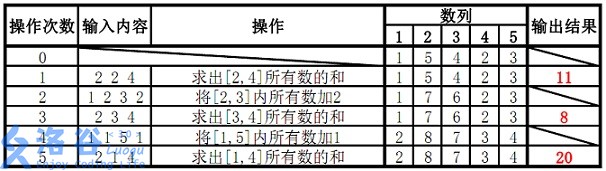
#Lab2A - Leader Election
- I. Source
- II. My Code
- III. Motivation
- IV. Solution
- S1 - 角色转换
- S2 - 发起 RequestVote 拉票请求
- S3 - 收到 RequestVote 的不同反应
- S4 - 发送 AppendEntries 心跳包
- S5 - 收到 AppendEntries 的不同反应
- S6 - defs.go约定俗成和GetState()
- V. Result
I. Source
- MIT-6.824 2020 课程官网
- Lab2: Raft 实验主页
- simviso 精品付费翻译 MIT 6.824 课程
II. My Code
- source code 的 Gitee 地址
- Lab2A: Leader Election 的 Gitee 地址
课程官网提供的 Lab 代码下载地址,我没有访问成功,于是我从 Github 其他用户那里 clone 到干净的源码,有需要可以访问我的 Gitee 获取
III. Motivation
提出 Raft 的主要目的,是为了解决容错问题,即使集群中有一些机器发生了故障,也不影响整体的运作(对外提供的服务)
我用一个 demo 来说明,假设我们的需求一直都是自己的 PC 能够顺利访问云端的资源(HTTP 或数据库)服务器。在服务器稳定在线的情况下,我们去访问它,一点问题都没有
但是,如果那唯一的一台服务器掉线了,那么我们将无法再访问,即对外的服务到此停止。这是我们无法忍受的,我们希望提供服务的一方能够保持稳定,时时刻刻为我提供访问服务。这就是我们的需求
好,现在问题摆在眼前,提供服务的一方怎样保证稳定性?让唯一的那台服务器永远维持稳定的状态,不允许宕机?这非常地不现实,就好比让一个人练成金刚不坏之身
所以,我们只能琢磨是否可以通过添加服务器的数量来确保对外服务的稳定。更近一步,即是现在服务器不再只有一台,扩充到 3 台,这 3 台中有一台是 primary 服务器,也主要由它对外提供服务;其他 2 台是 secondary 服务器(后备力量),拥有和 primary 服务器相同的数据内容
在 primary 服务器出现故障的时候,secondary 服务器顶上去,替代它的位置。这样就可以保持稳定的对外服务了
这就是我们应对资源服务器崩溃的最常用最有效的法子,但是想实现这个想法,首先要解决数据同步的问题,即如何确保 secondary 服务器拥有和 primary 服务器同样的内容?
这个同步问题,在学术上被称为共识算法,最经典的共识算法是 Paxos,但是它太难理解了。于是,斯坦福那帮人想出了更为简便的共识算法,即 Raft
通过 Raft 算法就可以同步集群中服务器的内容。要实现该算法,分三步走,5 - The Raft consensus algorithm 章节中的 Leader Election、Log Replication 和 Safety
本文主要针对第一步,Lab2A: Leader Election 展开讲解,集群只有选出了 leader,才能对外提供服务
IV. Solution
在讲解如何通过代码实现选举之前,先要清楚 Leader Election 的大致流程。只有知道了流程,才能开展编码工作
同样,学习的道理也是如此,只有先从理论上搞清楚这个东西的工作原理是怎样的,以及它是如何构建的,才知道自己应该如何动手
我很喜欢特斯拉的那种精神,他说,他在做实验之前,都会在脑中构思一下,想出蓝图,并反复推演每个细节。在理论上无误的情况下,才会开始实验。而且实验往往很快就能成功
他特别瞧不起爱迪生,嘲讽他一万次才点亮电灯。他大致说爱迪生做了一万次才成功,脑子完全就是浆糊,根本没有去思考为什么出错了,并且从一开始就没有好好地想想其中的原理
一万次才点亮,只能说瞎猫碰到了死耗子,运气好而已,其他的谈不上。很多学习上的事情,确实如此,是要有坚持的精神,但更要有确定正确方向的念头。好,下面正式开始
S1 - 角色转换
为了方便理解,我还是展示一下 Raft 节点主线程中的业务循环,在 raft.go:run() 中,
func (rf *Raft) run() {
for !rf.killed() {
switch rf.role {
case Follower:
select {
case <-rf.grantVoteCh:
case <-rf.heartBeatCh:
case <-time.After(randElectionTimeOut()):
rf.role = Candidate
}
break
case Candidate:
rf.mu.Lock()
rf.curTerm++
rf.votedFor = rf.me
rf.voteCount = 1
rf.mu.Unlock()
go rf.boatcastRV()
select {
case <-time.After(randElectionTimeOut()):
case id := <-rf.heartBeatCh:
/* 一定是收到了来自集群中同期 OR 任期比它大的 leader 的心跳包 */
rf.mu.Lock()
rf.role = Follower
rf.votedFor = id.int /* 被动回滚至 follower */
rf.mu.Unlock()
case <-rf.leaderCh:
/* 赢得了选举 */
rf.role = Leader
}
break
case Leader:
rf.boatcastAE()
time.Sleep(fixedHeartBeatTimeOut())
break
}
}
}
Raft 节点一直在待命着,反应在代码中就是最外层的 for 循环,它根据自己的角色做相应的事情。另外还需要介绍一下 Raft 结构体中的定义,
type Raft struct {
mu sync.Mutex // Lock to protect shared access to this peer's state
peers []*labrpc.ClientEnd // RPC end points of all peers
persister *Persister // Object to hold this peer's persisted state
me int // this peer's index into peers[]
dead int32 // set by Kill()
// Your data here (2A, 2B, 2C).
// Look at the paper's Figure 2 for a description of what
// state a Raft server must maintain.
role Role /* 三个角色 */
voteCount int /* 选票数 */
curTerm int /* 任期号 */
votedFor int /* 投给谁了 */
grantVoteCh chan struct{} /* 是否收到了拉票请求 */
leaderCh chan struct{} /* 是否赢得了选举 */
heartBeatCh chan struct{ int } /* 感知 leader 发来的心跳包 */
}
目前用于 Lab2A: Leader Election 的声明很简单,其中的 grantVoteCh 是用来感知身为 follower 的自己是否有收到拉票请求;leaderCh 是 candidate 用来感知自己是否赢得了选举;而 heartBeatCh 就很常见了,是 follower 和 candidate 用来感知自己是否收到了有效的心跳包。并在 raft.go:newRaft() 中定义其变量,
func newRaft(peers []*labrpc.ClientEnd, me int, persister *Persister, applyCh chan ApplyMsg) *Raft {
rf := &Raft{
peers: peers,
persister: persister,
me: me,
role: Follower,
voteCount: 0,
curTerm: 0,
votedFor: NoBody,
grantVoteCh: make(chan struct{}, ChanCap),
leaderCh: make(chan struct{}, ChanCap),
heartBeatCh: make(chan struct{ int }, ChanCap),
}
return rf
}
注意,这三个均为异步 channel,其容量为 ChanCap = 100
回归流程,follower 满脑子想当 leader,等待选举超时以便发起选举,同时还有两个对外的接口,grantVoteCh 和 heartBeatCh ,前者是 RequestVote() 中用来感知自己收否收到了有效的拉票请求;而后者是 AppendEntries() 中感知自己是否收到了有效的 leader 心跳包;如果收到了 candidate 有效的拉票申请或 leader 有效的心跳包,则重置自己的超时选举计时器
candidate 发起选举,将自己的任期加一并投票给自己;随后,立马发起投票,对应第 19 行的 go rf.boatcastRV() ;然后,线程进入 select 阻塞环节,一直在等待自己赢得选举的好消息 OR 收到集群中新 leader 的心跳包这个坏消息;如果这一轮的拉票没有结果,则继续开启新一轮的选举
而 leader 就简单很多了,成为 leader 就不会主动退位,除非它收到了来自新 leader 的有效心跳包。leader 就干一件事,即定期发送心跳包,对应第 34 行的 rf.boatcastAE()
这就是 Raft 节点之间的角色转换规则,如下图,

集群中每台机器,一开始的角色都是 follower,它们各自都有一个超时计时器,用来决定自己是否应该发起选举。何时应该发起选举呢?自然是等到计时器为 0,即超时了,才会主动跳出来竞争为 leader
而且,每个 follower 的计时器各不相同,是用随机值来设定超时时间的,这在论文的 5.2 - Leader election 中讲的很清楚,一般设为 150–300 ms。简单说一下,将超时时间设置成不同的值,主要是为了避免发生选票分散的情况
试想,现在集群中有 5 位 follower,大家的超时计时器值都相同,在同一时刻都倒计时为 0,都向着除了自己外的其他 4 台机器发起选票
这势必没有一个赢家,5 个人同时竞选,而且每人仅一张票,自己从 follower 变为 candidate 还要投自己一票,哪有功夫再去管别人。所以不可能有人会拿到过多数的选票
Raft 选用一种比较巧妙的随机超时值法,解决了上述的问题。在论文的 5.2 - Leader election 中提到了作者原先是想用排名系统来解决该问题的,但是鉴于该方案过于繁琐,不易理解,所以改用随机超时值的方法
回归正题,follower 发起选举,第一步就是将自己的角色从 follower 转变为 candidate,并且顺手将自己的任期加一。任期很好理解,跟现实世界一样,每个新皇帝刚上任,都会有一个新的年号。这个任期就可以理解成年号
随后,将立即向集群中的其他人发送拉票请求(RequestVote RPC) ,该 RPC 会包含一些重要的元数据,选民根据这些关于 candidate 的元数据来决定是否投票给它
如果 candidate 拿到了超过半数的选票,则直接当选为 leader;反之,则继续发起新的选举,所谓的 “新”,即任期也要累加增一
成为 leader 之后,就立马向集群发送心跳包以巩固自己的地位,raft.go:run() 中的第 33 行 case Leader 之后的代码
S2 - 发起 RequestVote 拉票请求
我们注意到在 Raft 节点成为 candidate 后会主动发起拉票请求,对应 raft.go:run() 的第 19 行 go rf.boatcastRV() ,其中的 go 意味着 rf.boatcastRV() 将会以新协程的方式开启,不会阻塞主线程的工作
这也很好理解,candidate 的拉票请求毕竟只是它自身的一部分,它还是要将重心放在监听自己是否有收到集群中有效心跳包的这件事上来。所以为了不影响这几件事情同时进行,这里选用了协程并发的思想来完成。看下其中的代码 raft.go:boatcastRV() ,
func (rf *Raft) boatcastRV() {
rf.mu.Lock()
args := RequestVoteArgs{
Term: rf.curTerm,
CandidateId: rf.me,
}
rf.mu.Unlock()
for i, _ := range rf.peers {
if i != rf.me && rf.role == Candidate {
go func(id int) {
reply := RequestVoteReply{}
rf.sendRequestVote(id, &args, &reply)
}(i)
}
}
}
该方法做的事情很简单,就是向集群中的其他人发送拉票请求,即 sendRequestVote() 。值得注意的,上锁的颗粒度尽量要细,这样并发起来会更快。在这里我没采用 golang 风格的 defer 延迟释放锁,而是自己手动管理上锁放锁的事宜
我需要展示一下 RequestVote 两个一问一答的 RPC 的声明,
type RequestVoteArgs struct {
// Your data here (2A, 2B).
Term int
CandidateId int
}
type RequestVoteReply struct {
// Your data here (2A).
Term int
VoteGranted bool
}
其中第 4 行的 CandidateId 标明了参选人的编号,第 10 行的 VoteGranted 是为了告诉发起人,我是否认同你
另外,这个拉票请求方法翻译一下,即是广播 RequestVote,方法名应该为 broadcastRequestVote() 才对,我这里为了简短起见,选用了 boatcast 来代替 broadcast ,RequestVote 简写成 RV 。其中的 sendRequestVote() 的定义如下,
func (rf *Raft) sendRequestVote(server int, args *RequestVoteArgs, reply *RequestVoteReply) bool {
ok := rf.peers[server].Call("Raft.RequestVote", args, reply)
rf.mu.Lock()
defer rf.mu.Unlock()
if !ok {
return ok
}
term := rf.curTerm
/* 自身过期的情况下,直接不再唱票 */
if rf.role != Candidate || args.Term != term {
return ok
}
/* 碰到一个任期比自己高的人 */
if reply.Term > term {
rf.curTerm = reply.Term
rf.role = Follower /* candidate 主动回滚至 follower */
rf.votedFor = NoBody
return ok
}
if reply.VoteGranted {
rf.voteCount++
if rf.role == Candidate && rf.voteCount > len(rf.peers)/2 {
rf.role = Leader /* 至关重要 */
rf.leaderCh <- struct{}{}
}
}
return ok
}
第 2 行会调用 Call() RPC 方法,在收到拉票应答时进行唱票。如果在收到票后发现自身已过期,则直接丢票;如果碰见比自己任期更高的选民,则直接回滚至 follower,这是在 S1 - 角色转换 中已经讲过的规则
我通过一个 demo 来讲解上段的代码。试想,现在集群中有 3 台机器。起初,大家都是 followers,A 先发制人,发起了选举,顺利收到了 B 和 C 的选票,成功地当选为 leader
从第 25 行开始说起,A 收到了 B 和 C 的成功回应,假设 B 的应答 RPC 先到达,A 根据第 25 行之后的逻辑,先累加选票数,然后再判断此时的票数是否已经过半
注意第 27 行的另一个条件,即 rf.role == Candidate ,candidate 要保证自身还是 candidate 的情况下,才会去唱票。反过来,如果 candidate 已经成为了 leader 或回滚至 follower,那么就无需再进行角色转换了。说得再直接点,A 收到了 B 的选票后,就已经满足了成为 leader 的条件(票数过半),可以直接忽略 C 的选票结果直接成为 leader 了
最难搞懂的地方,即第 28 行的角色转换操作必须要有,这是为了保证第 28、29 行的操作只执行一次!
有且仅执行一次,转换为选举问题,即是 A 在唱完 B 的选票后,就可以直接成为 leader 而忽略 C 的选票。这一步非常重要,要想通了
试想,如果 A 唱了 B 的票,那么 A 会在它自己的 leaderCh 中写入一个 struct{}{} 。而身为 candidate 的自己,在主线程中时时刻刻在监视着 sendRequestVote() 中的战况(是否选票过半?),一旦成功,它就会立刻成为 leader,结束 raft.go:run() 的 switch candidate 分支的流程,进入 switch leader 分支
在将第 28 行 rf.role == Leader 去掉的情况下,如果 A 在唱完 B 之后接着唱 C 的选票,那么会导致 rf.leaderCh <- struct{}{} 被再执行一次,即在这次选举期间已向 leaderCh 中写入了两个 struct{}{} ,这是非常致命的错误
我用个 demo 来证明,如果去掉第 28 行,那么整个流程就会有非常大的漏洞
假设,集群中还是 3 台机器,起初 A 先发制人成为了 leader,但是由于 A 的网络环境较差,断了联系脱离了集群( leader A 的任期为 1 );此时,B 和 C 发现集群中已无 leader,便都跃跃欲试;结果 B 当选 leader(任期为 2 );过段时间,A 又恢复连接上线了( A 的任期仍然为 1 ),它收到了来自更高任期 leader B 的心跳包后变为了 follower
但是,稳定的情况没维持多久,leader B 和 follower C 又双双掉线了,A 久久没收到了心跳包后,按耐不住要发起选举;成为 candidate 之后,A 发现 leaderCh 中还有一个 struct{}{} ,回想起来是第一次当选 leader 时,唱 B 和 C 两张票向 leaderCh 中写入了两个 struct{}{} 。虽然在第一次当选时读取了一个,但是还剩下一个,在这一次的选举中发挥作用,使得目前仅有一台服务器在线的集群选出了 leader,这本来就是个伪命题,仅有一台在线,它怎么可能获得过半的选票呢?
按照道理来说,即使 B、C 双双掉线,后来上线的 A 也不应该成为 leader!但是,A 靠着第一次当选积累的 leaderCh 的 struct{}{} 却成功当选了
讲到这里,已经可以明白,我们不应该让 sendRequestVote() 两次写入 leaderCh 。可以通过第 27 行的 rf.role == candidate 和第 28 行的 rf.role = leader 角色转换来给写入操作加上限制,让这个写入操作仅做一次
这样,就可以避免上述提出的 candidate 快速当选 leader 的荒谬问题
S3 - 收到 RequestVote 的不同反应
如果 candidate 的任期小于自身,则直接拒绝为其投票;反之,就需要好好考虑了,且看一下代码,
func (rf *Raft) RequestVote(args *RequestVoteArgs, reply *RequestVoteReply) {
// Your code here (2A, 2B).
rf.mu.Lock()
defer rf.mu.Unlock()
/* 默认不投票 */
reply.VoteGranted = false
reply.Term = rf.curTerm
if args.Term < rf.curTerm {
return
}
/* 也可能是为了镇压任期较旧的 leader */
if args.Term > rf.curTerm {
rf.curTerm = args.Term
rf.role = Follower
rf.votedFor = NoBody /* 为臣服做准备 */
}
if rf.votedFor == NoBody || rf.votedFor == args.CandidateId {
rf.role = Follower
rf.votedFor = args.CandidateId /* 臣服于 leader */
reply.VoteGranted = true
rf.grantVoteCh <- struct{}{} /* 如果投票给他人,那么就需要重置自己的 ElectionTimeOut */
}
}
最后决定该不该投票重点在第 21 行的条件判断,如 5 - The Raft consensus algorithm 的所讲到的,如果选民手里还有票 OR 已经投给你,则继续作为 follower 臣服于你
通过写入 grantVoteCh 告诉 Raft 主线程,当前我已收到了有效的拉票申请,恳请自己不要乱碰哒,继续老老实实作为 follower 即可
S4 - 发送 AppendEntries 心跳包
在 candidate 成为 leader 之后,要立刻通过 sendAppendEntries() 向集群中发送心跳包,以巩固自己的领导地位,对应 raft.go:run() 的第 34 行 rf.boatcastAE() ,
func (rf *Raft) boatcastAE() {
rf.mu.Lock()
args := AppendEntriesArgs{
Term: rf.curTerm,
LeaderId: rf.me,
}
rf.mu.Unlock()
for i, _ := range rf.peers {
if i != rf.me && rf.role == Leader {
go func(id int) {
reply := AppendEntriesReply{}
rf.sendAppendEntries(id, &args, &reply)
}(i)
}
}
}
以及 sendAppendEntries() 的定义如下,
func (rf *Raft) sendAppendEntries(server int, args *AppendEntriesArgs, reply *AppendEntriesReply) bool {
ok := rf.peers[server].Call("Raft.AppendEntries", args, reply)
rf.mu.Lock()
defer rf.mu.Unlock()
if !ok {
return ok
}
term := rf.curTerm
/* 自身过期的情况下,不需要在维护 nextIdx 了 */
if rf.role != Leader || args.Term != term {
return ok
}
/* 仅仅是被动退位,不涉及到需要投票给谁 */
if reply.Term > term {
rf.curTerm = reply.Term
rf.role = Follower /* 主动回滚至 follower */
rf.votedFor = NoBody
return ok
}
return ok
}
和 S2 - 发起 RequestVote 拉票请求 一样,唯一需要注意的,就是 leader 的退位是被动的,只有它收到了任期比它还高的回绝时,它才会从 leader 回滚至 follower。换句话说,leader 不会因为 followers 不服它而自暴自弃
S5 - 收到 AppendEntries 的不同反应
和 S3 - 收到 RequestVote 的不同反应 差不多,
func (rf *Raft) AppendEntries(args *AppendEntriesArgs, reply *AppendEntriesReply) {
rf.mu.Lock()
defer rf.mu.Unlock()
reply.Success = false
reply.Term = rf.curTerm
if args.Term < rf.curTerm {
return
}
/* 心跳包只对 follower 和 candidate 管用,leader 是不会响应它的 */
rf.heartBeatCh <- struct{ int }{args.LeaderId}
/* 主要为了让旧 leader 收到了新 leader 的心跳包后而被迫退位 */
if args.Term > rf.curTerm {
rf.curTerm = args.Term
rf.role = Follower
rf.votedFor = NoBody
}
rf.votedFor = args.LeaderId /* 臣服于 leader,仅适用 Lab2A Leader election */
reply.Success = true
}
如果任期比自己的还小,则直接回绝;反之,则继续老老实实的作 follower。需要注意的可能情况,即是旧 leader 会收到新 leader 的心跳包,这时候就需要考虑被动退位的情况了,即对应代码中的第 14 行的情况。之后,还需要告诉 leader:我已臣服于你
另外,两个 AppendEntries RPC 的声明如下,
type AppendEntriesArgs struct {
Term int
LeaderId int
}
type AppendEntriesReply struct {
Term int
Success bool
}
S6 - defs.go约定俗成和GetState()
在构建 Raft 的过程中,会用到一些较为固定的值,比如角色、超时时间,我在 defs.go 中定义,
package raft
import (
"math/rand"
"time"
)
type Role int
const (
NoBody = -1
Follower = 0
Candidate = 1
Leader = 2
ChanCap = 100
ElectionTimeOut = 250 * time.Millisecond /* 要远大于论文中的 150-300 ms 才有意义,当然也要保证在 5 秒之内完成测试 */
HeartBeatTimeOut = 100 * time.Millisecond /* 心跳 1 秒不超过 10 次 */
)
// 生成随机超时时间,在 250ms~500 ms 范围之内
func randElectionTimeOut() time.Duration {
r := rand.New(rand.NewSource(time.Now().UnixNano()))
t := time.Duration(r.Int63()) % ElectionTimeOut
return ElectionTimeOut + t
}
// 生成固定的心跳时间,固定值为 110 ms
func fixedHeartBeatTimeOut() time.Duration {
return HeartBeatTimeOut
}
论文中虽然讲到,超时选举值在 150~300 ms 之间较为合适,但是 Lab2: Raft 实验主页 中提示我们不能这样做,设定的值要远大于论文中规定的值才有意义。原话是这样说的,
The paper’s Section 5.2 mentions election timeouts in the range of 150 to 300 milliseconds. Such a range only makes sense if the leader sends heartbeats considerably more often than once per 150 milliseconds. Because the tester limits you to 10 heartbeats per second, you will have to use an election timeout larger than the paper’s 150 to 300 milliseconds, but not too large, because then you may fail to elect a leader within five
并且,心跳时间也应该大于 100 ms,即原话的每秒钟心跳不超过 10 次
最后,还需要实现 raft.go:GetState() ,这是测试的接口,用来检测 Raft 节点的状态,
func (rf *Raft) GetState() (int, bool) {
var term int
var isleader bool
// Your code here (2A).
term = rf.curTerm
isleader = rf.role == Leader
return term, isleader
}
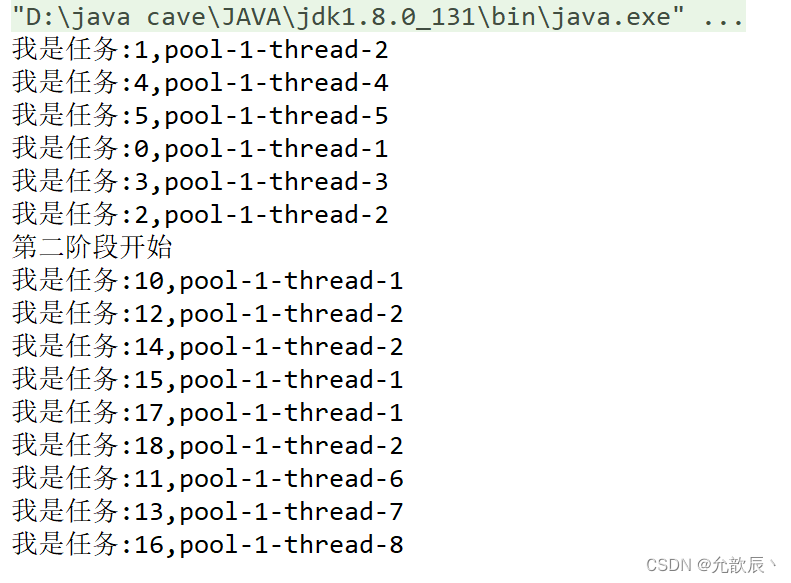
V. Result
golang 比较麻烦,它有 GOPATH 模式,也有 GOMODULE 模式,6.824-golabs-2020 采用的是 GOPATH,所以在运行之前,需要将 golang 默认的 GOMODULE 关掉,
$ export GO111MODULE="off"
随后,就可以进入 src/raft 中开始运行测试程序,
$ go test -run 2A
仅此一次的测试远远不够,可以通过 shell 循环,让测试跑个千把次,
$ for i in {1..1000}; go test -run 2A
这样,如果还没错误,那应该是真的通过了。分布式的很多 bug 需要通过反复模拟才能复现出来的,它不像单线程程序那样,永远是幂等的情况