一、具体介绍
timm 是一个 PyTorch 原生实现的计算机视觉模型库。它提供了预训练模型和各种网络组件,可以用于各种计算机视觉任务,例如图像分类、物体检测、语义分割等等。
timm 的特点如下:
- PyTorch 原生实现:timm 的实现方式与 PyTorch 高度契合,开发者可以方便地使用 PyTorch 的 API 进行模型训练和部署。
- 轻量级的设计:timm 的设计以轻量化为基础,根据不同的计算机视觉任务,提供了多种轻量级的网络结构。
- 大量的预训练模型:timm 提供了大量的预训练模型,可以直接用于各种计算机视觉任务。
- 多种模型组件:timm 提供了各种模型组件,如注意力模块、正则化模块、激活函数等等,这些模块都可以方便地插入到自己的模型中。
- 高效的代码实现:timm 的代码实现高效并且易于使用。
需要注意的是,timm 是一个社区驱动的项目,它由计算机视觉领域的专家共同开发和维护。在使用时需要遵循相关的使用协议。
二、图像分类案例
下面以使用 timm 实现图像分类任务为例,进行简单的介绍。
2.1 安装 timm 包
!pip install timm
2.2 导入相关模块,读取数据集
import torch
import torch.nn as nn
import timm
import torchvision.transforms as transforms
from torchvision.datasets import CIFAR10
# 数据增强
train_transforms = transforms.Compose([
transforms.RandomCrop(size=32, padding=4),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomRotation(degrees=15),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
test_transforms = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# 数据集
train_dataset = CIFAR10(root='data', train=True, download=True, transform=train_transforms)
test_dataset = CIFAR10(root='data', train=False, download=True, transform=test_transforms)
# DataLoader
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True, num_workers=4)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False, num_workers=4)
导入相关模块,其中 timm 和 torchvision.datasets.CIFAR10 需要分别安装 timm 和 torchvision 包。
定义数据增强的方式,其中训练集和测试集分别使用不同的增强方式,并且对图像进行了归一化处理。transforms.Compose() 可以将各种操作打包成一个 transform 操作流,transforms.ToTensor() 将图像转化为 tensor 格式,transforms.Normalize() 将图像进行标准化处理。
使用自带的 CIFAR10 数据集,设置 train=True 定义训练集,设置 train=False 定义测试集。数据集会自动下载到指定的 root 路径下,并进行数据增强操作。
使用 torch.utils.data.DataLoader 定义数据加载器,将数据集包装成一个高效的可迭代对象,其中 batch_size 定义批次大小,shuffle 定义是否对数据进行随机洗牌,num_workers 定义使用多少个 worker 来加载数据。

2.3 定义模型
# 加载预训练模型
model = timm.create_model('resnet18', pretrained=True)
# 修改分类器
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(train_dataset.classes))
这里使用 timm.create_model() 函数来创建一个预训练模型,其中参数 resnet18 定义了使用的模型架构,参数 pretrained = True 表示要使用预训练权重。
这里修改了模型的分类器,首先使用 model.fc.in_features 获取模型 fc 层的输入特征数,然后使用 nn.Linear() 重新定义了一个 nn.Linear 层,输入为上一层的输出特征数,输出为类别数(即 len(train_dataset.classes))。这里直接使用了数据集类别数来定义输出层,以适配不同分类任务的需求。

在这里,我们使用了 timm 中的 ResNet18 模型,并将其修改为我们需要的分类器,同时在创建模型时,设置参数 pretrained=True 来加载预训练权重。
2.4 定义损失函数和优化器
# 损失函数
criterion = nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
在深度学习中,损失函数是评估模型预测结果与真实标签之间差异的一种指标,常用于模型训练过程中。nn.CrossEntropyLoss() 是一个常用的损失函数,适用于多分类问题。
优化器用于更新模型参数以使损失函数最小化。在这里,我们使用了随机梯度下降法(SGD)优化器,以控制模型权重的变化。通过 model.parameters() 指定需要优化的参数,lr 定义了学习率,表示每次迭代时参数必须更新的量的大小,momentum 则是添加上次迭代更新值的一部分到这一次的更新值中,以减小参数更新的方差,稳定训练过程。
2.5 训练模型
num_epochs = 10
for epoch in range(num_epochs):
# 训练
model.train()
for images, labels in train_loader:
# 前向传播
outputs = model(images)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 测试
model.eval()
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
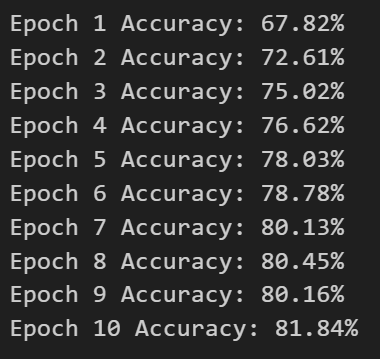
print('Epoch {} Accuracy: {:.2f}%'.format(epoch+1, 100*correct/total))
这段代码是模型训练和测试的循环。num_epochs 定义了循环的次数,每次循环表示一个训练周期。
在训练阶段,首先将模型切换到训练模式,然后使用 train_loader 迭代地读取训练集数据,进行前向传播、计算损失、反向传播和优化器更新等操作。
在测试阶段,模型切换到评估模式,然后使用 test_loader 读取测试集数据,进行前向传播和计算模型预测结果,使用预测结果和真实标签进行准确率计算,并输出每个训练周期的准确率。
其中,torch.max() 函数用于返回每行中最大值及其索引,total 记录了总的测试样本数,correct 记录了正确分类的样本数,最后计算准确率并输出。
输出结果为: