目录
1.解压改名
2.修改装有mysql的虚拟机的my.cnf文件
3.重启装有mysql的虚拟机
4.Datagrip创建azkaban数据库,执行脚本文件
5.修改/opt/soft/azkaban-exec/conf/azkaban.properties文件
6.修改commonprivate.properties
7.传入mysql-connector-java-8.0.29.jar
8.开启Azkaban服务
9.进入Datagrip查看是否成功激活
10.激活executor
11.修改/opt/soft/azkaban-web/conf/azkaban.properties文件
12.修改/opt/soft/azkaban-web/conf/azkaban-users.xml文件
13.复制mysql-connector-java-8.0.29.jar
14.开启AzkabanWeb工程
15.浏览器打开Azkaban服务
16.Azkaban的关闭
1.解压改名
注意:安装Azkaban尽量与安装了mysql的机器避开
[root@lxm147 install]# tar -zxf azkaban-db-3.84.4.tar.gz -C /opt/soft/
[root@lxm147 install]# tar -zxf azkaban-exec-server-3.84.4.tar.gz -C /opt/soft/
[root@lxm147 install]# tar -zxf azkaban-web-server-3.84.4.tar.gz -C /opt/soft/
[root@lxm147 soft]# mv azkaban-db-0.1.0-SNAPSHOT/ azkaban-db
[root@lxm147 soft]# mv azkaban-exec-server-0.1.0-SNAPSHOT/ azkaban-exec
[root@lxm147 soft]# mv azkaban-web-server-0.1.0-SNAPSHOT/ azkaban-web
2.修改装有mysql的虚拟机的my.cnf文件
进入/opt/soft/mysql8目录下,修改my.cnf文件,第31行
31 max_allowed_packet = 1024M3.重启装有mysql的虚拟机
[root@localhost mysql8]# shutdown -r now
PolicyKit daemon disconnected from the bus.
We are no longer a registered authentication agent.
Connection closing...Socket close.
# 或者
[root@localhost mysql8]# service mysqld restart4.Datagrip创建azkaban数据库,执行脚本文件
Datagrip连接mysql数据库,执行以下命令:
create database if not exists azkaban;
use azkaban;
CREATE TABLE active_executing_flows (
exec_id INT,
update_time BIGINT,
PRIMARY KEY (exec_id)
);
CREATE TABLE active_sla (
exec_id INT NOT NULL,
job_name VARCHAR(128) NOT NULL,
check_time BIGINT NOT NULL,
rule TINYINT NOT NULL,
enc_type TINYINT,
options LONGBLOB NOT NULL,
PRIMARY KEY (exec_id, job_name)
);
CREATE TABLE execution_dependencies(
trigger_instance_id varchar(64),
dep_name varchar(128),
starttime bigint(20) not null,
endtime bigint(20),
dep_status tinyint not null,
cancelleation_cause tinyint not null,
project_id INT not null,
project_version INT not null,
flow_id varchar(128) not null,
flow_version INT not null,
flow_exec_id INT not null,
primary key(trigger_instance_id, dep_name)
);
CREATE INDEX ex_end_time
ON execution_dependencies (endtime);
CREATE TABLE execution_flows (
exec_id INT NOT NULL AUTO_INCREMENT,
project_id INT NOT NULL,
version INT NOT NULL,
flow_id VARCHAR(128) NOT NULL,
status TINYINT,
submit_user VARCHAR(64),
submit_time BIGINT,
update_time BIGINT,
start_time BIGINT,
end_time BIGINT,
enc_type TINYINT,
flow_data LONGBLOB,
executor_id INT DEFAULT NULL,
use_executor INT DEFAULT NULL,
flow_priority TINYINT NOT NULL DEFAULT 5,
PRIMARY KEY (exec_id)
);
CREATE INDEX ex_flows_start_time
ON execution_flows (start_time);
CREATE INDEX ex_flows_end_time
ON execution_flows (end_time);
CREATE INDEX ex_flows_time_range
ON execution_flows (start_time, end_time);
CREATE INDEX ex_flows_flows
ON execution_flows (project_id, flow_id);
CREATE INDEX executor_id
ON execution_flows (executor_id);
CREATE INDEX ex_flows_staus
ON execution_flows (status);
CREATE TABLE execution_jobs (
exec_id INT NOT NULL,
project_id INT NOT NULL,
version INT NOT NULL,
flow_id VARCHAR(128) NOT NULL,
job_id VARCHAR(512) NOT NULL,
attempt INT,
start_time BIGINT,
end_time BIGINT,
status TINYINT,
input_params LONGBLOB,
output_params LONGBLOB,
attachments LONGBLOB,
PRIMARY KEY (exec_id, job_id, flow_id, attempt)
);
CREATE INDEX ex_job_id
ON execution_jobs (project_id, job_id);
-- In table execution_logs, name is the combination of flow_id and job_id
--
-- prefix support and lengths of prefixes (where supported) are storage engine dependent.
-- By default, the index key prefix length limit is 767 bytes for innoDB.
-- from: https://dev.mysql.com/doc/refman/5.7/en/create-index.html
CREATE TABLE execution_logs (
exec_id INT NOT NULL,
name VARCHAR(640),
attempt INT,
enc_type TINYINT,
start_byte INT,
end_byte INT,
log LONGBLOB,
upload_time BIGINT,
PRIMARY KEY (exec_id, name, attempt, start_byte)
);
CREATE INDEX ex_log_attempt
ON execution_logs (exec_id, name, attempt);
CREATE INDEX ex_log_index
ON execution_logs (exec_id, name);
CREATE INDEX ex_log_upload_time
ON execution_logs (upload_time);
CREATE TABLE executor_events (
executor_id INT NOT NULL,
event_type TINYINT NOT NULL,
event_time DATETIME NOT NULL,
username VARCHAR(64),
message VARCHAR(512)
);
CREATE INDEX executor_log
ON executor_events (executor_id, event_time);
CREATE TABLE executors (
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
host VARCHAR(64) NOT NULL,
port INT NOT NULL,
active BOOLEAN DEFAULT FALSE,
UNIQUE (host, port)
);
CREATE INDEX executor_connection
ON executors (host, port);
CREATE TABLE project_events (
project_id INT NOT NULL,
event_type TINYINT NOT NULL,
event_time BIGINT NOT NULL,
username VARCHAR(64),
message VARCHAR(512)
);
CREATE INDEX log
ON project_events (project_id, event_time);
CREATE TABLE project_files (
project_id INT NOT NULL,
version INT NOT NULL,
chunk INT,
size INT,
file LONGBLOB,
PRIMARY KEY (project_id, version, chunk)
);
CREATE INDEX file_version
ON project_files (project_id, version);
CREATE TABLE project_flow_files (
project_id INT NOT NULL,
project_version INT NOT NULL,
flow_name VARCHAR(128) NOT NULL,
flow_version INT NOT NULL,
modified_time BIGINT NOT NULL,
flow_file LONGBLOB,
PRIMARY KEY (project_id, project_version, flow_name, flow_version)
);
CREATE TABLE project_flows (
project_id INT NOT NULL,
version INT NOT NULL,
flow_id VARCHAR(128),
modified_time BIGINT NOT NULL,
encoding_type TINYINT,
json MEDIUMBLOB,
PRIMARY KEY (project_id, version, flow_id)
);
CREATE INDEX flow_index
ON project_flows (project_id, version);
CREATE TABLE project_permissions (
project_id VARCHAR(64) NOT NULL,
modified_time BIGINT NOT NULL,
name VARCHAR(64) NOT NULL,
permissions INT NOT NULL,
isGroup BOOLEAN NOT NULL,
PRIMARY KEY (project_id, name, isGroup)
);
CREATE INDEX permission_index
ON project_permissions (project_id);
CREATE TABLE project_properties (
project_id INT NOT NULL,
version INT NOT NULL,
name VARCHAR(255),
modified_time BIGINT NOT NULL,
encoding_type TINYINT,
property BLOB,
PRIMARY KEY (project_id, version, name)
);
CREATE INDEX properties_index
ON project_properties (project_id, version);
CREATE TABLE project_versions (
project_id INT NOT NULL,
version INT NOT NULL,
upload_time BIGINT NOT NULL,
uploader VARCHAR(64) NOT NULL,
file_type VARCHAR(16),
file_name VARCHAR(128),
md5 BINARY(16),
num_chunks INT,
resource_id VARCHAR(512) DEFAULT NULL,
startup_dependencies MEDIUMBLOB DEFAULT NULL,
uploader_ip_addr VARCHAR(50) DEFAULT NULL,
PRIMARY KEY (project_id, version)
);
CREATE INDEX version_index
ON project_versions (project_id);
CREATE TABLE projects (
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT,
name VARCHAR(64) NOT NULL,
active BOOLEAN,
modified_time BIGINT NOT NULL,
create_time BIGINT NOT NULL,
version INT,
last_modified_by VARCHAR(64) NOT NULL,
description VARCHAR(2048),
enc_type TINYINT,
settings_blob LONGBLOB
);
CREATE INDEX project_name
ON projects (name);
CREATE TABLE properties (
name VARCHAR(64) NOT NULL,
type INT NOT NULL,
modified_time BIGINT NOT NULL,
value VARCHAR(256),
PRIMARY KEY (name, type)
);
-- This file collects all quartz table create statement required for quartz 2.2.1
--
-- We are using Quartz 2.2.1 tables, the original place of which can be found at
-- https://github.com/quartz-scheduler/quartz/blob/quartz-2.2.1/distribution/src/main/assembly/root/docs/dbTables/tables_mysql.sql
DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;
CREATE TABLE QRTZ_JOB_DETAILS
(
SCHED_NAME VARCHAR(120) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
JOB_CLASS_NAME VARCHAR(250) NOT NULL,
IS_DURABLE VARCHAR(1) NOT NULL,
IS_NONCONCURRENT VARCHAR(1) NOT NULL,
IS_UPDATE_DATA VARCHAR(1) NOT NULL,
REQUESTS_RECOVERY VARCHAR(1) NOT NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
JOB_NAME VARCHAR(200) NOT NULL,
JOB_GROUP VARCHAR(200) NOT NULL,
DESCRIPTION VARCHAR(250) NULL,
NEXT_FIRE_TIME BIGINT(13) NULL,
PREV_FIRE_TIME BIGINT(13) NULL,
PRIORITY INTEGER NULL,
TRIGGER_STATE VARCHAR(16) NOT NULL,
TRIGGER_TYPE VARCHAR(8) NOT NULL,
START_TIME BIGINT(13) NOT NULL,
END_TIME BIGINT(13) NULL,
CALENDAR_NAME VARCHAR(200) NULL,
MISFIRE_INSTR SMALLINT(2) NULL,
JOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP)
);
CREATE TABLE QRTZ_SIMPLE_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
REPEAT_COUNT BIGINT(7) NOT NULL,
REPEAT_INTERVAL BIGINT(12) NOT NULL,
TIMES_TRIGGERED BIGINT(10) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CRON_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
CRON_EXPRESSION VARCHAR(200) NOT NULL,
TIME_ZONE_ID VARCHAR(80),
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_SIMPROP_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
STR_PROP_1 VARCHAR(512) NULL,
STR_PROP_2 VARCHAR(512) NULL,
STR_PROP_3 VARCHAR(512) NULL,
INT_PROP_1 INT NULL,
INT_PROP_2 INT NULL,
LONG_PROP_1 BIGINT NULL,
LONG_PROP_2 BIGINT NULL,
DEC_PROP_1 NUMERIC(13,4) NULL,
DEC_PROP_2 NUMERIC(13,4) NULL,
BOOL_PROP_1 VARCHAR(1) NULL,
BOOL_PROP_2 VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_BLOB_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
BLOB_DATA BLOB NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),
FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_CALENDARS
(
SCHED_NAME VARCHAR(120) NOT NULL,
CALENDAR_NAME VARCHAR(200) NOT NULL,
CALENDAR BLOB NOT NULL,
PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)
);
CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS
(
SCHED_NAME VARCHAR(120) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)
);
CREATE TABLE QRTZ_FIRED_TRIGGERS
(
SCHED_NAME VARCHAR(120) NOT NULL,
ENTRY_ID VARCHAR(95) NOT NULL,
TRIGGER_NAME VARCHAR(200) NOT NULL,
TRIGGER_GROUP VARCHAR(200) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
FIRED_TIME BIGINT(13) NOT NULL,
SCHED_TIME BIGINT(13) NOT NULL,
PRIORITY INTEGER NOT NULL,
STATE VARCHAR(16) NOT NULL,
JOB_NAME VARCHAR(200) NULL,
JOB_GROUP VARCHAR(200) NULL,
IS_NONCONCURRENT VARCHAR(1) NULL,
REQUESTS_RECOVERY VARCHAR(1) NULL,
PRIMARY KEY (SCHED_NAME,ENTRY_ID)
);
CREATE TABLE QRTZ_SCHEDULER_STATE
(
SCHED_NAME VARCHAR(120) NOT NULL,
INSTANCE_NAME VARCHAR(200) NOT NULL,
LAST_CHECKIN_TIME BIGINT(13) NOT NULL,
CHECKIN_INTERVAL BIGINT(13) NOT NULL,
PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)
);
CREATE TABLE QRTZ_LOCKS
(
SCHED_NAME VARCHAR(120) NOT NULL,
LOCK_NAME VARCHAR(40) NOT NULL,
PRIMARY KEY (SCHED_NAME,LOCK_NAME)
);
commit;
CREATE TABLE ramp (
rampId VARCHAR(45) NOT NULL,
rampPolicy VARCHAR(45) NOT NULL,
maxFailureToPause INT NOT NULL DEFAULT 0,
maxFailureToRampDown INT NOT NULL DEFAULT 0,
isPercentageScaleForMaxFailure TINYINT NOT NULL DEFAULT 0,
startTime BIGINT NOT NULL DEFAULT 0,
endTime BIGINT NOT NULL DEFAULT 0,
lastUpdatedTime BIGINT NOT NULL DEFAULT 0,
numOfTrail INT NOT NULL DEFAULT 0,
numOfFailure INT NOT NULL DEFAULT 0,
numOfSuccess INT NOT NULL DEFAULT 0,
numOfIgnored INT NOT NULL DEFAULT 0,
isPaused TINYINT NOT NULL DEFAULT 0,
rampStage TINYINT NOT NULL DEFAULT 0,
isActive TINYINT NOT NULL DEFAULT 0,
PRIMARY KEY (rampId)
);
CREATE INDEX idx_ramp
ON ramp (rampId);
CREATE TABLE ramp_dependency (
dependency VARCHAR(45) NOT NULL,
defaultValue VARCHAR (500),
jobtypes VARCHAR (1000),
PRIMARY KEY (dependency)
);
CREATE INDEX idx_ramp_dependency
ON ramp_dependency(dependency);
CREATE TABLE ramp_exceptional_flow_items (
rampId VARCHAR(45) NOT NULL,
flowId VARCHAR(128) NOT NULL,
treatment VARCHAR(1) NOT NULL,
timestamp BIGINT NULL,
PRIMARY KEY (rampId, flowId)
);
CREATE INDEX idx_ramp_exceptional_flow_items
ON ramp_exceptional_flow_items (rampId, flowId);
CREATE TABLE ramp_exceptional_job_items (
rampId VARCHAR(45) NOT NULL,
flowId VARCHAR(128) NOT NULL,
jobId VARCHAR(128) NOT NULL,
treatment VARCHAR(1) NOT NULL,
timestamp BIGINT NULL,
PRIMARY KEY (rampId, flowId, jobId)
);
CREATE INDEX idx_ramp_exceptional_job_items
ON ramp_exceptional_job_items (rampId, flowId, jobId);
CREATE TABLE ramp_items (
rampId VARCHAR(45) NOT NULL,
dependency VARCHAR(45) NOT NULL,
rampValue VARCHAR (500) NOT NULL,
PRIMARY KEY (rampId, dependency)
);
CREATE INDEX idx_ramp_items
ON ramp_items (rampId, dependency);
CREATE TABLE triggers (
trigger_id INT NOT NULL AUTO_INCREMENT,
trigger_source VARCHAR(128),
modify_time BIGINT NOT NULL,
enc_type TINYINT,
data LONGBLOB,
PRIMARY KEY (trigger_id)
);
CREATE TABLE validated_dependencies (
file_name VARCHAR(128),
file_sha1 CHAR(40),
validation_key CHAR(40),
validation_status INT,
PRIMARY KEY (validation_key, file_name, file_sha1)
);
5.修改/opt/soft/azkaban-exec/conf/azkaban.properties文件
vim /opt/soft/azkaban-exec/conf/azkaban.properties
7 default.timezone.id=Asia/Shanghai
21 azkaban.webserver.url=http://192.168.180.147:8081
44 mysql.host=192.168.180.141
45 mysql.database=azkaban
46 mysql.user=root
47 mysql.password=root
52 executor.port=123216.修改commonprivate.properties
[root@lxm147 jobtypes]# vim /opt/soft/azkaban-exec/plugins/jobtypes/commonprivate.properties
3 azkaban.native.lib=false
7.传入mysql-connector-java-8.0.29.jar
进入/opt/soft/azkaban-exec/lib目录下
[root@lxm147 lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar /opt/soft/azkaban-exec/lib
[root@lxm147 lib]# rm -rf /opt/soft/azkaban-exec/lib/mysql-connector-java-5.1.28.jar8.开启Azkaban服务
进入 /opt/soft/azkaban-exec/bin目录下
[root@lxm147 bin]# ./start-exec.sh
[root@lxm147 bin]# jps
1520 NameNode
1843 SecondaryNameNode
4820 JobHistoryServer
2822 RunJar
2153 ResourceManager
2313 NodeManager
32202 AzkabanExecutorServer
32218 Jps
1644 DataNode
2700 RunJar9.进入Datagrip查看是否成功激活
use azkaban;
select * from executors;
10.激活executor
[root@lxm147 bin]# curl -G "192.168.180.147:12321/executor?action=activate" && echo
{"status":"success"}
激活成功(忽略我的id,因为已经启动过很多次了)

11.修改/opt/soft/azkaban-web/conf/azkaban.properties文件
vim /opt/soft/azkaban-web/conf/azkaban.properties
7 default.timezone.id=Asia/Shanghai
41 mysql.host=192.168.180.141
42 mysql.database=azkaban
43 mysql.user=root
44 mysql.password=root
48 # MinimumFreeMemory 默认6G,实际服务器内存如果小于此值不启动
49 azkaban.executorselector.filters=StaticRemainingFlowSize,CpuStatus
12.修改/opt/soft/azkaban-web/conf/azkaban-users.xml文件
vim /opt/soft/azkaban-web/conf/azkaban-users.xml
<azkaban-users>
<user groups="azkaban" password="azkaban" roles="admin" username="azkaban"/>
<user password="metrics" roles="metrics" username="metrics"/>
<user password="123456" roles="admin" username="kb21"/>
<role name="admin" permissions="ADMIN"/>
<role name="metrics" permissions="METRICS"/>
</azkaban-users>
13.复制mysql-connector-java-8.0.29.jar
进入/opt/soft/azkaban-web/lib目录下
[root@lxm147 lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar /opt/soft/azkaban-web/lib
[root@lxm147 lib]# rm -rf ./mysql-connector-java-5.1.28.jar 14.开启AzkabanWeb工程
进入/opt/soft/azkaban-web目录下
注意:这里不要进入到bin目录下执行start-web.sh命令,因为conf/azkaban-users.xml目录中的某些文件路径是在/conf上面的
[root@lxm147 azkaban-web]# ./bin/start-web.sh
[root@lxm147 azkaban-web]# jps
1520 NameNode
32321 AzkabanExecutorServer
1843 SecondaryNameNode
4820 JobHistoryServer
32421 AzkabanWebServer
2822 RunJar
32439 Jps
2153 ResourceManager
2313 NodeManager
1644 DataNode
2700 RunJar
15.浏览器打开Azkaban服务
浏览器输入localhost:8081,如果有下面的页面弹出,就说明Azkaban真正启动,如果没有,可以看看有没有遗漏的步骤,或者写错的单词。
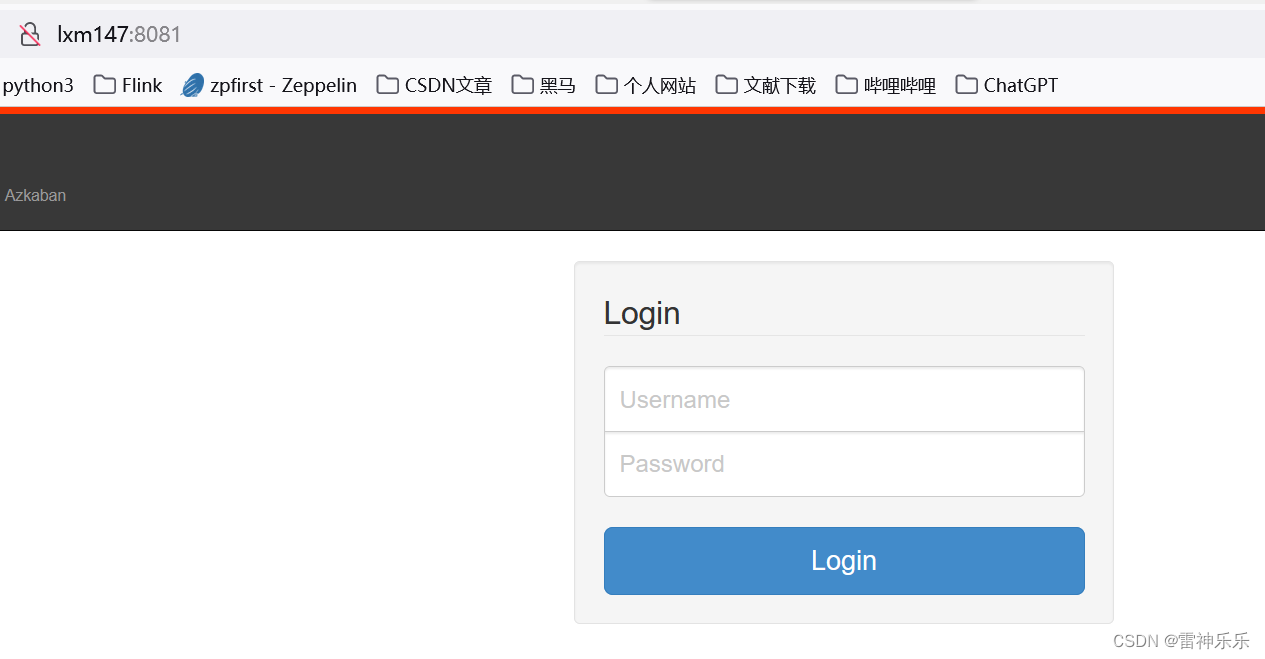
登录的用户名和密码就是步骤11新增的

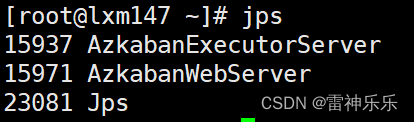
16.Azkaban的关闭
我们之前开启的顺序是:
# 进入 /opt/soft/azkaban-exec/bin目录下
[root@lxm147 bin]# ./start-exec.sh
[root@lxm147 bin]# curl -G "192.168.180.147:12321/executor?action=activate" && echo
{"status":"success"}
# 进入 /opt/soft/azkaban-web目录下
[root@lxm147 azkaban-web]# ./bin/start-web.sh 关闭服务要反着来:
# 先关闭web
[root@lxm147 ~]# cd /opt/soft/azkaban-web/
[root@lxm147 azkaban-web]# ./bin/shutdown-web.sh
Killing web-server. [pid: 15971], attempt: 1
shutdown succeeded
[root@lxm147 azkaban-web]# jps
15937 AzkabanExecutorServer
23110 Jps
# 再关闭exec
[root@lxm147 azkaban-web]# cd /opt/soft/azkaban-exec/
[root@lxm147 azkaban-exec]# ./bin/shutdown-exec.sh
Killing executor. [pid: 15937], attempt: 1
shutdown succeeded
[root@lxm147 azkaban-exec]# jps
23139 Jps关于Azkaban的使用,后面会写,敬请期待。