散列表的查找
简介:散列表(也成哈希表)是一种高效的数据结构,他可以在平均复杂度为O(1)的情况下实现查找、插入和删除操作。
哈希表的基本思想是根据关键字的值来计算其应存储的位置。这个计算过程就是通过哈希函数来实现的。
根据哈希函数H(),来确定关键字的存储位置。这个过程表示为:Hash(key)=Addr或Loc(i) = H(keyi)(这里的地址可以使数组下标、索引或内存地址等)。
基本术语:
- 散列方法(杂凑法):这是一种通过函数(散列函数)计算元素存储位置的方法。查找时,同样使用这个函数对给定的键计算地址,然后通过比较键和地址单元中元素的键来确定查找是否成功。
- 散列函数(杂凑函数):在散列方法中使用的转换函数,用于将键转换成数组索引(也就是元素在散列表中的位置)。
- 散列表(杂凑表):这是一个有限的连续存储空间,用来存储散列函数计算得到的相应散列地址的数据记录。散列表通常是一个一维数组,散列地址是数组的下标。
- 冲突:当两个或更多的键被散列函数映射到同一个散列地址时,就会发生冲突。冲突在散列表中是无法避免的,但我们可以通过一些方法尽可能地减少冲突。
- 同义词:这是指具有相同散列值(也就是通过散列函数计算得到的地址)的多个键。这些键会被映射到散列表的同一个位置,这就可能会导致冲突。
通过上述定义,我们可以知道散列表有能够快速定位关键字的存储位置的能力,下面来介绍一下散列表的主要特点:
- 高效的查找速度:理想情况下,哈希表的查找、插入和删除操作的时间复杂度都是O(1)。这是因为哈希表通过哈希函数直接定位到元素的存储位置,避免了下线性查找的时间开销。
- 处理冲突:在哈希表中,可能会出现不同的关键字被哈希函数映射到同一位置的情况,这被称为哈希冲突。哈希表需要通过某些方法来处理这些冲突。
- 动态扩容:当哈希表中的元素超过了一定比例(通常是装载因子超过0.7或0.75)时,为了维持哈希表的性能,通常需要对哈希表进行扩容,即增加哈希表的大小。这通常需要重新哈希所有的元素,所有扩容是一个昂贵的操作。
- 空间换时间:哈希表通常需要比实际存储的数据更多的空间,这是为了保证哈希表的性能。(牺牲空间换时间的策略)
- 无序性:由于哈希函数的映射关系,哈希表中元素的存储位置与元素的值无关,因此哈希表中的元素是无序的。如果需要有序的数据结构,那么哈希表可能不是一个好的选择。
散列函数的构造方法
在构造良好的哈希函数时,需要注意一下几个要求:
- 哈希函数的定义域必须包括全部需要存储的关键字,而值域的范围则依赖于散列表的大小和地址范围。
- 哈希函数的计算速度直接影响哈希表的性能,因此哈希函数要求尽可能简单,以提高转换速度。
- 哈希函数要求尽可能使所有元素在哈希表中均匀分布,以减少冲突和空间浪费。
- 考虑关键字的长度、散列表的大小、关键字的分布情况和查找频率:这些因素会影响到哈希函数的设计和效果。
制定有效的冲突解决方案:即使哈希函数设计得很好,冲突也是无法避免的。因此,我们需要制定一个好的冲突解决方案,如链地址法或开放定址法等。
下面我们来介绍几个常用的散列函数:
直接定址法
它是最简单的一种哈希函数,它直接把关键字或者关键字的某个线性函数值作为哈希地址。即:H(key) = key 或 H(key) = a*key + b。
-
优点:简单,易于理解和实现。
-
缺点:可能导致哈希表的空间利用率低。
-
使用范围:当关键字的的全域直接对应哈希表的大小时。
除留取余法
这种方法是把关键字除以某个不大于哈希表长度的数,然后取余数作为哈希地址。即:H(key) = key MOD p,其中 p 一般取小于或等于哈希表长度的最大质数。
除留取余法的关键是选好p,使得每个关键字通过该函数转换后等概率地映射到散列空间上的任意一个地址,以减少冲突的可能。
- 优点:简单,实现容易,对表长不敏感,适应性强。
- 缺点:取余数操作可能会导致关键字的特性失效,从而导致分布不均匀。
- 适用范围:当关键字的分布均匀且表长未知时。
数字分析法
这种方法是先观察关键字的分布情况,然后选择取关键字中独特的部分作为哈希地址。
平方取中法
这种方法是先把关键字平方,然后取平方数的中间几位作为哈希地址。这种方法适用于关键字本身无规律,但关键字平方后的中间几位数字分布比较均匀的情况。
折叠法
这种方法是把关键字分为几部分,然后把这几部分组合在一起,以求得哈希地址。折叠法有移位折叠和边界折叠两种。
-
位移折叠:位移折叠将关键字分为固定长度的几部分(通常是相等长度),然后将这些部分相加得到哈希地址。具体步骤如下:
- 将关键字按照固定长度分割为若干部分(通常是相等长度)。
- 将这些部分相加得到哈希地址。
例如,假设关键字是 12345678,固定长度为 2,则可以将关键字分割为 [12, 34, 56, 78],然后将这些部分相加得到哈希地址 12 + 34 + 56 + 78 = 180。
-
边界折叠:边界折叠将关键字分为固定长度的几部分,但最后一部分可以是不完整的。然后,将所有部分按照一定规则相加得到哈希地址。具体步骤如下:
- 将关键字按照固定长度分割为若干部分(通常是相等长度),最后一部分可以是不完整的。
- 根据需要,将最后一部分的剩余位数进行填充(通常填充为0)。
将所有部分按照一定规则相加得到哈希地址。 - 例如,假设关键字是 12345678,固定长度为 2,则可以将关键字分割为 [12, 34, 56, 78]。由于最后一部分只有两位,不完整,我们可以将其填充为 7800。然后,将所有部分相加得到哈希地址 12 + 34 + 56 + 7800 = 7882。
随机数法
这种方法是选择一个随机函数,把关键字的随机值作为哈希地址。这种方法适用于关键字长度不等的情况。
代码实现
#include<stdio.h>
#include<stdlib.h>
// 哈希表的大小
#define HASH_SIZE 100
// 直接定址法
// H(key) = key
int directAddress(int key)
{
return key;
}
// 除留取余法
// H(key) = key mod p (p <= m)
int division(int key)
{
int p = 97;
return key % p;
}
// 平方取中法
// H(key) = key^2的中间几位
int midSquare(int key)
{
// key^2
int square = key * key;
// 通常除以100(移除后两位)然后再对10000取余(取中间四位)
// 只适合四位数的键,对于其他位数的键,需要修改
return (square / 100) % 10000;
}
// 折叠法 (位移折叠)
// H(key) = key的若干位相加,然后将这几部分组合在一起
int foldShift(int key)
{
int part1 = key / 10000; // 取前两位
int part2 = key % 10000; // 取后两位
return part1 + part2;
}
// 折叠法(边界折叠)
// H(key) = 将key分为几部分,然后将这几部分组合在一起
int foldBoundary(int key) {
int part1 = key / 10000; // 前两位
int part2 = key % 10000; // 后两位
return part1 + part2;
}
// 随机出法
// H(key) = 随机函数
int random(int key)
{
return rand()%HASH_SIZE; // 生成0到HASH_SIZE-1之间的随机数
}
int main() {
int key = 12345678;
printf("Direct Address: %d\n", directAddress(key));
printf("Division: %d\n", division(key));
printf("Mid-Square: %d\n", midSquare(key));
printf("Fold-Shift: %d\n", foldShift(key));
printf("Fold-Boundary: %d\n", foldBoundary(key));
printf("Random: %d\n", random(key));
return 0;
}
处理冲突的方法
应该注意到,任何设计出来的哈希函数都不能绝对避免冲出。对此,必须考虑在发生冲突时应该如何处理,即为产生冲突的关键字寻找下一个“空”的哈希地址。用Hi表示处理冲突中第 i 次探测得到的哈希地址,假设得到的另一个散列地址H1仍然发生冲突,只得继续求下一个哈希地址H2,以此类推,知道Hk不发生冲突为止,则Hk为关键字在表中的地址。
开放定址法
开放地址法是指可存放新表项的空闲地址[既向它的同义词表项开放,又向它的非同义词表项开放](#解释 补充)。其数学递推公式为:
Hi = (H(key) + di) % m
其中 di 是冲突时的增量,也就是上面所提到的"它的同义词表项开放,又向它的非同义词表项开放"的过程。这个增量的选择取决于具体的冲突解决策略,通常有以下4种取法:
- 线性探测法:当di = 0,1,2…m-1时,成为线性探测法。这种方法的特点是:冲突发生时,顺序查看表中下一个单元(探测到表尾地址 m-1 时,下一个探测地址是表首地址0),知道找出一个空闲单元(当表未填满时一定能找到一个空闲单元)或查边全表。线性探测法可能使第 i 个散列地址的同义词存入第 i + 1 个散列地址,这样本应存入第 i + 1 个散列地址的元素就争夺第 i + 2 个散列地址的元素的地址……从而造成大量元素在相邻的散列地址上==“聚集”(或堆积)==起来,大大降低了查找效率。
- 平方探测法(二次探测法):它的增量序列是一个二次序列,如12,-12,22,-22,…,q2。它可以在一定程度上减少"聚簇"现象,但是增量序列的选择需要谨慎,以避免跳过某些空位置。
- 双散列法:当 d = Hash2(key)时,称为双散列法。需要用到两个哈希函数,在发生冲突时,使用第一个散列函数计算出一个增量值,然后将这个增量值与第二个散列函数的计算结果相结合,得到新的哈希地址。它的具体哈希函数形式:Hi = (H(key) + i * Hash2(key)) % m
- 伪随机序列法:它的增量序列是一个伪随机数序列。
注意:在开放定址的情形下,不能随便物理删除表中的已有元素,因为若删除元素,则会截断其他具有相同散列地址的元素的查找地址。
因此,在开放定址法中,常常使用逻辑删除的方式来标记要删除的元素,而不是直接物理删除。逻辑删除是将要删除的元素做一个特殊的标记,表示该位置上的元素已经被删除,但实际上仍然保留在哈希表中。
逻辑删除的优点是避免了截断其他具有相同散列地址的元素的查找地址,但它也会导致一个副作用。随着多次逻辑删除的执行,哈希表看起来可能会变得很满,实际上有很多未利用的位置。为了解决这个问题,需要定期维护散列表,即定期对哈希表进行重新哈希或重建,将逻辑删除的元素物理删除,从而回收未利用的位置,保持哈希表的性能。
代码实现
typedef struct
{
int* data; // 哈希表的数据
int size; // 哈希表的大小
} HashTable;
//创建一个新的哈希表
HashTable *createHashTable(int size)
{
HashTable* table = (HashTable*)malloc(sizeof(HashTable));
table->data = (int*)malloc(sizeof(int) * size);
// 初始化哈希表
for(int i = 0; i < size; i++)
{
table->data[i] = -1; // -1表示该位置没有被使用
}
table->size = size;
return table;
}
//假设哈希函数直接返回对应地址
int hash(int key)
{
return key;
}
// 线性探测插入
void lineProbingInsert(HashTable* table, int key)
{
int index = hash(key) % table->size;
while (table->data[index]!=-1) // 如果该位置已经被使用
{
index = (index + 1)% table->size; // 线性探测下一个位置
}
//找到了一个空位置,将关键字插入
table->data[index] = key;
}
// 二次探测插入
void quadraticProbingInsert(HashTable* table, int key) {
int index = hash(key) % table->size;
int i = 1;
while (table->data[index] != -1) { // 如果这个位置已经被占用了
index = (index + i * i) % table->size; // 则根据二次探测法计算下一个位置
i++;
}
// 找到了一个空位置,将关键字插入
table->data[index] = key;
}
链地址法(拉链法)
基本思想:它是将哈希表中的每个位置都存储一个链表的头指针,每个链表包含具有相同散列地址的键值对。
具体步骤如下:
- 根据给定的哈希函数计算每个键的散列地址。
- 若该地址对应的链表为空,则将键值对插入该链表。
- 若该地址对应的链表不为空,则根据选择的冲突处理方法,在该链表上执行插入操作。可以使用链表的前插法或后插法将键值对插入到链表中。
通过链地址法,非同义词不会发生冲突,因为它们被存储在不同的链表中,避免了聚集现象。链表的空间是动态申请的,所以链地址法更适合于表长不确定的情况,可以灵活地调整链表的大小。然而,链地址法也存在一些缺点,例如在查找特定键值对时需要遍历整个链表,可能会导致较长时间的查找时间。另外链表的存储空间额外消耗了一些内存。
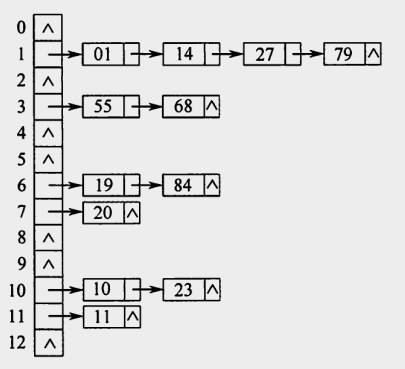
如下是关键字序列{19, 14, 23, 01, 68, 20, 84, 27, 55, 11,10, 79},散列函数H (key) =key%13,用拉链法处理冲突,如下图所示:
代码实现
#include <stdio.h>
#include <stdlib.h>
// 定义链表的节点
typedef struct Node {
int key; // 用于存储元素的键
int data; // 用于存储元素的值
struct Node* next; // 指向下一个节点的指针
} Node;
// 定义哈希表
typedef struct HashTable {
int size; // 哈希表的大小
Node** table; // 存储链表头节点的指针数组
} HashTable;
// 创建一个新的节点
Node* createNode(int key, int data) {
Node* newNode = (Node*)malloc(sizeof(Node)); // 动态分配内存空间
newNode->key = key; // 设置键
newNode->data = data; // 设置值
newNode->next = NULL; // 初始化下一个节点的指针为NULL
return newNode; // 返回新节点的指针
}
// 创建一个新的哈希表
HashTable* createHashTable(int size) {
HashTable* newTable = (HashTable*)malloc(sizeof(HashTable)); // 动态分配内存空间
newTable->size = size; // 设置哈希表的大小
newTable->table = (Node**)malloc(sizeof(Node*) * size); // 动态分配存储链表头节点的指针数组的内存空间
for (int i = 0; i < size; i++) {
newTable->table[i] = NULL; // 初始化每个链表的头节点的指针为NULL
}
return newTable; // 返回新哈希表的指针
}
// 散列函数
int hash(int key) {
return key % 13; // 返回键除以13的余数
}
// 插入元素
void insert(HashTable* table, int key, int data) {
// 计算散列地址
int index = hash(key);
// 创建新节点
Node* newNode = createNode(key, data);
// 如果散列地址对应的链表为空,则直接插入
if (table->table[index] == NULL) {
table->table[index] = newNode;
}
else {
// 如果散列地址对应的链表不为空,则插入到链表的头部(前插法)
/*
前插法的基本步骤是:
newNode->next = table->table[index]; 这一行是将新节点的 next 指向原来链表的头节点。这样,新节点就连接上了原来的链表。
table->table[index] = newNode; 这一行是将新节点设置为新的头节点。因为哈希表的 table[index] 存的是链表头节点的地址,我们将它设为 newNode,即新节点成为了链表的头部。
*/
newNode->next = table->table[index];
table->table[index] = newNode;
}
}
// 打印哈希表
void printHashTable(HashTable* table) {
for (int i = 0; i < table->size; i++) {
printf("slot[%d]: ", i);
Node* temp = table->table[i];
while (temp) {
printf("%d -> ", temp->data);
temp = temp->next;
}
printf("NULL\n");
}
}
int main() {
// 创建一个大小为13的哈希表
HashTable* table = createHashTable(13);
// 插入元素
insert(table, 19, 19);
insert(table, 14, 14);
insert(table, 23, 23);
insert(table, 1, 1);
insert(table, 68, 68);
insert(table, 20, 20);
insert(table, 84, 84);
insert(table, 27, 27);
insert(table, 55, 55);
insert(table, 11, 11);
insert(table, 10, 10);
insert(table, 79, 79);
// 打印哈希表
printHashTable(table);
return 0;
}
散列查找及性能分析
散列表的查找过程和构造散列表的过程基本一致。对于一个给定的关键字key,根据散列函数可以计算出其散列地址,算法步骤如下:
初始化:Addr = Hash(key)
- 检测查找表中地址为Addr的位置上是否有记录,若无记录,返回查找失败;若有记录,比较它与key 的值,若相等,则返回查找成功,否则执行步骤2
- 用给定的处理冲突的方法计算“下一个散列地址”,并把Addr置为此地址,转入步骤1。
例如,关键字序列{19, 14, 23, 01, 68, 20, 84, 27, 55, 11, 10, 79}按散列函数H(key) = key%13和线性探测处理冲突构造所得的散列表L如图所示:

给定值84的查找过程为:首先求得散列地址H(84)=6,因L[6]不空且L[6]≠84,则找
第一次冲突处理后的地址H1=(6+1)%16=7,而L[7]不空且L[7]≠84,则找第二次冲突处理后
的地址H2=(6+2)%16=8, L[8]不空且L[8]=84,查找成功,返回记录在表中的序号8。
查找各关键字的比较次数如图所示:

平均查找长度ASL为: ASL = (1*6+2+3*3+4+9)/12 = 2.5
从散列表的查找过程可见:
(1)虽然散列表在关键字与记录的存储位置之间建立了直接映像,但由于“冲突”的产生,使得散列表的查找过程仍然是-一个给定值和关键字进行比较的过程。因此,仍需要以平均查找长度作为衡量散列表的查找效率的度量。
(2)散列表的查找效率取决于三个因素:散列函数、处理冲突的方法和装填因子。
装填因子。散列表的装填因子一般记为α,定义为一个表的装满程度,即:
α = 表中记录数 n / 散列表长度 m α = {表中记录数n}/{散列表长度m} α=表中记录数n/散列表长度m
散列表的平均查找长度依赖于散列表的装填因子α,而不直接依赖于n或m。直观地看,α越大,表示装填的记录越“满”,发生冲突的可能性越大,反之发生冲突的可能性越小。
解释 补充
在哈希表的上下文中,"同义词"通常指的是具有相同哈希值的键。也就是说,如果两个键通过哈希函数计算得到的哈希值相同,那么它们就是同义词。这种情况通常会导致哈希冲突,因为哈希表无法在同一位置存储两个键值对。
相反,"非同义词"就是哈希值不同的键。理论上,非同义词应该被存储在哈希表的不同位置。然而,由于哈希表的大小是有限的,所以可能出现两个非同义词却被哈希到同一位置的情况,这也会导致哈希冲突。
在开放定址法中,如果发生哈希冲突,无论是同义词还是非同义词,都会寻找新的哈希地址来存储键值对。这就是"向它的同义词表项开放,又向它的非同义词表项开放"的含义。