转换算子(Transformation)
映射(map)
用于将数据流中的数据进行转换,形成新的数据流
“一一映射”,消费一个元素就产出一个元素
参数:接口 MapFunction 的实现
方法:map
返回值类型:DataStream
通过匿名类/实现类实现:
// 传入匿名类,实现 MapFunction
//Event是输入,String是输出
stream.map(new MapFunction<Event, String>() {
@Override
public String map(Event e) throws Exception {
return e.user;
}
});
// 传入 MapFunction 的实现类
stream.map(new UserExtractor()).print();
env.execute();
public static class UserExtractor implements MapFunction<Event, String> {
@Override
public String map(Event e) throws Exception {
return e.user;
}
}
源码相关:
调用map方法,可以看到返回的是一个SingleOutputStreamOperator
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
TypeInformation<R> outType = TypeExtractor.getMapReturnTypes((MapFunction)this.clean(mapper), this.getType(), Utils.getCallLocationName(), true);
return this.map(mapper, outType);
}
而SingleOutputStreamOperator 类本身也继承自 DataStream 类,在DataStream类的基础上对一些参数进行了更详细的设置;
public class SingleOutputStreamOperator<T> extends DataStream<T>
过滤(filter)
参数:FilterFunction 接口的实现
方法:filter
返回值类型:DataStream
// 传入匿名类实现FilterFunction
stream.filter(new FilterFunction<Event>() {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
});
// 传入FilterFunction实现类
stream.filter(new UserFilter()).print();
env.execute();
}
public static class UserFilter implements FilterFunction<Event> {
@Override
public boolean filter(Event e) throws Exception {
return e.user.equals("Mary");
}
}
扁平映射(flatMap)
先按照某种规则对数据进行打散拆分,再对拆分后的元素做转换处理
参数:FlatMapFunction 接口的实现
方法:flatMap
返回值类型:flatMap 并没有直接定义返回值类型,而是通过一个“收集器”(Collector)来指定输出
同 map 一样,flatMap 也可以使用 Lambda 表达式或者 FlatMapFunction 接口实现类的方式来进行传参,返回值类型取决于所传参数的具体逻辑,可以与原数据流相同,也可以不同
public static class MyFlatMap implements FlatMapFunction<Event, String> {
@Override
public void flatMap(Event value, Collector<String> out) throws Exception
{
if (value.user.equals("Mary")) {
out.collect(value.user);
} else if (value.user.equals("Bob")) {
out.collect(value.user);
out.collect(value.url);
}
}
}
聚合算子(Aggregation)
按键分区(keyBy)
对海量数据做聚合肯定要进行分区并行处理,这样才能提高效率,因此要聚合,先分区;
keyBy 通过指定键(key),可以将一条流从逻辑上划分成不同的分区,也就是并行处理的子任务,对应着任务槽(slot);这样具有相同的 key 的数据,都将被发往同一个分区,那么下一步算子操作就将会在同一个 slot中进行处理
在keyBy()方法的内部,是通过计算 key 的哈希值(hash code),对分区数进行取模运算来实现的。所以这里 key 如果是 POJO 的话,必须要重写 *hashCode() *方法
实现方法:
// 使用 Lambda 表达式
KeyedStream<Event, String> keyedStream = stream.keyBy(e -> e.user);
// 使用匿名类实现 KeySelector
KeyedStream<Event, String> keyedStream1 = stream.keyBy(new KeySelector<Event, String>() {
@Override
public String getKey(Event e) throws Exception {
return e.user;
}
});
//结果:将 DataStream 转换为KeyedStream
简单聚合

参数:
传入的参数决定了聚合的依据,
对于元组有两种形式,位置和名称:
stream.keyBy(r -> r.f0).sum(1).print();(元组中1号位置)
stream.keyBy(r -> r.f0).sum("f1").print();(元组中名称为f1的数据)
对于POJO,只能传入字段名:
stream.keyBy(e -> e.user).max( "timestamp" ).print();
通过聚合操作,从 KeyedStream 转换成了DataStream
也就是说,先分区,再聚合,得到的依然是一个DataStream

归约聚合(reduce)
reduce 算子是一个一般化的聚合统计操作
实现 ReduceFunction 接口,接口里需要实现 reduce()方法
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 通过reduce算子实现sum和maxBy的功能
env.addSource(new ClickSource())
.map(new MapFunction<Event, Tuple2<String,Long>>(
) {
@Override
public Tuple2<String, Long> map(Event event) throws Exception {
return Tuple2.of(event.getUser(),1L);
}
})
.keyBy(e -> e.f0)
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> t1, Tuple2<String, Long> t2) throws Exception {
return Tuple2.of(t1.f0, t1.f1+t2.f1);
}
})
.keyBy(e -> true)
.reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> t1, Tuple2<String, Long> t2) throws Exception {
return t1.f1 > t2.f1 ? t1 : t2;
}
})
.print();
env.execute();
}
用户自定义函数(UDF)
富函数类(Rich Function Classes)
所有的 Flink 函数类都有其Rich 版本
与常规函数类的不同主要在于,富函数类可以获取运行环境的上下文,并拥有一些生命周期方法,所以可以实现更复杂的功能

一个常见的应用场景就是,如果我们希望连接到一个外部数据库进行读写操作,那么将连接操作放在 map()中显然不是个好选择——因为每来一条数据就会重新连接一次数据库;所以我们可以在 open()中建立连接,在 map()中读写数据,而在 close()中关闭连接
另外,富函数类提供了 getRuntimeContext()方法,可以获取到运行时上下文的一些信息,例如程序执行的并行度,任务名称,以及状态
物理分区
keyBy:逻辑分区
物理分区与 keyBy 一大区别在于,keyBy 之后得到的是一个 KeyedStream,而物理分区之后结果仍是 DataStream,且流中元素数据类型保持不变。从这一点也可以看出,分区算子并不对数据进行转换处理,只是定义了数据的传输方式
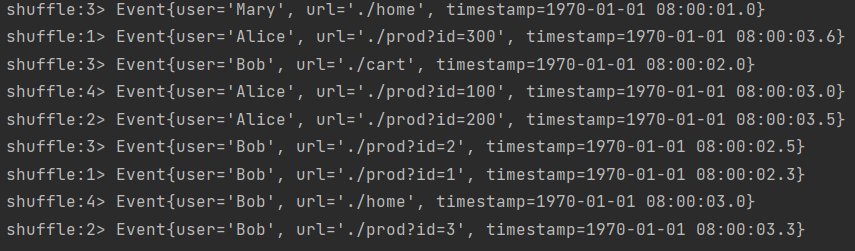
- 随机分区(shuffle)
方法:
.shuffle()
每次执行结果都会不相同:
2.轮询分区(Round-Robin)

方法:.rebalance();rebalance使用的是 Round-Robin 负载均衡算法,可以将输入流数据平均分配到下游的并行任务中去
3.重缩放分区(rescale)
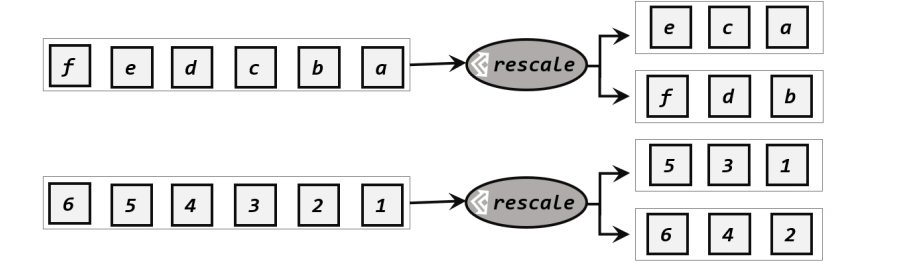
方法:.rescale()
重缩放和轮询的区别:
①重缩放分区和轮询分区非常相似。当调用 rescale()方法时,其实底层也是使用 Round-Robin算法进行轮询,但是只会将数据轮询发送到下游并行任务的一部分中;也就是说,“发牌人”如果有多个,那么 rebalance 的方式是每个发牌人都面向所有人发牌;而 rescale的做法是分成小团体,发牌人只给自己团体内的所有人轮流发牌
②从底层实现上看,rebalance 和 rescale 的根本区别在于任务之间的连接机制不同。rebalance将会针对所有上游任务(发送数据方)和所有下游任务(接收数据方)之间建立通信通道,这是一个笛卡尔积的关系;而 rescale 仅仅针对每一个任务和下游对应的部分任务之间建立通信通道,节省了很多资源
示例:
env.addSource(new RichParallelSourceFunction<Integer>() { // 这里使用了并行数据源的富函数版本
@Override
public void run(SourceContext<Integer> sourceContext) throws Exception {
for (int i = 1; i <= 8; i++) {
// 将奇数发送到索引为1的并行子任务
// 将偶数发送到索引为0的并行子任务
if ( i % 2 == getRuntimeContext().getIndexOfThisSubtask()) {
sourceContext.collect(i);
}
}
}
@Override
public void cancel() {
}
})
.setParallelism(2)
.rescale()
.print().setParallelism(4);
结果:
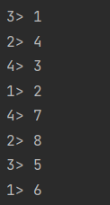
可以看到,奇数全部在3,4分区,偶数全部在1,2分区;
如果使用rebalance方法:
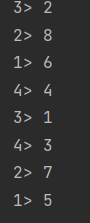
可以看到,奇数偶数平均分配到所有分区
4.广播(broadcast):经过广播之后,数据会在不同的分区都保留一份,可能进行重复处理。可以通过调用 DataStream 的 broadcast()方法,将输入数据复制并发送到下游算子的所有并行任务中去
5.全局分区(global):通过调用.global()方法,会将所有的输入流数据都发送到下游算子的第一个并行子任务中去。这就相当于强行让下游任务并行度变成了1
6. 自定义分区(Custom):使 用partitionCustom()方法来自定义分区
// 将自然数按照奇偶分区
env.fromElements(1, 2, 3, 4, 5, 6, 7, 8)
.partitionCustom(new Partitioner<Integer>() {
@Override
public int partition(Integer key, int numPartitions) { //分区器
return key % 2;
}
},
new KeySelector<Integer, Integer>() { //KeyBy
@Override
public Integer getKey(Integer value) throws Exception {
return value;
}
})
.print().setParallelism(2);
env.execute();