本篇将使用以下几个梯度下降算法进行对比:
不使用任何的优化算法(即整批数据集作为一次迭代更新梯度,也叫batch梯度下降,BGD)
mini-batch梯度下降法(Mini-batchGD)
使用具有动量的梯度下降算法(Momentum)
使用Adam算法(Momentum和RMSprob的结合)
导入
首先导入先后向传播等所需的函数的opt_utils.py:
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import sklearn
import sklearn.datasets
def sigmoid(x):
"""
Compute the sigmoid of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- sigmoid(x)
"""
s = 1 / (1 + np.exp(-x))
return s
def relu(x):
"""
Compute the relu of x
Arguments:
x -- A scalar or numpy array of any size.
Return:
s -- relu(x)
"""
s = np.maximum(0, x)
return s
def load_params_and_grads(seed=1):
np.random.seed(seed)
W1 = np.random.randn(2, 3)
b1 = np.random.randn(2, 1)
W2 = np.random.randn(3, 3)
b2 = np.random.randn(3, 1)
dW1 = np.random.randn(2, 3)
db1 = np.random.randn(2, 1)
dW2 = np.random.randn(3, 3)
db2 = np.random.randn(3, 1)
return W1, b1, W2, b2, dW1, db1, dW2, db2
def initialize_parameters(layer_dims):
"""
Arguments:
layer_dims -- python array (list) containing the dimensions of each layer in our network
Returns:
parameters -- python dictionary containing your parameters "W1", "b1", ..., "WL", "bL":
W1 -- weight matrix of shape (layer_dims[l], layer_dims[l-1])
b1 -- bias vector of shape (layer_dims[l], 1)
Wl -- weight matrix of shape (layer_dims[l-1], layer_dims[l])
bl -- bias vector of shape (1, layer_dims[l])
Tips:
- For example: the layer_dims for the "Planar Data classification model" would have been [2,2,1].
This means W1's shape was (2,2), b1 was (1,2), W2 was (2,1) and b2 was (1,1). Now you have to generalize it!
- In the for loop, use parameters['W' + str(l)] to access Wl, where l is the iterative integer.
"""
np.random.seed(3)
parameters = {}
L = len(layer_dims) # number of layers in the network
for l in range(1, L):
parameters['W' + str(l)] = np.random.randn(layer_dims[l], layer_dims[l - 1]) * np.sqrt(2 / layer_dims[l - 1])
parameters['b' + str(l)] = np.zeros((layer_dims[l], 1))
assert (parameters['W' + str(l)].shape == layer_dims[l], layer_dims[l - 1])
assert (parameters['W' + str(l)].shape == layer_dims[l], 1)
return parameters
def forward_propagation(X, parameters):
"""
Implements the forward propagation (and computes the loss) presented in Figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
parameters -- python dictionary containing your parameters "W1", "b1", "W2", "b2", "W3", "b3":
W1 -- weight matrix of shape ()
b1 -- bias vector of shape ()
W2 -- weight matrix of shape ()
b2 -- bias vector of shape ()
W3 -- weight matrix of shape ()
b3 -- bias vector of shape ()
Returns:
loss -- the loss function (vanilla logistic loss)
"""
# retrieve parameters
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
W3 = parameters["W3"]
b3 = parameters["b3"]
# LINEAR -> RELU -> LINEAR -> RELU -> LINEAR -> SIGMOID
z1 = np.dot(W1, X) + b1
a1 = relu(z1)
z2 = np.dot(W2, a1) + b2
a2 = relu(z2)
z3 = np.dot(W3, a2) + b3
a3 = sigmoid(z3)
cache = (z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3)
return a3, cache
def backward_propagation(X, Y, cache):
"""
Implement the backward propagation presented in figure 2.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- true "label" vector (containing 0 if cat, 1 if non-cat)
cache -- cache output from forward_propagation()
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(z1, a1, W1, b1, z2, a2, W2, b2, z3, a3, W3, b3) = cache
dz3 = 1. / m * (a3 - Y)
dW3 = np.dot(dz3, a2.T)
db3 = np.sum(dz3, axis=1, keepdims=True)
da2 = np.dot(W3.T, dz3)
dz2 = np.multiply(da2, np.int64(a2 > 0))
dW2 = np.dot(dz2, a1.T)
db2 = np.sum(dz2, axis=1, keepdims=True)
da1 = np.dot(W2.T, dz2)
dz1 = np.multiply(da1, np.int64(a1 > 0))
dW1 = np.dot(dz1, X.T)
db1 = np.sum(dz1, axis=1, keepdims=True)
gradients = {"dz3": dz3, "dW3": dW3, "db3": db3,
"da2": da2, "dz2": dz2, "dW2": dW2, "db2": db2,
"da1": da1, "dz1": dz1, "dW1": dW1, "db1": db1}
return gradients
def compute_cost(a3, Y):
"""
Implement the cost function
Arguments:
a3 -- post-activation, output of forward propagation
Y -- "true" labels vector, same shape as a3
Returns:
cost - value of the cost function
"""
m = Y.shape[1]
logprobs = np.multiply(-np.log(a3), Y) + np.multiply(-np.log(1 - a3), 1 - Y)
cost = 1. / m * np.sum(logprobs)
return cost
def predict(X, y, parameters):
"""
This function is used to predict the results of a n-layer neural network.
Arguments:
X -- data set of examples you would like to label
parameters -- parameters of the trained model
Returns:
p -- predictions for the given dataset X
"""
m = X.shape[1]
p = np.zeros((1, m), dtype=np.int)
# Forward propagation
a3, caches = forward_propagation(X, parameters)
# convert probas to 0/1 predictions
for i in range(0, a3.shape[1]):
if a3[0, i] > 0.5:
p[0, i] = 1
else:
p[0, i] = 0
# print results
# print ("predictions: " + str(p[0,:]))
# print ("true labels: " + str(y[0,:]))
print("Accuracy: " + str(np.mean((p[0, :] == y[0, :]))))
return p
def predict_dec(parameters, X):
"""
Used for plotting decision boundary.
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (m, K)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Predict using forward propagation and a classification threshold of 0.5
a3, cache = forward_propagation(X, parameters)
predictions = (a3 > 0.5)
return predictions
def plot_decision_boundary(model, X, y):
# Set min and max values and give it some padding
x_min, x_max = X[0, :].min() - 1, X[0, :].max() + 1
y_min, y_max = X[1, :].min() - 1, X[1, :].max() + 1
h = 0.01
# Generate a grid of points with distance h between them
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
# Predict the function value for the whole grid
Z = model(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# Plot the contour and training examples
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)
plt.ylabel('x2')
plt.xlabel('x1')
plt.scatter(X[0, :], X[1, :], c=y, cmap=plt.cm.Spectral)
plt.show()
def load_dataset(is_plot=True):
np.random.seed(3)
train_X, train_Y = sklearn.datasets.make_moons(n_samples=300, noise=.2) # 300 #0.2
# Visualize the data
if is_plot:
plt.scatter(train_X[:, 0], train_X[:, 1], c=train_Y, s=40, cmap=plt.cm.Spectral)
plt.show()
train_X = train_X.T
train_Y = train_Y.reshape((1, train_Y.shape[0]))
return train_X, train_Y
然后是各个优化算法的测试输入的函数的testCase.py:
# -*- coding: utf-8 -*-
import numpy as np
def update_parameters_with_gd_test_case():
np.random.seed(1)
learning_rate = 0.01
W1 = np.random.randn(2, 3)
b1 = np.random.randn(2, 1)
W2 = np.random.randn(3, 3)
b2 = np.random.randn(3, 1)
dW1 = np.random.randn(2, 3)
db1 = np.random.randn(2, 1)
dW2 = np.random.randn(3, 3)
db2 = np.random.randn(3, 1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
return parameters, grads, learning_rate
"""
def update_parameters_with_sgd_checker(function, inputs, outputs):
if function(inputs) == outputs:
print("Correct")
else:
print("Incorrect")
"""
def random_mini_batches_test_case():
np.random.seed(1)
mini_batch_size = 64
X = np.random.randn(12288, 148)
Y = np.random.randn(1, 148) < 0.5
return X, Y, mini_batch_size
def initialize_velocity_test_case():
np.random.seed(1)
W1 = np.random.randn(2, 3)
b1 = np.random.randn(2, 1)
W2 = np.random.randn(3, 3)
b2 = np.random.randn(3, 1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
def update_parameters_with_momentum_test_case():
np.random.seed(1)
W1 = np.random.randn(2, 3)
b1 = np.random.randn(2, 1)
W2 = np.random.randn(3, 3)
b2 = np.random.randn(3, 1)
dW1 = np.random.randn(2, 3)
db1 = np.random.randn(2, 1)
dW2 = np.random.randn(3, 3)
db2 = np.random.randn(3, 1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
v = {'dW1': np.array([[0., 0., 0.],
[0., 0., 0.]]), 'dW2': np.array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]), 'db1': np.array([[0.],
[0.]]),
'db2': np.array([[0.],
[0.],
[0.]])}
return parameters, grads, v
def initialize_adam_test_case():
np.random.seed(1)
W1 = np.random.randn(2, 3)
b1 = np.random.randn(2, 1)
W2 = np.random.randn(3, 3)
b2 = np.random.randn(3, 1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
return parameters
def update_parameters_with_adam_test_case():
np.random.seed(1)
v, s = ({'dW1': np.array([[0., 0., 0.],
[0., 0., 0.]]), 'dW2': np.array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]), 'db1': np.array([[0.],
[0.]]),
'db2': np.array([[0.],
[0.],
[0.]])}, {'dW1': np.array([[0., 0., 0.],
[0., 0., 0.]]), 'dW2': np.array([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]]),
'db1': np.array([[0.],
[0.]]), 'db2': np.array([[0.],
[0.],
[0.]])})
W1 = np.random.randn(2, 3)
b1 = np.random.randn(2, 1)
W2 = np.random.randn(3, 3)
b2 = np.random.randn(3, 1)
dW1 = np.random.randn(2, 3)
db1 = np.random.randn(2, 1)
dW2 = np.random.randn(3, 3)
db2 = np.random.randn(3, 1)
parameters = {"W1": W1, "b1": b1, "W2": W2, "b2": b2}
grads = {"dW1": dW1, "db1": db1, "dW2": dW2, "db2": db2}
return parameters, grads, v, s
batch梯度下降
梯度更新公式为:
W
[
l
]
=
W
[
l
]
−
α
d
W
[
l
]
W ^{[l]} = W ^{[l]} −α dW ^{[l]}
W[l]=W[l]−αdW[l]
b
[
l
]
=
b
[
l
]
−
α
d
b
[
l
]
b ^{[l]} = b ^{[l]} −α db ^{[l]}
b[l]=b[l]−αdb[l]
以下为测试代码:
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
import scipy.io
import math
import sklearn
import sklearn.datasets
import opt_utils
import testCase
plt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
def update_parameters_with_gd(parameters, grads, learning_rate):
"""
使用梯度下降更新参数
参数:
parameters - 字典,包含了要更新的参数:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads - 字典,包含了每一个梯度值用以更新参数
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
learning_rate - 学习率
返回值:
parameters - 字典,包含了更新后的参数
"""
L = len(parameters) // 2 # 神经网络的层数
# 更新每个参数
for l in range(L):
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * grads["dW" + str(l + 1)]
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * grads["db" + str(l + 1)]
return parameters
parameters, grads, learning_rate = testCase.update_parameters_with_gd_test_case()
parameters = update_parameters_with_gd(parameters, grads, learning_rate)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
运行输出为:
W1 = [[ 1.63535156 -0.62320365 -0.53718766]
[-1.07799357 0.85639907 -2.29470142]]
b1 = [[ 1.74604067]
[-0.75184921]]
W2 = [[ 0.32171798 -0.25467393 1.46902454]
[-2.05617317 -0.31554548 -0.3756023 ]
[ 1.1404819 -1.09976462 -0.1612551 ]]
b2 = [[-0.88020257]
[ 0.02561572]
[ 0.57539477]]
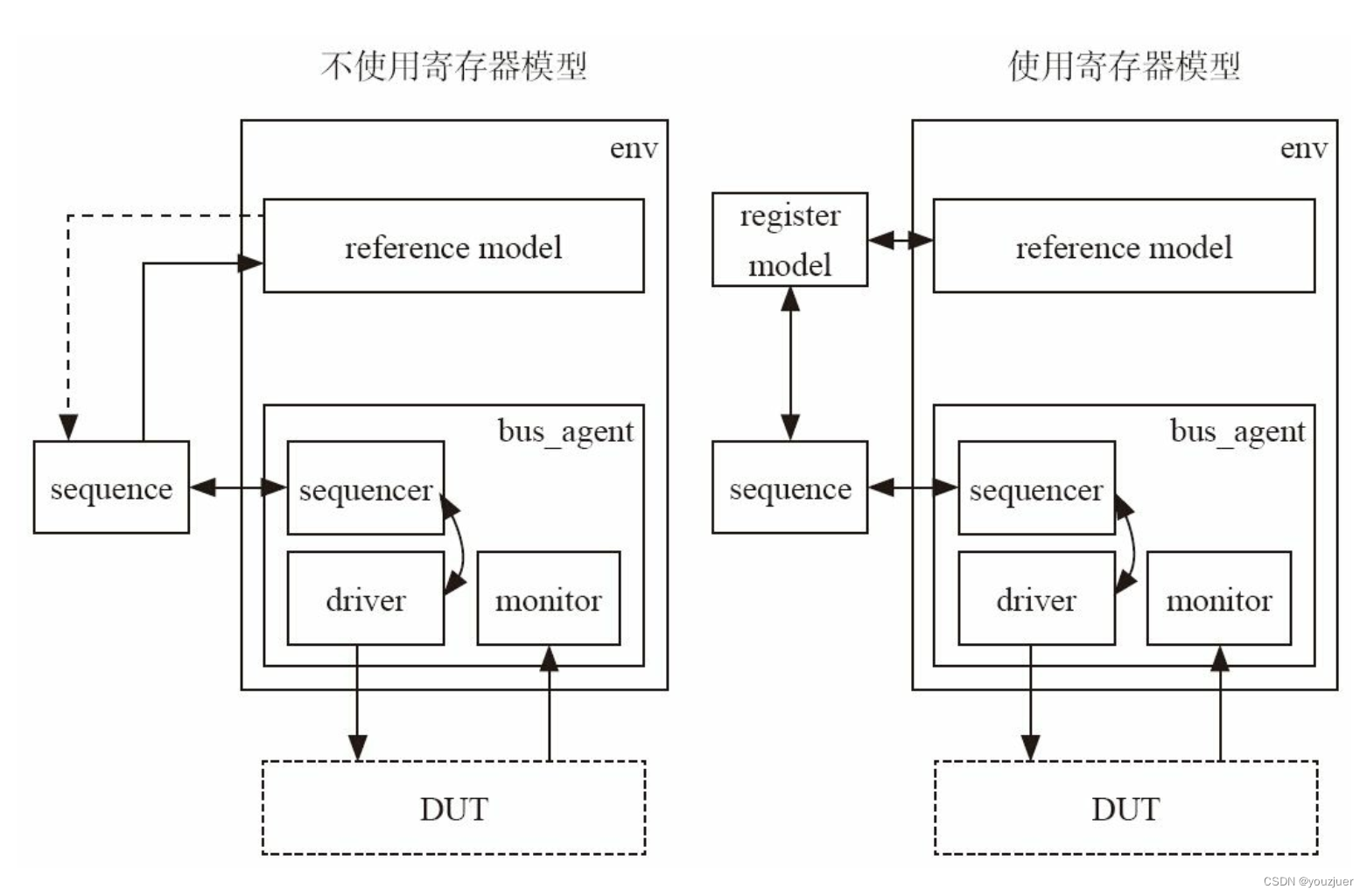
BGD的一次迭代是对整批训练集进行计算并更新参数,好处是直接向全局最优的方向直接前进,但缺点就是当数据集非常大上万上百万的时候,计算一次会非常久显然是不现实的。
当时用SGD即一次迭代是对一个样本进行计算并更新参数时,参数更新非常快,但不是向全局最优的方向直接前进平稳收敛而是波动前进向着最小值摆动。
他们之间的对比如图:

对比代码:
# BGD
X = data_input
Y = labels
parameters = initialize_parameters(layers_dims)
for i in range(0,num_iterations): # 每训练整批数据集更新一次
#前向传播
A,cache = forward_propagation(X,parameters)
#计算损失
cost = compute_cost(A,Y)
#反向传播
grads = backward_propagation(X,Y,cache)
#更新参数
parameters = update_parameters(parameters,grads)
# SGD
X = data_input
Y = labels
parameters = initialize_parameters(layers_dims)
for i in (0,num_iterations): # 每训练一个样本更新一次
for j in m:
#前向传播
A,cache = forward_propagation(X,parameters)
#计算成本
cost = compute_cost(A,Y)
#后向传播
grads = backward_propagation(X,Y,cache)
#更新参数
parameters = update_parameters(parameters,grads)
还有一种方法是小批量(mini-batch)梯度下降法,他不是一次训练整批数据集也不是一次只训练一个样本,而是把所有的数据集分割为一小块一小块的来学习,它会随机选择一小块(mini-batch),块大小一般为2的n次方倍。一方面,充分利用的GPU的并行性,更一方面,不会让计算时间特别长。折中了BGD和SGD。
下面是SGD和Mini-batchGD的对比图:

Mini-batchGD
两个步骤:打乱数据集(每个样本的排列顺序)、根据mini-batch size分割数据集。
Mini-batchGD每次选择一个mini-batch size的样本块进行学习并更新参数,下面是制作Mini-batchGD数据格式的代码:
def random_mini_batches(X, Y, mini_batch_size=64, seed=0):
"""
从(X,Y)中创建一个随机的mini-batch列表
参数:
X - 输入数据,维度为(输入节点数量,样本的数量)
Y - 对应的是X的标签,【1 | 0】(蓝|红),维度为(1,样本的数量)
mini_batch_size - 每个mini-batch的样本数量
返回:
mini-bacthes - 一个同步列表,维度为(mini_batch_X,mini_batch_Y)
"""
np.random.seed(seed) # 指定随机种子
m = X.shape[1]
mini_batches = []
# 第一步:打乱顺序
permutation = list(np.random.permutation(m)) # 它会返回一个长度为m的随机数组,且里面的数是0到m-1。若参数是数组,则对数组里的数打乱顺序
shuffled_X = X[:, permutation] # 将每一列的数据按permutation的顺序来重新排列。
shuffled_Y = Y[:, permutation].reshape((1, m))
"""
# 如果不好理解的话请看一下下面的伪代码,看看X和Y是如何根据permutation来打乱顺序的。
x = np.array([[1,2,3,4,5,6,7,8,9],
[9,8,7,6,5,4,3,2,1]])
y = np.array([[1,0,1,0,1,0,1,0,1]])
random_mini_batches(x,y)
permutation= [7, 2, 1, 4, 8, 6, 3, 0, 5]
shuffled_X= [[8 3 2 5 9 7 4 1 6]
[2 7 8 5 1 3 6 9 4]]
shuffled_Y= [[0 1 0 1 1 1 0 1 0]]
"""
# 第二步,分割
num_complete_minibatches = math.floor(m / mini_batch_size) # 把你的训练集分割成多少份,请注意,如果值是99.99,那么返回值是99,剩下的0.99会被舍弃
for k in range(0, num_complete_minibatches):
mini_batch_X = shuffled_X[:, k * mini_batch_size:(k + 1) * mini_batch_size]
mini_batch_Y = shuffled_Y[:, k * mini_batch_size:(k + 1) * mini_batch_size]
"""
a = np.array([[1,2,3,4,5,6,7,8,9],
[9,8,7,6,5,4,3,2,1],
[1,2,3,4,5,6,7,8,9]])
k=1
mini_batch_size=3
print(a[:,1*3:(1+1)*3]) #从第4列到第6列
'''
[[4 5 6]
[6 5 4]
[4 5 6]]
'''
k=2
print(a[:,2*3:(2+1)*3]) #从第7列到第9列
'''
[[7 8 9]
[3 2 1]
[7 8 9]]
'''
"""
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
# 如果训练集的大小刚好是mini_batch_size的整数倍,那么这里已经处理完了
# 如果训练集的大小不是mini_batch_size的整数倍,那么最后肯定会剩下一些,我们要把它处理了
if m % mini_batch_size != 0:
# 获取最后剩余的部分
mini_batch_X = shuffled_X[:, mini_batch_size * num_complete_minibatches:]
mini_batch_Y = shuffled_Y[:, mini_batch_size * num_complete_minibatches:]
mini_batch = (mini_batch_X, mini_batch_Y)
mini_batches.append(mini_batch)
return mini_batches
测试并查看制作的数据:
X_assess, Y_assess, mini_batch_size = testCase.random_mini_batches_test_case()
mini_batches = random_mini_batches(X_assess, Y_assess, mini_batch_size)
print("第1个mini_batch_X 的维度为:", mini_batches[0][0].shape)
print("第1个mini_batch_Y 的维度为:", mini_batches[0][1].shape)
print("第2个mini_batch_X 的维度为:", mini_batches[1][0].shape)
print("第2个mini_batch_Y 的维度为:", mini_batches[1][1].shape)
print("第3个mini_batch_X 的维度为:", mini_batches[2][0].shape)
print("第3个mini_batch_Y 的维度为:", mini_batches[2][1].shape)
运行结果如下:
第1个mini_batch_X 的维度为: (12288, 64)
第1个mini_batch_Y 的维度为: (1, 64)
第2个mini_batch_X 的维度为: (12288, 64)
第2个mini_batch_Y 的维度为: (1, 64)
第3个mini_batch_X 的维度为: (12288, 20)
第3个mini_batch_Y 的维度为: (1, 20)
Momentum
Mini-batchGD每次选择一个mini-batch size的样本块进行更新,由于每批数据都存在一定的差异,所以更新方向也会有所差异,还是会有震荡。使用MomentumGD会减缓摆动的幅度,因为计算了梯度的指数加权平均,参考了过去梯度(当然也有一部分比重来参考当前的梯度,这样才能朝着最优方向),使得更加平滑的收敛。
用图形解释大概是这个样子:

步骤如下:
首先创建一个和dW、db的结构相同的初始化变量
V
d
W
V_{dW}
VdW和
V
d
b
V_{db}
Vdb(0变量):
def initialize_velocity(parameters):
"""
初始化速度,velocity是一个字典:
- keys: "dW1", "db1", ..., "dWL", "dbL"
- values:与相应的梯度/参数维度相同的值为零的矩阵。
参数:
parameters - 一个字典,包含了以下参数:
parameters["W" + str(l)] = Wl
parameters["b" + str(l)] = bl
返回:
v - 一个字典变量,包含了以下参数:
v["dW" + str(l)] = dWl的速度
v["db" + str(l)] = dbl的速度
"""
L = len(parameters) // 2 # 神经网络的层数
v = {}
for l in range(L):
v["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)]) # 创建一个和w的shape相同的全0矩阵
v["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
return v
测试并查看初始化函数:
parameters = testCase.initialize_velocity_test_case()
v = initialize_velocity(parameters)
print('v["dW1"] = ' + str(v["dW1"]))
print('v["db1"] = ' + str(v["db1"]))
print('v["dW2"] = ' + str(v["dW2"]))
print('v["db2"] = ' + str(v["db2"]))
运行结果如下:
v["dW1"] = [[0. 0. 0.]
[0. 0. 0.]]
v["db1"] = [[0.]
[0.]]
v["dW2"] = [[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
v["db2"] = [[0.]
[0.]
[0.]]
我们将使用以下公式进行Momentum的梯度下降:
v
d
W
=
β
v
d
W
+
(
1
−
β
)
d
W
,
v
d
b
=
β
v
d
b
+
(
1
−
β
)
d
b
v_{dW} =βv_{dW} +(1−β)dW , v_{db} =βv_{db} +(1−β)db
vdW=βvdW+(1−β)dW,vdb=βvdb+(1−β)db
W
=
W
−
α
v
d
W
,
b
=
b
−
α
v
d
b
W =W - \alpha v_{dW} , b =b - \alpha v_{db}
W=W−αvdW,b=b−αvdb
β是动量参数,是一个实数,通常为0.9;
α是学习率。
Momentum梯度更新代码如下:
def update_parameters_with_momentun(parameters, grads, v, beta, learning_rate):
"""
使用动量更新参数
参数:
parameters - 一个字典类型的变量,包含了以下字段:
parameters["W" + str(l)] = Wl
parameters["b" + str(l)] = bl
grads - 一个包含梯度值的字典变量,具有以下字段:
grads["dW" + str(l)] = dWl
grads["db" + str(l)] = dbl
v - 包含当前速度的字典变量,具有以下字段:
v["dW" + str(l)] = ...
v["db" + str(l)] = ...
beta - 超参数,动量,实数
learning_rate - 学习率,实数
返回:
parameters - 更新后的参数字典
v - 包含了更新后的速度变量
"""
L = len(parameters) // 2
for l in range(L):
# 计算速度
v["dW" + str(l + 1)] = beta * v["dW" + str(l + 1)] + (1 - beta) * grads["dW" + str(l + 1)]
v["db" + str(l + 1)] = beta * v["db" + str(l + 1)] + (1 - beta) * grads["db" + str(l + 1)]
# 更新参数
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * v["dW" + str(l + 1)]
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * v["db" + str(l + 1)]
return parameters, v
进行测试并查看相关参数:
parameters, grads, v = testCase.update_parameters_with_momentum_test_case()
update_parameters_with_momentun(parameters, grads, v, beta=0.9, learning_rate=0.01)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
print('v["dW1"] = ' + str(v["dW1"]))
print('v["db1"] = ' + str(v["db1"]))
print('v["dW2"] = ' + str(v["dW2"]))
print('v["db2"] = ' + str(v["db2"]))
运行结果如下:
W1 = [[ 1.62544598 -0.61290114 -0.52907334]
[-1.07347112 0.86450677 -2.30085497]]
b1 = [[ 1.74493465]
[-0.76027113]]
W2 = [[ 0.31930698 -0.24990073 1.4627996 ]
[-2.05974396 -0.32173003 -0.38320915]
[ 1.13444069 -1.0998786 -0.1713109 ]]
b2 = [[-0.87809283]
[ 0.04055394]
[ 0.58207317]]
v["dW1"] = [[-0.11006192 0.11447237 0.09015907]
[ 0.05024943 0.09008559 -0.06837279]]
v["db1"] = [[-0.01228902]
[-0.09357694]]
v["dW2"] = [[-0.02678881 0.05303555 -0.06916608]
[-0.03967535 -0.06871727 -0.08452056]
[-0.06712461 -0.00126646 -0.11173103]]
v["db2"] = [[0.02344157]
[0.16598022]
[0.07420442]]
因为Momentum用了指数加权平均,而指数加权平均在初期会有些偏差,所以Momentum在初期也有。我们可以将
v
d
W
1
−
β
t
\frac{v_{dW}}{1 - \beta ^ t}
1−βtvdW(当t越大
β
t
\beta ^ t
βt就越接近0,所以可以修正前期的偏差),但一般来说我们不会进行偏差修正,因为移动平均过了初始阶段,就不再是具有偏差的预测了(一般训练迭代的次数也不会太低)。
β
\beta
β的值越大,对上一个值的占比越大,摆动也就越小,但偏差也会越大(对当前梯度的占比小了)。一般来说,
β
\beta
β为0.9是最合适的值。
除了可以使用Momentum来减少摆动外我们还可以使用Adam既减小摆动又能一开始就能很快的速度向最优方向前进。
Adam
Adam是Momentum和RMSprob的结合体,RMSprob梯度更新的公式为:
s
d
W
=
β
s
d
W
+
(
1
−
β
)
d
W
2
,
s
d
b
=
β
s
d
b
+
(
1
−
β
)
d
b
2
s_{dW} = \beta s_{dW} + (1 - \beta) dW^2, s_{db} = \beta s_{db} + (1 - \beta) db^2
sdW=βsdW+(1−β)dW2,sdb=βsdb+(1−β)db2
W
=
W
−
α
d
W
s
d
W
+
ϵ
,
b
=
b
−
α
d
b
s
d
b
+
ϵ
W = W -\alpha \frac {dW} {\sqrt {s_{dW} +\epsilon}}, b = b -\alpha \frac {db} {\sqrt {s_{db}+\epsilon}}
W=W−αsdW+ϵdW,b=b−αsdb+ϵdb
ϵ
\epsilon
ϵ一般取
1
0
−
8
10^{-8}
10−8,作用是防止分母很小接近于0,保证数值稳定一些。
下面正式开始Adam梯度更新公式。
结合上面Momentum的梯度更新公式,可以对比如下的Adam梯度更新公式:
v
d
W
=
β
1
v
d
W
+
(
1
−
β
1
)
d
W
,
v
d
b
=
β
1
v
d
b
+
(
1
−
β
1
)
d
b
v_{dW} =β_1v_{dW} +(1−β_1)dW , v_{db} =β_1v_{db} +(1−β_1)db
vdW=β1vdW+(1−β1)dW,vdb=β1vdb+(1−β1)db
s
d
W
=
β
2
s
d
W
+
(
1
−
β
2
)
d
W
2
,
s
d
b
=
β
2
s
d
b
+
(
1
−
β
2
)
d
b
2
s_{dW} = \beta _2s_{dW} + (1 - \beta _2) dW^2, s_{db} = \beta _2s_{db} + (1 - \beta _2) db^2
sdW=β2sdW+(1−β2)dW2,sdb=β2sdb+(1−β2)db2
使用Adam我们一般会进行偏差修正:
v
d
W
c
o
r
r
e
c
t
e
d
=
v
d
W
1
−
β
1
t
,
v
d
b
c
o
r
r
e
c
t
e
d
=
v
d
b
1
−
β
1
t
v^{corrected} _{dW} = \frac{v_{dW}}{1 - \beta _1^ t}, v^{corrected} _{db} = \frac{v_{db}}{1 - \beta _1^ t}
vdWcorrected=1−β1tvdW,vdbcorrected=1−β1tvdb
s
d
W
c
o
r
r
e
c
t
e
d
=
s
d
W
1
−
β
2
t
,
s
d
b
c
o
r
r
e
c
t
e
d
=
s
d
b
1
−
β
2
t
s^{corrected} _{dW} = \frac{s_{dW}}{1 - \beta _2^ t}, s^{corrected} _{db} = \frac{s_{db}}{1 - \beta _2^ t}
sdWcorrected=1−β2tsdW,sdbcorrected=1−β2tsdb
然后进行结合:
W
=
W
−
α
v
d
W
c
o
r
r
e
c
t
e
d
s
d
W
c
o
r
r
e
c
t
e
d
+
ϵ
,
b
=
b
−
α
v
d
b
c
o
r
r
e
c
t
e
d
s
d
b
c
o
r
r
e
c
t
e
d
+
ϵ
W = W -\alpha \frac {v^{corrected} _{dW}} {\sqrt {s^{corrected} _{dW}+\epsilon}}, b = b -\alpha \frac {v^{corrected} _{db}} {\sqrt {s^{corrected} _{db}+\epsilon}}
W=W−αsdWcorrected+ϵvdWcorrected,b=b−αsdbcorrected+ϵvdbcorrected
一般来说:
β
1
=
0.9
\beta _1=0.9
β1=0.9,
β
2
=
0.999
\beta _2=0.999
β2=0.999,
ϵ
=
1
0
−
8
\epsilon =10 ^{-8}
ϵ=10−8,
α
\alpha
α则需要自己调整。
先来初始化Adam所需要的参数:
def initialize_adam(parameters):
"""
初始化v和s,它们都是字典类型的变量,都包含了以下字段:
- keys: "dW1", "db1", ..., "dWL", "dbL"
- values:与对应的梯度/参数相同维度的值为零的numpy矩阵
参数:
parameters - 包含了以下参数的字典变量:
parameters["W" + str(l)] = Wl
parameters["b" + str(l)] = bl
返回:
v - 包含梯度的指数加权平均值,字段如下:
v["dW" + str(l)] = ...
v["db" + str(l)] = ...
s - 包含平方梯度的指数加权平均值,字段如下:
s["dW" + str(l)] = ...
s["db" + str(l)] = ...
"""
L = len(parameters) // 2
v = {}
s = {}
for l in range(L):
v["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
v["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
s["dW" + str(l + 1)] = np.zeros_like(parameters["W" + str(l + 1)])
s["db" + str(l + 1)] = np.zeros_like(parameters["b" + str(l + 1)])
return (v, s)
然后测试并查看数据:
parameters = testCase.initialize_adam_test_case()
v, s = initialize_adam(parameters)
print('v["dW1"] = ' + str(v["dW1"]))
print('v["db1"] = ' + str(v["db1"]))
print('v["dW2"] = ' + str(v["dW2"]))
print('v["db2"] = ' + str(v["db2"]))
print('s["dW1"] = ' + str(s["dW1"]))
print('s["db1"] = ' + str(s["db1"]))
print('s["dW2"] = ' + str(s["dW2"]))
print('s["db2"] = ' + str(s["db2"]))
运行结果如下,都是与对应参数相同shape的0矩阵:
v["dW1"] = [[0. 0. 0.]
[0. 0. 0.]]
v["db1"] = [[0.]
[0.]]
v["dW2"] = [[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
v["db2"] = [[0.]
[0.]
[0.]]
s["dW1"] = [[0. 0. 0.]
[0. 0. 0.]]
s["db1"] = [[0.]
[0.]]
s["dW2"] = [[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
s["db2"] = [[0.]
[0.]
[0.]]
更新梯度:
def update_parameters_with_adam(parameters, grads, v, s, t, learning_rate=0.01, beta1=0.9, beta2=0.999, epsilon=1e-8):
"""
使用Adam更新参数
参数:
parameters - 包含了以下字段的字典:
parameters['W' + str(l)] = Wl
parameters['b' + str(l)] = bl
grads - 包含了梯度值的字典,有以下key值:
grads['dW' + str(l)] = dWl
grads['db' + str(l)] = dbl
v - Adam的变量,第一个梯度的移动平均值,是一个字典类型的变量
s - Adam的变量,平方梯度的移动平均值,是一个字典类型的变量
t - 当前迭代的次数
learning_rate - 学习率
beta1 - 动量,超参数
beta2 - RMSprop的一个参数,超参数
epsilon - 防止除零操作(分母为0)
返回:
parameters - 更新后的参数
v - 第一个梯度的移动平均值,是一个字典类型的变量
s - 平方梯度的移动平均值,是一个字典类型的变量
"""
L = len(parameters) // 2
v_corrected = {} # 偏差修正后的值
s_corrected = {} # 偏差修正后的值
for l in range(L):
# 梯度的移动平均值,输入:"v , grads , beta1",输出:" v "
v["dW" + str(l + 1)] = beta1 * v["dW" + str(l + 1)] + (1 - beta1) * grads["dW" + str(l + 1)]
v["db" + str(l + 1)] = beta1 * v["db" + str(l + 1)] + (1 - beta1) * grads["db" + str(l + 1)]
# 计算第一阶段的偏差修正后的估计值,输入"v , beta1 , t" , 输出:"v_corrected"
v_corrected["dW" + str(l + 1)] = v["dW" + str(l + 1)] / (1 - np.power(beta1, t))
v_corrected["db" + str(l + 1)] = v["db" + str(l + 1)] / (1 - np.power(beta1, t))
# 计算平方梯度的移动平均值,输入:"s, grads , beta2",输出:"s"
s["dW" + str(l + 1)] = beta2 * s["dW" + str(l + 1)] + (1 - beta2) * np.square(grads["dW" + str(l + 1)])
s["db" + str(l + 1)] = beta2 * s["db" + str(l + 1)] + (1 - beta2) * np.square(grads["db" + str(l + 1)])
# 计算第二阶段的偏差修正后的估计值,输入:"s , beta2 , t",输出:"s_corrected"
s_corrected["dW" + str(l + 1)] = s["dW" + str(l + 1)] / (1 - np.power(beta2, t))
s_corrected["db" + str(l + 1)] = s["db" + str(l + 1)] / (1 - np.power(beta2, t))
# 更新参数,输入: "parameters, learning_rate, v_corrected, s_corrected, epsilon". 输出: "parameters".
parameters["W" + str(l + 1)] = parameters["W" + str(l + 1)] - learning_rate * (
v_corrected["dW" + str(l + 1)] / np.sqrt(s_corrected["dW" + str(l + 1)] + epsilon))
parameters["b" + str(l + 1)] = parameters["b" + str(l + 1)] - learning_rate * (
v_corrected["db" + str(l + 1)] / np.sqrt(s_corrected["db" + str(l + 1)] + epsilon))
return (parameters, v, s)
运行并查看相关参数:
parameters, grads, v, s = testCase.update_parameters_with_adam_test_case()
update_parameters_with_adam(parameters, grads, v, s, t=2)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
print('v["dW1"] = ' + str(v["dW1"]))
print('v["db1"] = ' + str(v["db1"]))
print('v["dW2"] = ' + str(v["dW2"]))
print('v["db2"] = ' + str(v["db2"]))
print('s["dW1"] = ' + str(s["dW1"]))
print('s["db1"] = ' + str(s["db1"]))
print('s["dW2"] = ' + str(s["dW2"]))
print('s["db2"] = ' + str(s["db2"]))
运行结果如下:
W1 = [[ 1.63178673 -0.61919778 -0.53561312]
[-1.08040999 0.85796626 -2.29409733]]
b1 = [[ 1.75225313]
[-0.75376553]]
W2 = [[ 0.32648046 -0.25681174 1.46954931]
[-2.05269934 -0.31497584 -0.37661299]
[ 1.14121081 -1.09245036 -0.16498684]]
b2 = [[-0.88529978]
[ 0.03477238]
[ 0.57537385]]
v["dW1"] = [[-0.11006192 0.11447237 0.09015907]
[ 0.05024943 0.09008559 -0.06837279]]
v["db1"] = [[-0.01228902]
[-0.09357694]]
v["dW2"] = [[-0.02678881 0.05303555 -0.06916608]
[-0.03967535 -0.06871727 -0.08452056]
[-0.06712461 -0.00126646 -0.11173103]]
v["db2"] = [[0.02344157]
[0.16598022]
[0.07420442]]
s["dW1"] = [[0.00121136 0.00131039 0.00081287]
[0.0002525 0.00081154 0.00046748]]
s["db1"] = [[1.51020075e-05]
[8.75664434e-04]]
s["dW2"] = [[7.17640232e-05 2.81276921e-04 4.78394595e-04]
[1.57413361e-04 4.72206320e-04 7.14372576e-04]
[4.50571368e-04 1.60392066e-07 1.24838242e-03]]
s["db2"] = [[5.49507194e-05]
[2.75494327e-03]
[5.50629536e-04]]
测试
三个优化器此时都已经做好了,此时我们可以开始进行测试对比。
首先加载数据集:
train_X, train_Y = opt_utils.load_dataset(is_plot=True)

然后定义能够选择优化器的模型:
def model(X, Y, layers_dims, optimizer, learning_rate=0.0007,
mini_batch_size=64, beta=0.9, beta1=0.9, beta2=0.999,
epsilon=1e-8, num_epochs=10000, print_cost=True, is_plot=True):
"""
可以运行在不同优化器模式下的3层神经网络模型。
参数:
X - 输入数据,维度为(2,输入的数据集里面样本数量)
Y - 与X对应的标签
layers_dims - 包含层数和节点数量的列表
optimizer - 字符串类型的参数,用于选择优化类型,【 "gd" | "momentum" | "adam" 】
learning_rate - 学习率
mini_batch_size - 每个小批量数据集的大小
beta - 用于动量优化的一个超参数
beta1 - 用于计算梯度后的指数衰减的估计的超参数(adam的v)
beta2 - 用于计算平方梯度后的指数衰减的估计的超参数(adam的s)
epsilon - 用于在Adam中避免除零操作的超参数,一般不更改
num_epochs - 整个训练集的遍历次数
print_cost - 是否打印误差值,每遍历1000次数据集打印一次,但是每100次记录一个误差值,又称每1000代打印一次
is_plot - 是否绘制出曲线图
返回:
parameters - 包含了学习后的参数
"""
L = len(layers_dims)
costs = []
t = 0 # 每学习完一个minibatch就增加1
seed = 10 # 随机种子
# 初始化参数
parameters = opt_utils.initialize_parameters(layers_dims)
# 选择优化器
if optimizer == "gd":
pass # 不使用任何优化器,直接使用梯度下降法
elif optimizer == "momentum":
v = initialize_velocity(parameters) # 使用动量
elif optimizer == "adam":
v, s = initialize_adam(parameters) # 使用Adam优化
else:
print("optimizer参数错误,程序退出。")
exit(1)
# 开始学习
for i in range(num_epochs):
# 定义随机 minibatches,我们在每次遍历数据集之后增加种子以重新排列数据集,使每次数据的顺序都不同
seed = seed + 1
minibatches = random_mini_batches(X, Y, mini_batch_size, seed)
for minibatch in minibatches:
# 选择一个minibatch
(minibatch_X, minibatch_Y) = minibatch
# 前向传播
A3, cache = opt_utils.forward_propagation(minibatch_X, parameters)
# 计算误差
cost = opt_utils.compute_cost(A3, minibatch_Y)
# 反向传播
grads = opt_utils.backward_propagation(minibatch_X, minibatch_Y, cache)
# 更新参数
if optimizer == "gd":
parameters = update_parameters_with_gd(parameters, grads, learning_rate)
elif optimizer == "momentum":
parameters, v = update_parameters_with_momentun(parameters, grads, v, beta, learning_rate)
elif optimizer == "adam":
t = t + 1
parameters, v, s = update_parameters_with_adam(parameters, grads, v, s, t, learning_rate, beta1, beta2,
epsilon)
# 记录误差值
if i % 100 == 0:
costs.append(cost)
# 是否打印误差值
if print_cost and i % 1000 == 0:
print("第" + str(i) + "次遍历整个数据集,当前误差值:" + str(cost))
# 是否绘制曲线图
if is_plot:
plt.plot(costs)
plt.ylabel('cost')
plt.xlabel('epochs (per 100)')
plt.title("Learning rate = " + str(learning_rate))
plt.show()
return parameters
不使用任何的优化算法测试
首先我们不使用任何的优化算法:
layers_dims = [train_X.shape[0], 5, 2, 1]
parameters = model(train_X, train_Y, layers_dims, optimizer="gd", mini_batch_size=train_X.shape[1], is_plot=True)
这里我们使用mini-batch size为整批样本数量的Mini-batchGD,相当于BGD。
运行结果如下:
第0次遍历整个数据集,当前误差值:0.7024140504990622
第1000次遍历整个数据集,当前误差值:0.6943118340285278
第2000次遍历整个数据集,当前误差值:0.6871467723037228
第3000次遍历整个数据集,当前误差值:0.680783295462522
第4000次遍历整个数据集,当前误差值:0.6745697990495347
第5000次遍历整个数据集,当前误差值:0.668099491415458
第6000次遍历整个数据集,当前误差值:0.6615453281689901
第7000次遍历整个数据集,当前误差值:0.6551945773784773
第8000次遍历整个数据集,当前误差值:0.6489697288050273
第9000次遍历整个数据集,当前误差值:0.6423837881671763

绘制分类的情况:
# 预测
preditions = opt_utils.predict(train_X, train_Y, parameters)
# 绘制分类图
plt.title("Model with Gradient Descent optimization")
axes = plt.gca()
axes.set_xlim([-1.5, 2.5])
axes.set_ylim([-1, 1.5])
opt_utils.plot_decision_boundary(lambda x: opt_utils.predict_dec(parameters, x.T), train_X, train_Y)
运行结果如下:
Accuracy: 0.66

mini-batch梯度下降法测试
这里将mini_batch_size的值去掉(使用默认的64):
parameters = model(train_X, train_Y, layers_dims, optimizer="gd", is_plot=True)
运行结果:
第0次遍历整个数据集,当前误差值:0.690735512291113
第1000次遍历整个数据集,当前误差值:0.6852725328458241
第2000次遍历整个数据集,当前误差值:0.6470722240719003
第3000次遍历整个数据集,当前误差值:0.6195245549970403
第4000次遍历整个数据集,当前误差值:0.5765844355950944
第5000次遍历整个数据集,当前误差值:0.6072426395968576
第6000次遍历整个数据集,当前误差值:0.5294033317684576
第7000次遍历整个数据集,当前误差值:0.46076823985930115
第8000次遍历整个数据集,当前误差值:0.465586082399045
第9000次遍历整个数据集,当前误差值:0.46451797221676844

改一下绘图的标题:
plt.title("Model with Mini-batch Gradient Descent optimization")
运行:
Accuracy: 0.7966666666666666

Momentum测试
改一下优化器optimizer参数的值为momentum,然后添加动量参数值 β \beta β:
parameters = model(train_X, train_Y, layers_dims, beta=0.9, optimizer="momentum", is_plot=True)
运行:
第0次遍历整个数据集,当前误差值:0.6907412988351506
第1000次遍历整个数据集,当前误差值:0.6853405261267578
第2000次遍历整个数据集,当前误差值:0.6471448370095255
第3000次遍历整个数据集,当前误差值:0.6195943032076022
第4000次遍历整个数据集,当前误差值:0.5766650344073023
第5000次遍历整个数据集,当前误差值:0.607323821900647
第6000次遍历整个数据集,当前误差值:0.5294761758786997
第7000次遍历整个数据集,当前误差值:0.46093619004872366
第8000次遍历整个数据集,当前误差值:0.465780093701272
第9000次遍历整个数据集,当前误差值:0.4647395967922748

改一下绘图标题:
plt.title("Model with Momentum optimization")
运行:
Accuracy: 0.7966666666666666

Adam测试
改变优化器参数optimizer的值为adam(剩下的参数使用默认的):
parameters = model(train_X, train_Y, layers_dims, optimizer="adam", is_plot=True)
运行:
第0次遍历整个数据集,当前误差值:0.6905522446113365
第1000次遍历整个数据集,当前误差值:0.18550136438550574
第2000次遍历整个数据集,当前误差值:0.15083046575253203
第3000次遍历整个数据集,当前误差值:0.0744543857099718
第4000次遍历整个数据集,当前误差值:0.1259591565133716
第5000次遍历整个数据集,当前误差值:0.10434443534245479
第6000次遍历整个数据集,当前误差值:0.10067637504120665
第7000次遍历整个数据集,当前误差值:0.031652030135115576
第8000次遍历整个数据集,当前误差值:0.111972731312442
第9000次遍历整个数据集,当前误差值:0.19794007152465484

改变绘图标题:
plt.title("Model with Adam optimization")
运行:
Accuracy: 0.94

总结
| 优化算法 | 准确率 | 曲线平滑程度 |
|---|---|---|
| BGD | 0.66 | 平滑 |
| Mini-batchGD | 0.80 | 震荡 |
| Momentum | 0.80 | 震荡 |
| Adam | 0.94 | 平滑下降,末端振荡 |
由于数据集很简单,所以本次实验的Momentum看不太出来效果,几乎微乎其微,否则会比Mini-batchGD要有更好的效果。
通过本次对比明显看出Adam梯度下降效果是最好的,收敛最快且loss学习最低,检测的准确率最高。而且还具有内存要求低的优点。