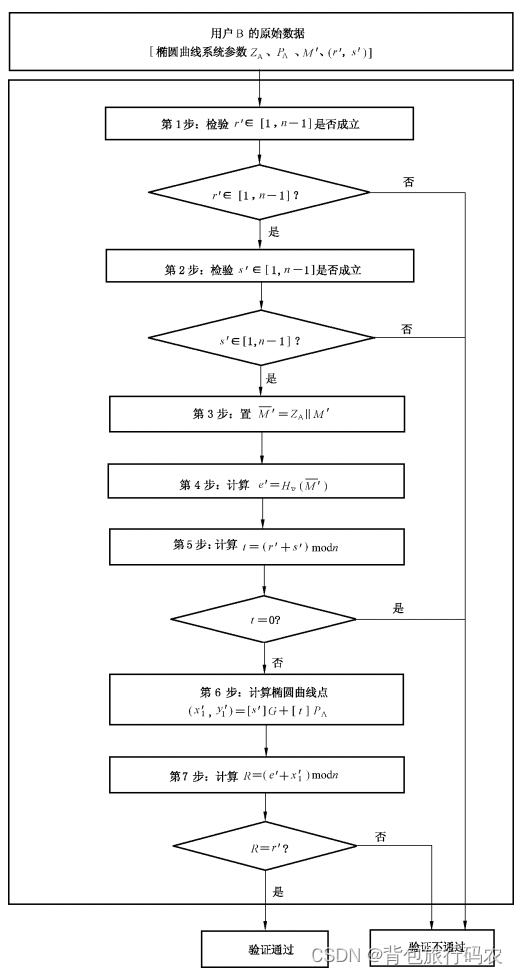
探索对抗样本生成方法:保护机器学习模型的安全性
在当今人工智能时代,机器学习模型被广泛应用于各个领域,包括图像识别、语音识别、自然语言处理等。然而,随着机器学习模型的普及应用,对抗样本攻击也成为了一个备受关注的问题。对抗样本是经过有意设计的、对机器学习模型具有误导性的输入数据,可以引发模型的误判。本文将探索对抗样本生成方法,以期提供一些参考和启示,从而加强机器学习模型的安全性。
1. 什么是对抗样本?
对抗样本是通过对原始输入进行微小的、有针对性的扰动而生成的,这些扰动通常无法被人类察觉,但却足以使机器学习模型产生错误的输出。对抗样本攻击可以分为白盒攻击和黑盒攻击,前者假设攻击者具有对模型的完全访问权限,而后者只能通过模型的输入和输出来进行攻击。
2. 常见的对抗样本生成方法:
a. 基于梯度的方法:这类方法利用模型的梯度信息来生成对抗样本。例如,Fast Gradient Sign Method(FGSM)通过计算输入数据关于损失函数的梯度,然后根据梯度的符号对输入数据进行微小扰动。
b. 优化方法:这类方法将对抗样本生成问题转化为一个优化问题,通过最小化输入数据与原始数据之间的差异,并同时使模型输出发生变化。例如,基于迭代的方法(Iterative methods)通过迭代地应用梯度信息来生成对抗样本。
c. 对抗生成网络(GANs):GANs 是一种生成模型,由生成器和判别器组成。生成器试图生成看起来与真实数据相似的对抗样本,而判别器则试图区分真实数据和生成的对抗样本。通过训练生成器和判别器的对抗过程,可以生成具有欺骗性的对抗样本。
3. 对抗样本生成的应用和挑战:
对抗样本生成方法不仅可以用于评估机器学习模型的鲁棒性和安全性,还可以应用于提高模型的鲁棒性。然而,对抗样本生成也面临着一些挑战。首先,生成的对抗样本需要保持与真实数据的分布相似,这对于一些复杂的数据域来说是一项困难的任务。其次,对抗样本生成方法需要考虑攻击者的目标和资源限制,以及对模型的可解释性和鲁棒性的平衡。
4. 对抗样本防御方法:
针对对抗样本攻击,研究者们也提出了一系列的对抗样本防御方法。以下是一些常见的方法:
a. 对抗训练(Adversarial Training):在训练过程中引入对抗样本,使模型能够更好地适应对抗样本的扰动,提高模型的鲁棒性。
b. 检测与过滤方法:通过检测输入数据是否为对抗样本,或者过滤掉对抗样本,以减少模型的受攻击性。
c. 基于隐私保护的方法:通过添加随机噪声或模糊化数据来减少对抗样本攻击的效果。
d. 模型改进方法:改进模型的结构和训练方法,以提高模型对对抗样本的鲁棒性。
5. 未来展望
对抗样本生成方法和防御方法仍然是一个活跃的研究领域。未来的研究可以探索更加高效和稳健的对抗样本生成方法,提出更全面的对抗样本防御策略,并将对抗样本攻击和防御方法与其他领域的安全机制相结合,以进一步提高机器学习模型的安全性和可靠性。
对抗样本生成方法是一项重要的研究课题,它对于保护机器学习模型的安全性至关重要。通过了解对抗样本生成方法以及相关的防御策略,我们可以更好地应对对抗样本攻击,加强机器学习模型的鲁棒性和可靠性,推动人工智能技术的发展与应用。