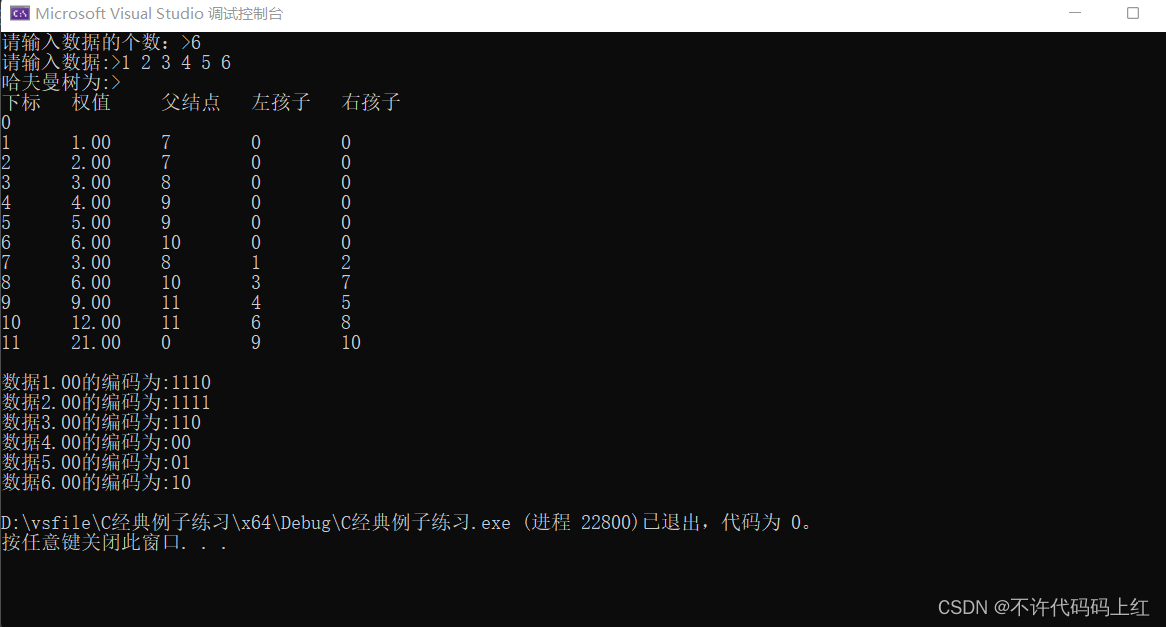
背景:
one-hot:
缺点:1.高维稀疏,2.不能体现句子中词的重要性,3.不能体现词与词之间的关系。
embedding:
1.解决了高维稀疏
tf-idf:
2.解决了one-hot中不能体现句子中词的重要性这一特点。
语言模型:
3.解决不能体现词与词之间的关系。
前馈神经网络:上一层的输出只作为下一层的输入(即标准神经网络NN)
反馈神经网络/循环神经网络:当前层的输出除了作为下一层的输入,还返回回来重新作为输入
基于统计的语言模型:n-gram
基于神经网络的语言模型:
基于前馈神经网络的语言模型:NNLM(编码词向量:训练一个语言模型,一旦模型训练完成,那么嵌入的矩阵C也跟着训练完成,那么我们可以用C矩阵去做任何一个中文字的嵌入。)
基于循环神经网络的语言模型:RNNLM
1.n-gram:基于统计的语言模型
利用联合概率分布(P(w1,w2,w3...)=P(w1)*P(w2|w1)*P(w3|w1w2)...)
越往后概率越小,甚至为0;越往后计算量越大,越复杂。
造成的主要原因:依赖前边的词太多。
解决办法(n-gram):加一个窗口限制n,n为几,那么就依赖几个词
假设n=2,
P(w1,w2,w3,w4,w5)=P(w1)*P(w2|w1)*P(w3|w2)*P(w4|w3)*P(w5|w4)
n太大,依赖前边的词太多,提取信息全面了但是计算信息量大;
n太小,依赖前边的词就小,但是提取信息就小。
一般情况下:n=2 or 3,n=2,bigram,n=3,tregram
出现的问题:
问题1:即使是正确的句子,它的句子联合概率也很小;
问题2:统计的方式并不是最优的计算方式。
缺点:1.缺乏长依赖关系
2.随着n的增长参数量、计算量会随着n指数增大
3.数据稀疏
4.统计计算方法不是最好
2.NNLM:基于神经网络的语言模型
优点:通过神经网络去预测概率
缺点:在当时模型显得略微复杂,并且没有数据量
P(w1,w2,w3...)=P(w1)*P(w2|w1)*P(w3|w2)...(也是通过窗口)
w1,w2,w3原本是中文词,通过词汇表变成下标的形式。
常用的信息融合人方式:1.求和,2.求和求平均,3.拼接
残差网络:将输入直接和输出相加
y=x+f(x)
残差的作用:解决梯度消失
梯度的方向:指的是值上升最快的方向,而我们要的是梯度下降,因此一般说的是反方向,即定义代价的时候为什么要加负号的原因。
如何求梯度:用代价对参数求偏导,则求出了该参数的梯度,代价越大,梯度越大,代价越小,梯度越小。
w=w-learning_rate*梯度
梯度消失:指的是因为梯度太小导致w不能更新
梯度爆炸:指的是因为梯度太大导致w更新太大,解决办法:梯度裁剪
数据拼接:为了进行信息融合。
基于统计的语言模型:n-gram
基于神经网络的语言模型:1.基于前馈神经网络 2.基于循环神经网络
基于统计的语言模型:
要判断一段文字是不是一句自然语言,可以通过确定这段文字的概率分布来表示其存在的可能性。 语言模型中的词是有顺序的,给定m个词看这句话是不是一句合理的自然语言,关键是看这些词的排列顺序是不是正确的。所以统计语言模型的基本思想是计算条件概率。比如一段文字有w1,w2,w3...,wm这m个词组成,看看是不是一句话,就可以用下面的公式计算其联合概率:
P(w1,w2,w3...,wm)=P(w1)P(w2|w1)P(w3|w1,w2)...P(wm|w1,w2,...wm-1)P(w1,w2,w3...,wm)=P(w2|w1)P(w3|w1,w2)...P(wm|w1,w2,...wm-1)
N-Gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成了长度是N的字节片段序列。
每一个字节片段称为gram,对所有gram的出现频度进行统计,形成关键gram列表,也就是这个文本的向量特征空间,列表中的每一种gram就是一个特征向量维度。
该模型基于这样一种假设,第N个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
如果我们有一个由 m 个词组成的序列(或者说一个句子),我们希望算得概率 ,![]() 根据链式规则,可得
根据链式规则,可得
![]()
这个概率显然并不好算,不妨利用马尔科夫链的假设,即当前这个词仅仅跟前面几个有限的词相关,因此也就不必追溯到最开始的那个词,这样便可以大幅缩减上述算式的长度。即
![]()
这个马尔科夫链的假设为什么好用?我想可能是在现实情况中,大家通过真实情况将n=1,2,3,....这些值都试过之后,得到的真实的效果和时间空间的开销权衡之后,发现能够使用。
下面给出一元模型,二元模型,三元模型的定义:
当 n=1, 一个一元模型(unigram model)即为 :

当 n=2, 一个二元模型(bigram model)即为 :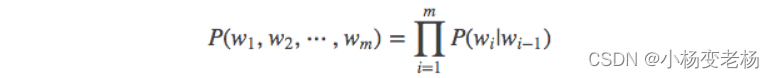
当 n=3, 一个三元模型(trigram model)即为
然后下面的思路就很简单了,在给定的训练语料中,利用贝叶斯定理,将上述的条件概率值(因为一个句子出现的概率都转变为右边条件概率值相乘了)都统计计算出来即可。这里先给出公式:

对第一个进行解释,后面同理,如下:
![]()
假设现在有一个语料库,我们统计了下面的一些词出现的数量

下面的这些概率值作为已知条件:

p(want|<s>) = 0.25
下面这个表给出的是基于Bigram模型进行计数之结果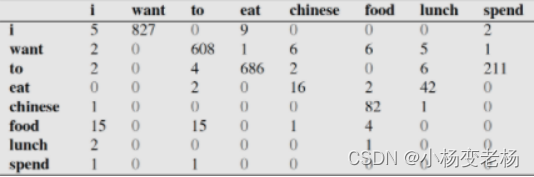
例如,其中第一行,第二列 表示给定前一个词是 “i” 时,当前词为“want”的情况一共出现了827次。因此我们可以算得相应的频率分布表如下。
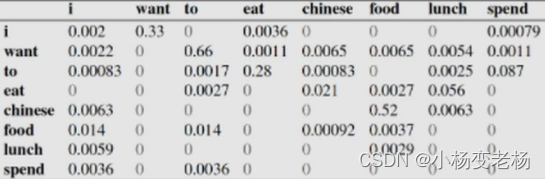
比如说,我们就以表中的p(eat|i)=0.0036这个概率值讲解,从表一得出“i”一共出现了2533次,而其后出现eat的次数一共有9次,p(eat|i)=p(eat,i)/p(i)=count(i,eat)/count(i)=9/2533 = 0.0036
下面我们通过基于这个语料库来判断s1=“<s> i want english food</s>” 与s2 = "<s> want i english food</s>"哪个句子更合理:通过例子来讲解是最人性化的,我在网上找了这么久发现这个例子最好:
首先来判断p(s1)
P(s1)=P(i|<s>)P(want|i)P(english|want)P(food|english)P(</s>|food)
=0.25×0.33×0.0011×0.5×0.68 = 0.000031
再来求p(s2)
P(s2)=P(want|<s>)P(i|want)P(english|want)P(food|english)P(</s>|food)
=0.25*0.0022*0.0011*0.5*0.68 = 0.00000002057
通过比较我们可以明显发现0.00000002057<0.000031,也就是说s1= "i want english food</s>"更像人话,更符合说话的逻辑。
再深层次的分析,我们可以看到这两个句子的概率的不同,主要是由于顺序i want还是want i的问题,根据我们的直觉和常用搭配语法,i want要比want i出现的几率要大很多。所以两者的差异,第一个概率大,第二个概率小,也就能说的通了。
总结:
在实际操作中,如果文本较长,P(wi|w1,w2,...wi−1) 的估计会非常困难,所以就出现了一个简化模型N-gram语言模型:当前词只和它前面的n个词有关,与更前面的词无关,与后边的词也无关。
为什么说文本较长估计会非常困难?
语言模型的任务是根据语料训练模型参数,根据词典中存在的词自动生成一句自然语言,需要保证生成的这句话是一段通顺的话,如果N-gram中的N选取的比较大,比如说5,那每个当前词的估计都和前面的5个词有关,比如我要生成‘中华人民共和国’,在生成第六个词‘和’时,要计算P(和|w1,w2,w3,w4,w5),要知道在生成第六个词的时候前面的5个词并不是确定的,需要将所有的可能性都列出来一个一个比较,选择概率最大的那个,而每个词的可能性都是词典大小的可能性,如果词典里有1万个词,那w1,w2,w3,w4,w5每个词都有1万中选择,这5个词组成的序列有10000^5个序列,这是一个非常大的数,每一种序列都会去训练语料中寻找该种序列出现的次数,也就是序列频率,这只是计算出了条件概率的分母,还有分子,分子是6个词所有可能性每一种可能性出现的次数,会得到10000^6个序列,用一个公式表示:
P(w6|w1,w2,w3,w4,w5) = count(w1,w2,w3,w4,w5,w6) / count(w1,w2,w3,w4,w5)
根据上面的分析每个词的预测我们都会得到10000^6个这样的概率,想一下,如果不约束文本的长度,那后面的条件概率几乎是无法计算的,因为数量太多了,不仅有这个问题,还有如果 w1,w2,w3,w4,w5,w6w1,w2,w3,w4,w5,w6组成的序列不是一个常用的序列,在预料中找不到这样的词序组合,那对应序列算出来的概率会很小很小,但是你也不能不计算他,所以就会面临你要计算非常多的概率,但是计算出来的大部分值非常小,甚至接近于0,而这些接近于0的概率还不能舍弃,必须存在,这样就会造成数据稀疏的问题。
n-gram语言模型解决了用普通的条件概率计算句子概率参数太多难以训练的问题,理论上来说n取得越大保留的词序信息就越多,生成的句子越合理,但如果n取得比较大,同样会面临数据稀疏的问题,n-gram 模型解决了参数太多难以训练的问题,但没有解决数据稀疏的问题。
之所以存在数据稀疏的问题,是因为我们想把n取得大一点来更多的保留词序信息,但n太大会导致w1,w2,w3,...wnw1,w2,w3,...wn这个序列在语料中很少出现或者根本不出现,(根据经验也知道太长的一句话在语料中出现的次数不是那么多,要远远小于2,3个词出现的次数)造成计算出的条件概率接近于0,那算出的句子的概率也是接近于0,这个语言模型就没法用了,这是数据稀疏导致的训练出的语言模型无法用的原因。
基于统计的 n-gram 语言模型的优缺点:
优点:(1) 采用极大似然估计,参数易训练;(2) 完全包含了前 n-1 个词的全部信息;(3) 可解释性强,直观易理解。
缺点:(1) 缺乏长期依赖,只能建模到前 n-1 个词;(2) 随着 n 的增大,参数空间呈指数增长;(3) 数据稀疏;(4) 单纯的基于统计频次,泛化能力差。
现在问题来了,我们既想把n取的大一点以保留更多的词序信息,又想避免数据稀疏的问题,事实上,确实有这样的模型,那就是神经网络语言模型。
神经网络语言模型得提出解决了n-gram中出现的数据维度稀疏的问题
和n-gram模型相同,神经网络语言模型(NNLM)也是对n元语言模型进行建模,估计。
不同点就是,NNLM不通过计数的方式对n元条件进行估计,而是直接通过,一个神经网络去进行建模求解。

NNLM的模型分为三层,输入层,隐藏层和输出层。
如果要生成‘中华人民共和国’这句话,已经生成了前面的四个词,要在前面的四个字为条件的情况下输出第五个词,输入层是将原始文字映射层向量,当然,这个向量是随机初始化得到的,也是我们要在训练过程中调整的参数(权重),在输入层将词向量拼接起来输入到隐藏层,隐藏层是一个非线性激活函数,输出层得到的是一个词典大小的向量,表示词典中的每个词作为语言模型生成的第五个词的可能性。
NNLM也是N元语言模型,比如假设我们训练的是一个7元语言模型,在训练预料中我们会按照每7个词做一个样本,其中前6个词是输入,第七个词是正确的输出,模型通过6个词的输入在输出层预测第七个词在字典上的概率分布。对整个语料来说,语言模型需要最大化:
∑ logP(wi|wi−n+1,...wi−1)
训练阶段的话使用随机梯度下降即可,求导求极值,来优化这个目标函数。
为什么神经网络语言模型能够缓解数据稀疏的问题?
这是由于NNLM使用词序列的词向量对上文(预测词前面的词被称为上文)进行表示,而统计语言模型使用的上文是各词的one-hot 表示,词是直接在字典里拿出来的,词与词之间是相互独立的,每个位置都可以在词典中任意选择词,可以这样理解,作为条件的每个词都是一个维度为词典大小的one hot向量,这样构成的条件矩阵是一个非常稀疏的矩阵,而NNLM将词向量压缩在一个低维空间,利用这种低维的实数表示,可以用相似的上文预测出相似的目标词,而传统模型只能用相同的上文预测出相同的目标词(无法计算词与词之间的距离,只能去语料中匹配找词频,很机械)。
至此出现了两个数据稀疏,一个是说输入是one-hot的形式,输入词典大小的向量,但这个向量只有一个1,其余维度都是0,输入一个很大的矩阵但包含的信息太少,造成数据稀疏。另一个是说在输出层,由于n太大导致长度为n-1的序列在语料中出现的频次太少甚至不出现,导致计算出来的条件概率很多都是0或者接近于0,这样就会造成模型生成出来的句子概率基本都接近于0,无法分出那些是正常的句子,那些是不对的句子,使模型失效。NNLM对这两个数据稀疏问题都起到一定的缓解作用。
语言模型是考虑上文,用 上文预测下一个词,而后来出现的Word2vec中的CBOW用 上下文来预测中间词训练词向量。
即使使用了神经网络,本质上NNLM仍然是N元语言模型,就是你要预测的当前词只和他前面的N-1个词有关,与更前面的词无关,尽管这种方法一定程度上解决了数据稀疏的问题,但还是损失了一些信息。那有没有一种把要预测的当前词的前面所有的词都利用上的模型,显然是有的,这就要涉及到自然语言处理中的大杀器循环神经网络(RNN),我们都知道,循环神经网络的定义是当前的输出不仅和当前的输入有关,还和上一时刻的隐藏层的输出有关,这样讲神经网络展开后就会发现他把序列从开头到结尾全连起来了, 十分方便处理序列数据,而这个性质正是我们做语言模型所需要的:预测的当前词要和他前面的所有词有关,而不仅仅是他前面的N-1个词。