第一章:Spring简介
SpringIOC工厂是Spring所有特性的基础,Spring所有的特性都是基于IOC控制反转特性而来的。
当今微服务已经成为主流,微服务依赖于SpringBoot和SpringCloud,而SpringBoot和SpringCloud是衍生于Spring,所以,学习Spring很重要。(Spring学习到位之后才能理解到位SpringBoot和SpringCloud)
Spring全称Spring Framework,2002年写出来的东西,轻量级企业开发开发解决方案,为了解决EJB的缺陷。
一:EJB框架缺陷
1:运行环境苛刻
当前我们开发的程序是属于JavaWeb程序,这样的程序运行的时候需要一个服务器环境,当前我们常用的服务器是Tomcat服务器,我们写好的Java代码都运行在Tomcat上,Tomcat帮我们集中处理请求响应,包括完成Servlet和相关代码的运行和解析。
在Tomcat当中最为核心的组件是一个Servlet引擎的这样一个组件,Tomcat当中所有的核心的工作都是交给一个叫做Servlet引擎的组件来做,这样Tomcat就能实现让我们的代码实现一下web请求的工作,Tomcat我们成为也就是web服务器。
EJB代码对于环境要求很苛刻,他的代码不能运行在Tomcat服务器当中,而是需要运行在EJB容器当中,Tomcat是不具备这个东西的,所以EJB需要运行在更复杂的服务器上,比方说weblogic服务器上,这个服务器上不仅包含servlet引擎,还包括EJB容器,所以这样的服务器也叫做ApplicationServer这个是非开源的是收费的。很多中小型公司没有钱的话用不了这两种收费的服务器,也就书写不了EJB的代码,而且因为是非开源的,无法进行定制。
2: 代码移植性差
EJB的代码运行在weblogic这个服务器当中需要实现webLogic服务器当中一些特殊的接口,才可以进行运行,当这样的代码想往WebSphere中进行迁移时,就这个服务器当中并没有提供这样接口,就无法进行移植
总结:EJB是一个重量级的框架,运行环境苛刻,代码移植性差
二: 什么是Spring
Spring是一个轻量级的Java2EE解决方案,聚合众多优秀的设计模式
1: 轻量级
对于运行环境没有额外要求的
2: 常用服务器
开源的:Tomcat,Resion,Jetty
收费的:WebLogic,WebSphere
3:Spring是全套企业开发解决方案
我们之前的开发是分层的,Controller层,Service层解决业务,Dao层访问数据库,而当今众多优秀的框架中Struct2(解决的是控制器),Mybatis都是解决的某一层的问题,而spring是一个解决方案,可以解决JavaEE开发当中所有层的问题,可以通过SpringMVC解决控制层的问题,可以通过SpringAop解决Service层事务的控制和日志处理的问题,还可以通过将Hibernate,Mybatis进行整合解决Dao层的问题。经过分析,整个Spring来讲每一层都有对应的解决方案。所以他是一个完整的整个体系的解决方案
4: Spring为什么是轻量级的
Spring并不是发明了什么新技术,而是对众多优秀的设计模式的进行了高度的封装和整合,所有的特点都是基于一些列设计模式的整合来实现的
5: 四个核心设计模式
1):什么是设计模式
设计模式是面向对象设计过程中解决特定问题的经典代码,Java中一共 23种设计模式。
2):工厂模式
简单 vs 通用工厂模式 反射+配置
通过反射我们可根据类的全限定类名获取到子类的运行时对象也就是他的Class对象,通过这个Class对象我们就可以创建这个类的实例。
通过将类的全限定类名可以写入到properties配置文件当中,在这个配置文件当中,我们基于对配置的解析,将配置文件通过流的方式读取到property集合对象当中,然后将全限定类名匹配到反射当中完成对象的创建。:
小的配置文件当中,我们一般使用properties,properties类型的文件介绍,在maven项目当中,main->Java下面完成的是代码,main->resources下边专门放置配置文件,Properties配置文件语法有一个特殊的要求,必须采用key_value的形式进行组成,Key随便写,唯一就行,Properties集合可以用于存储properties文件的内容,是一种特殊map形式,可以通过getProperty属性进行获取Properties集合创建之后可以通过io流的方式将properties文件中的对象转换成集合,io流在我们整个Java操作过程当中是系统级资源,我们一般避免重复打开io,并且最好在程序启动的时候一次性读取完毕我们所有的内容。所以,我们采用静态代码快的方式来完成,流用完了,我们要关闭一下。
在反射工厂中采用一个反射机制+配置文件的方式可以彻底解决类的耦合的问题。这样替换的时候,不需要修改任何一行代码,直接增加一个类,实现对应的接口,然后修改配置文件中的内容既可以了,重启一下服务器就可以了。
在Service层当中也有耦合的情况,对于dao层对象的耦合,在工厂类当中,工厂设计的核心就是工厂类。在这个反射工厂当中要对一个对象进行解耦合,就需要在反射工厂类中添加一个对应的方法,通过一种反射+配置文件(流读取成集合)的方式进行解耦,有大量的冗余的代码。这样造成的工厂类中的方法是无穷无尽的。
对于spring来讲,最为核心的就是spring的工厂设计模式,作为spring的框架来讲,spring当中的工厂模式已经创建好了,spring当中的工厂类是ApplicationContext类,对应的配置文件是ApplicationContext.xml,spring的配置文件用的是xml,实现思路和我们工厂是一样的,只不过spring的工厂模式更为强大
第二章:第一个Spring程序
一:Spring依赖
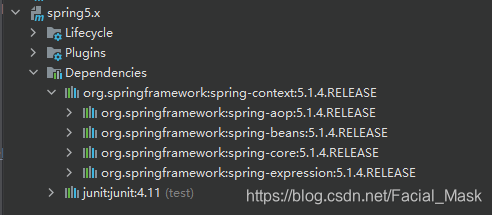
当前我们都是基于maven进行jar包的管理,我们只需要引入相应的坐标就可以了。maven会自动为我们下载我们所以来的jar包和依赖的依赖进行下载下来,单纯的使用一个Spring的IOC的话,spring-context就够用了,我们使用的版本是spring-context 5.1.4release版本。
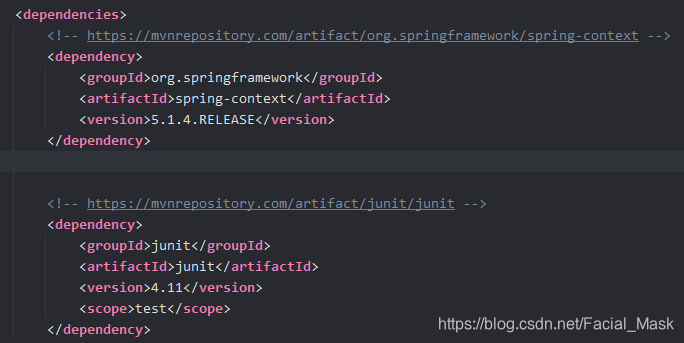
仅仅一个上下文就可以引入:
二: 配置文件
1:Spring配置文件的要求
任何一个框架都需要进行配置文件,Spring框架的配置文件,不要求具体的放置位置,在项目中都可以,也没有具体的配置名称,但是ApplicationContext.xml是Spring官方推荐的配置名称, 日后应用Spring框架时需要进行配置文件路径的配置,需要告诉Spring我们的配置文件的位置在哪里,在创建对象的时候有体现。
在Spring核心配置文件的根标签是一个Beans标签,在里边引入了Spring的一个默认的Schema(书写提示),方便进行获取标签中的xml语法书写提示
2: Spring核心API
ApplicationContext是Spring的核心Api就是指的spring的核心类,这是一个框架最核心的类。这是一个接口
核心类的作用和好处
作用:Spring当中最为核心的API就是提出的那个工厂ApplicationContext.java工厂主要作用是对象的创建。
好处:就是解耦合。
为什么spring进行设计的时候会把核心Api设计成接口
Spring设计工厂的时候会设计成接口,接口的最主要的目的是为了屏蔽实现的差异,提供规范性
作者考虑到这个工厂会应用到不同的开发环境(例如web与非web),为了屏蔽具体工厂类型之间的差异,Spring将工厂API设计成了接口,可以屏蔽具体工厂之间的差异,提供规范性。
Spring当中提供的常用的两种工厂类型
1:非web环境:ClassPathXmlApplicationContext (main junit)
2:web环境: XmlWebApplicationContext
补充说明:
1:以上是Spring中主要提供了两种类型的工厂
2:对于web环境,我们很熟悉,非web英勇主要指的是我们的,main函数和Junit单元测试,在main函数和Junit单元测试里边是不启动服务器的,在main函数和Junit当中和在web当中用到的工厂类是不一样的
3:查看继承关系,idea快捷键是ctrl+h,如果查看继承关系图当中没有这个类的话,是因为没有导入相关的web依赖。添加依赖的快捷键是<dep
为什么ApplicationContext是一个重量级资源
1:ApplicationContext工厂的对象会占用大量内存资源。
2:ApplicationContext工厂对象不会频繁的创建,一个应用只会有一个工厂对象。
3:ApplicationContext工厂一定是线程安全的。
重量级资源都具有以上三种特性:
1:区分一个资源或者对象的轻重量级的区别在于在内存中占用资源的多少,如果一个对象占用内存比较小,就是一个轻量级资源,重量级资源就是会占用大量内存
2:我们在这值得工厂是他的具体的实现类,主要指的是那两种的实现类,我们不会频繁的创建这两个的对象,一个应用只会创建一个工厂对象
3:在一个项目中只有一个这个对象,在一个项目中只会有一个这个对象实例,大家都会访问,那么就会产生比并发访问问题,但凡是这种重量级资源可以被多线程多用户访问,说明他们一定是线程安全的,一定做了锁的设置,它是线程安全的,可以被多线程并发访问
三: 程序开发
1:Spring核心配置文件
<!--id属性:起个名字,要求:唯一-->
<!--class属性:写全限定类名-->
<bean id = "person" class = "com.pactera.spring.Person"/>
2:Java代码
//获取spring的工厂对象,这里我们在单元测试当中指定的是非web工厂。
ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");
//getBean返回的是Object对象。
Person person = (Person)clx.getBean("person");//这里边传入的是id值。
System.out.println(person.getClass());
3:实现思路
1:创建Bean的类文件。
2:在ApplicationContext.xml文件中配置该对象属性;
3:使用spring原生工厂类获取对象;
补充说明:
1:Spring最大的特点就是为我们提供了工厂对象,而这个工厂创建对象起到了一个很好的解耦合的作用,Spring提供的工厂和我们写的工厂本质上是没有区别的,都是创建对象解耦合,对于Spring工厂和通用工厂模式是没有本质区别的
2:如果在Junit当中进行测试的话,应该使用ClassPathXmlApplicationContext这个类
4: 细节分析
1):什么叫做Bean或者组件
Spring工厂为我们创建对象,由spring为我们创建的对象叫做bean或者组件(Component)这些指的都是spring工厂为我们创建的对象
2):Spring工厂提供的一些方法
ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");
Person person = (Person)clx.getBean("person");
Person person = clx.getBean("person", Person.class);
Person person1 = clx.getBean(Person.class);
package com.pactera.spring;
import org.junit.jupiter.api.Test;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
public class TestSpring {
/**
* 研究目的:用于测试第一个spring的程序。
* */
@Test
public void test03(){
//获取spring的工厂对象,这里我们在单元测试当中指定的是非web工厂。
ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");
Person person = (Person)clx.getBean("person");//这里边传入的是id值。
System.out.println(person.getClass());
}
/**
* 用于测试Spring工厂为我们提供的其他的方法。
* 研究目的:Spring工厂对象核心方法getBean方法的重载。
* */
@Test
public void test04(){
ApplicationContext clx = new ClassPathXmlApplicationContext("/applicationContext.xml");
//这个重载的getBean的方法的好处在于不用进行强制类型转换了。
Person person = clx.getBean("person", Person.class);
System.out.println("person="+person);//person=com.pactera.spring.Person@2a4fb17b
System.out.println("person="+person.getClass());//person=class com.pactera.spring.Person
//这个重载的getBean的方法的好处在于不用进行强制类型转换了。
//如果是这种方式:
//<bean id = "person" class = "com.pactera.spring.Person"/>
//<bean id = "person1" class = "com.pactera.spring.Person"/>
//使用getBean(Person.class)会抛出异常,因为无法保证一个唯一性。
//使用这个方法的时候必须保证spring配置文件中标签的唯一性。
//Person person1 = clx.getBean(Person.class);//expected single matching bean but found 2
/**
* 在上边创建了一次Person的对象,将这个对象储存了起来,如果下边使用的话直接拿给我们
* spring当中的当前这个对象只创建了一次,默认是单例设计模式。
* */
//System.out.println("person1="+person1);//person1=com.pactera.spring.Person@2a4fb17b
//获取spring核心配置文件当中所有的id值;
//---bean的定义:就是在spring核心配置文件当中的bean标签就叫做bean的定义
//---bean定义的名字就是获取的是:id的值,返回的是是一个名字的数组。
String[] beanDefinitionNames = clx.getBeanDefinitionNames();
for (String beanDefinitionName : beanDefinitionNames) {
System.out.println("beanDefinitionName="+beanDefinitionName);
}
//根据类型获取spring配置文件当中的所有的id值
//---获取工厂类型当中所有Person类的值。获取的都是id
String[] beanNamesForType = clx.getBeanNamesForType(Person.class);
for (String id : beanNamesForType) {
System.out.println("id="+id);
}
//判断spring工厂中是否存在这个bean,参数传入的是id值;
boolean b = clx.containsBeanDefinition("a");
System.out.println("b="+b);
//判断spring工厂中是否存在指定id的bean
System.out.println(clx.containsBean("person"));
//目前角度来讲这两个方法是没啥区别的。
}
/**
* 研究目的:在spring核心配置文件中的bean标签当中值配置class,spring可以不可以创建对象。
* :可以
* :spring会不会为他默认分配一个id值呢?
* :会,默认是 全限定名+#+num,这个id是spring按照一定的算法生成的。这个num是因为在
* 配置文件当中可能默认不止配置一次。
* 应用场景:如果这个bean只使用一次,那么就可以省略id值,如果这个bean会被使用多次,或者被其他bean
* 就需要进行设置。
* 研究目的2:name属性在spring配置文件中的使用
* :为bean对象定义别名,小名。id是大名,是唯一标识,name属性定义的内容是别名,是小名,
* spring当中通过大名和小名都是找到这个bean对象的,可以获取到这个bean对象。
* */
@Test
public void test05(){
ApplicationContext ctx = new ClassPathXmlApplicationContext("/applicationContext.xml");
Person person = ctx.getBean(Person.class);
System.out.println("person="+person);//person=com.pactera.spring.Person@128d2484
String[] beanDefinitionNames = ctx.getBeanDefinitionNames();
for (String beanDefinitionName : beanDefinitionNames) {
System.out.println("beanDefinitionName="+beanDefinitionName);//beanDefinitionName=com.pactera.spring.Person#0
}
}
/**
*研究目的2:name属性在spring配置文件中的使用
* :为bean对象定义别名,小名。id是大名,是唯一标识,name属性定义的内容是别名,是小名,
* spring当中通过大名和小名都是找到这个bean对象的,可以获取到这个bean对象。
*应用场景:id和name有共性,他们相同的地方在于都能使用获取对象,相同的地方在于<bean id,class/>等效与
* <bean name,class/>都可以定义一个对象。
* :区别在于别名可以定义多个,别名之间用,间隔就可以了使用任何一个别名都可以找到这个。,id只能定义一个,
* applicationContext.xml(xml语法导致的区别)这个文件当中id属性值命名的时候必须以字母开头,后面可以根字母、数字、下划线、连字符。
* name属性定义的时候比较灵活没有要求,可以明明在特殊场景下,比方说\的使用
* 到了今天xml里的id属性的限制已经不存在了,已经没有这个约束了。
* :区别当中的类的 containsBeanDefinition()和containsBean;
*
* */
@Test
public void test06(){
ApplicationContext ctx = new ClassPathXmlApplicationContext("/applicationContext.xml");
Person person = (Person)ctx.getBean("p");
System.out.println("person="+person);//person=com.pactera.spring.Person@2a4fb17b
Person person1 = (Person)ctx.getBean("p",Person.class);
System.out.println("person1="+person1);//person=com.pactera.spring.Person@2a4fb17b
boolean p1 = ctx.containsBean("p1");//既能判断id也能判断name属性。
System.out.println(p1);//true
boolean p11 = ctx.containsBeanDefinition("p1");//只能判断id,不能判断name值。
System.out.println(p11);//false
}
}
3、Bean标签的特殊写法?
1.只配置class属性不配置id属性
<bean class = "..."/>
//这样是可以的,spring会默认分配一个默认的id值,格式一般是全限定类名+特殊符号+num
3):Spring工厂实现思想
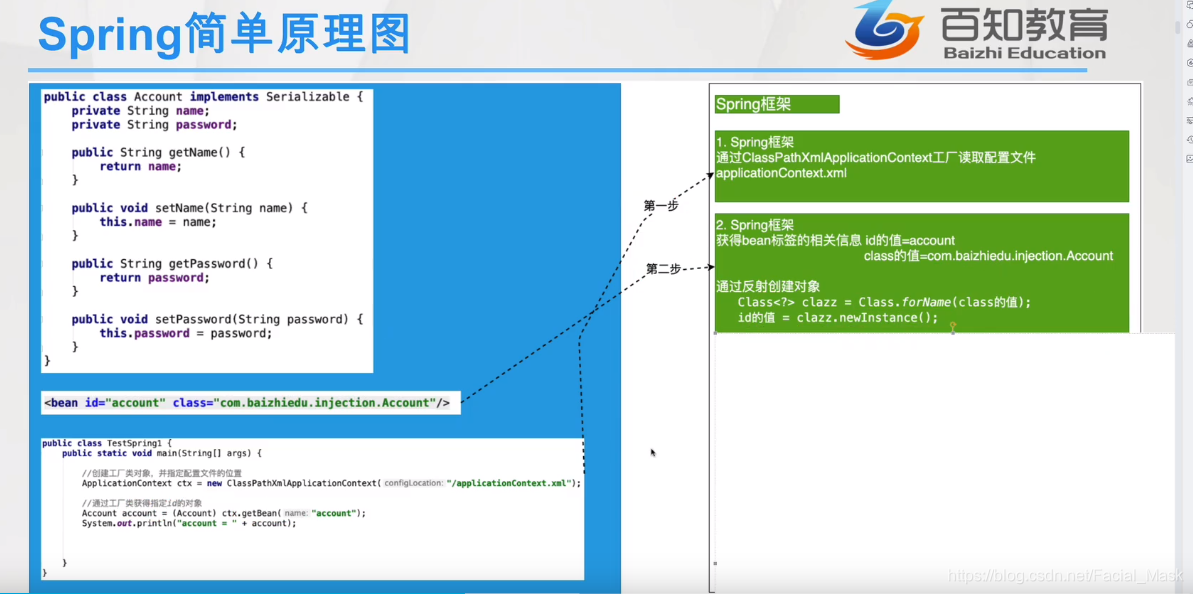
1、为什么我们应用了Spring工厂实现类,写了类搞了配置之后,就可以通过工厂创建对象呢?
当我们定义好类,在applicationContext.xml配置文件中配置好Bean标签之后,创建工厂对象就可以获取相应的配置文件中的对象配置,Spring在Junit或者main方法的程序入口执行之后,创建工厂类对象的时候,Spring会读取applicationContext.xml配置文件,读取之后获取每个bean标签的id和class,根据class采用反射的方式获取对象,并将引用地址赋值给id属性,随后可以通过Spring工厂对象中重载的getBean的方法进行获取对应的对象引用
2、 反射创建对象调用不调用这个类的构造方法呢?
一定会的,默认调用的是无参的构造方法。验证方法:在无参构造方法内部加入一个打印语句就可以了。虽然反射创建了对象,但是反射创建对象其实等效于new创建对象,底层也会调用new来创建对象。反射的底层调用的这个对象的无参构造方法
3、如果一个类的构造方法是私有的怎么办呢?
private修饰的内容只可以在本类中进行使用,如果构造器是private的,spring也能够创建对象,实际上底层通过反射调用私有的属性或者方法的,在反射中私有的内容也可以通过暴力反射的方式进行获取
4、在开发过程中,是不是所有的对象都会交由spring进行创建?
理论上来讲是这样的,但是有特例:实体对象(entity)这个对象中的属性是和数据库进行一一对应的,他的对象往往用于封装数据库中的数据,所以一般实体类对象都是交由mubatis,hibernate的持久层框架进行创建。
第三章:Spring整合日志框架
为什么Spring要和日志框架进行整合
1:Spring和日志框架整合之后,日志框架就可以在控制台中输出Spring框架运行时的一些重要的信息。方便我们了解spring程序的运行的过程,方便我们调试程序
Spring如何整合日志框:
1:Spring不同的版本对于框架的整合,不同的框架整合起来是有区别的,对于Spring1.2.3这是spring的早期版本,都是和与Commons-logging(Apache)
2:Spring4尤其是Spring5.x之后,默认的日志框架是logback log4j2这两个框架,默认的意思就是已经帮我们整合好了的。我们可以选择用logback,也可以选择用Log4J,log4j2和log4j也是不太一样,我们让spring整合log4j就好了
一: 引入log4j相关的jar包
//这个东西叫做日志门面,他的核心作用是把spring5默认集成的日志框架logback和log4j2进行干掉,进而来支持我们的log4j,详细的可以去日志课程中去看,引入这个依赖的目的就是为了让spring支持log4j.摒弃另两个日志框架。
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
二: 引入log4.properties
log4j.rootLogger=debug,console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.Out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=[frame] %d{yyyy-MM-dd HH:mm:ss,SSS} - %-4r %-5p [%t] %C:%L %x - %m%n