划分聚类 是用于基于数据集的相似性将数据集分类为多个组的聚类方法。我们围绕聚类技术进行一些咨询,帮助客户解决独特的业务问题。
【视频】KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
KMEANS均值聚类和层次聚类:R语言分析生活幸福质量系数可视化实例
,时长06:05
分区聚类,包括:
- K均值聚类 (MacQueen 1967),其中每个聚类由属于聚类的数据点的中心或平均值表示。K-means方法对异常数据点和异常值敏感。
- K-medoids聚类或PAM(Partitioning Around Medoids,Kaufman和Rousseeuw,1990),其中,每个聚类由聚类中的一个对象表示。与k-means相比,PAM对异常值不太敏感。
- CLARA算法(Clustering Large Applications),它是适用于大型数据集的PAM的改进。
对于这些方法中的每一种,我们提供:
- 基本思想和关键概念
- R软件中的聚类算法和实现
- R用于聚类分析和可视化的示例
数据准备:
my_data <- USArrests
# 删除所有缺失值(即NA值不可用)
my_data <- na.omit(my_data)
# 标准化变量
my_data <- scale(my_data)
# 查看开始3行
head(my_data, n = 3)## Murder Assault UrbanPop Rape
## Alabama 1.2426 0.783 -0.521 -0.00342
## Alaska 0.5079 1.107 -1.212 2.48420
## Arizona 0.0716 1.479 0.999 1.04288确定k-means聚类的最佳聚类数:
fviz_nbclust(my_data, kmeans,
method = "gap_stat")## Clustering k = 1,2,..., K.max (= 10): .. done
## Bootstrapping, b = 1,2,..., B (= 100) [one "." per sample]:
## .................................................. 50
## .................................................. 100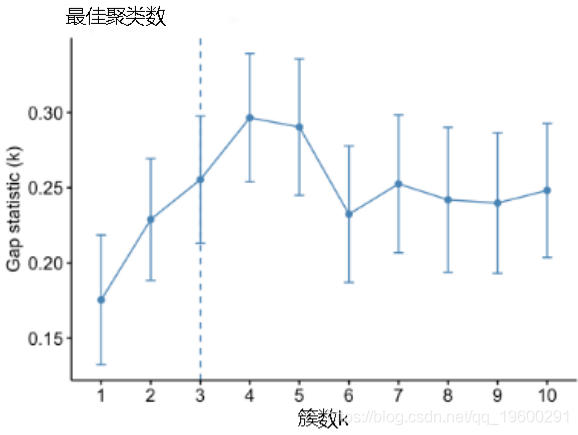
计算和可视化k均值聚类:
fviz_cluster(km.res, data = my_data,
ellipse.type = "convex",
palette = "jco",
repel = TRUE,
ggtheme = theme_minimal())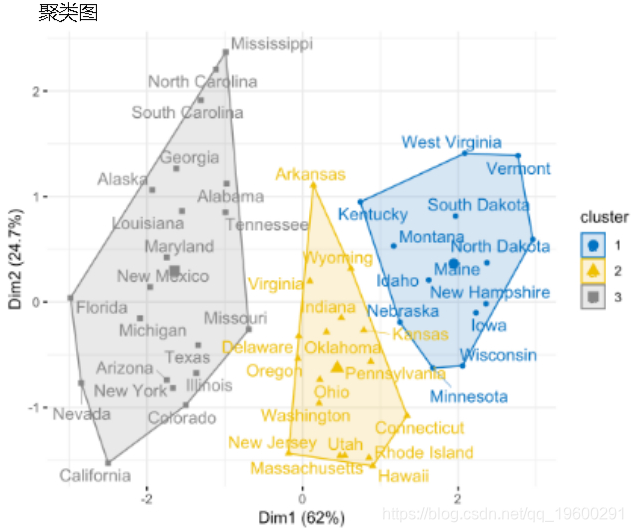
同样,可以如下计算和可视化PAM聚类:
pam.res <- pam(my_data, 4)
# 可视化
fviz_cluster(pam.res)









![[附源码]Python计算机毕业设计Django高校社团管理系统](https://img-blog.csdnimg.cn/fc2937fc5e52471ba6677b1649820598.png)