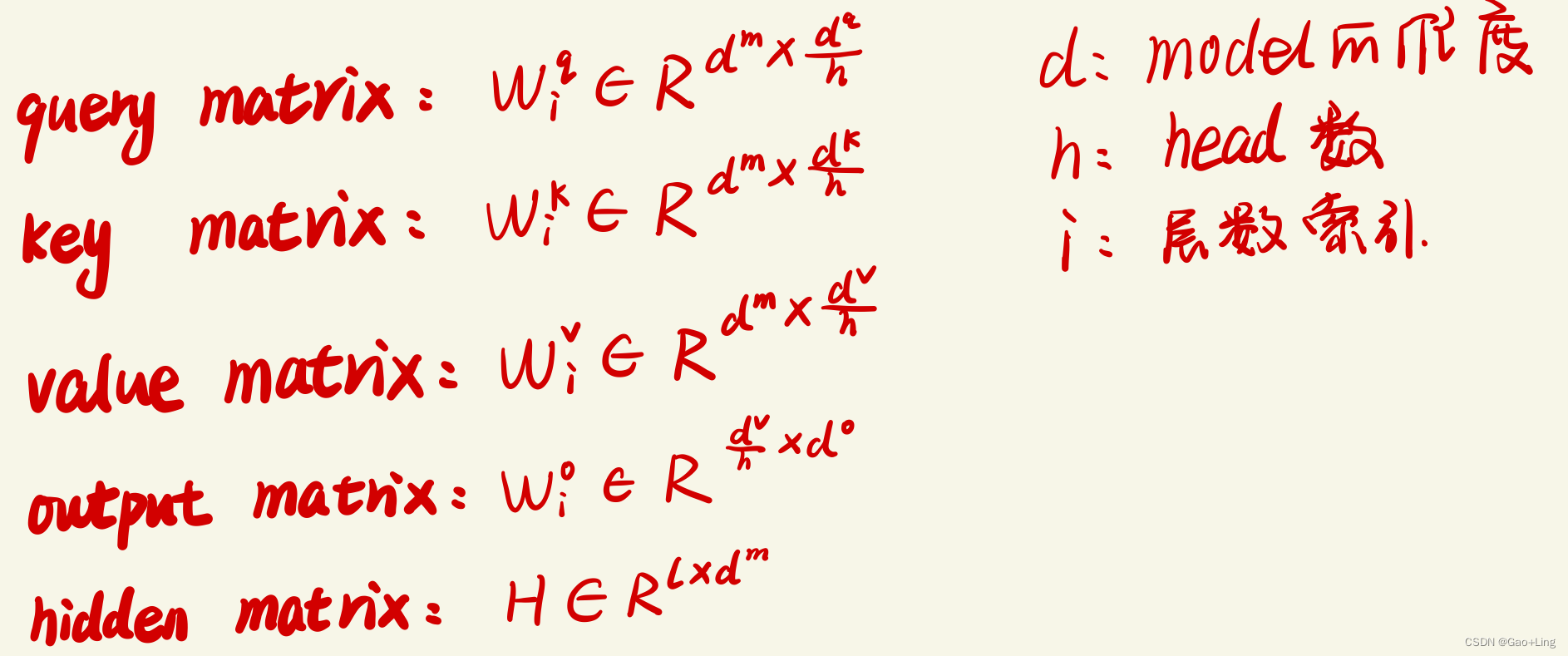
注意力的输出如下:

3.2 Framework overview 框架概述
所提出的多模态图转换器方法的整个框架如图2所示。在不失去一般性的前提下,我们假设下面讨论的最终任务是VQA,同时注意到我们的框架可以应用于其他视觉语言任务,例如多模态问答。
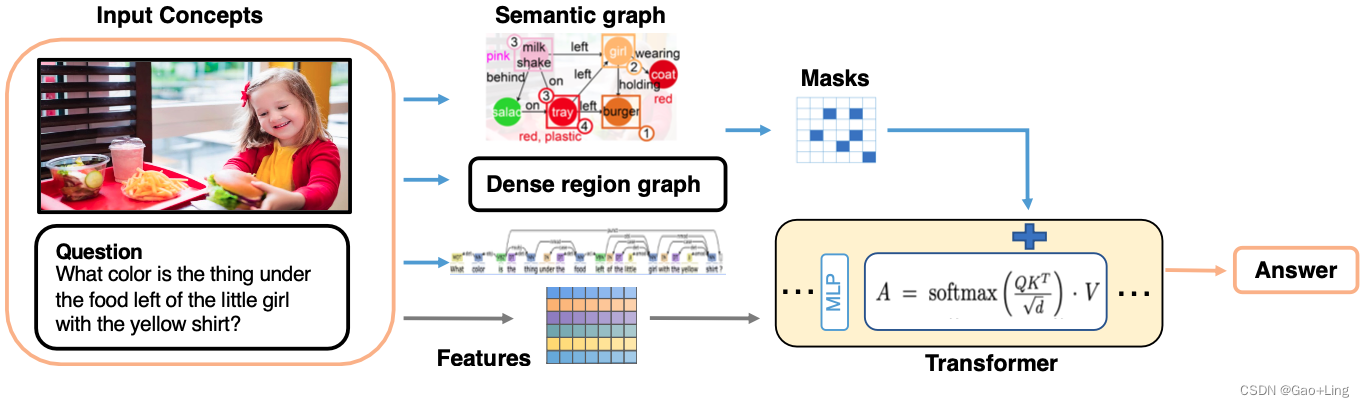
图2:该图说明了我们的Multimodal Graph Transformer的整体框架。来自不同模态的输入被处理并转换成相应的图形,然后转换成掩模并结合其特征馈送到变压器进行下游推理。其中,通过场景图生成方法生成语义图,提取密集区域图作为密连图,通过解析生成文本图。
给定输入的图像和问题,框架首先构建三个图,包括语义图、密集区域图和文本图,这些图将在下面的部分中进行更详细的描述。图G = (V, E),其中V表示图中的节点集,E表示连接它们的边,将图G = (V, E)馈送到transformer中以指导训练过程。
3.3 Multimodal graph construction多模态图的构建
我们构建了三种类型的图,并将它们输入到transformer中:文本图text graph、语义图semantic graph 和 密集区域图anddense region graph。
Text graph
视觉问题回答的任务包括图像、问题和相应答案的组合。为了处理这个问题,我们提取实体并创建一个文本图形表示。我们然后构建了graph g =(V,E),如图2左侧所示。节点集V表示实体,边集E表示实体对之间的关系。这导致:
- N个实体的集合,每个实体由标记嵌入的向量表示,构成图的节点。
- 实体之间的一组成对关系,形成文本图的边缘。实体i和j之间的关系由一个向量e_ij表示,该向量e_ij编码了相对关系。
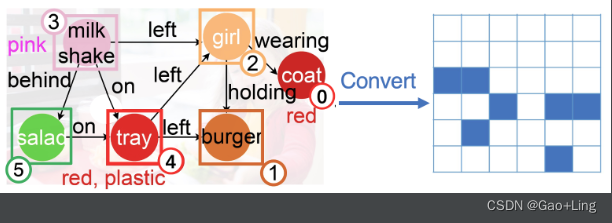
图3:将语义图转换为邻接矩阵的简单演示。蓝色的单元格表示图矩阵中该元素的“0”,而白色的单元格表示“-inf”。在计算准注意力时,我们采用矩阵作为掩模。
Semantic graph
在诸如多模态问答之类的任务中,可能会以表格或长段落句的形式添加额外的输入。为了处理这些输入,可以创建表的线性表示,并使用类似的方法构造语义图。它们使用场景图解析器(Zhong et al., 2021)进行处理,该解析器将文本句子转换为实体和关系的图,如图3所示。场景图解析器的输出包括:
- 构成语义图节点的N个单词的集合,其中N是文本中已解析单词的数量。
- 一组词之间可能的成对关系,如“left”和“on”,如图3所示,它们构成了我们图的边。连接j和i的单词之间的一条边用eij表示,即关联性被表示为:
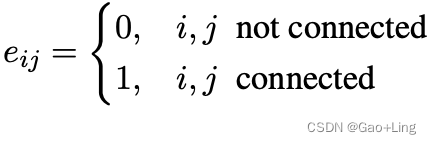
Dense region graph
通过将输入图像切成小块并使其平坦化来提取视觉特征。然后将密集区域图dense region graph G = (V, E)转换为掩码,其中V为提取的视觉特征集,E为连接每个特征节点的边集,方法参见(Kim et al., 2021)。这将得到一个几乎完全连通的图。
然后将生成的三个图转换为邻接矩阵,其中元素为 -∞ 或 零 。
图3以语义图为例描述了转换过程。这些邻接矩阵被用于内标点积注意,通过屏蔽(设置为 -∞ )值来控制信息流。
Graph-involved quasi-attention
为了有效地利用结构化图知识在我们的自注意计算中,我们通过将图转换成邻接矩阵,将图作为每个注意头的额外约束。图矩阵记为G,由多个掩模组合而成。图4显示了这个过程。视觉蒙版由密集区域图生成,文本蒙版由文本图导出。此外,跨模态蒙版被设置为全零矩阵,以鼓励模型学习视觉和文本特征之间的交叉注意,从而促进跨不同模态的对齐。
在添加图形信息的情况下,当视觉图形掩码和文本图形掩码与图像和文本特征相连接和对齐时,我们认为一个更灵活的掩码机制是有益的,而不是在Softmax操作中保持一个单一的恒定掩码矩阵。借鉴Liu等人(2021)的见解,他们在计算相似度时包含了每个头部的相对位置偏差,我们还直观地将可训练偏差G -参数化并将其纳入训练过程。最后,我们计算准注意力如下:
总结