文章目录
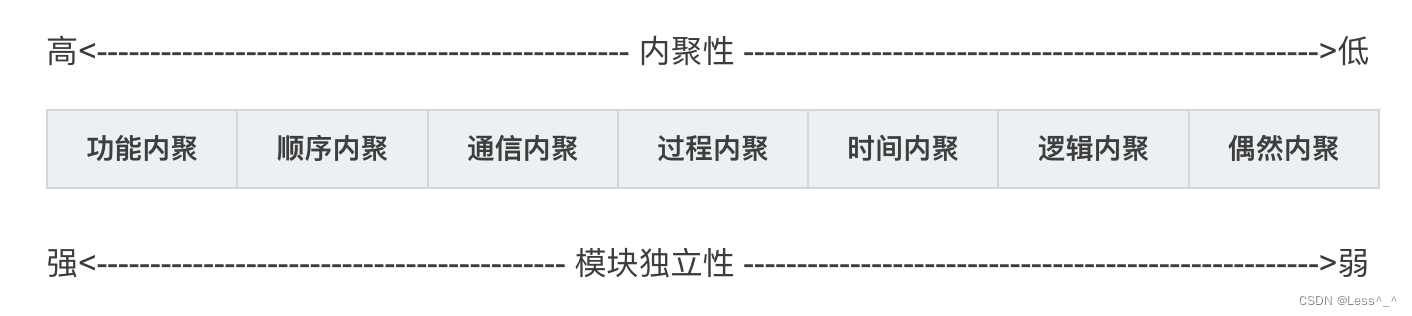
- 1. 目的
- 2. 设计
- 3. 串行实现
- 4. 并行实现
- 5. 比对:耗时和正确性
- 6. 加速比探讨

1. 目的
读取单张图像,计算整图均值,这很好实现,运行耗时很短。
读取4000张相同大小的图像,分别计算均值,这也很好实现,运行耗时则较长。
对于单张图的读取、单张图的均值计算,可以认为 OpenCV 已经做了不错的优化。因此主要从多线程角度出发,用多个CPU核心分别读图、分别计算均值。
最终的耗时:从48.78秒降低到5.36秒。以下具体展开。
2. 设计
- 给出串行的实现,并测量耗时
- 给出并行的实现,并测量耗时
- 测量耗时:使用先前博文中给出的 Timer 类 C++: 计时器类的设计和实现
- 并行实现:使用先前博文中给出的线程安全队列 Queue 类 C++:设计一个线程安全的队列
- 串行和并行实现的结果比对:分别把结果写入文本文件
- 每个结果的形式: 图像名字, b通道均值,g通道均值,r通道均值
- 使用 VSCode / Beyond Compare / diff 命令 等方式, 比对差异
- 使用 fmtlib 实现字符串格式化
- 使用 c++11 thread 创建多线程(pthread亦可)
3. 串行实现
定义基础数据结构:
class Result
{
public:
Result() = default;
Result(std::string img_name, cv::Scalar& m):
image_name(img_name), mean(m)
{}
public:
std::string image_name;
cv::Scalar mean;
};
static void write_result_to_txt(const std::vector<Result>& vec, const std::string filename)
{
std::ofstream fout(filename);
for (int i = 0; i < image_num; i++)
{
const Result& res = vec[i];
const std::string& img_name = res.image_name;
const cv::Scalar& m = res.mean;
fout << fmt::format("{} {:f}{:f}{:f}\n", img_name, m.val[0], m.val[1], m.val[2]);
}
}
串行代码的核心实现:
int sequential_read_and_process(digimon::Timer& timer)
{
timer.start();
const std::string img_dir = get_image_dir();
std::vector<Result> vec(image_num);
for (int i = 0; i < image_num; i++)
{
const std::string img_name = fmt::format("{:06d}.png", i);
const std::string img_path = img_dir + "/" + img_name;
cv::Mat im = cv::imread(img_path);
cv::Scalar m = cv::mean(im);
vec[i] = Result(img_name, m);
}
timer.stop();
write_result_to_txt(vec, "sequential_result.txt");
return 0;
}
4. 并行实现
void read_and_process(int startIdx, int endIdx, digimon::Queue<Result>& result_queue)
{
const std::string img_dir = get_image_dir();
for (int i = startIdx; i < endIdx; i++)
{
const std::string img_name = fmt::format("{:06d}.png", i);
const std::string img_path = img_dir + "/" + img_name;
cv::Mat im = cv::imread(img_path);
cv::Scalar m = cv::mean(im);
Result res(img_name, m);
result_queue.push(res);
}
}
int parallel_read_and_process(digimon::Timer& timer)
{
timer.start();
std::vector<std::thread> threads(16);
digimon::Queue<Result> result_queue;
for (size_t i = 0; i < threads.size(); i++)
{
int startIdx = i * (image_num / threads.size());
int endIdx = (i == threads.size() - 1) ? image_num : ((i + 1) * (image_num / threads.size()));
threads[i] = std::thread(read_and_process, startIdx, endIdx, std::ref(result_queue));
}
for (size_t i = 0; i < threads.size(); i++)
{
threads[i].join();
}
timer.stop();
std::vector<Result> vec(image_num);
for (int i = 0; i < image_num; i++)
{
vec[i] = result_queue.pop();
}
std::sort(vec.begin(), vec.end(), [](const Result& r1, const Result& r2){
return r1.image_name < r2.image_name;
});
write_result_to_txt(vec, "parallel_result.txt");
return 0;
}
5. 比对:耗时和正确性
int main()
{
{
digimon::Timer timer1(false);
sequential_read_and_process(timer1);
std::cout << fmt::format("sequential_read_and_process(): {:6.2f} s\n", timer1.getElapsedAsSecond());
}
{
digimon::Timer timer2(false);
parallel_read_and_process(timer2);
std::cout << fmt::format("parallel_read_and_process(): {:6.2f} s\n", timer2.getElapsedAsSecond());
}
return 0;
}
耗时:开启了16个线程,耗时从48.78秒降低到5.36秒:
zz@Legion-R7000P% ./testbed
sequential_read_and_process(): 48.78 s
parallel_read_and_process(): 5.36 s
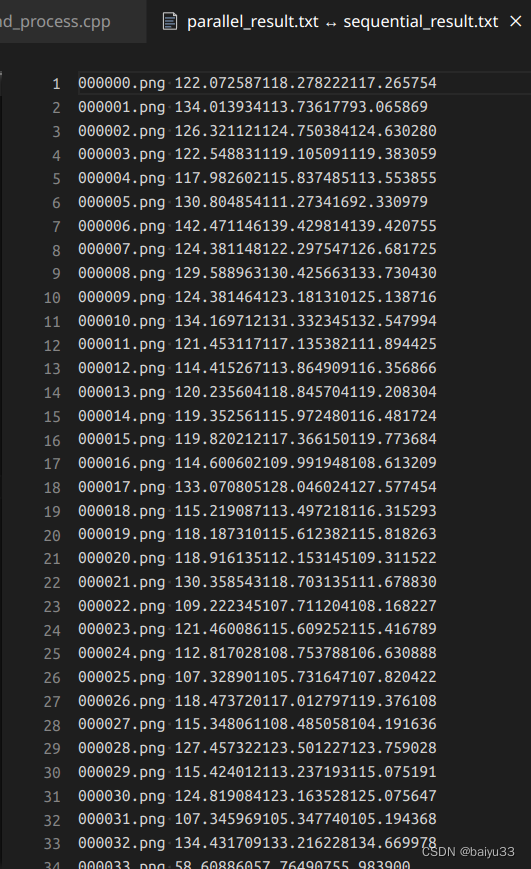
正确性比对:diff 结果为空, 说明完全一致
zz@Legion-R7000P% diff parallel_result.txt sequential_result.txt
注意检查文本内容本身非空:
6. 加速比探讨
开启多线程后确实有加速的,但是加速比例并没有达到线程数量, 原因主要是CPU温度升高, 一方面频率有所降低, 另一方面会限制实际并行的CPU数量。
这一点在 macbook pro 电脑上可能更明显:
- 在开启了Chrome,VSode等应用时, 单个进程 CPU 利用率只能达到300%左右, 整个电脑CPU占用率50%左右;
- 关掉各种应用程序,冷却电脑一会儿,大概降低温度到45度,重新运行,耗时得到明显降低(24秒->13秒),CPU占用率从50%升高到100%