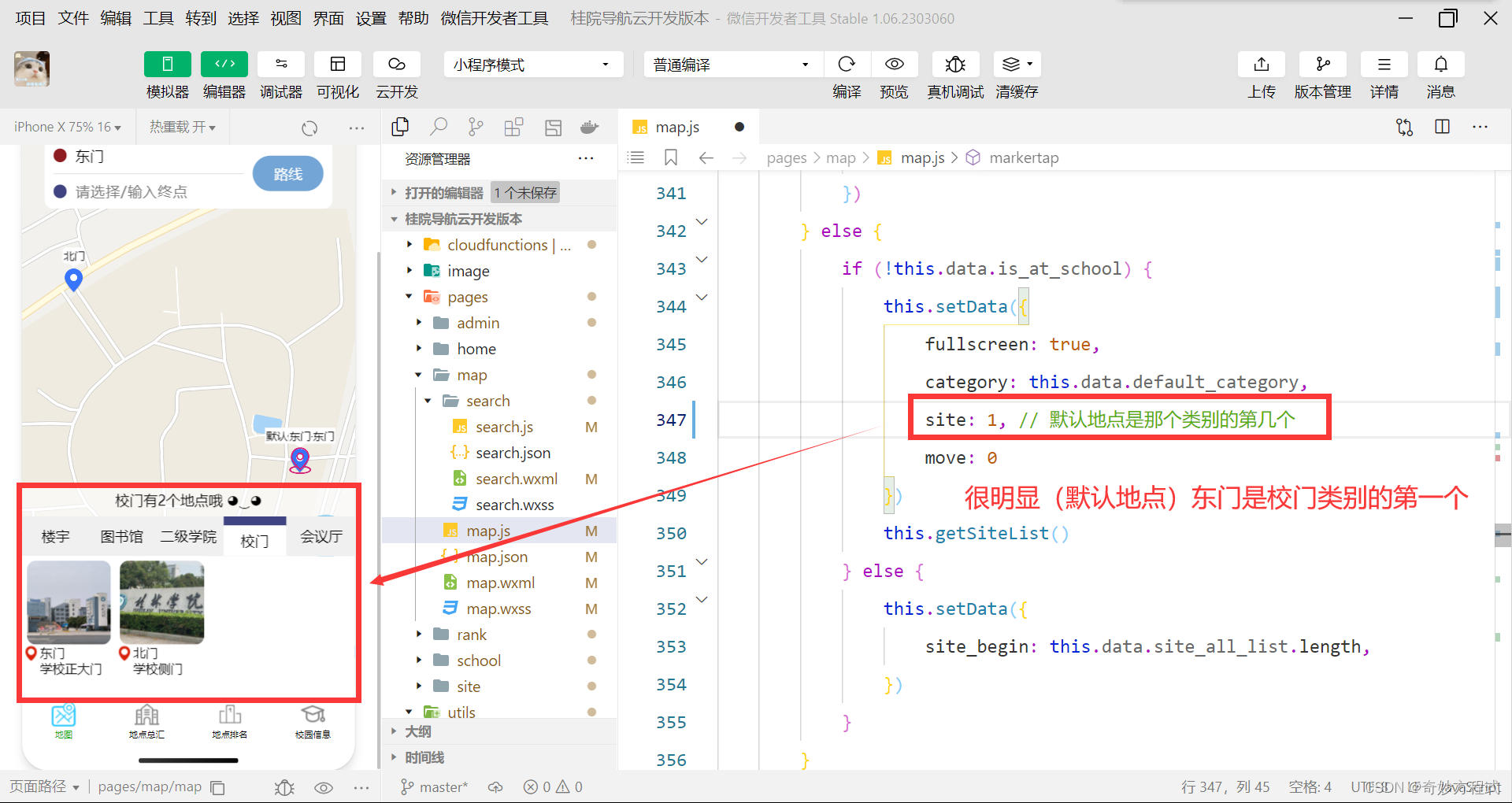
训练目标检测模型有个很令人头疼的问题,就是有些特征与要训练的特征较为相似的背景区域也被误检出来(作为本应不该检测出来的负样本却被误检出为正样本的FP)。
根据这一问题的解决办法,除了可以对正样本特征较为模糊或者有歧义的样本进行清洗,还有一个策略就是收集这些误检的背景图作为负样本(不标标签)参与训练。
所以本片就针对这类无标签的图片的拼图代码进行编写。
思路
- 首先背景图或大或小(一般根据实际摄像头误检框出的区域稍微外括少部分比例),而训练输入的size是固定的,为了不让小图的resize比例过大导致的太模糊特征遭到破坏,我们这里依据图片的大小范围进行1×1、2×2等宫格拼图(这里的图片大小都是特定大小,更复杂的放在下一篇)。
- 将范围相同的图片放在同一容器中,每次取n(1×1、2×2……)个样本,依次粘贴到一张大图上,大图的大小就是训练输入的大小。
- 拼图的图片会依次升序命令,而被拼的小图也会依次记录其图片名。这里的作用主要是用在模型测试上,将这些拼图输入模型测试,若是哪张拼图上有检测框,则证明哪张图片有误检,可以根据图片名以及在图片当中的哪一个位置来判断原图(被拼的小图)是哪张,可以快速找到领出来再次作为负样本进行训练。
代码
import PIL.Image as Image
import os
import cv2
img_size = 416
# 定义图像拼接函数
def image_compose(idx, ori_tmp, num):
to_image = Image.new('RGB', (img_size, img_size)) #创建一个新图
a = 0
for y in range(idx):
for x in range(idx):
to_image.paste(Image.open(os.path.join(images_path, ori_tmp[a])), (
int(x * (img_size / idx)), int(y * (img_size / idx))))
print(f"ori_tmp[{a}] :", ori_tmp[a])
a += 1
new_name = os.path.join(save_path, "bg_" + str(idx) + "_" + str(num) + ".jpg")
to_image.save(new_name) # 保存新图
# print(new_name)
images_path = '/data/cch/000test/img' # 图片集地址
save_path = '/data/cch/000test/save' # 图片转换后的地址
ori_1 = []
ori_2 = []
ori_3 = []
ori_4 = []
ori_5 = [] # 存放将要5×5拼图的原图
ori = [ori_1, ori_2, ori_3, ori_4, ori_5]
image_names = os.listdir(images_path)
for i in image_names:
imgPath = os.path.join(images_path, i)
img = cv2.imread(imgPath)
[img_h, img_w, _] = img.shape
img_h = max(img_h, img_w)
# print(img_h,img_w)
if img_h == img_size:
ori_1.append(i)
elif img_h == int(208/2):
ori_2.append(i)
elif img_h == int(208/3):
ori_3.append(i)
elif img_h == int(208/4):
ori_4.append(i)
elif img_h == int(208/5):
ori_5.append(i)
# print(ori_5)
idx = 1
for ori_n in ori:
ori_path = os.path.join(save_path, "path_txt", "ori_" + str(idx) + ".txt")
if os.path.exists(ori_path):
os.remove(ori_path)
for i in ori_n:
with open(ori_path, 'a') as file:
file.write(i)
file.write("\n")
num = 0
ori_tmp = []
for i in ori_n:
if len(ori_tmp) < (idx*idx):
ori_tmp.append(i)
else:
image_compose(idx, ori_tmp,num) #调用函数
# print(ori_tmp)
ori_tmp.clear()
num += 1
ori_tmp.append(i)
idx += 1
测试
我们拿一组图片进行测试,输出的目录如下:

txt文本文件则是保存的拼图顺序。
1×1即单张图片(以bg_1开头):

2×2即单张图片(以bg_2开头):

3×3即单张图片(以bg_3开头):

4×4即单张图片(以bg_4开头):

5×5即单张图片(以bg_5开头):

我觉得5×5的小图已经足够小的,在小的基本上也不可能被误检出来,即使真的误检出来也没必要加进去训练了。
最后
本篇是拼图篇最简单的案例,即没有标签、小图的大小也要固定死是那五个值才能拼、拼图方式为宫格的,都被限定死了,接下来的将会针对有标签的、图片大小不固定的、非宫格拼图方式等复杂方式进行拼图。