(二)正则表达式——捕获
正则捕获的懒惰性
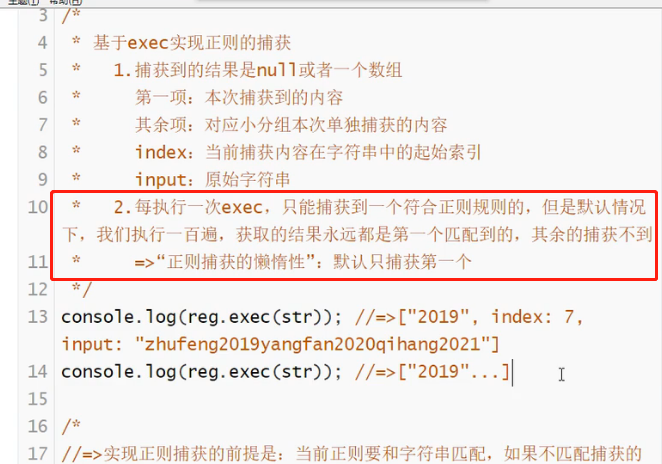
实现正则捕获的方法:exec

exec返回的结果:

懒惰性
这就是正则捕获的懒惰性:默认只捕获第1个
lastIndex:下次匹配的开始位置
懒惰的原因:默认lastIndex的值不会改变,所以每次找都是从开始位置开始找,所以都只找到第1个。
解决正则的懒惰性:用全局g模式

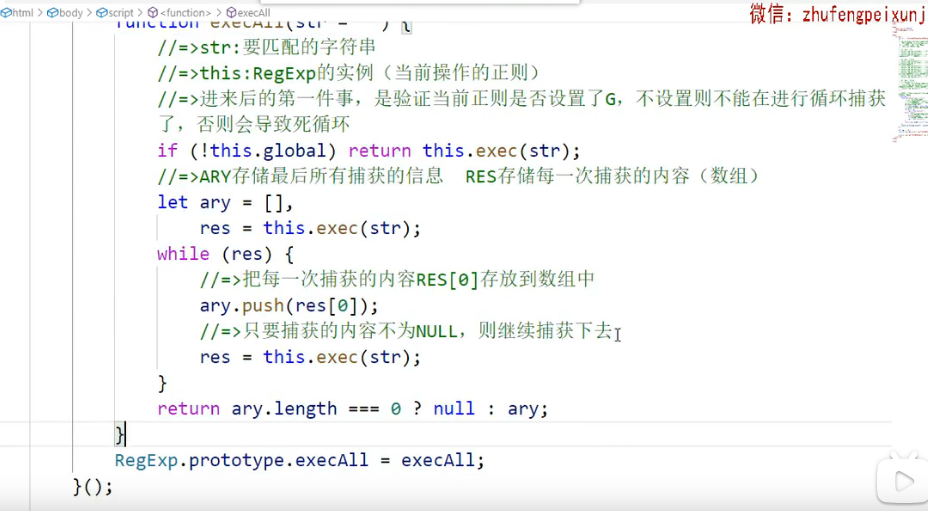
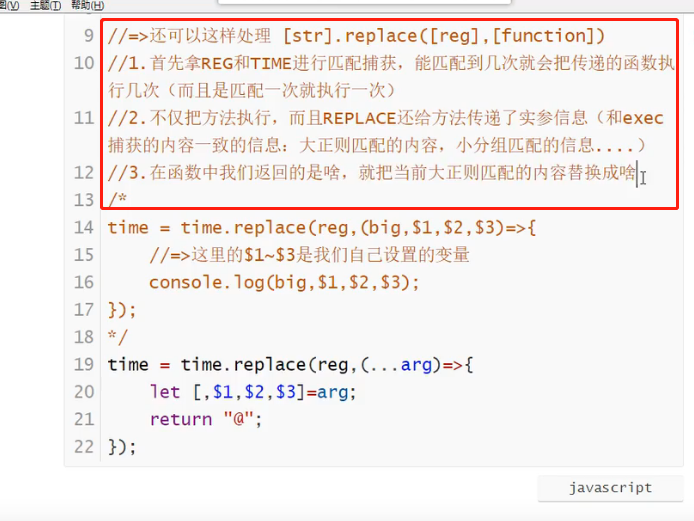
手写execAll
let str=`baidu2019ali2020zhufeng2021peixun2022`
let reg=/(\d+)/g
reg.lastIndex=11;
console.log(reg.exec(str));
(function(){
RegExp.prototype.execAll=function(str){
let arr=[],res=this.exec(str);
if(!this.global) return res;
while(res){
arr.push(res[0]);
res=this.exec(str);
}
return arr.length?arr:null;
}
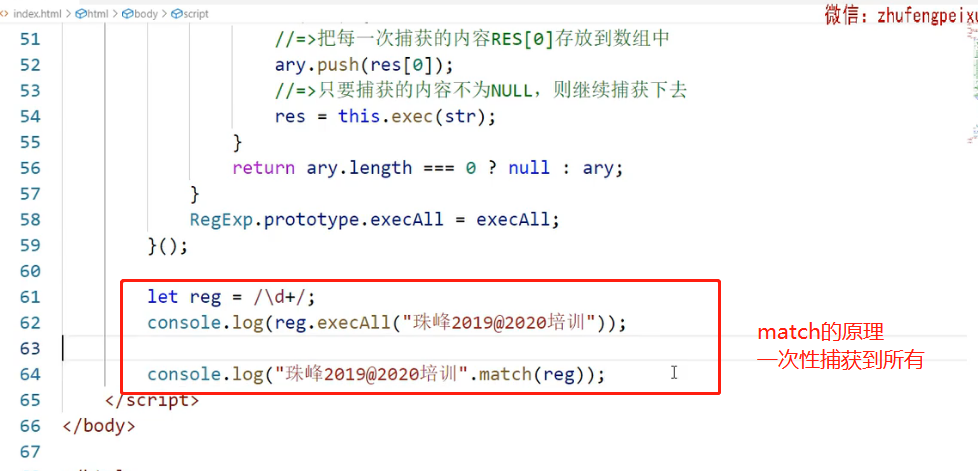
const reg=/\d+/g;
const str=`baidu2019ali2020zhufeng2021peixun2022`
console.log(reg.execAll(str));
})()
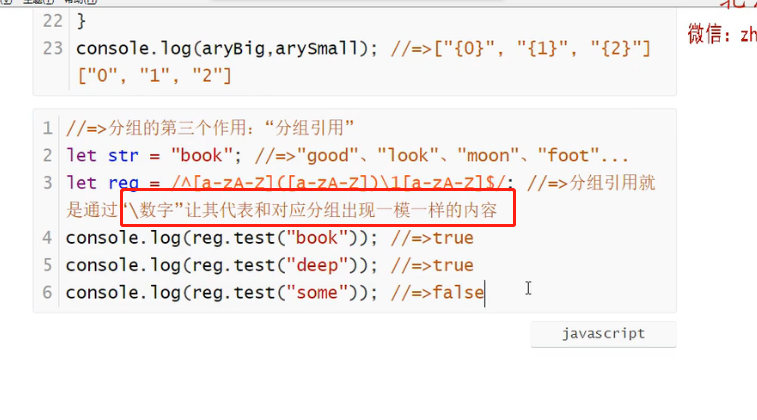
分组捕获和分组引用

非g模式

分组引用
\1:出现跟分组1一模一样的内容
取消贪婪性
当?出现在量词元字符后面,表示的是取消贪婪

let str=`look`
let reg=/([a-z])\1+/i
console.log(reg.exec(str));
str=`2019-12-23`
reg=/\d+?/g
console.log(reg.exec(str));
当出现在其他元字符后面,表示的是0-1次
?的五大作用

分组的3大作用:
- 改变优先级
- 捕获到匹配的内容
- 分组引用
其他能捕获到的方法
reg.test略
使用test方法,则需要用RegExp.$1 拿到捕获到的信息。
最多支持$1-$9

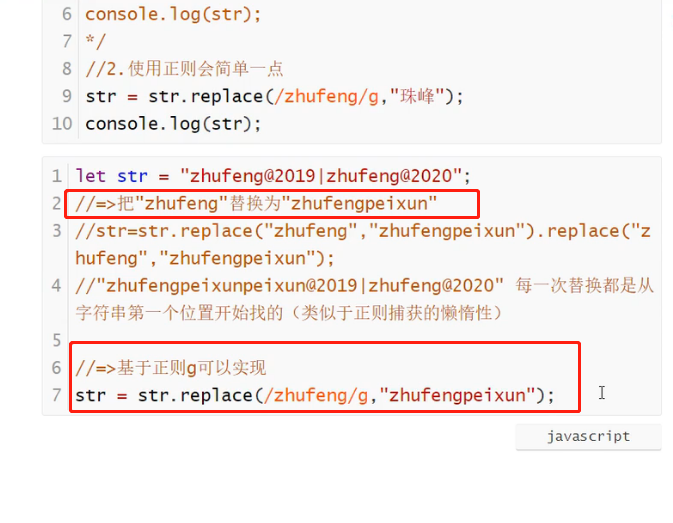
replace*
年月日
let str='2019-11-23'
let reg=/(?<=\d{4})-/
str=str.replace(reg,'年');
console.log(str);
str='2019-11-23'
reg=/^(\d{4})-(\d{2})-(\d{2})$/
// str=str.replace(reg,function(_,$1,$2,$3){
// return `${$1}年${2}月${3}日`
// })
str=str.replace(reg,'$1年$2月$3日')
str=str.replace(reg,`$1年$2月$3日`)
console.log(str);
replace中通过$1 $2 直接拿到分组信息
单词首字母大写

let str=`Cybersecurity firm's word-spell 'abc' Symantec says Dragonfly group has been`
let reg=/\b[a-z]+\b/gi
str=str.replace(reg,function(word){
return word[0].toUpperCase()+word.slice(1)
})
console.log(str);
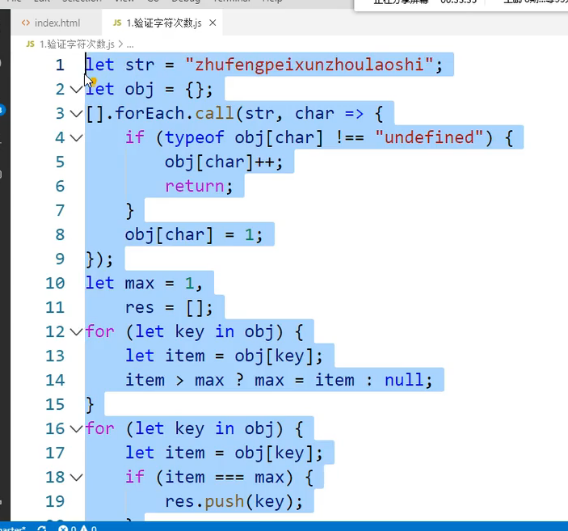
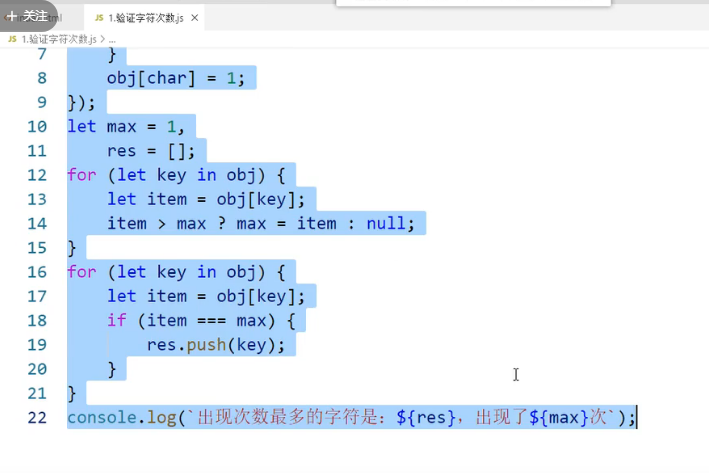
最多出现的字母
对象法(去重思路)
排序+正则法*
- 先排序
- 和前面一样:分组引用
!!!用正则很巧妙
- str.match
用正则:
当你不需要分组信息的时候,用str.match更方便;
但是需要分组信息的时候,str.match则无法满足,需要循环reg.exec(replace等)

let str=`aghijijfeiswwwwaacvfefefeefeass`;
str=str.split('').sort((a,b)=>a.localeCompare(b)).join('')
console.log(str);
let reg=/([a-z])\1+/g
let arr=str.match(reg);
console.log(arr);
arr.sort((a,b)=>b.length-a.length);
console.log(arr);
let max=arr[0].length;
arr=arr.filter(str=>str.length===max);
console.log(arr);
arr=arr.map(i=>i[0])
console.log(`最多次数的字符是${arr.join('|')} 最多次数为${max}`)
次数+正则法*
let str=`aghijijfeiswwwwaacvfefefeefeass`;
str=str.split('').sort((a,b)=>a.localeCompare(b)).join('')
console.log(str);
let count=str.length,arr=[];
for(;count>0;count--){
const reg=new RegExp(`([a-z])\\1{${count-1}}`,'g')
arr=str.match(reg);
if(arr){
arr=arr.map(i=>i[0])
break;
}
}
console.log(`最多次数的字符是${arr.join('|')} 最多次数为${count}`)
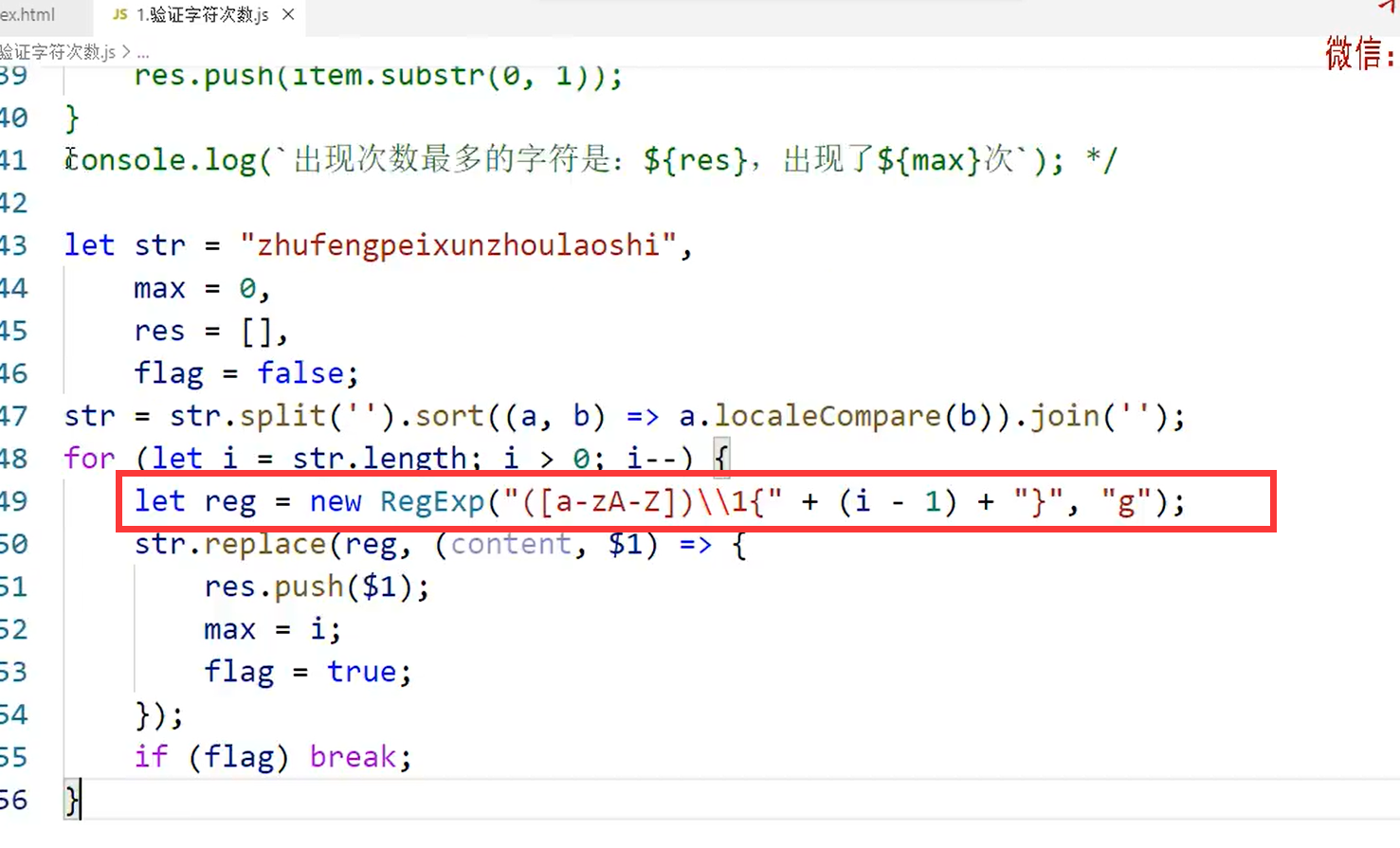
其他做法

时间字符格式化

(function(){
function format(template=`{0}年{1}月{2}日 {3}时{4}分{5}秒`){
let date=this.match(/\d+/g);
template=template.replace(/\{(\d+)\}/g,function(_,$1){
const time=date[$1]
time.length<2?`0${time}`:null;
return time;
})
return template;
}
String.prototype.format=format;
let str=`2019-7-21 18:25:39`
str=str.format()
console.log(str)
})()
queryURLParams

答案做得很简单
千分符*
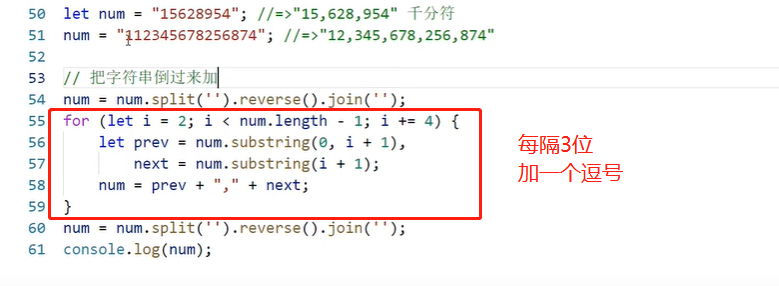
正则解法:
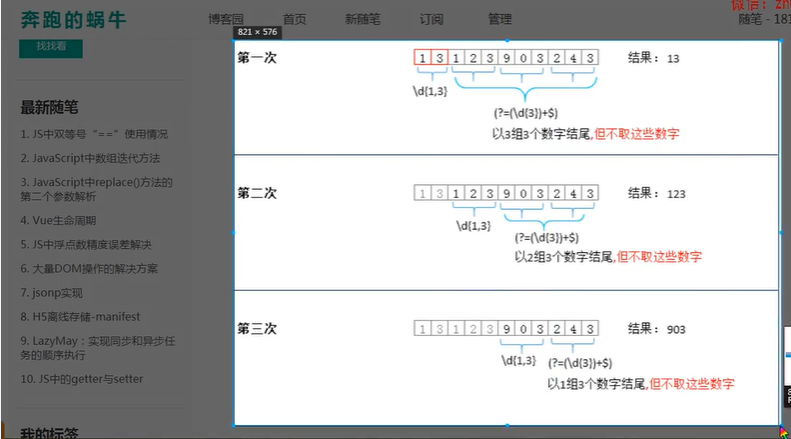
正向预查:条件符合
负向预查:只要条件不符合
// 3位一个逗号
let num=567825612345;
let str=num+'';
console.log(str);
let reg=/\d(?=(\d{3})+(?!\d))/g
reg=/\d(?=(\d{3})+$)/g
str=str.replace(reg,(num)=>num+',')
console.log(str);
这里也有一段 断言 的正则
https://cdn.jsdelivr.net/gh/bobcn/hexo_resize_image.js@master/hexo_resize_image.js

![[附源码]SSM计算机毕业设计疫情状态下病房管理平台JAVA](https://img-blog.csdnimg.cn/13bbbd1e119f4d7c82fffa57a6185a03.png)




![[附源码]计算机毕业设计springboot体育馆场地预约管理系统](https://img-blog.csdnimg.cn/b63d789a3d6943c4a0b4e163a17acb98.png)